はじめに
初めましての人もそうでない人もこんにちは!
新学期になり皆さんの周りの環境はどのように変わりましたか?
特に新社会人や新入生などは忙しい時期ではないでしょうか?
気候も不安定な季節になったので、体調に気を付けながらも良いスタートダッシュを決められるよう微力ながら願っています!
本題ですが、最近はChatGPT、Gemini、Claudeなど生成AIの進化がどんどん進んでいます!
そんな進化の早い生成AIの活用方法の一つに「RAG」という技術があります!
大雑把に言うと、RAGとはAIが質問に答えるとき、事前に関連する情報を検索してから回答を作る仕組みのことです!
この技術によって、生成AIがより専門的な回答をすることができたり、社内の情報を登録することによって社内アプリとして業務効率化に貢献したりすることができます!
本格的なRAGシステムは専門的知識が必要となってくるので、今回は自分ができる限りのRAGっぽいチャットボットを作成していきたいと思います!
ぜひ最後までご覧ください!
使用技術
フロントエンド
- React
- TypeScript
バックエンド
- Python
- SQLite
- GeminiAPI
登録ナレッジ
RAGシステムは主にPDFやWordなどテキストベースのファイルを使います!
今回はブルーアーカイブというゲームに登場する私の推しキャラ、白洲アズサの情報を登録したいと思います!
情報のソースはピクシブ大百科の内容を必要な分だけWordにコピペして登録します!
ソースURL:
主なファイルディレクトリ
gemini_rag/
├── backend/
│ ├── app.py
│ └── rag.db
└── frontend/
└── app.tsx
目指す機能(ナレッジが白洲アズサのみ登録された場合)
- アズサの情報が入ったPDFファイルを登録
- SQLiteのデータベースに保存
- ユーザーが質問
- GeminiAPIがデータベースに入っている情報をもとに質問に答える
これらが実現できるように頑張ります!
検索方法について
登録したナレッジを参照して回答するときに一回検索を挟みます!
その時に代表的なのはベクトル検索とキーワード検索の2つです!
それぞれの特徴としては:
- ベクトル検索:キーワードが完全に一致していなくても、意味が類似していれば関連性の高い結果を出します
- キーワード検索:キーワードをもとに検索して結果を出す方法です
つい最近ではその2つのいいとこどりをしたハイブリッド検索というものもあるようです!
今回はその中でもキーワード検索を用いてRAGチャットボットを作成したいと思います!
キーワード検索の中でも今回は部分一致検索、AND検索、OR検索の3つを使って検索機能を実装します!
部分一致検索とは
指定したキーワードが検索対象にあればそれを検索結果に含める方法です!
キーワード: リンゴ
- 赤いリンゴが美味しい → 検索対象(リンゴが含まれているため)
- 赤いアップルが美味しい → 非検索対象(リンゴが含まれていないため)
- 梨とミカンが好き → 非検索対象(リンゴが含まれていないため)
AND検索とは
全てのキーワードが検索対象に含まれているものを検索結果に含める方法です!
キーワード: 赤い リンゴ
- 赤いリンゴが美味しい → 検索対象(「赤い」と「リンゴ」が含まれるため)
- 青いリンゴもある → 非検索対象(「赤い」が含まれていないため)
OR検索とは
指定したキーワードのいずれかが含まれているものを検索結果に含める方法です!
キーワード: 赤い リンゴ
- 赤いリンゴが美味しい → 検索対象(「赤い」と「リンゴ」が含まれているため)
- 青いリンゴもある → 検索対象(「リンゴ」が含まれているため)
- 赤いトマトが美味しい → 検索対象(「赤い」が含まれているため)
- 青い梨もある → 非検索対象(「赤い」と「リンゴ」どちらも含まれていないため)
今回はこれらの検索手法を用いてRAGシステムの開発をしていきます!
実装について
さて、ここからは実際の実装について説明していきます!
全て紹介しようとすると長すぎるので一部抜粋して紹介します!
