1.整形処理のスクリプト(改
前回の続き。上場会社全銘柄を1301から9997まで通しで実行して、金融庁に提出された有価証券報告書のXBRLファイル(feat.有報キャッチャー)から「従業員の状況」の箇所の文章を読み込んで保存したcsvファイルを元に、平均年間給与の数値等の抽出および整形を試みた。
以下は、前回のスクリプトを少し改良したもの↓
!pip install mojimoji
##########################
import pandas as pd
import requests
from bs4 import BeautifulSoup
import unicodedata
import re
import mojimoji
fn = 'emp1000.csv'
df = pd.read_csv(fn , header=None, error_bad_lines=False)
lst_f = []
def fn_modvle1(s):
ptn = '[\[[\(\(\)\)\〔\〕\)]'
if str(s).find('円')>-1:
# 単位の整形
s = re.sub(ptn ,"", str(s) )
s = s.strip()
s =str(s).replace('平均年間給与','')
if str(s).find('_')>-1: s = s.replace('_','',2).replace('\u3000','',2)
if str(s).find('、')>-1: s = s.replace('、','')
s = re.sub('[\u3000|\xa0|\n|,]' ,"", str(s) )
return s
def fn_modvle2(s):
if str(s).find('月')>-1:
if re.search(r'[年|才|歳]', str(s))is not None:
# 平均年齢と平均勤続年数の整形
s = mojimoji.zen_to_han( s )
obj = re.search(r'[年|才|歳]', str(s))
u = obj.start()
if u>0: v = s[u+1:]
if u>0: e = s[:u].strip()
v = re.sub('[ヵ|か|カ|ケ|ヶ|カ|ケ|月|年|才|歳]' ,"", str(v) )
####s = e
e,v = int(e), int(v)
w = e + round(v/12,1) #小数部分を10進法に変換
s = s +'/'+ str(w)
elif re.search(r'[年|才|歳]', str(s))is not None:
s = s +'/'+ re.sub('[年|才|歳]' ,"", str(s) )
return s
def fn_cleanse_emp(k):
lst , i = [] , 0
txt=df.iloc[k,3]
sic , ecode =df.iloc[k,1] , df.iloc[k,5]
ed , adrs =df.iloc[k,4] , df.iloc[k,6].replace('\n','_')
####emp_nc , emp_c =df.iloc[k,7] , df.iloc[k,8]
#
emp_nc =df.iloc[k,7]
pdf=df.iloc[k,2]
tds = []
