はじめに
ある稼働中のスマートフォンゲームアプリで機能追加・データ増加等により明るみに出てきたボトルネックを解消する作業を行いました。
その対応内容をまとめてみました。
既存ソースに不具合的なコードがあったのでプログラム修正の話も含みます。
概要
アプリ
iOS、Androidのネイティブアプリ(ほとんどがWebviewでページを表示するブラウザアプリ)
カードバトル系ゲーム、GvGバトルあり
サーバ構成
ざっくりですがこんな感じ(チューニング後のバージョンも含む)
図はとりあえず書いてみましたが書き方間違ってたらすいません。
| Ver | 備考 | |
|---|---|---|
| PHP | 5.4 | EC2、PHP-FPM |
| FuelPHP | 1.8 | EC2 |
| MySQL | 5.6 | RDS、マスタ系・プレイヤー系など複数サーバに分散されている |
| Nginx | 1.10.2 | EC2 |
| Memcached | 1.4.15 | EC2、セッション用に外部Memcached、DBデータのキャッシュ用にWEBサーバのローカルMemcached |
| Redis | 2.8.19 | ElastiCache |
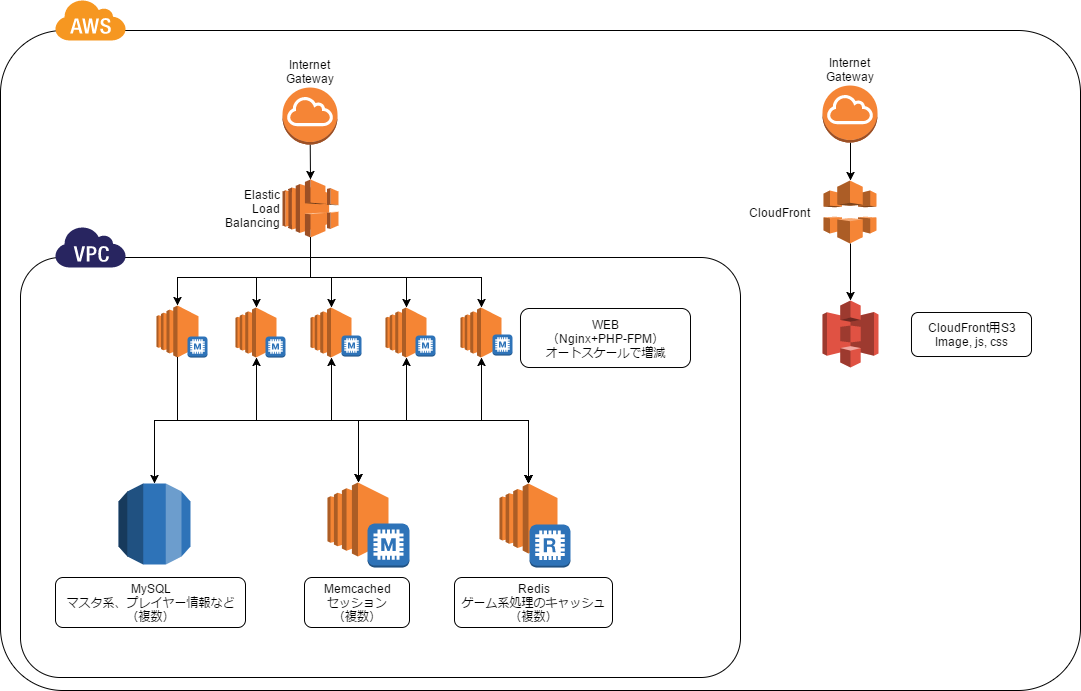 |
WEBサーバが通常40台でGvGバトル時は60台に増やすというスケール設定になっている。
CPUもメモリも使用率高くないのにサーバ台数増やさないとレスポンスが悪くなる。
WEBサーバ:CPU10%ぐらい、メモリ10%ぐらい
DBサーバ:CPU10~20%ぐらい、メモリ20%ぐらい
これ以上サーバを増やしたくないし、できれば減らしたい。
調査で使うもの
New Relic
https://newrelic.com/
これをWEBサーバのどれか1台にインストールしておきます。
最初の30日は有料版の機能も使えるのでその期間で一気にボトルネックを探りました。
URLごとにどんなメソッドやSQLが何回実行されているかなど見れるのでチューニングが捗ります。
無料で使える機能だけでも割と使えます。
アラート閾値(初期値)が少し高めなのでチューニング中は低く設定しましょう。
そうしないと重い箇所を特定できないので…。
ARM → 自分で設定したAPP名のリンク → SETTINGS:Application
Apdex T:0.1に設定
BROWSER → 自分で設定したAPP名のリンク → SETTINGS:Application Settings
Apdex T:1に設定
※ソフトウェアによってベストな値を調整してください。
ボトルネックがあるシステムでは頻繁に**黄色(Non Critical problem)か赤色(Critical problem)**になると思いますが、それでよいです。
**システムオールグリーン**になるように直しましょう…。
ここでプログラムのエラーを見れます。
ARM → 自分で設定したAPP名のリンク → EVENTS:Errors
本番環境だけ発生しているようなエラーを見つけるのに役立つかも。
Linuxコマンド
$ netstat -anp | grep TIME_WAIT | wc -l
$ ss -anp | grep TIME_WAIT | wc -l
$ ab -l -n 10000 -c 100~1000 http://xxx.xxx.xxx.xxx/
ソフトウェアをバージョンアップできるならしておく
実はこれあらかたチューニングが終わってしまった後にやりました。
ステージング環境と同じバージョンと思っていたら全然違かったというオチで…。
| 元のVer | 更新したVer | |
|---|---|---|
| FuelPHP | 1.6 | 1.8 |
| Nginx | 1.6.2 | 1.10.2 |
| Memcached | 1.4.13 | 1.4.15 |
| libevent | 2.0.18 | 2.0.21 |