キーワード検索機能
今回は3つの検索方法を実装していますが、その部分はこんな感じです:
# キーワード検索(部分一致、AND検索、OR検索)
def search_chunks_by_keyword(query: str, top_k: int = Config.DEFAULT_TOP_K) -> List[Dict]:
logger.info(f"\n--- 検索実行: '{query}' ---")
conn = DatabaseManager.get_connection()
cursor = conn.cursor()
# 検索キーワードの抽出
words = [w for w in query.replace('?', '').replace('?', '').split() if len(w) > 1]
logger.info(f"検索キーワード: {words}")
# 全てのナレッジソースを取得
cursor.execute("""
SELECT id, filename FROM knowledge_sources
ORDER BY created_at DESC
""")
all_sources = [dict(row) for row in cursor.fetchall()]
if not all_sources:
logger.info("ナレッジソースが見つかりません")
conn.close()
return []
results = []
# 方法1: 部分一致検索
for source in all_sources:
cursor.execute("""
SELECT kc.*, ks.filename
FROM knowledge_chunks kc
JOIN knowledge_sources ks ON kc.knowledge_id = ks.id
WHERE kc.knowledge_id = ? AND kc.text_content LIKE ?
ORDER BY kc.chunk_index
LIMIT ?
""", (source['id'], f"%{query}%", max(1, top_k // len(all_sources))))
exact_matches = [dict(row) for row in cursor.fetchall()]
results.extend(exact_matches)
# 方法2: AND検索
if words and len(results) < top_k:
for source in all_sources:
conditions = []
params = [source['id']]
for word in words:
conditions.append("text_content LIKE ?")
params.append(f"%{word}%")
sql = f"""
SELECT kc.*, ks.filename
FROM knowledge_chunks kc
JOIN knowledge_sources ks ON kc.knowledge_id = ks.id
WHERE kc.knowledge_id = ? AND {' AND '.join(conditions)}
ORDER BY kc.chunk_index
LIMIT ?
"""
params.append(max(1, (top_k - len(results)) // len(all_sources)))
cursor.execute(sql, params)
and_matches = [dict(row) for row in cursor.fetchall()
if not any(m['id'] == row['id'] for m in results)]
results.extend(and_matches)
# 方法3: OR検索
if words and len(results) < top_k:
for source in all_sources:
conditions = []
params = [source['id']]
for word in words:
conditions.append("text_content LIKE ?")
params.append(f"%{word}%")
sql = f"""
SELECT kc.*, ks.filename
FROM knowledge_chunks kc
JOIN knowledge_sources ks ON kc.knowledge_id = ks.id
WHERE kc.knowledge_id = ? AND ({' OR '.join(conditions)})
ORDER BY kc.chunk_index
LIMIT ?
"""
params.append(max(1, (top_k - len(results)) // len(all_sources)))
cursor.execute(sql, params)
or_matches = [dict(row) for row in cursor.fetchall()
if not any(m['id'] == row['id'] for m in results)]
results.extend(or_matches)
# 以下略
このように、まず部分一致検索を行い、十分な結果が得られなければAND検索、それでも足りなければOR検索と順番に試していくようにしています!これによって、ユーザーの質問に関連する情報をできるだけ多く取得できるようになっています!
SQLiteを使ったナレッジベース管理
RAGシステムの重要な部分として、SQLiteデータベースを使ったナレッジの管理があります!今回は軽量で扱いやすいSQLiteを選びましたが、その実装について簡単に紹介したいと思います!
def init_db():
try:
with DatabaseManager() as cursor:
cursor.execute('''
CREATE TABLE IF NOT EXISTS knowledge_sources (
id TEXT PRIMARY KEY,
filename TEXT NOT NULL,
created_at TEXT NOT NULL,
pdf_data BLOB
)
''')
cursor.execute('''
CREATE TABLE IF NOT EXISTS knowledge_chunks (
id TEXT PRIMARY KEY,
knowledge_id TEXT NOT NULL,
chunk_index INTEGER NOT NULL,
text_content TEXT NOT NULL,
FOREIGN KEY (knowledge_id) REFERENCES knowledge_sources (id) ON DELETE CASCADE
)
''')
cursor.execute('''
CREATE INDEX IF NOT EXISTS idx_knowledge_chunks_text
ON knowledge_chunks(text_content)
''')
except Exception as e:
logger.error(f"データベースエラー: {str(e)}")
traceback.print_exc()
raise
# 以下略
このように2つのテーブルを作成しています:
- knowledge_sources:PDFファイルの情報とデータを保存
- knowledge_chunks:PDFから抽出したテキストチャンクを保存
フロントエンドについて
フロントエンドはReactとTypeScriptを使用して、シンプルで使いやすいUIを作成しました!主な機能としては:
- PDFファイルのアップロード機能
- 登録済みのナレッジ一覧表示
- チャットインターフェース
これらを実装しています!
