人工知能(AI)の時代において、膨大なデータセットから有意義な知識を抽出することが、ビジネスおよび個人にとって不可欠となっています。そこで登場するのがRetrieval-Augmented Generation(RAG)です。これはAIの能力をターボチャージし、人間のようなテキストを生成するだけでなく、リアルタイムで関連情報を取り込むことを可能にする画期的な進歩です。この融合により、コンテキストに富み、詳細に正確なレスポンスが生み出されます。
大規模な人工知能(AI)の海を興味深い航海で進むにあたり、私たちの道しるべとなる三つの柱、すなわち生成AI、大規模言語モデル(LLMs)、LangChain、Hugging Face、そしてこのRAG(Retrieval-Augmented Generation)の実用的な適用を理解することが不可欠です。
大規模言語モデルと生成AI:革新のエンジン
私たちの旅の中核には、革新の船を前進させる二つの強力なエンジンである大規模言語モデル(LLMs)と 生成AI があります。
大規模言語モデル(LLMs)

LLM、Qwen, GPTなどは、大規模に人間のような言語を理解し生成する能力を持つ、テキストの巨人たちです。これらのモデルは広範なテキストデータのコーパスでトレーニングされており、連続したテキストの予測と生成ができるようになっていて、文脈に即した一貫した文を作り出します。翻訳からコンテンツ作成まで、多くの自然言語処理タスクの基盤となっています。
Generative AI (GenAI)
Generative AI はAI領域内の創造的な魔法使いです。トレーニングデータに似た新しいデータインスタンスを生成する技術を含んでおり、画像、音楽、そして私たちの航海にとって最も重要なテキストがこれに該当します。私たちの文脈では、生成AIとはAIが今までにない新しく有益なレスポンス、物語、またはアイデアを生み出す能力を指します。それにより、AIは過去を模倣するだけでなく、発明し、革新し、刺激を与えることができます。
LangChain:あなたのAIシンフォニーを調整する
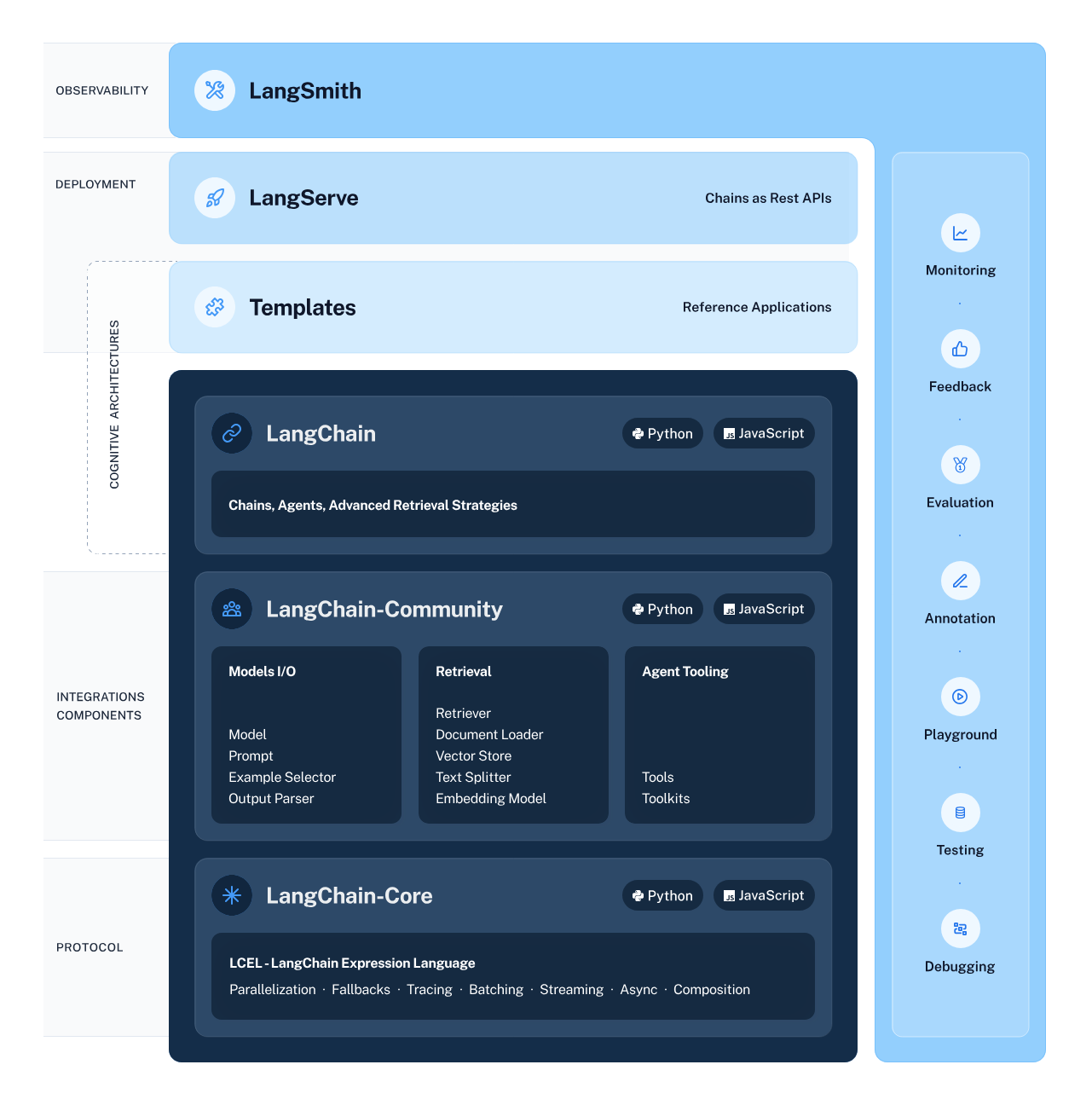
LangChain は、さまざまなAIコンポーネント間のシームレスな統合と相互作用を可能にする構造を入念に設計する、私たちのAIワークフローの建築家として機能します。このフレームワークは、LLMsや検索システムを含むインテリジェントなサブシステムからのデータフローを連携させる複雑なプロセスを簡素化し、情報抽出や自然言語理解といったタスクを以前にも増して容易にします。
Hugging Face:AIモデルのメトロポリス

Hugging Faceは、AIモデルが活況を呈する都市のような環境です。この中心地は、機械学習の探求と応用のための豊かな土壌として、膨大な数のプリトレーニングモデルを提供しています。このハブとそのリソースへのアクセスを得るためには、Hugging Faceアカウントを作成する必要があります。この手順を踏むと、広大なAIの世界があなたを待っています — Hugging Faceに訪れてサインアップし、あなたの冒険を始めましょう。
RAG: 加速インテリジェンスのためのベクターデータベースの活用