FuelPHPは変化なかったですけど、その他はabコマンドのテスト結果が少しよくなりました。
バージョンアップしても問題ないシステムならまず最新版入れてみましょう。
FuelPHPはPHP7とセットで入れ替えられるならやる価値あるかもしれません。
開発環境のスペックは低い方がよい
開発環境のマシンスペックは少ないアクセスでもボトルネックに気づけるようになるべく低めに構築するのがよいと思います。
せっかくNew Relicを導入しても高スペックすぎると動作が速くてボトルネックを検知しづらくなります。
このシステムでは以下のような感じになっています。
(低すぎると動かなくなる可能性もあるのでシステムごとに要調整)
開発環境
| 種別 | インスタンス | 台数 | |
|---|---|---|---|
| WEB | m1.medium | 1 | 画像、css、js、ローカルMemcachedでDBデータキャッシュとPHP Sessionを兼用 |
| Redis | t2.small | 1 | |
| RDS | db.t1.micro | 1 | 本番では分かれているDBも全部まとめて1台に集約 |
本番環境
| 種別 | インスタンス | 台数 | |
|---|---|---|---|
| WEB | c3.2xlarge | 複数 | ローカルMemcachedでDBデータキャッシュ |
| Redis | ElastiCache(cache.m3.2xlarge) | 複数 | |
| RDS | db.m3.2xlarge | 複数 | |
| Memcached | c3.2xlarge | 複数 | PHP Session |
| CloudFront | 画像、css、js |
New Relicの閾値を低めに設定してチューニング開始した際は常に黄色か赤色になってました。
チューニング後は常にオールグリーンになってます。
あえてキツイ環境にしてプログラム改修せざるを得ない状況にするのも一つの手かと思います…。
ボトルネックを解消していく
さっそくNew Relicの解析グラフを見てボトルネックを探ります。
といっても負荷がかかっているURLが上位に表示されるし、詳細を見ると負荷がかかっているメソッドなどが赤く表示されるため速攻であたりがつけられます。
これがなければ特定するのにめちゃくちゃ時間がかかると思うし本当に便利です。
ソフトウェアごとに分けて書いたので対応した時系列はぐちゃぐちゃです。
Redisでのキャッシュについては↓こちらで書きました。
ローカルRedisでアプリケーションを高速にする(Linux+PHP+DB+Redis)
Memcached
ローカルMemcachedにはUNIXドメインソケット接続
WEBサーバのローカルにMemcachedがあるのはイマイチな気がしましたが、外部Memcachedにすると今度は負荷が集中するのが気になったのでUNIXドメインソケット接続を試しました。
これが結構速かったので結果的に外部Memcachedにするより良い方法だったかもしれません。
また後述するTCP接続のTIME_WAIT問題への影響も0になります。
memcached -d -u memcached -m 3072 -c 65535 -P /var/run/memcached/memcached-sock.pid
memcached -d -u memcached -m 1024 -c 65535 -P /var/run/memcached/memcached-sock.pid -b 2048 -U 0 -C -s /var/run/memcached/memcached.sock
-m 1024:元々割り当てる量が多すぎた。でも事前にメモリ確保するわけじゃないみたいなので大き目でいいのかも…
-C:CASを無効(このシステムでは使っていない)
-U 0 :UDPを無効(もしかすると-sの時はなくても無効?)
