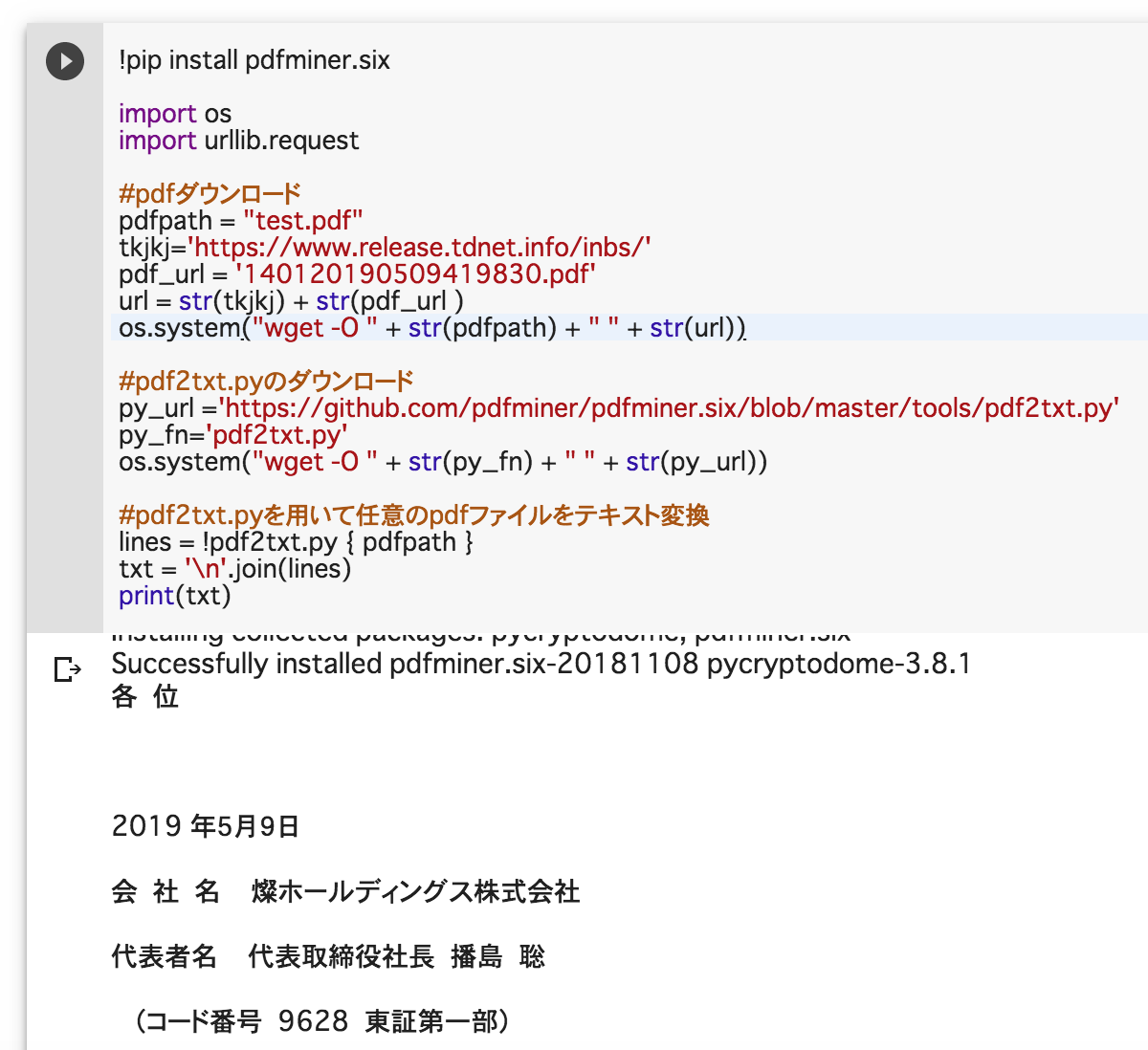
test.py
!pip install pdfminer.six
import os
import urllib.request
# pdfダウンロード
tkjkj='https://www.release.tdnet.info/inbs/'
pdf_url = '140120190509419830.pdf' #JPXの適時開示情報のページの開示資料pdf(サンプル)
url = str(tkjkj) + str(pdf_url )
pdfpath = "test.pdf"
os.system("wget -O " + str(pdfpath) + " " + str(url))
# pdf2txt.pyのダウンロード
py_url ='https://github.com/pdfminer/pdfminer.six/blob/master/tools/pdf2txt.py'
py_fn='pdf2txt.py'
os.system("wget -O " + str(py_fn) + " " + str(py_url))
# pdf2txt.pyを用いてpdfファイルをテキスト変換
lines = !pdf2txt.py { pdfpath }
txt = '\n'.join(lines)
print(txt)
前回JPXの適時開示情報のページを参照閲覧するスクリプトを書いたが、決算短信や業績予想の修正のリリースなどはXBRLファイルが付いているのでXBRLファイルを読み込んで値を取得する処理を施すとして、XBRLファイルの付いていないリリースをどうするか?ということで、今回はpythonのライブラリ「pdfminer.six」を利用してpdfファイル内の文章をテキスト情報に変換する方法を調べてみた。
pdfminer.sixには付属ファイルとして、pdf2txt.pyが付いているので、これを用いて読み込むpdfを指定すると、pdfファイルの中の文章を文字列に変換してくれる模様。
なおWeb上のpdfを指定すると、file not foundとエラーになるので、上記スクリプトでは一旦wgetコマンドでカレントディレクトリにpdfファイルをダウンロードしている。またgoogle colaboratory上で実行する場合は、githubのpdfminer.sixのページからwgetコマンドで、pdf2txt.pyをカレントディレクトリにダウンロードしている。
※google colaboratory上での実行イメージ↓