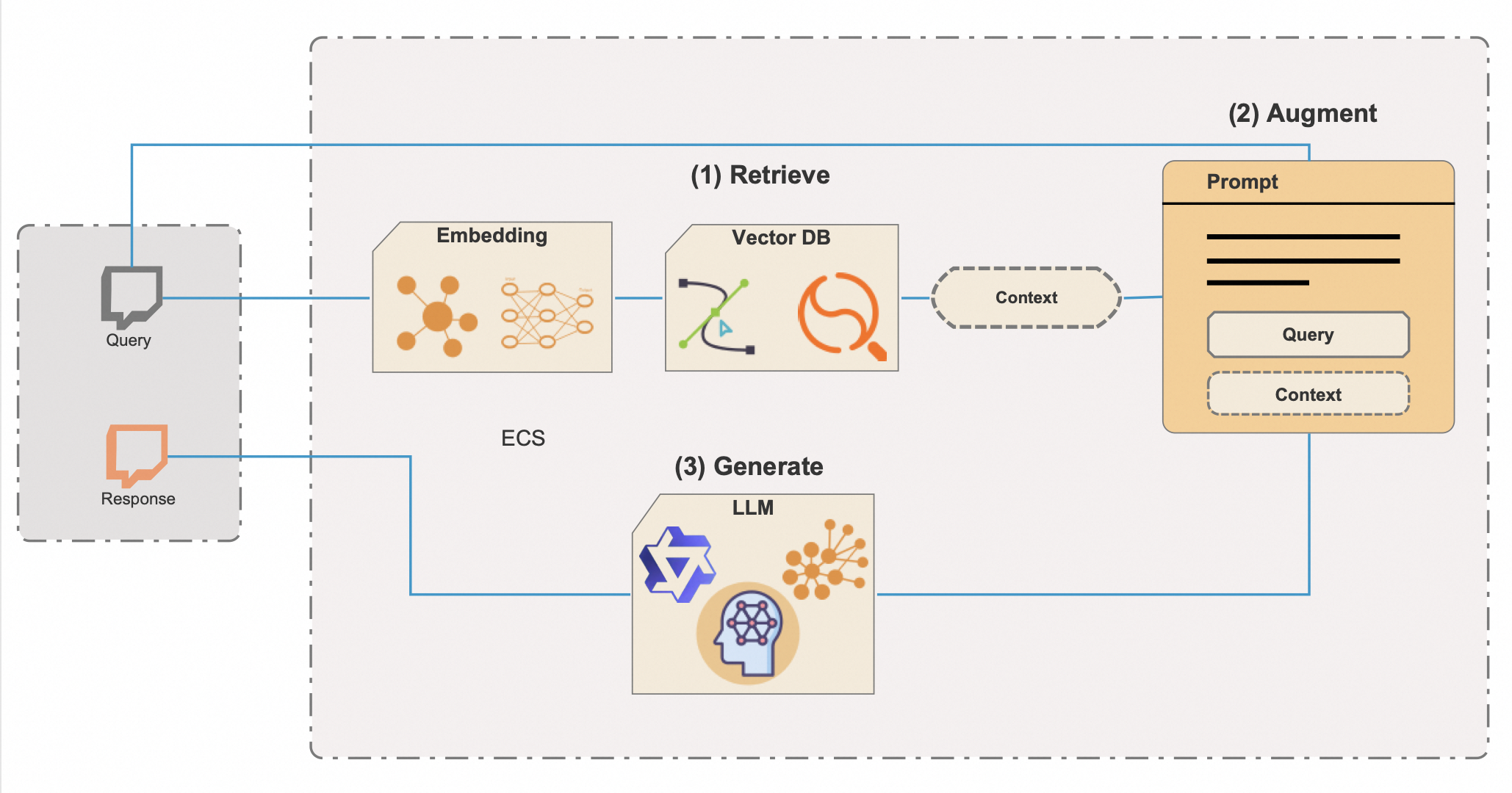
Retrieval-Augmented Generation(RAG)は、生成AIの創造的な力と知識検索の精密さを結合させた洗練されたAI技術であり、流暢でありながら深く知識に基づいたシステムを創り出します。RAGの完全なポテンシャルと効率を引き出すためには、膨大な情報リポジトリを迅速に探索する強力なツールであるベクターデータベースを統合しています。以下に、ベクターデータベースを使用してRAGがどのように機能するかの詳細な説明を示します:
-
ベクターデータベースを使用した検索:** RAGは、大量の情報が埋め込まれた表現を保持するベクターデータベースへのクエリからプロセスを開始します。これらの埋め込みは、文書やデータスニペットの意味的本質を包括する高次元ベクトルです。ベクターデータベースにより、RAGはこれらの埋め込みを横断して、与えられたクエリに最も関連するコンテンツを素早く特定することが可能になるため、あたかもAIがデジタルライブラリーを素早くナビゲートしてちょうど良い本を見つけるかのようです。
-
コンテキストによる増強: ベクターデータベースから取得した関連情報は、文脈的増強として生成モデルに提供されます。このステップにより、AIは知識の凝縮された投与を受け、創造的でありながら文脈に富み、精密なレスポンスを作り出せるようになります。
-
インフォームドレスポンスの生成: この文脈を装備して、生成モデルはテキストの生産に移ります。学習されたパターンだけに依存する標準的な生成モデルとは異なり、RAGは取得したデータからの具体的な情報を織り交ぜながら出力を行い、これによって想像力に富むとともに取得した知識に裏打ちされた結果をもたらします。その結果、生成は向上し、より正確で、有益で、真の文脈を反映したレスポンスがもたらされます。
ベクターデータベース の統合は、RAGの効率性にとって鍵となります。従来のメタデータ検索方法は遅かったり正確でなかったりすることがありますが、ベクターデータベースは極めて大規模なデータセットからの文脈に関連した情報のほぼ瞬時の検索を可能にします。このアプローチは貴重な時間を節約するだけでなく、AIのレスポンスが利用可能な最も適切で最新の情報に基づいていることを保証します。
RAGの能力は、正確で信頼性があり、文脈に基づいた情報を提供することが重要なチャットボット、デジタルアシスタント、洗練された研究ツールなどのアプリケーションに特に有利です。それは単に説得力のあるレスポンスを作り出すだけではなく、検証可能なデータと実世界の知識に根ざしたコンテンツを生成することについてです。
LangChain、Hugging Face、LLMs、GenAI、そしてベクターデータベースによって強化されたRAGの豊かな理解を携えて、これらの技術を実生活に持ち込むコーディングの冒険の瀬戸際に立っています。私たちが掘り下げるPythonスクリプトはこれらの要素の相乗効果を表しており、クリエイティビティと文脈だけでなく、かつてはサイエンスフィクションの領域だと思われていた理解の深さで応答する能力を持つAIシステムを示しています。ベクターデータベースを使用したRAGの変革的な力を体験するため、コーディングの準備をしましょう。
