はじめに
申し訳ありませんが競馬用語の解説は省きます。競馬に興味がある人が読んでいると思うので。
netkeiba.comで公開されている情報(スクレイピングでとってくる情報)
には血統、走破タイム、走行距離等色々あります。前提として、スクレイピングしたデータをそのままモデルに
fitさせたところで何も予想してくれません。情報を選別、整理、分析していく必要があります。
データの分析の方針を決める前に、まずは仮説として、
レースが始まってから最後の直線まで色々あったが、上り3ハロンで馬は残る力全てをもって走り切り
ゴールを通過した順に着順が決まる
とします。当たり前だと思われるかもしれませんがこれにより考慮すべき情報が絞れます。
私が分析を進める上で使用しているデータは以下
・ラップタイム
→レース全体のペース、レースのグレードを評価
・レースの種類芝orダート/距離
→数あるレースの種類を細分化
馬毎のデータ
・馬毎のコーナー通過順、上り3fタイム
→脚質の分類、同じ脚質の馬の中での最後の直線の評価
補足1:騎手、馬名、血統、枠順、走破タイム等は考慮していない
補足2:血統、騎手を考慮していないため、メイクデビューレースは分析対象としない
以上、長いですが前置きでした。
実際の予想するにあたっての作業について
さてAIにレースの予想をしてもらうための訓練データを作成していく。
下位の馬のデータを作成しても馬券に絡まないため無駄。過去のレースにおいて1〜6着の馬でデータを作成する。
例:
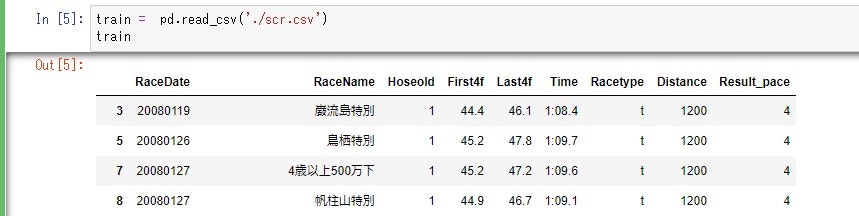
scr.csv
train.csv
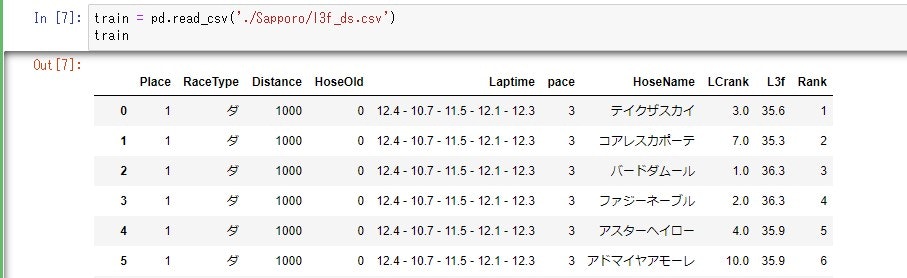
数行だけチラッと。
scrがスクレイピングしてきたrowデータ。trainが整理整頓や標準偏差など計算したもの(訓練データ)