-b 2048:バックログを2048(デフォルト:1024、ソケットにするので増やしてみた)
※MemcachedプロセスにはTCPかUNIXドメインソケットどちらか1つしか設定できません。
運用中のシステムで切り替える時にはTCP接続のMemcachedとUNIXドメインソケット接続のMemcachedをそれぞれ立ち上げておいて、UNIXドメインソケット接続に切り替えたソースを反映してからTCP接続のMemcachedを落とすというやり方になると思います。
PHP側で持続的接続している場合はWebサーバやPHP-FPMの再起動も忘れずに。
(再起動が難しいなら持続的接続のパラメータpersistent_idを変える)
またEC2(オートスケールで起動)で設定した際には何故か.sockファイルに書き込み権限がない状態でMemcachedが起動してしまいました。
しょうがないので起動スクリプトで書き込み権限つけるようにしました…。
ところで…WEBサーバのローカルにMemcached?APCuじゃダメなのか?
といったようなコメントが某所で書かれていたので、ここに追記。
実はAPCuに変更する案もありましたが、APCuはバッチ処理(CLI)ではほぼ使えません。
確かCLIではデフォルトでAPCuがOFFになってます。
またONにしたところで処理が終了するとキャッシュが解放されてしまうので、CLIでもキャッシュを共有したいならMemcachedやRedisなど別のソフトウェアを使うしかないと思います。
このシステムではキャッシュがないとバッチ処理がかなり遅くなってしまうので、もともとインストールしてあったMemcachedの設定を調整して使うことにしました。
あとはmemcached-toolみたいにコマンドorツール類があるとデバッグ&調査に便利ですね。
永久キャッシュを止める
New Relicの解析を見ていて一定時間経過すると段々性能が劣化していくようなグラフが出ました。
どうもキャッシュが一定量(KEYの数?データ容量?)増えると性能が劣化するようです。
いろいろ試してみてこのシステムでは1時間ぐらいに設定するのが良さそうだったので、全キャッシュの有効期限を1時間以下になるように調整しました。
これでMemcachedのレスポンスが安定しました。
対策前
レスポンスタイムが5~20msぐらいで時間が経つにつれて段々増えていく。
最大で200ms~400msぐらいまで増えていた。
(毎日0時にキャッシュクリアされていたのでこのくらいで済んでいたのかも)
キャッシュクリアすると5~20msぐらいに戻る。
対策後
レスポンスタイムが5~20msぐらいで時間が経つにつれて段々増えていくが、
最大で40ms~50msぐらいまでで安定する。
※1コールではなくNew Relicの1分間の数値です。
ORMを用いた実装で大量のSELECTキャッシュ
基本的にマスタ系DBのSELECT結果をMemcachedにキャッシュし、2回目からはキャッシュを見る設計でした。
ループで何度も1レコードSELECTするという処理が結構あり、直接DB参照した方が速いのではないかというぐらいキャッシュを読みまくってる場合も。
何でもキャッシュすればいいってもんじゃない!というのが良くわかる例でした。
何度も呼ばれていて同じ結果を返してよいメソッドに変数キャッシュを入れてみます。
static $_cache = array();
function select($x) {
$cacheKey = 'prefix_'.$x;
if (isset(self::$_cache[$cacheKey])) {
$result = self::$_cache[$cacheKey];
} else {
$cache = new \Memcached('dbcache_pool');
try{
$result = $cache->get($cacheKey);
}catch(\CacheNotFoundException $e){
$result= NULL;
$sql = \Db::select()->from(xxxx)->where(xxxx);
$row = $sql->execute()->current();
if(!empty($row)) {
$result = new Model_Db_Data_xxxx();
$result->setRow($row);
}
