普段DBを活用してシステムを構築していると、仕様変更などのタイミングで、
- ストアドプロシージャに纏めたDB処理を変更する
- テーブルに新しいカラムを追加する
といった場面によく出くわします。ですがPythonやC#等のプログラミング言語と違い、SQLのバージョン管理は一般的ではなく、情報が出回っていません。
そしてDB管理では筆者はよくこういった事象に悩まされていました。
- 重要な処理が気付いたら変更されていたが、誰がどう変更したのか分からない
- ロールバックしようと思ったが、構成情報が残っていない/どこに戻ればいいか分からない
- テストDBサーバーから本番DBサーバーへのデプロイミス(ALTER TABLE漏れやINDEX、デフォルト値の設定忘れ等)
こういった問題を解消すべく、社内システムのDBのバージョン管理やデプロイの自動化方法などを少しばかり調査・検証をしたので情報共有します。ご参考あれ。
なお私は担当システムの都合上SQLServer専門ユーザーなので、他のDBサーバーの管理ツールの話は他の人にお任せします。((無責任
CLIツール「mssql-scripter」

mssql-scripterは、SQL Serverのスクリプト生成ツールです。
SQL Server Management Studio (SSMS) のコマンドライン版と考えることができ、データベースオブジェクト(テーブル、ビュー、ストアドプロシージャ、関数など)のスクリプトを簡単に生成するために使用できます。
使用方法
0.前提条件
pythonのインストールが必要です。
持っていない人はここからpythonをインストールしましょう。
https://www.python.org/downloads/
1.pipを使ってmssql-scripterをインストール
pip install mssql-scripter
pythonを入れていれば使えるパッケージ管理ツール「pip」を使ってインストールします。
インストールが完了すると、自動でコマンドが使えるようになります。
2.コマンドラインで実行する
例えば、
- サーバー名: MyServer
- DB名: MyDB
というDBの情報を取得するにはこのようなコマンドを実行します。
mssql-scripter -S MyServer -d MyDB -U sa -P your_password --file-per-object --output ./db
このコマンドを実行すると、カレントディレクトリ直下に「db」というフォルダが作成され、その中に以下の様にsqlファイルがオブジェクト毎に生成されます。
USE [MyDB]
GO
/****** Object: Table [dbo].[AppUsers] Script Date: 9/2/2024 *****/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[AppUsers](
[UserID] [int] IDENTITY(1,1) NOT NULL,
[UserName] [nvarchar](50) NOT NULL,
[LastLoginDate] [datetime] NULL,
PRIMARY KEY CLUSTERED
(
[UserID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
/****** Object: Default Constraint [DF_AppUsers_LastLoginDate] Script Date: 9/2/2024 *****/
ALTER TABLE [dbo].[AppUsers] ADD CONSTRAINT [DF_AppUsers_LastLoginDate] DEFAULT (getdate()) FOR [LastLoginDate]
GO
/****** Object: Index [IX_AppUsers_UserID] Script Date: 9/2/2024 *****/
CREATE NONCLUSTERED INDEX [IX_AppUsers_UserID] ON [dbo].[AppUsers]
(
[UserID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
/****** Object: Stored Procedure [dbo].[spGetAppUsers] Script Date: 9/2/2024 *****/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[spGetAppUsers]
@UserID INT
AS
BEGIN
SET NOCOUNT ON;
SELECT UserID, UserName, LastLoginDate
FROM dbo.AppUsers
WHERE UserID = @UserID
END
GO
このように、スキーマ名.オブジェクト名.種類.sqlというファイル形式で出力されます。
出力できるものは、
- テーブル(CREATE TABLE)
- ビュー(CREATE VIEW)
- ストアドプロシージャ(CREATE PROCEDURE)
- ユーザー定義関数(CREATE FUNCTION)
- ユーザー権限設定文
- データベース定義文
等様々です。大体これがあれば必要なバージョン管理はできそうですね。
また、オプションも豊富で、特定のオブジェクトのみをスクリプト化するためのフィルタリングオプションや、全て.sqlを1つのファイルに纏めて出力する事も出来ます。
詳しいオプションはこちらをご覧ください!