コーディングの旅を始める
はじめに:必要なもの
この技術のオデッセイに出航する前に、すべての準備が整っていることを確認しましょう:
-
GPUカード付きのLinuxサーバーが望ましいです — 速度が重要だということは言うまでもありません。
-
Python 3.6以上 — プログラミングの魔法の杖です。
-
pipまたはAnaconda — 手軽なパッケージマネージャーです。
-
GPUカードがある場合は、NVIDIAドライバー、CUDAツールキット、およびcuDNN — GPUアクセラレーションのための三位一体です。
すべて揃いましたか?素晴らしいです!
コードの実行
Pythonの依存関係を慎重に管理することで、AIプロジェクトが安定した信頼できる基盤の上に構築されることを確保します。依存関係が整い、環境が正しくセットアップされれば、スクリプトを実行し、RAGとLangChainのパワーを実際に目の当たりにする準備が整います。
ステージを設定する:ライブラリをインポートし、変数を読み込む
LangChainフレームワークとHugging FaceのTransformersライブラリを用いてAIの探究に乗り出す前に、安全でよく構成された環境を確立することが極めて重要です。この準備には、必要なライブラリをインポートし、APIキーなどの機密情報を環境変数を通じて管理する作業が含まれます。
from torch import cuda
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
from transformers import AutoModelForCausalLM, AutoTokenizer
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
from transformers import pipeline
from dotenv import load_dotenv
load_dotenv()
Hugging FaceのAIモデルを使用する際には、Hugging Face APIへのアクセスがよく必要になりますが、これにはAPIキーが必要です。このキーはHugging Faceのサービスにリクエストを送る際のあなたのユニークな識別子であり、モデルをロードしてアプリケーションで使用することを可能にします。
環境を安全に設定するために必要な手順は次のとおりです:
-
Hugging Face APIキーを取得する: Hugging Faceアカウントを作成したら、「アクセストークン」セクションのアカウント設定でAPIキーを見つけることができます。
-
APIキーを安全に保管する: APIキーは機密情報であり、プライベートに保つべきです。スクリプトに直接コーディングするのではなく、環境変数を使用するべきです。
-
.envファイルを作成する: GitHubリポジトリからクローンしたAwesome-Qwenフォルダ内に.envというファイルを作成します。このファイルには環境変数が格納されます。
-
APIキーを.envファイルに追加する: テキストエディタで.envファイルを開き、以下のフォーマットでHugging Face APIキーを追加します:
HUGGINGFACE_API_KEY=your_api_key_here
your_api_key_hereをHugging Faceから取得した実際のAPIキーに置き換えてください。
モデルパスと設定を定義する
modelPath = "sentence-transformers/all-mpnet-base-v2"
device = 'cuda' if cuda.is_available() else 'cpu'
model_kwargs = {'device': device}
ここでは、埋め込みに使用される事前トレーニング済みモデルへのパスを設定します。また、利用可能な場合はより高速な計算のためにGPUを使用し、そうでない場合はCPUをデフォルトとするデバイス設定を構成します。
Initialize Hugging Face Embeddings とFAISSベクターストアを初期化する
embeddings = HuggingFaceEmbeddings(
model_name=modelPath,
model_kwargs=model_kwargs,
)
# Made up data, just for fun, but who knows in a future
vectorstore = FAISS.from_texts(
["Harrison worked at Alibaba Cloud"], embedding=embeddings
)
retriever = vectorstore.as_retriever()
Hugging Face埋め込みのインスタンスを選択したモデルと設定で初期化します。次に、高次元空間での効率的な類似性検索を可能にするFAISSを使用してベクターストアを作成します。また、埋め込みに基づいて情報を取得するリトリバーもインスタンス化します。
チャットプロンプトのテンプレートを設定する
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
ここでは、AIとの対話を構造化するために使用されるチャットプロンプトのテンプレートを定義しています。コンテキストと質問のためのプレースホルダーが含まれており、チェーンの実行中に動的に埋められます。
トークナイザーと言語モデルを準備する
AIと自然言語処理の世界では、トークナイザーと言語モデルはテキストを意味のあるアクションに変えるダイナミックなコンビです。トークナイザーは言語をモデルが理解できる部分に分解し、言語モデルはこれらの入力に基づいて言語を予測し生成します。私たちの旅では、これらの機能を活用するためにHugging FaceのAutoTokenizerとAutoModelForCausalLMクラスを使用しています。しかし、言語モデルを選ぶ際にはワンサイズがすべてに合うわけではないことを覚えておくことが重要です。
モデルサイズと計算リソース
モデルのサイズは重要な要因です。Qwen-72Bのような大きなモデルにはより多くのパラメータがあり、一般的にはより洗練されたテキストを理解し生成することができます。しかし、それらはより多くの計算能力を必要とします。高性能のGPUと十分なメモリを搭載している場合は、これらの大型モデルを選択してその能力を最大限に活用することができるでしょう。