$cache->add($cacheKey, $result);
self::$_cache[$cacheKey] = $result;
}
}
return $result;
}
※上の例では直接Memcachedを呼び出していますが実際にはMemcache管理用の独自クラスを使っています。
これが地味で確実に効果あります。何度も同じ処理を呼び出してますからね。
ついでにマスタ系データはキャッシュを上書きする必要がないのでMemcached::set()からMemcached::add()に変更しました。
無駄にsetし直さないようにという意図でしたが、以下のようなしょうもない処理も発見してくれました。
$cache = new \Memcached('dbcache_pool');
$sql = \Db::select()->from(xxxx)->where(xxxx);
$rows = $sql->execute()->as_array();
if(!empty($row)) {
foreach ($rows as $row) {
$tmp = new Model_Db_Data_xxxx();
$tmp->setRow($row);
$result[] = $tmp;
$cache->set($cacheKey, $result); // この中がMemcached::setだと結果が正しくなってしまう
}
}
実際には$cacheが独自クラスになってまして$cache->set()の内部処理をMemcached::set()からMemcached::add()に置き換えました。
元の処理は合っている前提で見てなかったので気づかないんですよね…。
こういったキャッシュ自爆がタクサンアッタノデス。
カード情報の取得が多い
上で書いた通りデータ1件ごとにキャッシュされていて、カード枚数分のキャッシュ取得が走っていました。
こういったものが多数あり処理効率が悪くなっていました。
Redis(Memcachedでも可)に予めバッチ処理で1件ずつマスタデータをキャッシュしておき、1回で複数カードのキャッシュを取得できるようにしました。
function mget($keys) {
$redis = \Redis::forge('name');
$redis->pipeline();
foreach ($keys as $key) {
$redis->get($key);
}
return $redis->execute();
}
pipelineで一気に複数keyを送るので効率がよくなります。
MemcachedならMemcached::getMulti()を使えば同じことができます。
デッキのデータ取得が重い
デッキ編成画面で全デッキデータを取得しているため重くなっていました。
取得するデータを削ることができないため、Redisにデッキデータをgzip圧縮してキャッシュするようにしました。
1回目は遅いままですが、2回目以降はかなり速くなります。
GvGバトルでは選択したデッキ単体で戦うのでデッキ単位でキャッシュしています。
キャッシュの有効期限は長めに設定しておきます。
デッキ編成したり、デッキにあるカードのデータがレベルアップなどで変わったらキャッシュクリアします。
データ更新よりデータ取得が多いなら効果ありです。
FuelPHP
キャッシュ処理が非効率
キャッシュクラスがデータ取得でMemcached::get() 2回、データ保存でMemcached::set() 2回実行されるような実装になっていて負荷が上がっていました。
1回ずつになるように独自処理に置き変えました。
改修ついでに持続的接続、バイナリプロトコルなどオプションを加えました。
(持続的接続は元からあったかな)
$cacheServers = array(
array('host' => 'xxx.xxx.xxx.xxx', 'port' => 11211),
array('host' => 'xxx.xxx.xxx.xxx', 'port' => 11211),
);
static $_memcached = new \Memcached('dbcache_pool');
if (count(static::$_memcached->getServerList()) == 0) {
static::$_memcached->addServers($cacheServers);