soup = BeautifulSoup( txt ,"html.parser")
tbls = soup.find_all("table")
#「給与」の文字が記載されているテーブルの特定
for tbl in tbls:
if str(tbl).find('給与')>-1 and str(tbl).find('勤続')>-1:
tds = tbl.find_all("td")
l=len(tds)
if l>0:
for td in tds:
#「給与」の文字が記載されているtdタグの特定
if str(td).find('給与')>-1 :
u = 8 if l-i >=8 else l-i
#年間平均給与/平均勤続年数/平均年齢等の値の取得
for j in range(1,u):
f1 = tds[i+j].text
if f1.find('\n')>-1: f1=f1.replace('\n','')
if f1.find('\u3000')>-1: f1=f1.replace('\u3000','')
if f1.find('\xa0')>-1: f1=f1.replace('\xa0','')
if f1.find(',')>-1: f1=f1.replace(',','')
#print(f1 )
ecd=str(f1).encode('unicode-escape')
if str(ecd).find('3014')==-1 and str(f1).find('[')==-1 and str(f1).find('〔')==-1 and str(f1).find('(')==-1 :
if str(f1).find('(')==-1 and str(f1).find('[')==-1 :lst.append( fn_modvle2(f1))
#年間平均給与の単位をセット
f1=td.text.split('給与')[1]
if f1.find('円')>-1: f1=f1[:f1.find('円')+1]
f1=f1.replace('\n','')
#print(f1)
x = lst.append( fn_modvle1(f1) )
i=i+1
else:
x = [lst.append('nan') for j in range(3)]
#リストを左右逆転させる
lst=list(reversed(lst))
if len(lst)<4: lst.insert(2,'')
if lst[0]=='' and lst[1].find('円')>-1: lst[0]=re.sub('[0-9]','',lst[1])
if lst[1].find('円')>-1: lst[1]=re.sub('[^0-9]','',lst[1])
#lst_f = [k,sic ,ed,pdf, emp_nc,emp_c,fn_modvle1( adrs ) ] + lst
lst_f = [k,sic ,ed,pdf, emp_nc, fn_modvle1( adrs ) ] + lst
if lst_f[-1]==emp_nc :lst_f[-1] =''
print(lst_f)
# main
if __name__ == '__main__':
st,ed=0 ,len(df) #rec_id
#fn_cleanse_emp( 1089 ) #レコードIDを指定
x=[fn_cleanse_emp(k) for k in range(st ,ed)]
