1.概要
pandasにはcsvやExcelファイル、あるいはリレーショナルデータベース(RDB)やGoogleのBigQueryなど各種データソースのデータ書き込み/読み込みを行うメソッドが用意されていて、例えばSQLServerなどのRDBMSのテーブルにデータを書き込みしたい場合は、pandasのto_sql()なるメソッドを使えば簡単にテーブルにデータ更新ができる訳だが。既にテーブルに格納したデータを2回目の更新処理の際に同じデータをテーブルに再度書き込みしようとした場合、データが重複してしまうのでそうした重複するデータに関してはテーブル書き込みをしないよう、テーブル上でデータが一意になる形でデータ更新をしたい場合に、pandasのto_sql()だとやや小回りが効かない感が否めない。さりとてreplaceモードでto_sql()を実行するわけにもいかなく...
ということで今回はpandasのto_sql()を使わずに、以下の流れでSQLServer上のテーブルに差分データのみ更新する方法について試作/考察してみた。
1:pythonにてpandasのdfデータフレームからelementTreeでXML文字列を生成・・・(1)
2:(1)のXML文字列を引数にしてSQLAlchemyでSQLServerのストアドプロシージャを実行
3:(1)のXML文字列をSQLServerのOPENXML関数で読み込んでデータ展開・・・(2)
4:(2)のデータを一時テーブル#tableに格納して、実テーブルとJOINして差分のみ更新
なおこの上記のイメージでデータ更新が可能なのは、MicrosoftのRDBMS製品であるSQLServerに標準で用意されているXML文字列を操作する機能であるOPENXML関数なるサポートがあることが前提であり、他のRDBMS製品では、OPENXML関数みたいなXML文字列を操作する機能があるのかないのか定かではないがどうなんでしょうか?(注:自分はMySQLやpostgresなどが詳しくないのであれだが、方向性としてはXML文字列をRDB上で簡単に操作する機能がMySQLやpostgresなどにもしあれば、それらの機能で代替できるのではないかなと、なんとなく思ったりしつつ...)
従ってこのイシューはSQLServer限定で実装可能な方法である点をご留意していただきたく!
2.前半部分(python上でXML文字列を生成)
import pandas as pd
import xml.etree.ElementTree as ET
# サンプルデータ
lei = ['353800PIEETYXIDK6K51','5493006W3QUS5LMH6R84','not found']
cname = ['トヨタ自動車','極洋','さくらインターネット']
isin = [' JP3633400001' , 'JP3257200000','JP3317300006']
sic =['7203','1301','3778']
# df生成
Pythondata={'sic': sic, 'isin': isin, 'cname': cname ,'lei': lei }
df = pd.DataFrame(data)
columns = ['sic', 'isin', 'cname', 'lei' ]
df.columns = columns
print(df)
# XML文字列の生成
roots = ET.Element('root')
for i in range(len(df)):
f0 = ET.SubElement(roots, 'sb')
f1 = ET.SubElement(f0, 'hoge')
f1.set('sic', df.iloc[i,0])
f1.set('isin', df.iloc[i,1])
f1.set('cname', df.iloc[i,2])
f1.set('lei', df.iloc[i,3])
tree = ET.tostring(roots)
tree = tree.decode()
tree = "'" + tree + "'"
print(tree)
まず上記のサンプルデータ3件(トヨタ自動車、極洋、さくらインターネット)は、JPX東証のページからコード等を調べた。またLEIのコードはGLEIFのページで調べた。
上記のpythonコードを実行すると、まずpandasデータフレームdfが生成され、そのdfからXML文字列を生成する。上記ではXMLオブジェクトを生成して操作するためのpythonモジュールelementTreeを利用して、XMLオブジェクトを生成して、rootタグから逐次XMLタグ(正確にはXMLの属性情報)をforループで追加している。
以下は上記のサンプルpythonコードの実行結果↓

※ 簡易的にGoogle Colabratoryでスクショ取ったが、実際は後述するSQLServerにデータを更新する処理が後続にあるので、Google Colabratoryではなく、利用するSQLServerにアクセスできる環境のpython実行環境にてスクリプトを実行するべし!