一方、Qwen-1.8Bのような小型モデルは標準的なコンピューティング環境でずっと扱いやすいです。この小さなモデルであれば、IoTやモバイルデバイス上でも実行できるはずです。より大きなモデルほど言語の複雑さを捉えることはできませんが、それでも優れたパフォーマンスを提供し、特殊なハードウェアを持たない人にとってもアクセスしやすいです。
タスク固有のモデル
考慮すべき別のポイントは、タスクの性質です。会話AIを構築している場合は、Qwen-7B-Chatのようなチャット専用モデルを使用すると、これらのモデルはダイアログの微細なニュアンスを扱うためにファインチューニングされており、基本モデルよりも優れた結果が得られる可能性があります。
推論のコスト
大きなモデルはハードウェアからより多くを要求するだけでなく、モデルの実行にクラウドベースのサービスを使用している場合は、より高いコストがかかる可能性があります。各推論は処理時間とリソースを消費し、巨大なモデルを扱う場合には費用がかさむ可能性があります。
Qwenシリーズ
-
Qwen-1.8B: 計算能力が少なくて済むタスクに適した小型モデル。プロトタイピングやパワフルなGPUを搭載していないマシンでの実行に適しています。
-
Qwen-7B: パフォーマンスと計算要求のバランスが取れた中規模モデル。テキスト生成や質問応答を含む一連のタスクに適しています。
-
Qwen-14B: より複雑なタスクをより微妙な言語理解と生成で扱うことができる大型モデル。
-
Qwen-72B: シリーズで最大のモデルであり、深い言語理解を必要とする高度なAIアプリケーションに最先端のパフォーマンスを提供します。
-
Qwen-1.8B-Chat: チャットボットや他の対話システムを構築するために特別に設計された会話モデル。
-
Qwen-7B-Chat: Qwen-1.8B-Chatに似ていますが、より複雑な対話を処理するための増加した容量を持ちます。
-
Qwen-14B-Chat: 洗練された対話インタラクションを可能にするハイエンドの会話モデル。
-
Qwen-72B-Chat: Qwenシリーズで最も高度な会話モデルであり、要求の厳しいチャットアプリケーションに卓越したパフォーマンスを提供します。
選択をする
どのモデルを使用するかを決める際には、より大きなモデルの利点と利用可能なリソース、およびプロジェクトの特定の要件を天秤にかけます。ちょうど始めたばかりであるか、小規模で開発している場合は、小さいモデルが最良の選択かもしれません。ニーズが成長するにつれて、またはより高度な機能が必要な場合は、より大きなモデルへの移行を検討してください。
Qwenシリーズはオープンソースであるため、さまざまなモデルを実験して、プロジェクトに最適なモデルを見つけることができます。異なるモデルを使用することにした場合、スクリプトのモデル選択部分は以下のようになるかもしれません:
# This can be changed to any of the Qwen models based on your needs and resources
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