上記スクリプトの実行結果↓
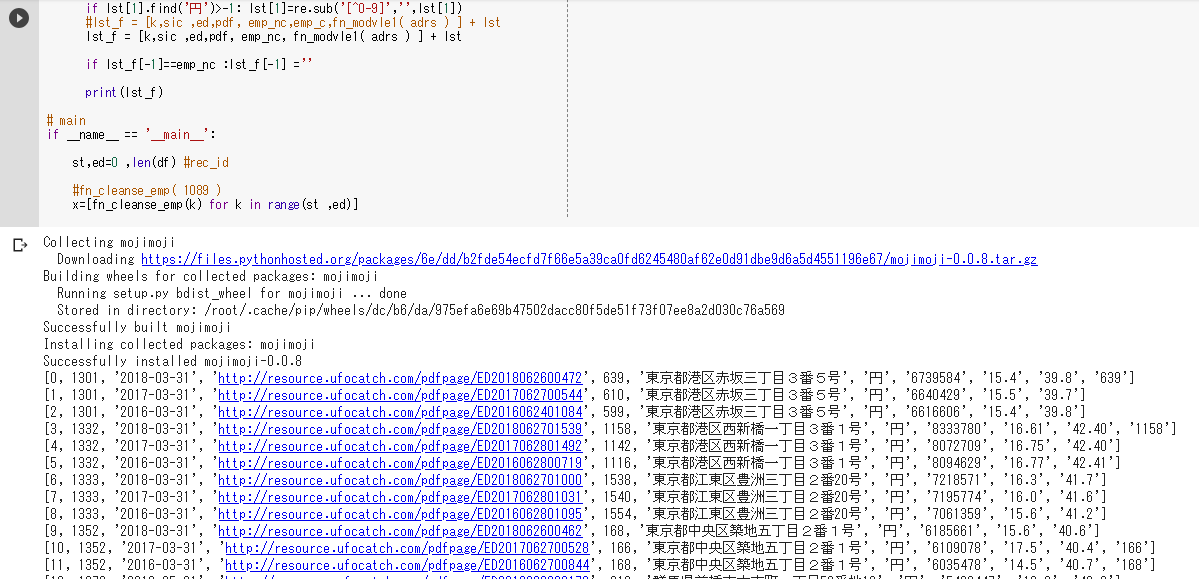
※Google Colaboratoryで上記スクリプトを実行
上記スクリプトの前回からの主な修正点↓
・臨時従業員の数値は今回は不要なので、カッコの含まれている項目はappend()で取得しないようにした。
・平均年間給与の単位(円、千円、百万円)の前後のカッコは不要なので、append()で取得する際に別途ファンクションfn_modvleX()にて除去処理をしている。
・平均年齢と平均勤続年数は、「○○年XXヶ月」であったり「「○○歳XXカ月」というような表記があるので、漢字部分を除去しつつ、小数点の部分を抽出して、12進法表記を10進法に変換(12で割る)した上で、小数表記(XX.X)に直している(上記では変換が妥当かどうか確認するために、置き換えではなく追記している)
・平均年齢と平均勤続年数の12進法表記の「XXヶ月」は、いろんなパターンがあって、「1ヶ月」「1ヵ月」「1か月」「1カ月」「1ケ月」「1カ月」「1ケ月」、それと「1月」などの表記が見られた。これらはパターンが多いので、正規表現でsub()で一括除去している。
・文字列検索(find()とsearch())と文字列置換(replace()とsub())を雑然と実行していて、まだまだ洗練されていないのは自分でも承知していて、もっときれいに文字列検索と文字列置換ができるはず。
・文字列検索と文字列置換の関数を色々と試してみて分かったのは、正規表現との関係性は以下のイメージかと↓
| 文字列検索 | 文字列置換 | 正規表現利用可能有無 |
|---|---|---|
| find() | replace() | できない |
| search() | sub() | できる |
・python初心者の自分にとってはfind()とreplace()がパッと頭に浮かび、思わずreplace()を多用しがちなのだが、正規表現が使えるsearch()とsub()を使いこなせるようになると、上記スクリプトはもっとすっきりした記述になるかと思われ。 |
||
| ・平均年間給与の単位の部分が''もしくは'円'となっていて、平均年間給与の数値が「5000000円」となっているレコードがあるので、リストで平均年間給与の単位と平均年間給与の額を確認して、平均年間給与の額の箇所に記載のある単位を平均年間給与の単位の箇所に再セットして、平均年間給与の箇所に記載のある単位は除去している。 | ||
| ・連結従業員数の項目は今回は割愛した。最悪バフェット・コードで従業員数は閲覧取得できるので、今回は平均年間給与と平均勤続年数、平均年齢に注力。 | ||
| ・有価証券報告書の提出者の最寄りの連絡場所(≒本社住所)は、本社住所を移転しました的な文章を載せているケースが数件確認できた。一応邪魔にならないように「、」を除去している。 |
2.従業員の表の様式についての特殊?なパターン例(抜粋)
(1)従業員の表がないケース
例)2702:日本マクドナルドHD
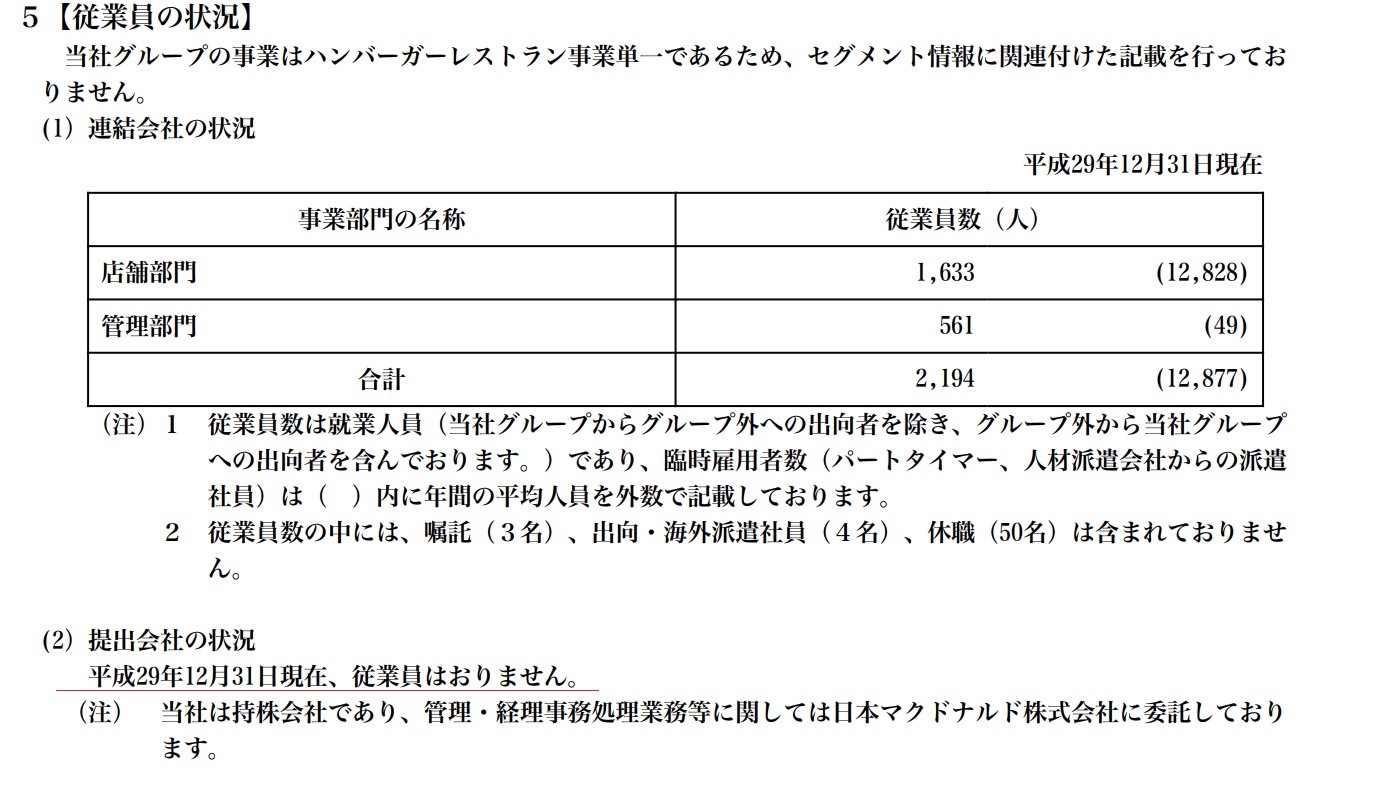
持株会社で従業員がいなくて、数値の記載がないケースはありますよね。(実際の持株会社の総務や経理部門の処理はホールディングス子会社の総務部門や経理部門にかけもちで処理させて、持株会社は役員のみ置いて従業員置かない的なイメージ?)