https://github.com/microsoft/mssql-scripter/blob/dev/doc/usage_guide.md
バージョン管理への活用
mssql-scripterはcliのため、自動化やci/cdとの相性が抜群です。
mssql-scripterを使ったバージョン管理をする一例を紹介します。
1.出力スクリプトの生成
SQLServer内にある各DBを一括出力するpythonスクリプトを作成します。
※言語は問いませんが、恐らくインタプリタ言語の方がやり易いと思います。
出力イメージ
scripts/
├── DB1/
│ ├── tables/
│ │ ├── Table1.sql
│ │ └── Table2.sql
│ ├── views/
│ │ ├── View1.sql
│ │ └── View2.sql
│ ├── procedures/
│ │ ├── Procedure1.sql
│ │ └── Procedure2.sql
│ ├── functions/
│ │ ├── Function1.sql
│ │ └── Function2.sql
│ └── triggers/
│ ├── Trigger1.sql
│ └── Trigger2.sql
├── DB2/
│ ├── tables/...
│ ├── views/...
│ ├── procedures/...
│ ├── functions/...
│ └── triggers/...
import os
import subprocess
import shutil
# データベース情報のリスト
databases = [
{"server": "localhost", "database": "DB1", "user": "sa", "password": "password1"},
{"server": "localhost", "database": "DB2", "user": "sa", "password": "password2"}
]
# 出力ディレクトリ
output_dir = "./scripts"
# オブジェクトの種類ごとのフォルダを作成する関数
def create_object_folders(base_dir):
object_types = ["tables", "views", "procedures", "functions", "triggers"]
