pythonに初めて触れてから約1年が経ちましたので
趣味の競馬ばかりに対してばかりでなく
そろそろ本腰いれて案件をとっていけるように簡単な案件から
経験を積んでいこうと画策中。
↓↓↓今回やらせていただく募集終了済みの案件(ランサーズ様より本文抜粋)↓↓↓
youtube上のキーワード検索した状態で、
指定の条件にある動画のURL、再生回数、登録日付、チャンネル登録者数、タイトルなどの情報を抜き出してスプレッドシートに反映させたい
指定の条件は、再生回数/チャンネル登録者数=○%以上 ・・・a%以上
○日以内に投稿されたもの ・・・b日以内
検索キーワード ・・・キーワード'c'
という条件
指摘の検索キーワードで条件に該当する動画をひたすら集めてくる形
キーワードは複数登録可能
キーワードの選定はこちらでやります
環境はanaconda/jupyternotebook/python3でやっていきます。
実際のこちらの作業順序としては
YoutubeAPIv3の使用申請、キーを取得
条件a,b,cを取得
(ここでは再生回数/チャンネル登録者数100%以上、1800日以内
検索キーワード…ものまね とする)
あらかじめgoogleスプレッドシートのセルにリサーチ希望の
条件a,b,cが書かれているとする
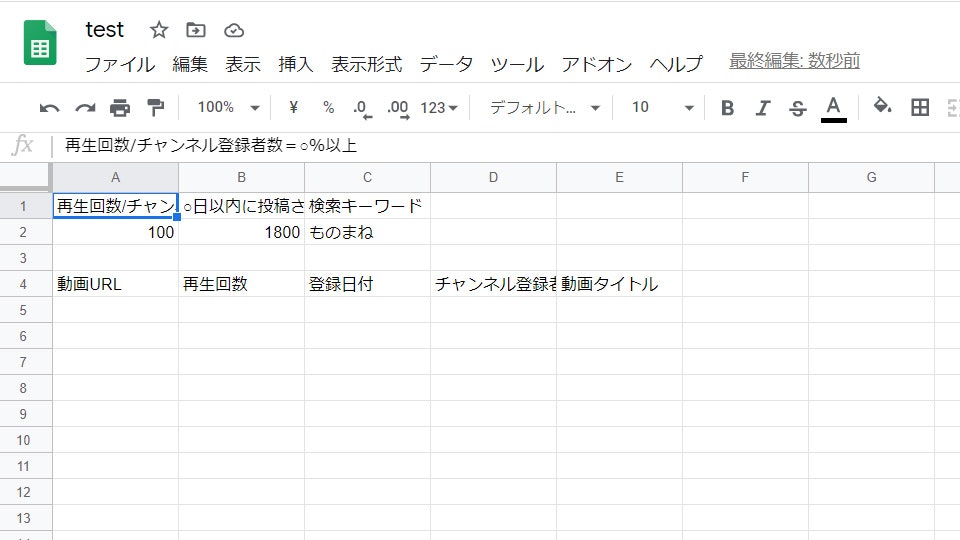
(test.py実行前)
json形式で動画情報取得、一度pd.Dataframeに格納
import pandas as pd
from googleapiclient.discovery import build
YOUTUBE_API_KEY = 'xxx'
youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY)
part='snippet'
q = import_value_C
order = 'viewCount'
type = 'video'
num = 1 #num*5件を検索
search_response = youtube.search().list(part=part,q=q,order=order,type=type)
output = youtube.search().list(part=part,q=q,order=order,type=type).execute()
dic_list = []
for i in range(num):
dic_list = dic_list + output['items']
search_response = youtube.search().list_next(search_response, output)
output = search_response.execute()
df = pd.DataFrame(dic_list)
df1 = pd.DataFrame(list(df['id']))['videoId']
df2 = pd.DataFrame(list(df['snippet']))[['channelTitle','publishedAt','channelId','title']]
df_get = pd.concat([df1,df2], axis = 1)
条件に合わない動画情報をDrop
# 指定の条件に絞る
import datetime
# 再生回数/チャンネル登録者数=a%以上(サンプルは100%以上/変数viewrate)
drop_list = []
for i in range(0,df_output.shape[0]-1,1):
videoviewcount = int(df_output.iloc[i,6])
subscriberCount = int(df_output.iloc[i,-1])
viewrate = round(videoviewcount/subscriberCount * 100,1)
if viewrate < import_value_A:
drop_list.append(i)
df_output_percent = df_output.drop(drop_list)
# b日以内に投稿されたもの以外は削除(サンプルは1800日、約6年)
drop_list = []
for j in range(0,df_output_percent.shape[0]-1,1):
upload_date = df_output_percent.iloc[j,2].split('T')[0].split('-')
dt1 = datetime.datetime(year=int(upload_date[0]), month=int(upload_date[1]), day=int(upload_date[2]), hour=0)
dt_dis = int(str(datetime.datetime.now() - dt1).split(" days, ")[0])
if dt_dis > import_value_B:
drop_list.append(j)
df_output_drop = df_output_percent.drop(drop_list)
条件に合う動画情報のみgoogleスプレッドシートに書き込み
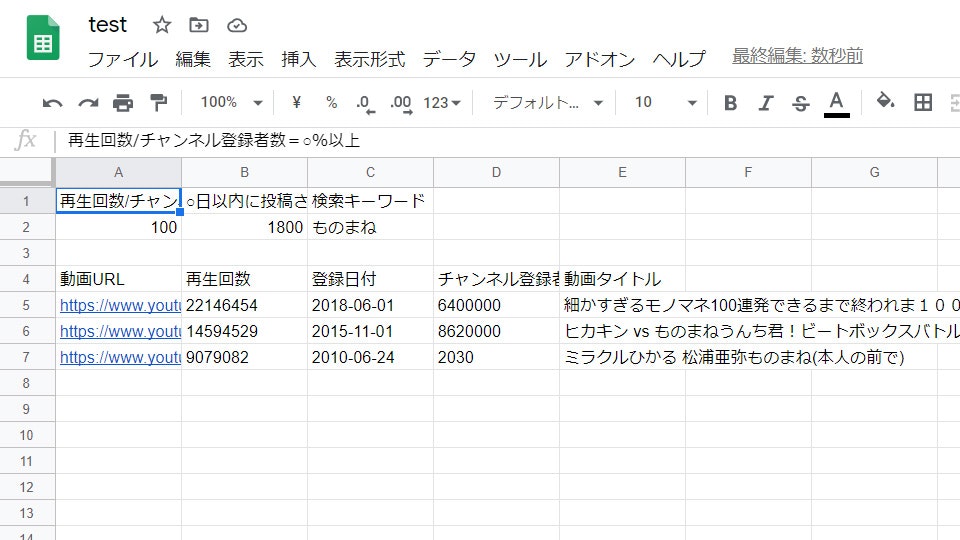
(test.py実行後)
ここまでやって、test.pyを何かしらの方法でクライアントが使用できる形にして
納品となり案件完了ですかね。
またgoogleスプレッドシートに書き込まれたセルの情報をpythonに反映させるのは
①googleスプレッドシートに対して情報取得(googleAPI,スプレッドシートの秘密鍵,スプレッドシートキー取得必要)
②セルの情報を取得(条件a,b,c取得)
という流れになります。
作成中に参考にしたサイト様
YoutubeAPIv3
https://qiita.com/g-k/items/7c98efe21257afac70e9
googleスプレッドシート読み書き
https://tanuhack.com/operate-spreadsheet/
ご覧いただきありがとうございました。
夏季休暇中にASIN、twitterAPIを使った案件にも触れていきます。