上記スクリプトでは、tableのtdタブをbeautifulsoupで読みこんで取得が0件でなかった場合のみ整形処理をするようにして、0件の場合は処理しないようにした。
(2)従業員の表が変則的のケース
a)従業員の表にセグメントの名称の列があるパターン
例)5013:ユシロ化学工業_2018年3月期有報
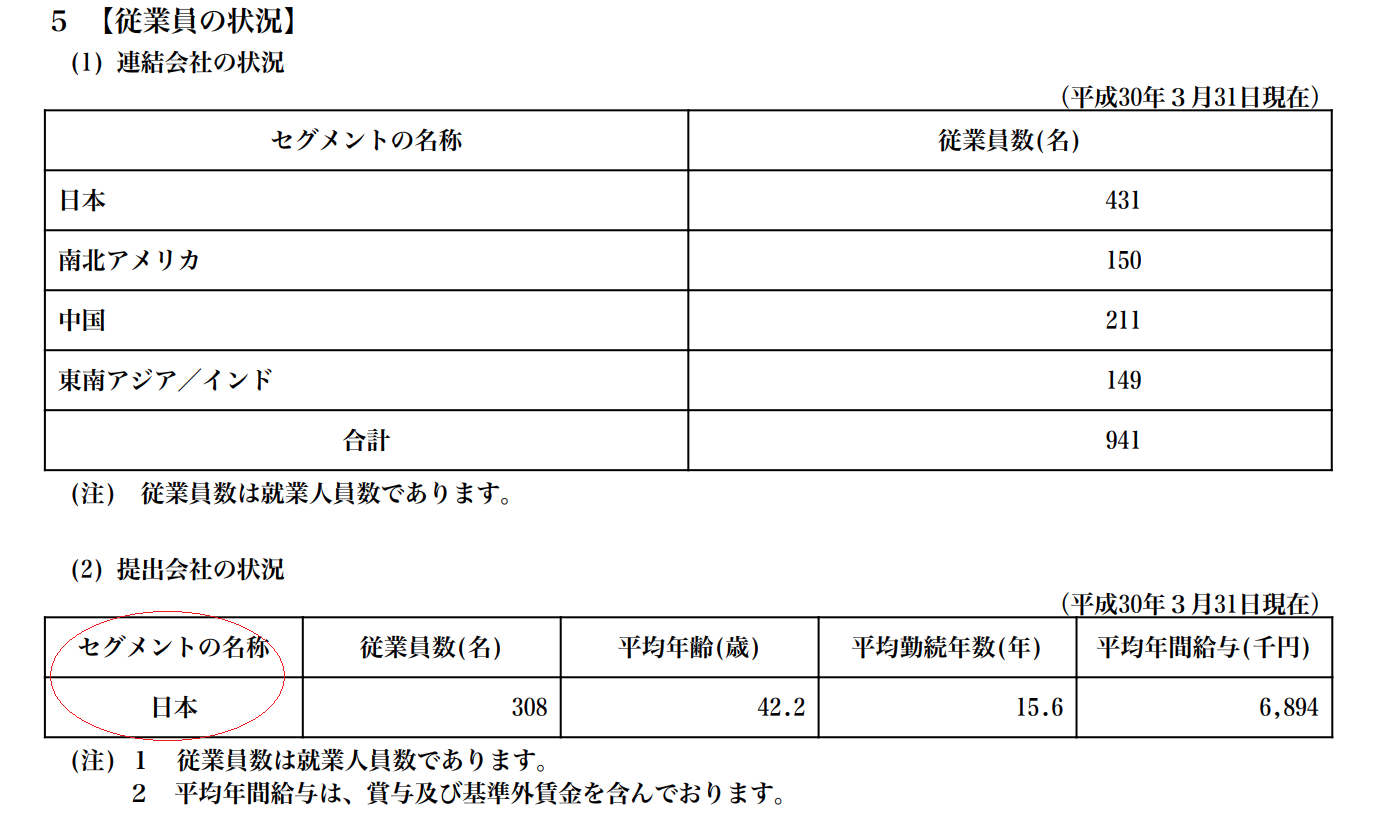
その会社の主要なセグメント、もしくは主要な地域(日本)における項目を記載しているパターン。このパターンの会社は他にも何社かあったのだけれども、上記のスクリプトでは普通に項目の取得はできる。が、主要なセグメントや地域の記載であって全社の項目値ではないので、値をどう扱うかは要検討。
b)縦形式の表で記載しているパターン
例)7267:ホンダ_2018年3月期有報
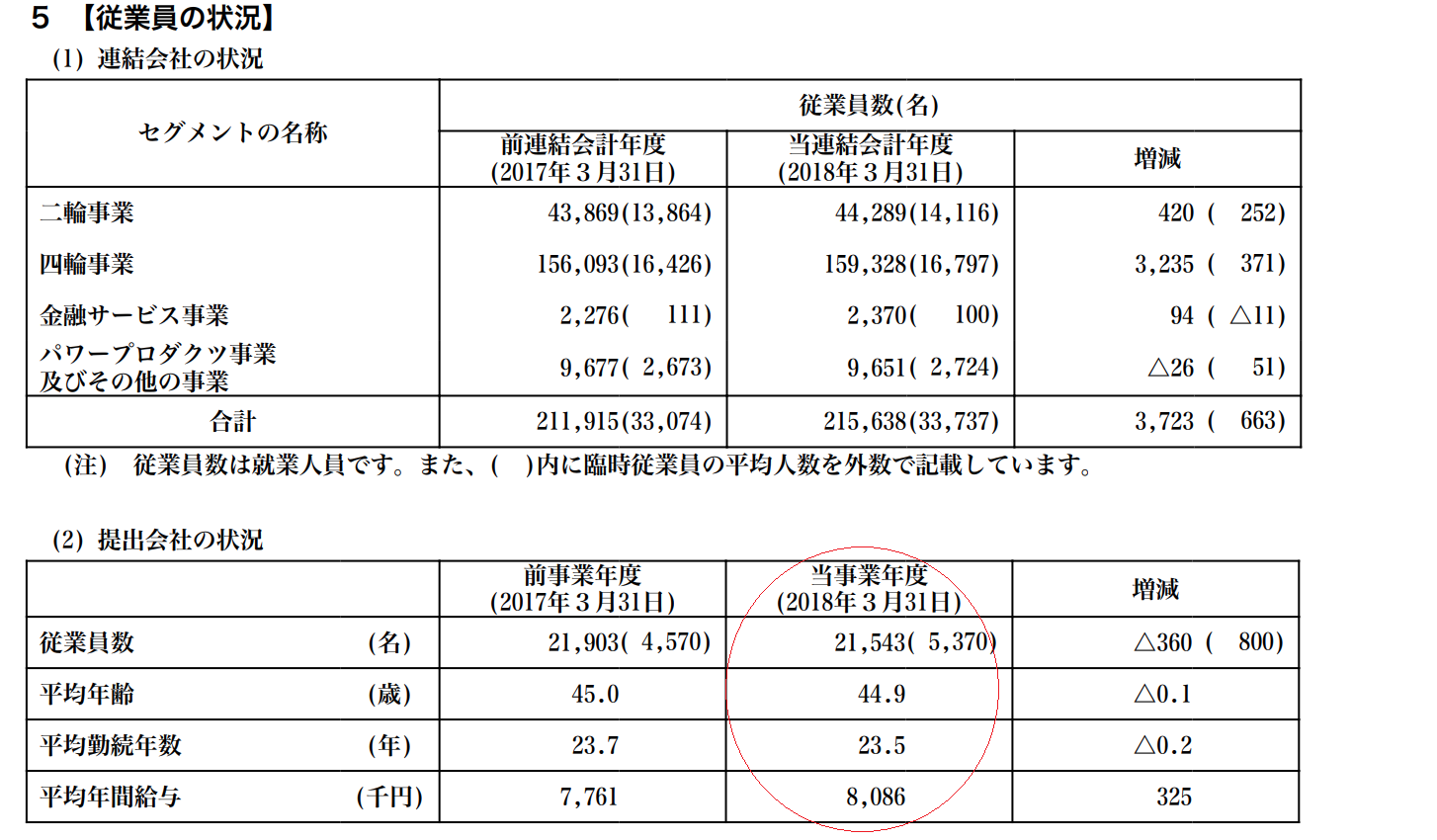
前年度と今年度の数値を表現するために縦形式の表で従業員数等を記載しているパターン。これは上記のスクリプトでは想定外なので、狙った項目を取得できない。ただ縦形式の表で記載している会社は、ホンダ以外なかったので、後で有報のpdf見て追記修正するでもいいかも。
c)平均年齢と平均勤続年数が整数部分と小数点部分と列が分離しているパターン
例)4912:ライオン_2017年12月期有報

平均年齢と平均勤続年数の項目で、整数部分(歳/年)と小数点部分(月)が別の列になっているパターン。
さもありなむ。
(5)複数の項目・分類に分けて記載しているケース
部署毎だったり、複数の事業毎だったり、雇用体系の異なる職種毎だったりと、複数に分けて表記しているパターン。上記スクリプトを実行すると、日本語の項目をそのまま取得しに行くので気づくのだが、こういうパターンは上記スクリプトでは処理できないので、後で人間が有報pdfを見て再確認する必要がある。
抜粋してみたところ以下のような会社が分類分けをして複数表記している模様。(そんな多い訳ではない)↓
| 証券コード | 社名 | memo |
|---|---|---|
| 1380 | 秋川牧園 | 「月給社員」と「日給社員」 |
| 1381 | アクシーズ | 「社員」と「従業員」 |
| 2162 | NMSホールディングス | 「一般社員」と「合計又は平均」 |
| 2398 | ツクイ | 「常勤従業員」と「非常勤従業員」と「合計」 |
| 2406 | アルテサロンHD | 「本部」と「合計」 |
| 2427 | アウトソーシング | 「内勤社員」と「外勤社員」と「合計又は平均」 |
| 2831 | はごろもフーズ | 「職員」と「月業員」と「合計又は平均」 |
| 4290 | プレステージ・インターナショナル | 「社員」と「地域限定社員」と「契約社員」 |
| 7181 | かんぽ生命保険 | 「内務職員」と「営業職員」 |
| 7211 | 三菱自動車工業 | 「事務技術系」と「技能系」 |
| 7270 | SUBARU | 「男性」と「女性」と「合計」 ※2018年3月期 |
| 8377 | ほくほくフィナンシャルG | HDと傘下子会社銀行の2表あり |
| 9009 | 京成電鉄 | 従業員数の列が「運輸」「不動産」「全社共通」「合計」の4列あり |