for obj_type in object_types:
os.makedirs(os.path.join(base_dir, obj_type), exist_ok=True)
# ファイルをオブジェクトの種類ごとのフォルダに移動する関数
def move_files_to_folders(base_dir):
for file_name in os.listdir(base_dir):
if file_name.endswith(".sql"):
if "Table" in file_name:
shutil.move(os.path.join(base_dir, file_name), os.path.join(base_dir, "tables", file_name))
elif "View" in file_name:
shutil.move(os.path.join(base_dir, file_name), os.path.join(base_dir, "views", file_name))
elif "Procedure" in file_name:
shutil.move(os.path.join(base_dir, file_name), os.path.join(base_dir, "procedures", file_name))
elif "Function" in file_name:
shutil.move(os.path.join(base_dir, file_name), os.path.join(base_dir, "functions", file_name))
elif "Trigger" in file_name:
shutil.move(os.path.join(base_dir, file_name), os.path.join(base_dir, "triggers", file_name))
# 各データベースのスクリプトを生成
for db in databases:
db_output_dir = os.path.join(output_dir, db["database"])
create_object_folders(db_output_dir)
# mssql-scripterコマンドを構築
command = [
"mssql-scripter",
"-S", db["server"],
"-d", db["database"],
"-U", db["user"],
"-P", db["password"],
"--file-per-object",
"--output", db_output_dir
]
# スクリプトの生成を実行
subprocess.run(command)
# ファイルをオブジェクトの種類ごとのフォルダに移動
move_files_to_folders(db_output_dir)
print("スクリプトの生成が完了しました。")
2.DB変更後にコマンド実行
DBをSSMSやAzure Data Studio等で編集後に、ターミナルで以下のコマンドを叩きます。
python db_to_script.py
これにより、現在のDBの構成情報を全てローカルに取得してきます。
3.Gitを使って変更履歴を記録
先程の処理をGitリポジトリ上で行うことで、DBの差分管理をすることが出来ます。
コマンド実行後、git add, git commit, git pushを行い、リモートリポジトリに変更を記録します。
このようにGitを使う事で、今まで不明だった「誰が、いつ、どこを変更したか」が履歴に残るようになり、トレーサビリティが格段に向上します。
4.定期実行する
上げ忘れ等が怖い場合は先ほどのSQL出力スクリプト「db_to_script.py」を定期実行させちゃいましょう。私の職場ではGitLabを導入しているので、GitLabのCI/CD機能を使い、スケジュール登録で毎日深夜に実行されるようにしました。
これで万が一上げ忘れても変更履歴が残るので、自動+手動の両方で差分管理することで強力なバージョン管理が可能です。
5.SQL管理ツールと併用する
例えば、AzureDataStudioはDB管理、SQL実行、Git管理、ターミナルといった機能を持っているので、
- AzureDataStudioのソース管理ツールで、DB管理用のGitリポジトリを開く
- AzureDataStudioのDBツールで、テーブルやストアドを開発
- 変更後、ターミナルでSQL出力スクリプトを実行
- 取得した.sqlファイルを元にGitが変更点を自動取得
- ソース管理ツールでCommit&Push
をすることで、1つのツールでDB開発+ソース管理を行う事が可能です。
SQL実行
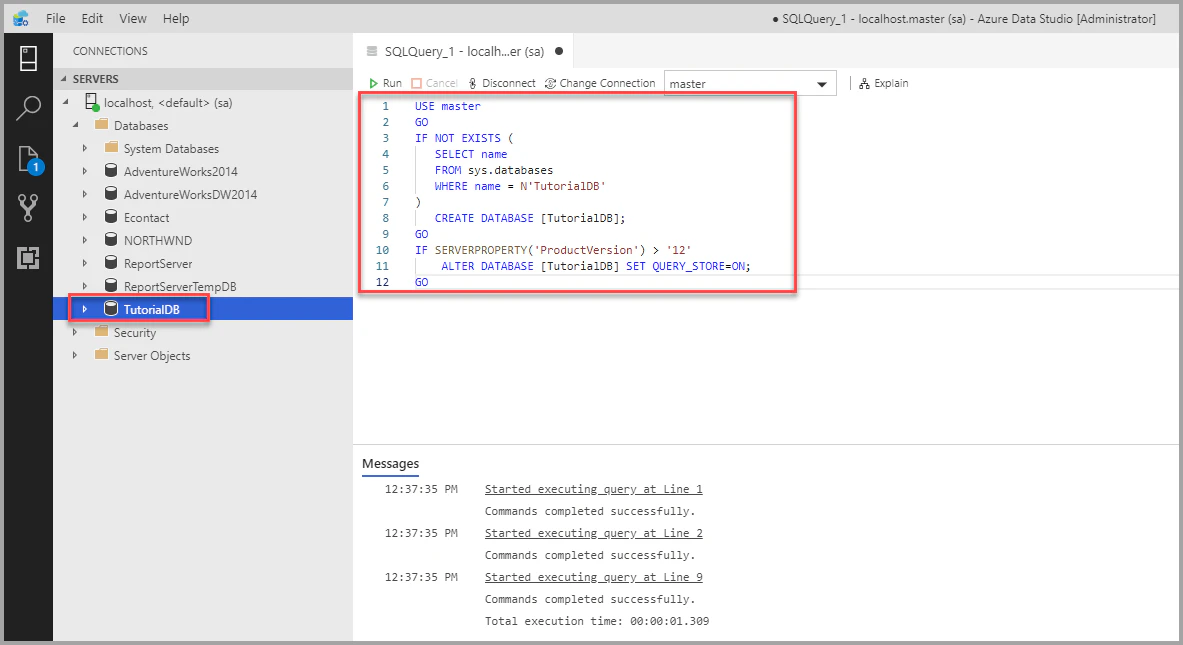
ソースコード管理
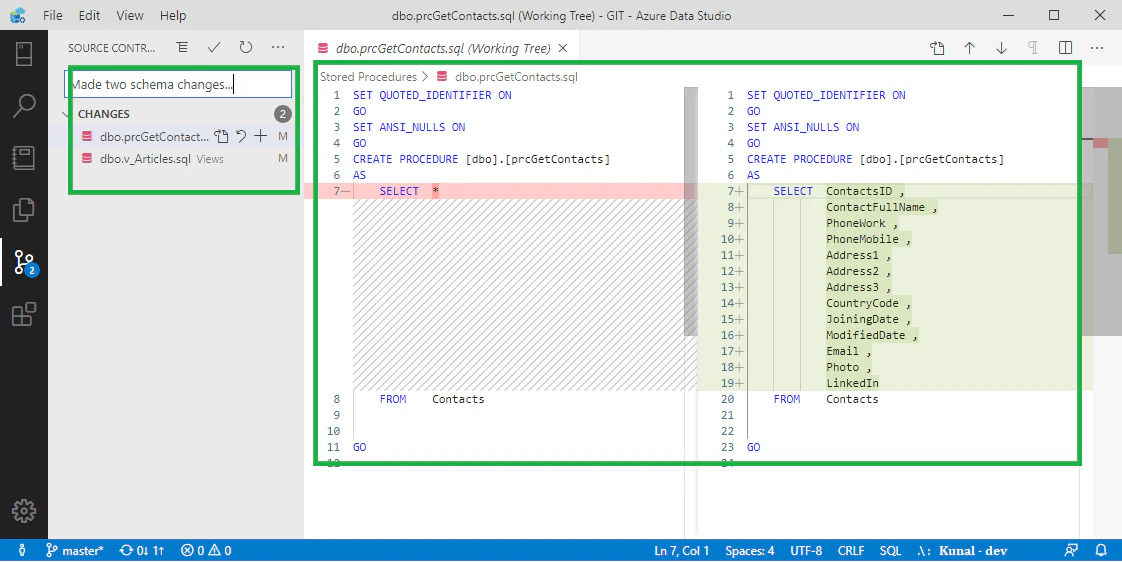