面倒でも新たにcsvファイルをしっかりと書き出しておく。
訓練データをしっかりと作成しておけばモデルのパラメータとかいじらなくても良い結果が出そうだけど、
一応弄ってます。
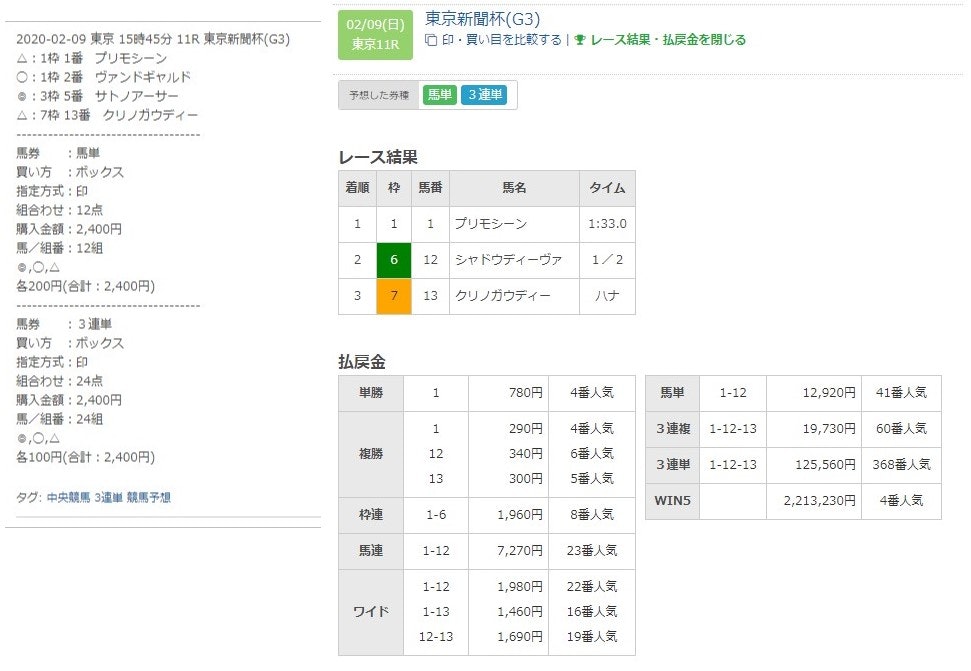
このモデルを用いて導き出したデータで4頭BOX買いをし一応馬単、三連単を的中させることができた。
某中央競馬予想サイトにて公開した予想
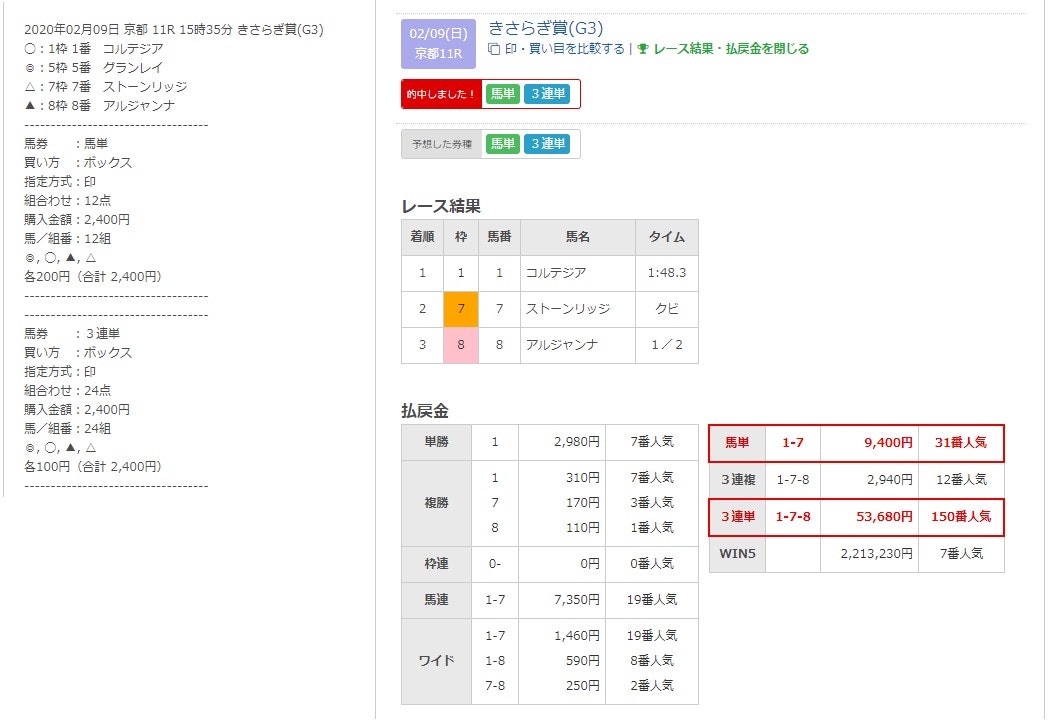
外したレースにおいても3着以内に2頭が入るなどそこそこ良いものが作れたと思います。
あとがき
改善策としてまだまだやれること
・血統
・騎手
・枠順
・季節
・負の特徴量
血統や騎手を基に予想を組み立てるのは競馬の醍醐味なのでいつかはやりたい。しかしやり方が想像すらつかない。
レースの3着以内になった騎手や父馬母馬をひたすらカウントするとかだろうか?模索中。
枠順も芝は内枠有利とは言うが関係ないときもある。ダートでは外枠のほうが馬場が荒れてないため有利とか言うし。
季節によって発情期とかで牡馬牝馬で力の差がでてくるとか?競馬歴1年未満なので正直全然わかりません。
この辺に関してはデータサイエンティストな人たちより、競馬好きのおっちゃんとかと意見交換になると思う。
負の特徴量とは確実に4着以下になってくれる馬を炙り出そうと言う魂胆。
危険な人気馬や目移りする穴馬に無駄なお金を使わなくて済むようにするのが狙い。
また他視点からも予想することによって、BOX買いする4馬にさらに確信を持つことができるようにする。
開発言語はpython、フレームワークはAWS/Cloud9/jupyternotebook。
詳しいコードは余裕があるときに記事を書きたいと思っています。
実際の予想はレジまぐというサイトで公開中、そちらも是非遊びに来てください。