| 9104 | 商船三井 | 「陸上従業員」と「海上従業員」と「合計」 |
| 9127 | 玉井商船 | 「陸上従業員」と「海上従業員」と「合計」 |
| 9206 | スターフライヤー | 「一般従業員」と「運航乗務員」と「客室乗務員」 |
| 9962 | ミスミグループ本社 | 「正社員」と「有期雇用社員」 |
(6)外国会社など
9399:ビートホールディングス・リミテッド(旧新華ファイナンス)
→ 有報は提出している模様。だが従業員の項目がないので取得あたわず。
4875:メディシノバ・インク
→ 有報は提出している模様。だが、取得スクリプトがこの銘柄でエラーで止まった。
8421:信金中央金庫
→ 有報は提出している模様。信金中央金庫は、東証のエクセルファイルで、sectorCode列の値が「-」となっているので、銘柄一覧から除外されており、XBRLファイルを読みに行っていない。
8301:日本銀行
→ 有報キャッチャーでは検索すらできず。なお日本銀行は、東証のエクセルファイル上では、sectorCode列の値が「-」となっているので、銘柄一覧から除外されており、XBRLファイルを読みに行っていない。
バフェット・コードでもこれらの銘柄は対象外にしているので、まあ項目値が取得できなくても良しとしますか。
(5)記載ミスのパターン
2291:福留ハム_2016年3月期有報、平均年間給与の単位

「4,878百万円」って...自分もこれくらい(48億円)お給料欲しいものです(違
(6)従業員の表の数字が変則的なケース
a)3536:アクサスHD_2016年8月期有報、平均勤続年数

「4.3ヶ月」は「4年3ヶ月」とも「[4.3]ヶ月(≒4ヶ月ちょい)」ともどちらにも意味が取れる可能性が...一応経年比較すると翌年と翌々年が7年くらいなので、おそらく「4年3ヶ月」でしょうね。。。
b)4217:日立化成_2018年3月期有報
従業員の表の数値がすべて、全角数字(カンマや小数点もすべて全角)になっている。

...堪忍してつかぁさい(泣
ってか、全角を半角に直すためにライブラリ「mojimoji」を入れて変換かましているつもりだったのだけれども、変換できていないっすね。
(なお全項目を全角で表記しているのは、上場企業ではこの会社だけでしたです、はい)
3.pandasでmap()と無名関数lamba()を利用する
# pandasでmap()とlamba()を利用する練習
import pandas as pd
def fn_hoge(x):
return x*200
fn_test = lambda x: fn_hoge(x)
df1 = pd.DataFrame([['A','B','C'],[25,10,55],[40,15,-15]]).T
df2 = df1[1].map(fn_test)
df0 = pd.concat([df1,df2], axis=1)
# df[ df.columns[df.columns!='not_this_column'] ]
df0