同様の事はVSCodeやVisualStudioでも可能ですが、扱いやすさ・軽さ的には最もAzureDataStudioが優れていると思います。(個人の感想です)
SSMSはGitツールがデフォルトで入っていないのがネックで、外部ツールに頼る必要がありそうです。
VisualStudio/Azure DataStudioの「DBプロジェクト」
先程のツールはあくまでもスクリプト出力に特化していましたが、
Visual StudioやAzure DataStudioには「DBプロジェクト」というものを作成・管理する機能があります。
これがどういう事が出来るかご紹介します。
1. データベーススキーマの管理
データベースプロジェクトでは、テーブル、ビュー、ストアドプロシージャなどのデータベースオブジェクトをソースコードとして管理できます。既存のデータベースからこれらのオブジェクトをプロジェクトにインポートしたり、新規に作成したりできます。
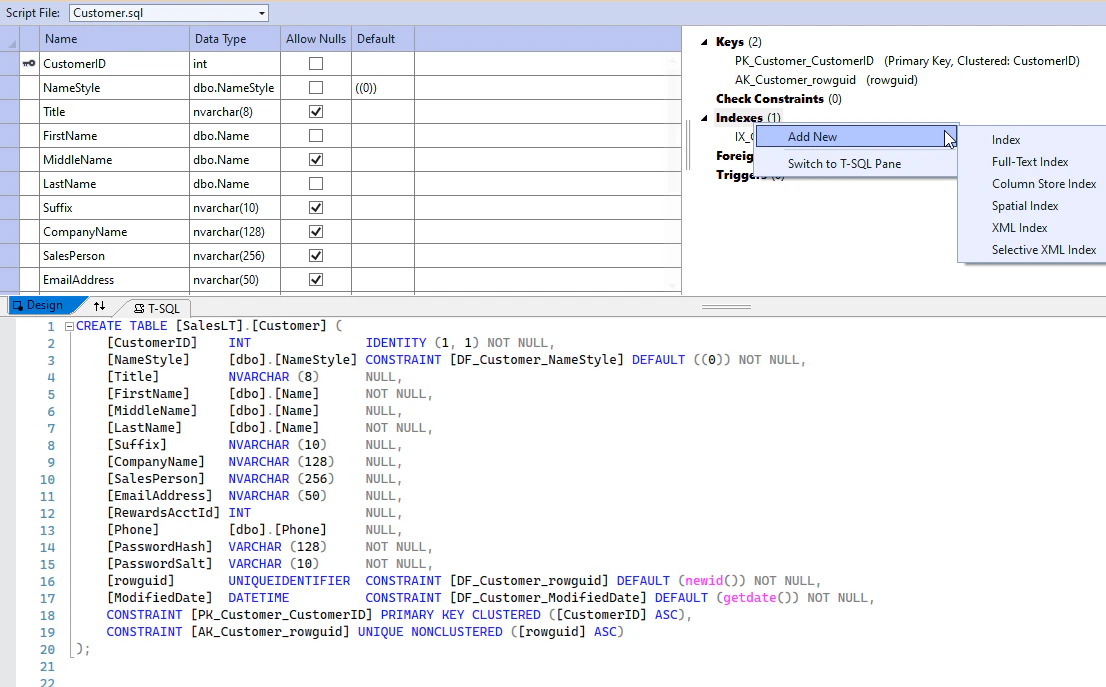
作成したプロジェクトはビルドするとDACPACファイルというものが生成され、これを使用してローカルDB(SQL Server LocalDBなど)にデプロイすることで、テスト環境として動作させることができます。
2. データベース同士の比較・デプロイ
ローカルサーバー、テストサーバー、本番サーバーなどのデータベース間で、スキーマの違いを比較し、一方のデータベースのスキーマをもう一方に反映するデプロイ処理を行うことができます。
VisualStudioの画面。「Update」を押すことで左から右へ構成が適用される。
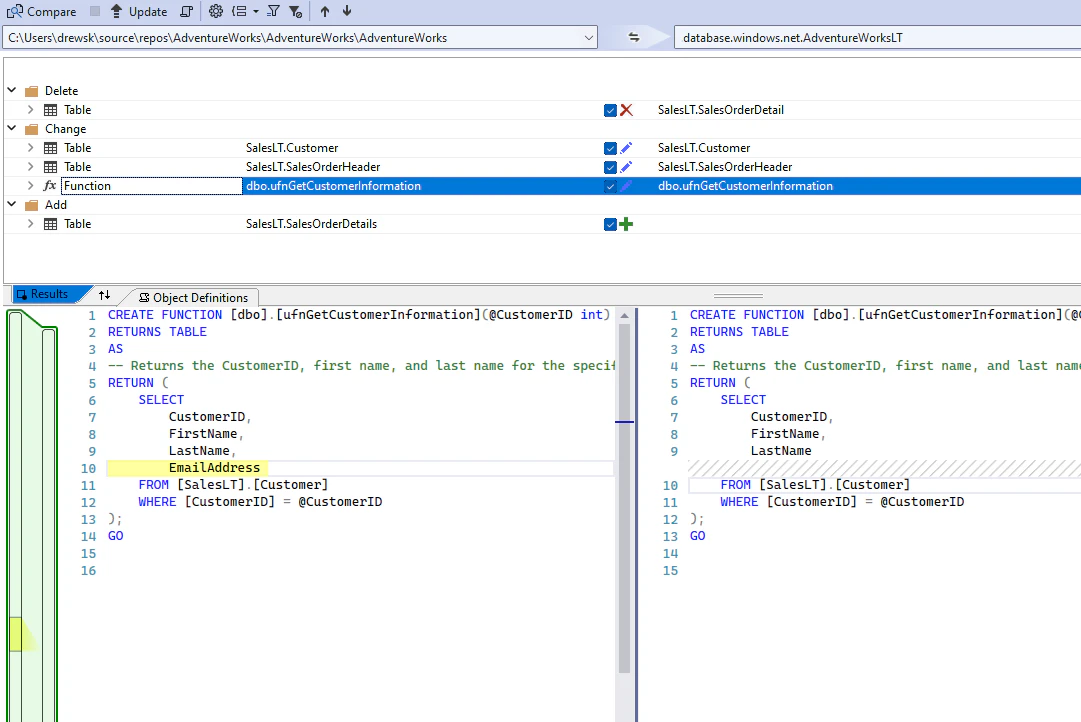
AzureDataStudioでも同様の機能がある。Applyを押すことで左から右へ構成が適用される。
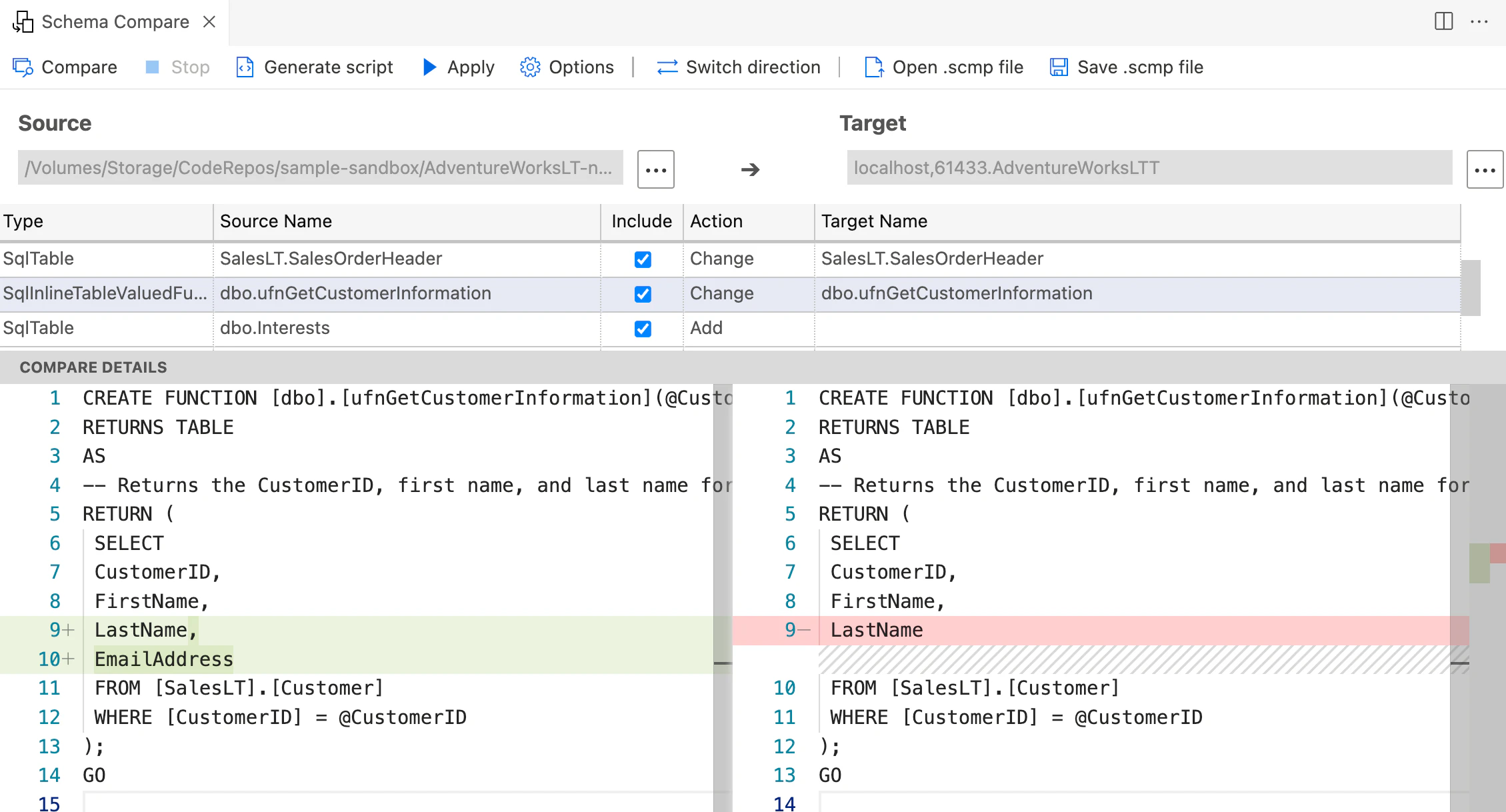
例えば、ローカルサーバーで新機能の検証をしており、新しくテーブルを追加したり、ストアドを変更したとします。
その際にローカルサーバーと本番サーバーの構成比較ツールを使う事で、
- ローカルサーバーにあって本番サーバーに無いDBオブジェクト
- 本番サーバーにあるがローカルサーバーに無いDBオブジェクト
- 内容が変更されているDBオブジェクト
を閲覧し、本番サーバーをローカルサーバーの構成と同一にするためのスクリプトを生成してくれます。新規オブジェクトがあればCREATE、変更があるオブジェクトはALTER、不要になったオブジェクトはDELETE文が実行され、ローカルサーバーと同一の環境にすることが出来ます。