上記のサンプルpythonコードで生成したXML文字列は以下の通り↓
'<root><sb><hoge cname="トヨタ自動車" isin=" JP3633400001" lei="353800PIEETYXIDK6K51" sic="7203" /></sb><sb><hoge cname="極洋" isin="JP3257200000" lei="5493006W3QUS5LMH6R84" sic="1301" /></sb><sb><hoge cname="さくらインターネット" isin="JP3317300006" lei="not found" sic="3778" /></sb></root>'
XML文字列をもう少し可読性を上げて改行して記述すると、以下のようなXML構造となる↓
'<root>
<sb>
<hoge cname="トヨタ自動車" isin="JP3633400001" lei="353800PIEETYXIDK6K51" sic="7203" />
</sb>
<sb>
<hoge cname="極洋" isin="JP3257200000" lei="5493006W3QUS5LMH6R84" sic="1301" />
</sb>
<sb>
<hoge cname="さくらインターネット" isin="JP3317300006" lei="not found" sic="3778" />
</sb>
</root>'
上記のXMLでは、要素(element)で定義するのではなく、属性(attribute)で定義をしている。これは後述のSQLServerのOPENXML関数でXMLを読み込むときの仕様に基づいて属性(attribute)で定義付けを行なっている。あとはXML文字列を生成するときに、NULL(NaN/None)をどう処理するかがキモになるのかなと。pandasで扱うデータで欠損値は当然出てくると思うが、その際NULL(NaN/None)のたぐいは、XMLの文字列で定義付けする際に上手く扱えないので、何かしらの文字列を付与してあげるとかの回避策を考える必要がある。
(例えば上記のサンプルでは、1301極洋と7203トヨタ自動車はLEIのコードを保有しているが、一方の3778さくらインターネットはLEIのコードを持っていなくて、XML文字列を生成するために無理やりNULLのデータを「not found」などの文字に無理やり変換して、後述のSQLServerでのOPENXML関数での読み込み後にそれらを上手に対応するなどが必要かと。ここは改良の余地あり)
3.後半部分(SQLServer上でOPENXML関数でXML文字列からデータを読み込み/組成)
DECLARE @idoc INT
DECLARE @xml AS NVARCHAR(MAX)
SET @xml = '<root><sb><hoge cname="トヨタ自動車" isin=" JP3633400001" lei="353800PIEETYXIDK6K51" sic="7203" /></sb><sb><hoge cname="極洋" isin="JP3257200000" lei="5493006W3QUS5LMH6R84" sic="1301" /></sb><sb><hoge cname="さくらインターネット" isin="JP3317300006" lei="not found" sic="3778" /></sb></root>'
--SELECT @xml
DROP TABLE IF EXISTS #temp;
EXEC sp_xml_preparedocument @idoc OUTPUT, @xml;
SELECT *
INTO #temp
FROM OPENXML(@idoc, '/root/sb/hoge',1)
WITH (SIC varchar(50) './@sic'