今回はリスト内包表記でリスト内でforループを記述して、上から1レコードずつ値をfn_cleanse_emp()というファンクションを実行して整形処理をしているが、上記のスクリプト(test.py)のようにpandasのdataframeの各項目に対してmap()やapplymap()などの高階関数を使って、無名関数lamda()を介してfn_cleanse_emp()を実行する形でも処理は可能ですね。
(リスト内包表記で記述した後に、map()とlamda()を組み合わせた書き方があるのだということを発見したのと、今回扱うデータの量がそれほど多くないため処理速度がそれほど変わらなかったというのがあって、今回はリスト内包表記でループ処理をする書き方で通しました。次に機会があるときに、map()とlamda()を使った書き方を試してみようかと思います。)
#i=100
#fn_test = lambda x: fn_cleanse_emp2(x)
#df[2] = df[3].head(i).map(fn_test)
#df2 = pd.DataFrame(sr)
#x = df.head(i)
#print(x)
4.[おまけ]未上場で有価証券報告書を提出している会社の平均年間給与について
import pandas as pd
def fn_foo():
### 未上場の有報提出会社
df2 = pd.DataFrame([['E00738','E00718','E00699','E00698','E00697','E00169','E22559'
,'E00141','E04379','E04396','E00706','E25321','E04413','E21951']
,['日本経済新聞社','朝日新聞社','東洋経済新聞社','神戸新聞社','西日本新聞社'
,'竹中工務店','サントリーHD','鴻池組','毎日放送','山陽放送'
,'毎日新聞社','毎日新聞GH','東海テレビ','商工中金'
]]).T
print( df2 )
fn_foo()
有報キャッチャーは上場会社以外の未上場会社でEDINETに書類提出している会社も検索可能なので、未上場会社で有価証券報告書を提出している会社を抜粋(主に平均年収の高そうな規制産業?のマスメディアなどを狙い撃ち)してスクリプトを実行して、平均年間給与の値等の取得を試みた。
以下は、スクリプトを実行して取得したデータ↓
| 会社名 | Edinetコード | 決算期末 | 従業員数(単独) | 従業員数(連結) | 本社住所 | 単位 | 平均年間給与 | 平均年齢 | 平均勤続年数 |
|---|---|---|---|---|---|---|---|---|---|
| 日本経済新聞社 | E00738 | 2017-12-31 | 2497 | 9406 | 東京都千代田区大手町一丁目3番7号 | 円 | 12216296 | 19年2ヵ月/19.2 | 43歳5ヵ月/43.4 |
| 日本経済新聞社 | E00738 | 2016-12-31 | 2518 | 9413 | 東京都千代田区大手町一丁目3番7号 | 円 | 12549431 | 19年3ヶ月/19.2 | 43歳4ヶ月/43.3 |
| 日本経済新聞社 | E00738 | 2015-12-31 | 2500 | 9411 | 東京都千代田区大手町一丁目3番7号 | 円 | 12626731 | 19年1ヶ月/19.1 | 43歳2ヶ月/43.2 |