static::$_memcached->setOptions(array(
\Memcached::OPT_BINARY_PROTOCOL => true,
\Memcached::OPT_DISTRIBUTION => \Memcached::DISTRIBUTION_CONSISTENT,
\Memcached::OPT_LIBKETAMA_COMPATIBLE => true,
\Memcached::OPT_SERVER_FAILURE_LIMIT => 3,
));
}
セッション処理で持続的接続を使っていない
セッションクラスではMemcachedが持続的接続になっていませんでした。
こちらもキャッシュ処理と同じように持続的接続、バイナリプロトコルの対応をしました。
たまに接続タイムアウトが発生していたのですが、持続的接続にした後は発生していません。
セッションは外部Memcachedだったのでより効果が大きかったですね。
レスポンスが1.5~2倍ぐらい速くなったと思います。
※接続が溢れないようにMemcachedの設定に注意(WEBサーバ台数 * PHP-FPMプロセス数)
Agentクラスが重い
FuelPHPのAgentクラス(ブラウザ情報を取得する処理)が激重でした。
いちおう対策はしてあってRedisでキャッシュされていましたが、このために毎回外部接続したくないのでCrossjoin/Browscapというライブラリを使って処理を差し替えました。
キャッシュせずに毎回処理させてますが高速です。
使う前にbrowscap.iniファイルをダウンロード(&定期的に更新)しておく必要があります。
バッチ処理を作ってcronで設定するなりしましょう。
参考:【改訂版】FuelPHPのAgentクラスが重い問題と暫定的な対処方法
複数同時INSERTはBULK INSERTする
特に10~30レコードのINSERTを1レコードずつINSERTしている箇所が多々あったので、これをBULK INSERTに変えました。
ユーザーごとに発生するものだったのでかなり速くなったと思います。
なおBULK INSERTする際はINDEXの順になるようにソートしてから突っ込みます。
そうしないとデッドロックになってしまうケースがあるようです。
参考:FuelPHPのDatabase_Query_Builder_Insertでバルクインサートが使用できた話
MySQLのBULK INSERTでデッドロックを回避する
Linuxカーネルパラメータ
TCP/IPのTIME_WAITが大量にあった
一番負荷がかかるGvGバトル開催時にTIME_WAITが結構ありました。
サーバーによってまちまちですが2万~2万8千ぐらいでした。
これはMemcached関連の改修をした後の数値なので、改修前はレスポンスが悪くTIME_WAITがもっと多かったと推察します。
カーネルパラメータの設定を見るとnet.ipv4.ip_local_port_rangeが32768 - 65535だったので32767までしか受け付けられませんでした。
改修前は接続が溢れていてサーバー台数を増やす必要があったのかも…。
net.ipv4.ip_local_port_rangeを10000 - 65535に。
net.ipv4.tcp_fin_timeoutが10だったのを5に。
他にはメモリ関連の数値などを増やして最終的に以下のようになりました。
vm.swappiness = 0
vm.overcommit_memory = 2
vm.overcommit_ratio = 99
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 349520 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
net.ipv4.tcp_fin_timeout = 5
net.ipv4.ip_local_port_range = 10000 65535
調整後はTIME_WAITが半分ぐらいになりました。
これはtcp_fin_timeoutを半分にしたからですかね…。
Nginx & PHP-FPM
AWSのELBのHealthCheckに指定していたURLがいわゆるマイページ(HOME)だった
AWSのELB配下にあるサーバには一定秒数で死活監視の通信がきます。