データベースプロジェクトはビルドする事でローカルDB化する事が可能なので、
- データベースプロジェクトを使い、VisualStudio上でテーブル・ストアドを追加
- ビルドしてローカルDBサーバーとして検証する
- 確認後、本番サーバーのDBとビルドしたローカルDBを比較
- ローカルDBの変更内容を本番サーバーにアップロードするスクリプトをVisualStudioが生成&実行
といったデータベースプロジェクトを中心とした開発も可能です。
3. ソース管理との連携
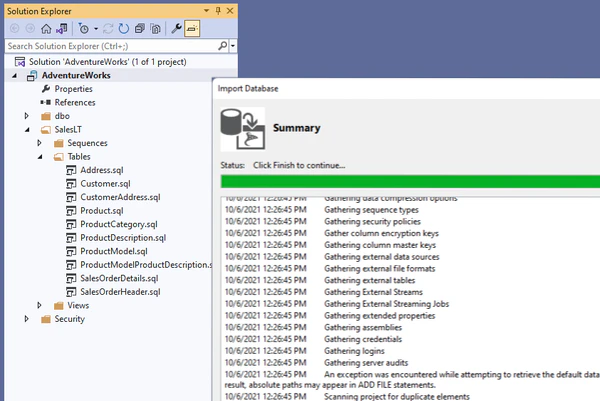
データベースプロジェクトは、プロジェクトフォルダ内にDBの構成情報を.sql形式で吐き出します。mssql-scripterの様に
- テーブル(CREATE TABLE)
- ビュー(CREATE VIEW)
- ストアドプロシージャ(CREATE PROCEDURE)
- ユーザー定義関数(CREATE FUNCTION)
- ユーザー権限設定文
- データベース定義文
等DB管理に必要なデータを全て.sql形式で持ってくることが出来ます。
このプロジェクトフォルダをGitリポジトリ化すれば、DBのソースコードと差分の管理ができます。
尚、VisualStudioとAzureDataStudioは両方データベースプロジェクトを扱う事ができるツールですが、
- VisualStudio内で全てのDB開発を行いたいならVisualStudio
- 多機能さを求めるならVisualStudio
- DBサーバーを実際に触って開発を行い、合間でバージョン管理だけしたいライト層はAzureDataStudio
- 動作の軽さを重視するならAzureDataStudio
- Azureと連携させるならAzureDataStudio
といった棲み分けになるかと思います。
技術選定のアドバイス
mssql-scripterとDBプロジェクトは一応同時に使う事が可能ですが、出力フォーマット(空白数等)が違うため、
両ツールを交互に使ってGit管理すると、フォーマットの差分の変更履歴が余計につきます。
その為、基本的にはどちらかに絞った方がいいと思います。
mssql-scripter
メリット
- コマンドで実行できるので、定期実行やパイプラインなどの自動処理と非常に相性がいい