| 朝日新聞社 | E00718 | 2018-03-31 | 3933 | 7449 | 東京都中央区築地五丁目3番2号 | 円 | 12082396 | 20.5 | 44.7 |
| 朝日新聞社 | E00718 | 2017-03-31 | 3948 | 7371 | 東京都中央区築地五丁目3番2号 | 円 | 12139686 | 20.2 | 44.4 |
| 朝日新聞社 | E00718 | 2016-03-31 | 4178 | 7605 | 東京都中央区築地五丁目3番2号 | 円 | 12442844 | 20.2 | 44.3 |
| 東洋経済新聞社 | E00699 | 2017-09-30 | 274 | None | 東京都中央区日本橋本石町一丁目2番1号 | 円 | 11736340 | 16.3 | 43.6 |
| 東洋経済新聞社 | E00699 | 2016-09-30 | 269 | None | 東京都中央区日本橋本石町一丁目2番1号 | 円 | 11835523 | 16.4 | 44.0 |
| 神戸新聞社 | E00698 | 2017-11-30 | 485 | 1355 | 神戸市中央区東川崎町一丁目5番7号 | 千円 | 7742 | 18.7 | 43.8 |
| 神戸新聞社 | E00698 | 2016-11-30 | 486 | 1363 | 神戸市中央区東川崎町一丁目5番7号 | 千円 | 7672 | 18.0 | 43.6 |
| 神戸新聞社 | E00698 | 2015-11-30 | 480 | 1345 | 神戸市中央区東川崎町一丁目5番7号 | 千円 | 7570 | 17.5 | 43.2 |
| 西日本新聞社 | E00697 | 2018-03-31 | 667 | 1548 | 福岡市中央区天神一丁目4番1号 | 円 | 8864719 | 18.13 | 45.54 |
| 西日本新聞社 | E00697 | 2017-03-31 | 719 | 1600 | 福岡市中央区天神一丁目4番1号 | 円 | 8740882 | 17.51 | 45.21 |
| 西日本新聞社 | E00697 | 2016-03-31 | 742 | 1623 | 福岡市中央区天神一丁目4番1号 | 円 | 8616920 | 17.26 | 44.72 |
| 竹中工務店 | E00169 | 2017-12-31 | 7400 | 12982 | 大阪市中央区本町四丁目1番13号 | 円 | 10013993 | 19.2 | 44.0 |
| 竹中工務店 | E00169 | 2016-12-31 | 7307 | 12592 | 大阪市中央区本町四丁目1番13号 | 円 | 9569442 | 19.6 | 44.3 |
| 竹中工務店 | E00169 | 2015-12-31 | 7195 | 12328 | 大阪市中央区本町四丁目1番13号 | 円 | 9211209 | 19.8 | 44.4 |
| サントリーHD | E22559 | 2017-12-31 | 449 | 37745 | 大阪市北区堂島浜二丁目1番40号 | 円 | 11266704 | 18.2 | 43.4 |