, ISIN varchar(50) './@isin'
, CNAME varchar(50) './@cname'
, LEI varchar(50) './@lei'
);
SELECT *
FROM #temp;
DROP TABLE IF EXISTS #temp;
上記のSQLクエリーの実行結果↓
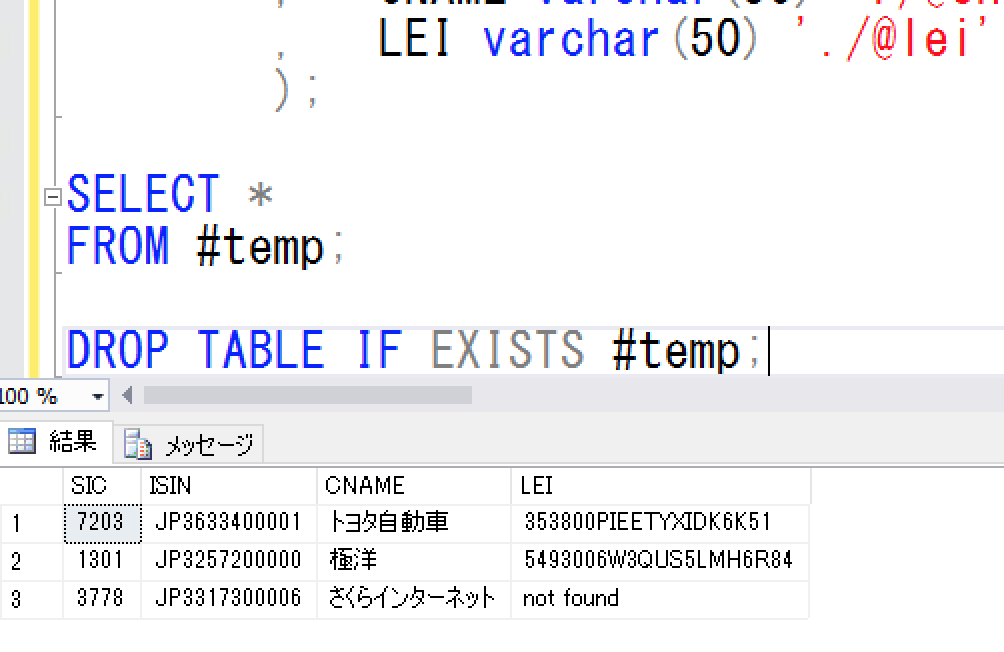
SQLServerにはOPENXML関数というXML文字列を操作する機能が標準装備でサポートしており、このOPENXML関数を用いて、上記のpythonで生成したXML文字列をSQLで操作可能な状態のデータにした上で、一時テーブル#tempにデータを格納(SELECT * INTO〜句)してあげれば、あとはその#tempと格納先テーブルをJOINして、まだ格納先テーブルに存在していない#tempのレコードを差分レコードとして格納先テーブルにInsert処理するトランザクションクエリーを記述してあげれば、データの一意性を担保しつつテーブルのデータ更新が実現できるのではないかと思われる。
なお前半部分で生成したXML文字列(のXMLの構造)と、後半のSQLのOPENXML関数で読み込む際のXMLの読み込み記述の箇所は完全に同一である必要があって、扱うXMLの構造は前半のXML文字列吐き出し部分と後半のXML読み込み部分が同じである必要があるので、ここが注意点であると思われる。(このSQLServerのOPENXML関数での読み込み部分でXML文字列が上手に読み込めない場合は、大抵XMLの記述の箇所で前半のpython上で生成した文字列と、SQLServer上でOPENXMLで読み込む箇所がシンクロしてない可能性がある)
4.SQLAlchemyでSQLServerのストアドプロシージャを実行
import sqlalchemy
# DB接続設定文字列
CONNECT_INFO = 'mssql+pyodbc://hoge' #hoge=ODBC名
engine = sqlalchemy.create_engine(CONNECT_INFO, encoding='utf-8')
# ...(中略)...
## DB更新
Session = sqlalchemy.orm.sessionmaker(bind=engine)
session = Session()
## ストアド実行
query = 'EXEC dbo.spUpdatehoge @prm = {0}'.format(tree)
res = session.execute(query) #sp実行
print(res.fetchall())
session.commit() #コミット
session.close()
SQLServerのストアドプロシージャをpython(のSQLAlchemy)で実行する際、上記クエリーのsession.execute(query)の箇所で、ストアドプロシージャを実行した戻り値(レスポンス)をpython上で取得して表示させたい場合、ストアドプロシージャ内ではReturn句ではなくSelect文で更新結果状態を返すようにすると、python上でストアド実行した結果が即分かるのではないかと思う。どうやらストアドプロシージャ内にてReturn句で返した結果を、SQLAlchemyのResultProxyオブジェクトは、上手く取得ができない模様。
今回記した更新方法は、前半部分のPythonスクリプトでXML文字列を生成する箇所と、後半部分のSQLServerでのストアドプロシージャ内のOPENXML処理の箇所と、処理の前半/後半とで分かれてしまっているので、ストアドプロシージャの処理結果(成功失敗有うんぬん)がPythonのSQLAlchemyで取得表示できると、安心できるのではないかなと思われ。