この監視対象のURLがいわゆるマイページ(HOME)で設定されていました。
結構データ取得が走る場所なので無駄に負荷がかかっていました。
ひとまずWEBサーバが応答するかチェックできればよいのでNginxのempty_gifを使いました。
ゲームの調査をする際に邪魔なのでログ保存はOFFにしました。
location = /healthcheck {
empty_gif;
access_log off;
break;
}
サーバー台数増えるほどDBに負荷がかかるものなのであまりバカにはできないですね。
PHP-FPMのプロセスは少ない方がよい
プロセスが元々12個立ち上がっていました。
CPUコアは8個あり使用率も10%未満なので余裕がありました。
プロセスが多いともっと捌けるのではないかと思って50個まで設定変更を試しました。
pm = static
pm.max_children = 50
pm.max_requests = 1000
request_terminate_timeout = 30
実際に運用してみて…
軽い処理がたくさん走る時はよくても、GvGバトルなどで重い処理が走る時はCPUパワーが分散されてよくないようです。
ということで再度調整します。
pm = static
pm.max_children = 20
pm.max_requests = 2000
request_terminate_timeout = 30
今度はちゃんとabコマンドで負荷チェックしてみました。(最初からやりましょう…)
ab -l -n 10000 -c 100~1000 http://xxx.xxx.xxx.xxx/
秒間500~1000リクエストぐらいしか捌けません…。
チェックしたURLはPHPが実行されていますが軽い処理のページです。
もうちょっと頑張れる気がしたのでNginxの設定を調べて調整してみました。
events {
accept_mutex_delay 100ms;
}
sendfile_max_chunk 512k;
open_file_cache max=100000 inactive=20s;
open_file_cache_valid 30s;
open_file_cache_min_uses 2;
open_file_cache_errors on;
これで再度abコマンドでチェックしてみると秒間4000リクエストぐらい捌けるようになりました。
open_file_cache入れるとかなり違いますね。
実際に実機で見てみると以前より画面遷移がスムーズに感じます。
なおスレッドプールも試してみようと設定したらこのプラットフォームでは対応していないと怒られました。
ロケール情報の容量が大きい
PHP-FPMのマスタープロセスが読み込むロケール情報が結構な容量でした。
不要なロケールを削るとメモリを節約できます。
cd /usr/lib/locale/
sudo cp locale-archive locale-archive.bak
sudo localedef --list-archive | grep -v -e ^ja -e ^en_GB -e en_US -e ^zh | sudo xargs localedef --delete-from-archive
sudo cp -a locale-archive locale-archive.tmpl
sudo build-locale-archive
AWSだとスペックを細かく調整できないためメモリが結構余っていて無理にやる必要はなかったかも。
メモリの少ないサーバーで節約したいならばやりましょう。
RDS
メモリが30GBあるのにinnodb_buffer_pool_sizeが6GBという設定
全DBメモリ30GB搭載でしたがメモリを全然使っていない!!
一律で以下のように設定しました。
思い切って分離レベルも変えてます。
メモリはもうちょっと割り当てても大丈夫だったかなという感じがしてますが、RDSのモニタリングでアラートの閾値ギリギリなのでこのままにしています。
たぶんデフォルトがメモリ搭載量の3/4割り当てる設定だからですかね。
つまりinnodb_buffer_pool_sizeはRDSのデフォルト設定でよいはずです。
何故固定で書いたかというと元が3/4になるような設定になっていたのに6GBしか割り当てられてなかったからです!