画面は「ナレッジ登録」と「チャットボット」の2つのタブで切り替えられるようにしました!
これによって、ナレッジの管理とチャットを簡単に行き来できます!
使ってみた!
ナレッジ登録
無事に表示されました!
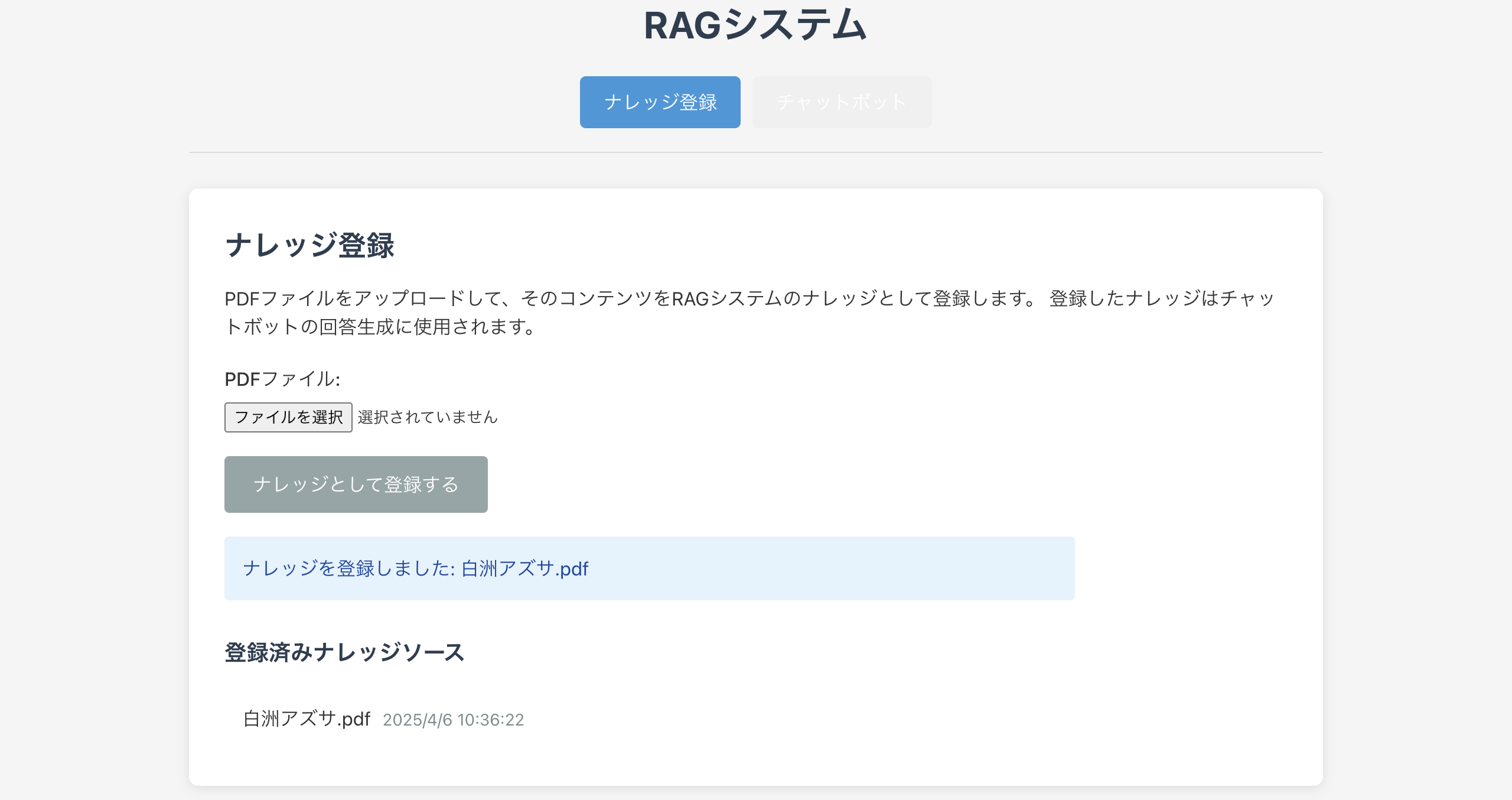
これで登録が完了です!
