Twitter分析大好きなFooQooです.暇さえあればTwitterで情報収拾してます.
いきなりですが,Twitterのユーザ分析って中々手間が掛かると思いませんか?
私は具体的に以下の点において,いつも時間を浪費してしまいます.
- ツイートデータの取得
- 分析環境の構築
まずツイートデータの取得では,TwitterのWebAPIではOauth認証が必要なので,その準備とプログラミングが必要になります.
幸いにもネットには大量の情報があるので,コピー&ペーストだけでも十分実現可能ですが,ハマる人はハマるかなと思います.
次に分析環境の構築です.pythonの導入から分析用のライブラリを用意するためには,それなりに調べなければならない項目が多いので,大変だと思う人も少なくはないだろうと思います.
そこで,今回は以下の二つのツールを使って手軽にTwitterユーザの分析を行う方法をご紹介します.
ちなみにお気付きの方もいらっしゃるかもしれませんが,筆者は学生の頃,SocialDogの開発に従事していました笑
SocialDog
SocialDogは,AutoScale, Inc.が提供するTwitterアカウント運用ツールです.
フォロワーの管理や分析,ツイート投稿の予約や自動化機能が提供されており,「スマートで効率的な Twitter アカウント運用」が行えます.
SocialDogは,自分用のTwitterアカウントさえあれば利用できるので,非常に手軽に導入できます.
本記事では,SocialDogの「キーワードフォロー」と「CSVダウンロード」の機能を利用します.
Colaboratory