- UIを操作する必要が無く操作が最低限で終わる
- pythonなどと組み合わせる事で、出力結果のカスタマイズが可能
デメリット
- スクリプト生成に特化しており、DB間の構成比較やデプロイ機能は搭載していない
- 積極的にメンテナンスされているツールではない
VisualStudio(DBプロジェクト)
メリット
- DB間の構成比較やデプロイ機能がある
- GUIの為、操作方法が分かりやすく、差分の閲覧も非常にしやすい
- DB開発の強力なツール(SSDT)を搭載しており、上手く使えば全てVisualStudioでDB開発が完結する
デメリット
- 基本的にスキーマ比較やスクリプト生成は手動で行う必要がある。自動化にはPowerShellなどが必要
AzureDataStudio(DBプロジェクト)
メリット
- DB間の構成比較やデプロイ機能がある
- 軽量で、実際にDBサーバーでSQLを実行しながら開発するのに適している
- Azureと連携する機能がある
デメリット
- VisualStudioと比べ機能が未熟で、スキーマ比較の起動やデプロイ手順などが複雑になっている。(今後のアップデートに期待)
総評
DB開発を全て1つのツールで完結させたいならVisualStudio + DBプロジェクト
SQLを実行しながらDB開発したいならAzureDataStudio + DBプロジェクト
自動化も交えるならAzureDataStudio + mssql-scripter
かと思います。
正直、「どのパターンにも適用できる夢の様なツール」は今のところ存在しませんでした。
SQLServerのバージョン管理が普及するまでの道のりはまだ長そうです...
ですが、確実に無いよりかはマシだと断言できます。
- トラブルが起きた際に、一時的にGitから前のバージョンのストアドに簡単に戻せる
- テストサーバー→本番サーバーへのデプロイを自動化する事で人作業起因のポカミスが激減
- 共同開発の際、変更履歴をもとに変更者の特定をしたり、変更点のコードレビューが出来る
- ローカルで開発する際に、本番サーバーの環境を「ワンクリックで」丸ごとコピーして環境構築の手間削減
このようにDB周りの困りごとがかなり改善されました。
DB起因の不具合も激減しました。以前はテーブル構造違いによるエラー等が頻発していたのですが、自動化してからは一切出なくなりました。
まぁそれくらい自分のDB作業が適当だったというのもあるんですけどね。((