登録した日時が表示されてめっちゃ恥ずかしいですw
チャット
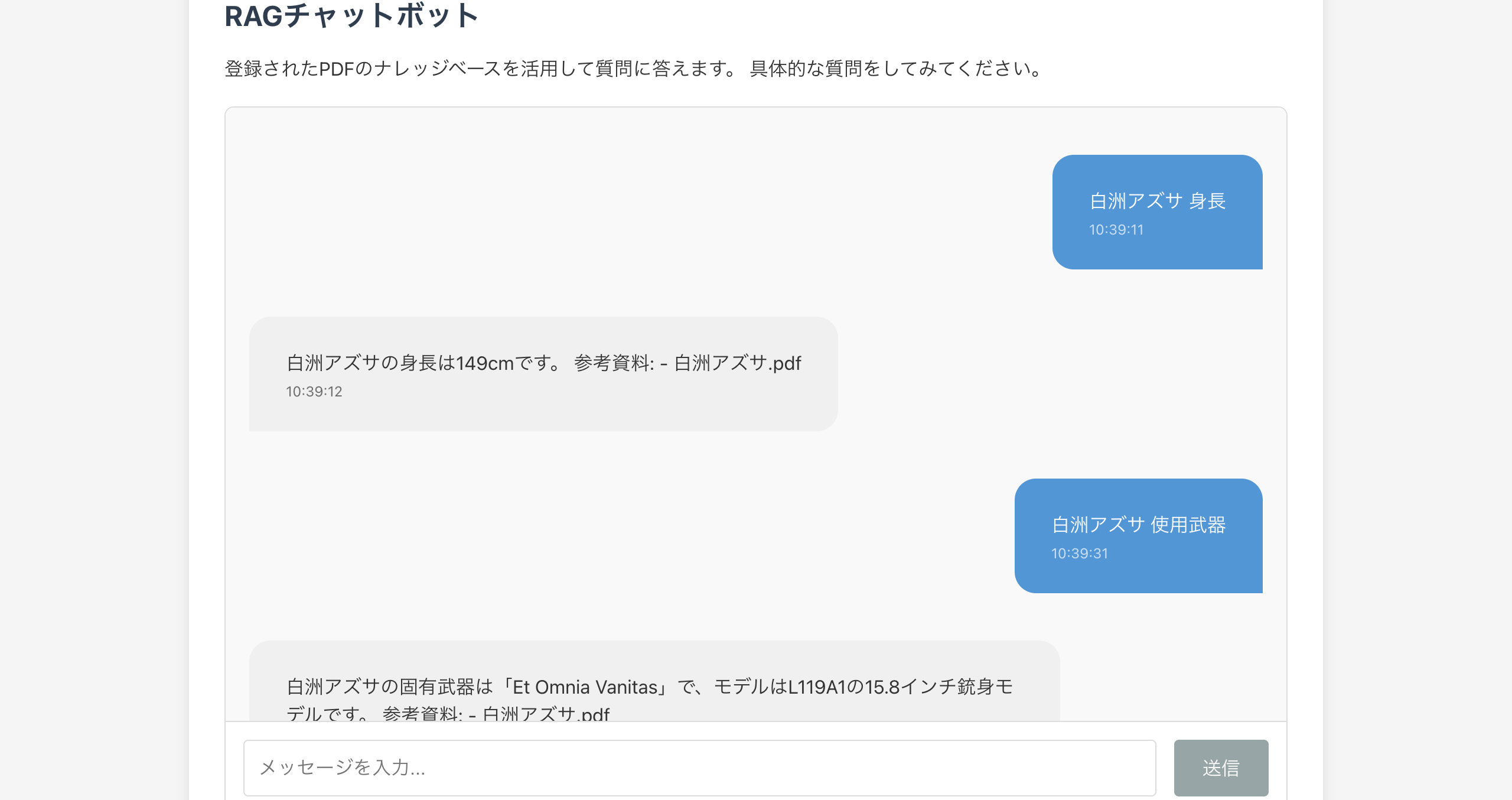

きちんと登録した通りの情報が返ってきました!
おわりに
今回はGeminiAPIを使ったRAGシステムを作ってみました!
この程度の情報なら意味がないため、わかりやすく魅力を伝えるために仮想のQ&Aドキュメントや会社情報を使わないといけなかったですがめんどくさかったので省略してしまいましたw
今後としては:
- ベクトル検索の実装
- チャンクサイズの最適化
- 複数のPDFを効率的に管理する機能
- より高度な検索アルゴリズムの導入
などがありいつか挑戦してみたいですね!
もし興味を持っていただけたら、この記事のいいねをいただけると嬉しいです!
またどこかの記事でお会いしましょう!