Colaboratoryは,Googleが提供するクラウドで実行できるJupyter notebookの環境です.
ブラウザで開くだけで,Jupyterライクなpythonのコーディングが行えます.またnumpyやpandasといった分析に必要となるライブラリがプリインストールされていて,事前準備ほぼなしでpythonによるデータ分析が行えます.
分析内容
今回は以下の分析を行います.
特定のキーワードを含むユーザを対象とした
- フォロワー数などの統計量の確認
- 各統計量の相関の分析
実際にやってみる
SocialDogを用いたTwitterユーザデータの取得
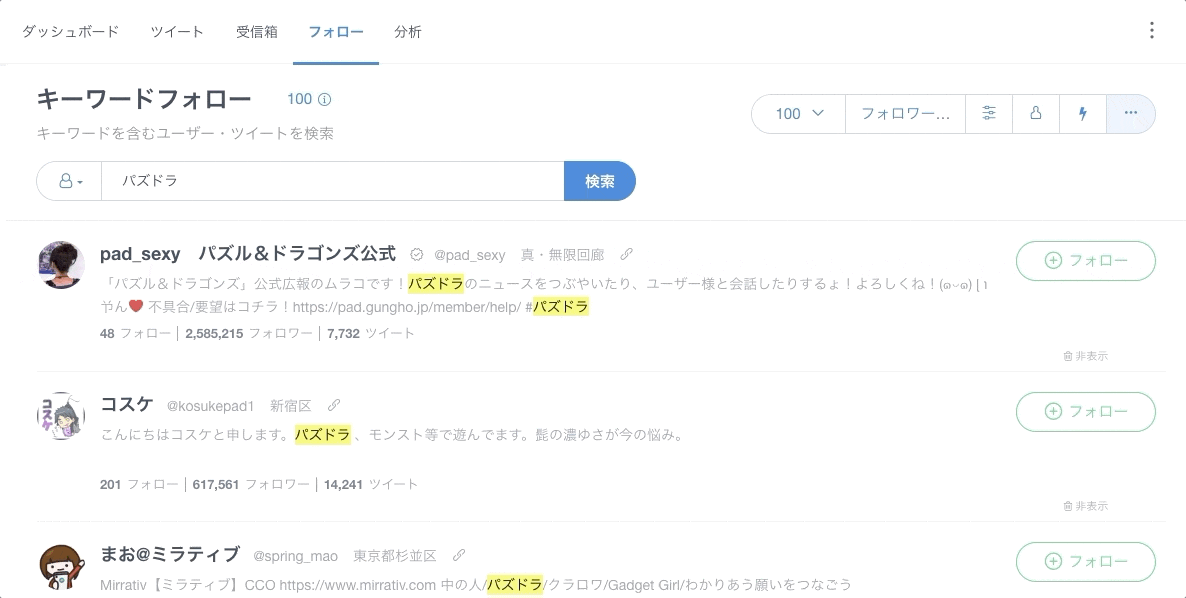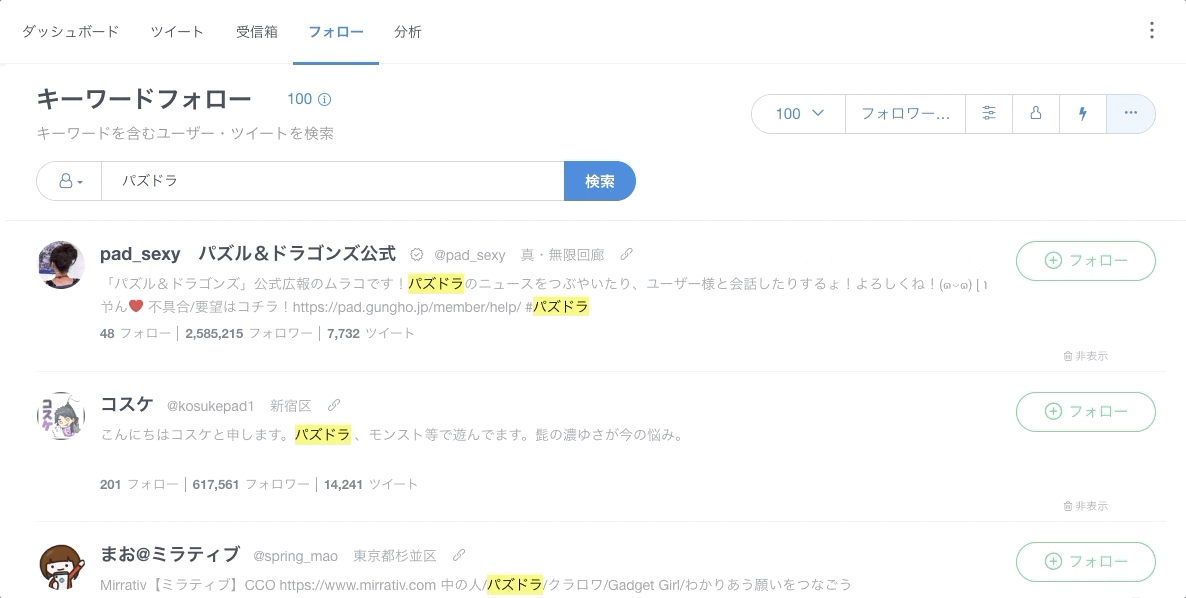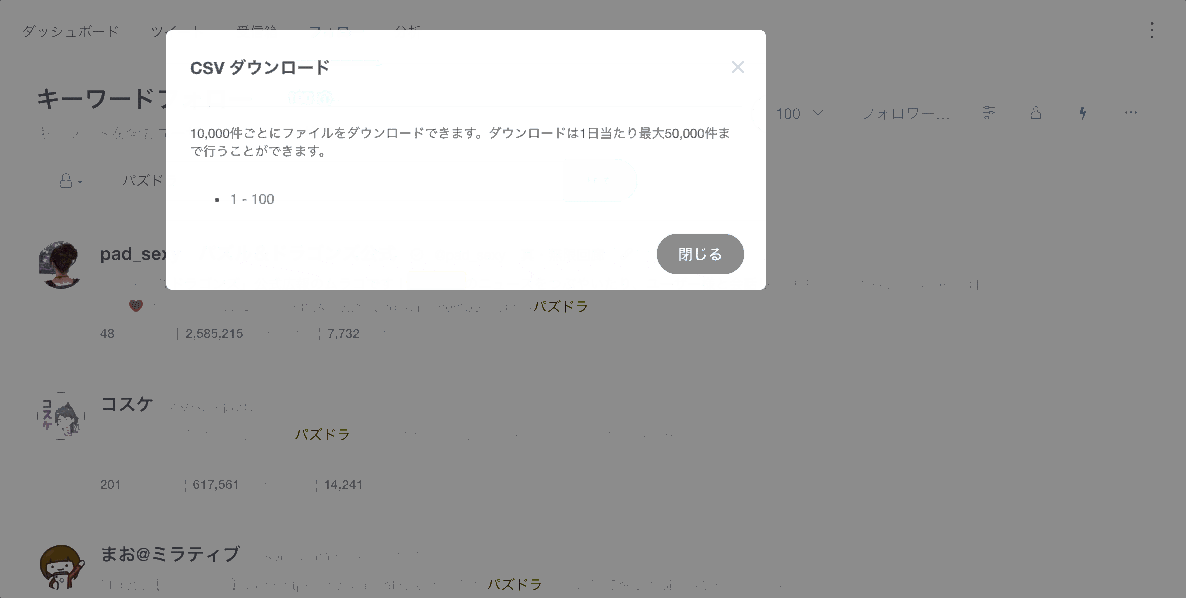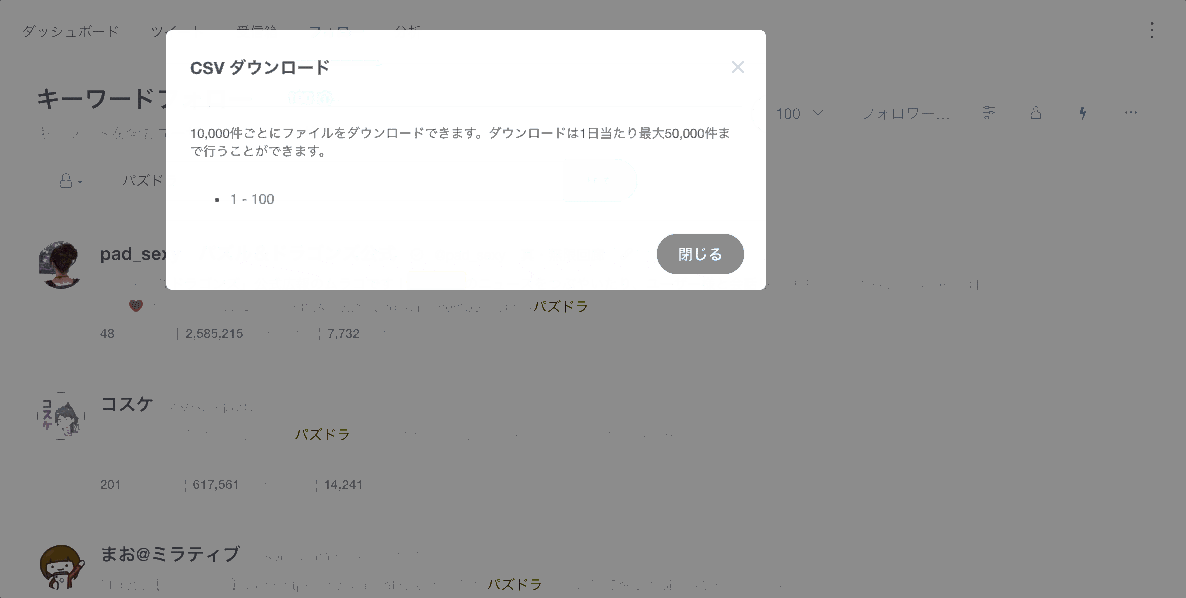
キーワードフォローの機能は,ログインして「ダッシュボード」->「フォロー」の順に探すと見つかります.
実際に「パズドラ」のキーワードをプロフィールに含むユーザをSocialDogで検索し,その結果をCSV形式でダウンロードしてみました.
以下のgifアニメーションでみれる通り,簡単なUIの操作だけで,Twitterユーザのデータが取得できます.
取得するユーザ数やより詳細な条件は,右上のツールバーで変更できます.
SocialDogで取得できるcsvファイルに記述されたユーザの属性はこちらで確認できます.
TwitterAPIとは少し異なる属性がありますが,ほぼ同一のものになっています.
Colaboratoryによる分析
実際に分析を行なっている様子がこちらになります.
Jupyter notebookと同様に,セルを追加して,pythonのソースコードやマークダウンを記述することができます.
Colaboratoryで利用するデータは以下のpythonコードを実行することで,簡単にGoogle Driveにアップロードし,Colaboratory上で利用できます.
# ファイルのアップロード
from google.colab import files
uploaded = files.upload()
では,具体的に分析で利用した処理をご紹介します.
データの欠損の確認と削除
SocialDogでダウンロードしたユーザデータには欠損値が存在します.
そこで,各属性のデータの欠損率を確認します.
# 各列の欠損率を計算する
num_samples = raw_data.shape[0]
defect_rate = raw_data.isnull().sum(axis=0) / num_samples
欠損率をもとに,残す属性と残さない属性を決めます.
本記事では欠損率が10%を超える場合,その属性を削除します.
それ以外で欠損値を含む場合は,欠損値を含むユーザごと削除します.
これは行ごとの削除を意味します.
picked_columns = raw_data.columns[defect_rate < 0.1]
filtered_data = raw_data.loc[:,picked_columns].dropna(axis=0)
統計量の確認
ユーザの統計量は,分析におけるユーザの特徴量となります.