| サントリーHD | E22559 | 2016-12-31 | 438 | 38013 | 大阪市北区堂島浜二丁目1番40号 | 円 | 10657132 | 17.9 | 43.0 |
| サントリーHD | E22559 | 2015-12-31 | 442 | 42081 | 大阪市北区堂島浜二丁目1番40号 | 円 | 10407404 | 17.6 | 42.8 |
| MBSメディアホールディングス | E04379 | 2017-03-31 | 627 | 906 | 大阪市北区茶屋町17番1号 | 千円 | 13448 | 19.3 | 43.7 |
| MBSメディアホールディングス | E04379 | 2016-03-31 | 636 | 907 | 大阪市北区茶屋町17番1号 | 千円 | 13211 | 19.1 | 43.6 |
| 山陽放送 | E04396 | 2018-03-31 | 144 | 268 | 岡山市北区丸の内二丁目1番3号 | 千円 | 8760 | 17.0 | 43.0 |
| 山陽放送 | E04396 | 2017-03-31 | 149 | 268 | 岡山市北区丸の内二丁目1番3号 | 千円 | 8493 | 17.1 | 43.5 |
| 山陽放送 | E04396 | 2016-03-31 | 143 | 260 | 岡山市北区丸の内二丁目1番3号 | 千円 | 8595 | 17.4 | 43.9 |
| 商工中金 | E21951 | 2018-03-31 | 3765 | 4083 | 東京都中央区八重洲二丁目10番17号 | 千円 | 7830 | 16.4 | 39.3 |
| 商工中金 | E21951 | 2017-03-31 | 3753 | 4080 | 東京都中央区八重洲二丁目10番17号 | 千円 | 7879 | 16.4 | 39.3 |
| 商工中金 | E21951 | 2016-03-31 | 3773 | 4102 | 東京都中央区八重洲二丁目10番17号 | 千円 | 7900 | 16.8 | 39.7 |
鴻池組や東海テレビなど一部取得できない銘柄があったが、これら銘柄は以前に金融庁に書類を提出していてEDINETコードは付与されているものの、最近は有価証券報告書を提出していないので取得できないというパターンで取れていないものである。あと毎日放送は、社名変更していて、現在はMBSメディアホールディングスとなっている模様。
それにしても平均年間給与、たかっ!(驚
某ネットメディアが「自分以外の会社員がどれだけお給料をもらっているのか知りたい」という人々の潜在的欲求につけ込んで?PV稼ぐ目的で頻繁に配信している年収ランキングの記事などは、上場企業限定でソーティングしているので、上場していない会社の年収はランキングには載らないのだが...
※例の年収ランキング記事のコメント欄↓
仮に上記のスクリプトで得られた未上場企業の年収データを、例の年収ランキング記事のランキング表に脳内で「UNION ALL」で連結して再ソーティングしてみると、例えば東京都トップ500社ランキングだと、このランキング記事を配信している運営会社や、東京の築地に本社がある某新聞社や大手町の経団連ビルの隣に本社がある某経済新聞社などは、確実に上位にランクインしますよね(白目