(もしかすると再起動すれば直ったのかもしれません…)
innodb_buffer_pool_size = 21474836480
innodb_log_file_size = 4294967296
innodb_buffer_pool_instances = 10
innodb_max_dirty_pages_pct = 95
innodb_sync_array_size = 4
innodb_flush_neighbors = 0
sync_binlog = 1
sync_relay_log = 1
relay_log_info_repository = TABLE
master-info-repository = TABLE
binlog_format = ROW
tx_isolation = READ-COMMITTED
innodb_autoinc_lock_mode = 2
thread_cache_sizeとtable_open_cacheが足りてない
コネクションに関連するところはDB別に調整しました。
マスタ系DBは読みが中心で接続もテーブル数も多いので設定値を多めにしています。
show global statusでMax_used_connectionsとOpen_tablesを見て足りなそうなら値を調整します。
table_open_cache_instancesは16→2に変更しました。
MySQLのマニュアルにはCPU16コア以上で8~16にするとよいと書いてありました。
DBサーバを調べたら8コアだったので設定値が大きすぎでした。
max_connect_errors = 100000
max_connections = 1600~3000
thread_cache_size = 1600~3000
table_open_cache = 1000~16000
table_definition_cache = 900~8400
table_open_cache_instances = 2
Binlog_cache_disk_useが増えていく
特にマスタ系のDBでBinlog_cache_disk_useがたくさん増えていました。
全DBの設定が共通で
binlog_cache_size = 32768
となっていました。
Binlog_cache_disk_useが増えているDB(ほとんど全部でしたが…)のbinlog_cache_sizeを調整しました。
こちらもshow global statusで確認しながら上げていきます。
binlog_cache_size = 32768~98304
Aborted_connectsが増えていく
特にマスタ系のDBでたくさん増えていました。
キャッシュが足りないのかと思ってthread_cache_sizeをmax_connectionsと同じにしました。
またwait_timeが30~60だったのを180にしました。
これでAborted_connectsがほぼ増えなくなりました。
ついでにinteractive_timeoutがwait_timeと同じ値で設定されていたので28800にしました。
この値はmysqlコマンドで接続した時か明示的にオプション指定した時だけ?に使われるので小さく調整する必要はないはずです。
直接MySQLに接続してINDEX作成等する際にタイムアウトして不便だったので…。
thread_cache_size = 1000~3000
wait_time = 180
interactive_timeout = 28800
ソート系のメモリ割り当てが足りない
元々が524288~1048576ぐらいの割り当てでした。
各buffer_sizeは参考情報をもとにざっと割り当てました。
tmp_table_sizeはCreated_tmp_disk_tablesの値を見ながら調整しました。
0にはできないようなので上昇が緩やかになる数値で決めました。
max_heap_table_sizeが上限になるのでtmp_table_sizeと同じ数値に変えておきます。
read_buffer_size = 2097152
sort_buffer_size = 4192304
read_rnd_buffer_size = 4192304
join_buffer_size = 262144
max_heap_table_size = 268435456
tmp_table_size = 268435456
マスタ系DBだけは
read_buffer_size = 4192304
join_buffer_size = 1048576
としました。
本当はいらないはずですが、プログラムの実装をすぐ直せない面もあって増やしました。
Provisioned IOPSなのにディスクIOの設定がデフォルトのまま
ストレージがProvisioned IOPSになっているDBはディスクIOの設定も変えました。
デフォルトのままだったので性能発揮できていなかったと思います…。
innodb_io_capacity = 1000
innodb_io_capacity_max = 2000
innodb_lru_scan_depth = 1000
CloudFront
gzip圧縮機能を使っていなかった
AWSの管理画面でちょっと設定変更するだけでgzip圧縮機能が使えます。
未圧縮をキャッシュ済みの場合は、キャッシュから未圧縮のファイルを返してしまうので
gzip圧縮を設定した後にCloudFrontの全キャッシュを削除するとよいです。
これでテキストファイル(CSS、JSなど)の通信容量がかなり減ります。
詳細はAWSを参照のこと
AWS Documentation - 圧縮ファイルの供給
結局WEBサーバをどれだけ減らせたのか
チューニング前
通常時:40台
GvGバトル時:60台
チューニング後
通常時:5~15台(人が少ない深夜帯が5台、昼間は10~15台)
GvGバトル時:30台
これ以上はMemcachedのコール数がボトルネックで減らすのがちょっと怖いです…。
チューニング前よりかなり速くなったしサーバも半分以上減らせたし上出来でしょうかね。
参考情報
こちらの情報を参考にさせていただきました。
貴重な情報を公開してくれた方々に感謝します。
MySQL 5.6のインストール後にチューニングすべき項目
MySQLをインストールしたら、必ず確認すべき10の設定
MySQLのパラメータチューニングメモ
nginx - カーネルパラメーターのチューニング
【改訂版】FuelPHPのAgentクラスが重い問題と暫定的な対処方法
FuelPHPのDatabase_Query_Builder_Insertでバルクインサートが使用できた話
MySQLのBULK INSERTでデッドロックを回避する
locale情報のスリム化(locale-archiveとか)
パフォーマンスチェック
ネットワーク図の作成で使いました。
draw.io