単純に,この値を眺めるだけでもユーザの傾向を知ることができます.
(例:キーワードをプロフィールに含むユーザの中でフォロワー数の多いユーザは誰か?)
ユーザ統計量は,CSVファイルの以下の属性と対応しています.
| 統計量 | 属性名 |
|---|---|
| フォロワー数 | followers_count |
| フォロー数 | friends_count |
| FF比(フォロワーー数/フォロー数) | 別途計算が必要 |
| お気に入りした回数 | favourites_count |
| リストに登録された数 | listed_count |
| ツイート数 | statuses_count |
FF比とは,フォロー数に対するフォロワー数の割合を表します.
FF比は以下のように計算を行いました.
ただしフォロー数が0の場合,FF比は無限大になってしまうのでフォロー数0のユーザは削除しておきます.
filtered_data = filtered_data.loc[ filtered_data.friends_count >0,:]
filtered_data['ff'] = filtered_data.followers_count / filtered_data.friends_count
ユーザ統計量の相関の分析
さきほど確認を行なったユーザ統計量同士の相関係数を計算してみます.
相関係数は文字通り,2組の変量同士の相関の強さ$r$を$-1 \leq r \leq 1$の範囲に示したもので,1に近いほど相関が強く0に違いほど相関が弱いことを表します.
また負方向に大きいほど負の相関が強いと言われ,片方の変量が大きくなるほど,もう一方の変量の値が小さくなります.
pythonではnumpyを利用することで容易に計算することができます.
import numpy as np
# 統計量の行列を生成
statics = ['followers_count', 'friends_count', 'ff', 'statuses_count', 'favourites_count', 'listed_count']
mat_stat = filtered_data.loc[:, statics]
# 統計量の相関係数を行列の形で計算
mat_corr = np.corrcoef(data.transpose())
先ほど計算した相関係数をヒートマップにします.
ヒートマップにすることで,特徴量の相関を視覚的に知ることができます.
# 相関行列のヒートマップを描く
import seaborn as sns
sns.heatmap(coef, annot=True,
xticklabels=statics,
yticklabels=statics)
この結果得られたヒートマップがこちらです.
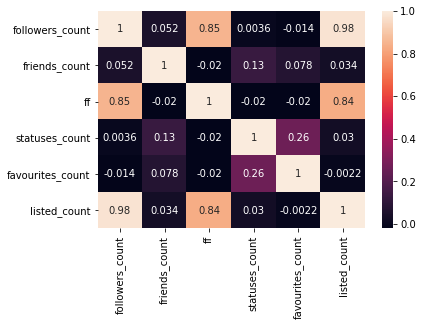
FF比はフォロー数およびフォロワー数をもとに計算された値なので,FF比に対するフォロー数とフォロワー数の相関係数が高くなることは自明です.
このヒートマップから以下の項目を考察してみました.
-
フォロワー数およびFF比とリストへの登録数は非常に強い相関がある.
- フォロワー数およびFF比とリストへの登録数は,共にそのユーザの人気を示すため,強い相関が得られたと考えられる.
-
お気にいり数とツイート数は弱い相関がある.
- どちらもTwitterの利用頻度が高いユーザに見られる傾向である.しかし相関の強さは決して強いものではないため,ツイート数が多いからといってお気に入り数が多いとは限らない.逆も然り.
-
ツイート数に影響を与えるという観点では,フォロワー数よりフォロー数の方が効いているように見える.
- ただし,これはフォロワー数とフォロー数同士の相関を除去していないため,偏相関係数を求める必要がある.
- フォロワー数の影響を除いたフォロー数とツイート数の偏相関係数 = 0.131
- フォロー数の影響を除いたフォロワー数とツイート数の偏相関係数 = -0.003
- この結果から,ようやくフォロー数の方がフォロワー数よりもツイート数に効いていることがわかる.
- ただし,これはフォロワー数とフォロー数同士の相関を除去していないため,偏相関係数を求める必要がある.
まとめ
SocialDogとColaboratoryを使って,ほぼブラウザだけでTwitterユーザの分析を行なってみました.
この方法では,自前によるTwitterAPIによる取得やpythonの分析環境の構築が不要となるため,非常にお手軽です.
機会があれば,統計量以外の要素,例えばプロフィールテキストやユーザツイートも考慮した分析について,記事にできればと思います.