model_name_or_path = "Qwen/Qwen-7B"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=True)
それぞれAutoTokenizerとAutoModelForCausalLMクラスを用いて、Hugging Faceからトークナイザーと因果関係言語モデルをロードします。これらのコンポーネントは自然言語入力の処理とアウトプットの生成に不可欠です。
テキスト生成パイプラインを作成する
このパイプラインは、以前にロードされた言語モデルとトークナイザーを使ってテキストを生成するために設計されています。パラメーターを細分化して、テキスト生成の挙動をコントロールする役割を理解しましょう:
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=8192,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
hf = HuggingFacePipeline(pipeline=pipe)
####テキスト生成パイプラインでのパラメーターの説明
-
max_new_tokens (8192): このパラメーターは、出力で生成されうる最大のトークン数を指定します。トークンは、使用されるトークナイザーによって、単語、文字、またはサブワードのいずれかになります。
-
do_sample (True): Trueに設定すると、このパラメーターはモデルによって生成される可能性のある次のトークンの分布から確率的にサンプリングを有効にします。これにより、生成されるテキストにランダム性と多様性がもたらされます。Falseに設定すると、モデルは常に最も可能性の高い次のトークンを選択し、決定論的で多様性の少ない出力になります。
-
temperature (0.7): 温度パラメーターは、サンプリングプロセスに導入されるランダム性の量をコントロールします。温度値が低い(0に近い)場合は、モデルは自信を持って選択を行い、ランダム性の少ない出力になります。温度値が高い(1に近い)場合は、ランダム性と多様性を促進します。
-
top_p (0.95): このパラメーターは、核サンプリングを制御します。これは、累積確率が閾値top_pを超える最も可能性の高いトークンのみを考慮するテクニックで、多様かつ一貫性のあるテキストを生成するのに役立ちます。非常に低い確率のトークンの含まれることを避け、テキストが意味不明になるのを防ぎます。
-
top_k (40): トップkサンプリングは、サンプリングプールを最も可能性の高い次のkトークンに限定します。これにより、次のテキストを生成するためにモデルが検討するトークンのセットをさらに絞り込み、出力が関連性があり一貫性を保つようにします。
-
repetition_penalty (1.1): このパラメーターは、モデルが同じトークンやフレーズを繰り返すことを抑制し、より興味深く多様なテキストを促進します。1より大きい値は、すでに現れたトークンの可能性をペナライズし、それによって減少させます。
望ましいパラメーターでパイプラインをセットアップした後、次のコード行:
hf = HuggingFacePipeline(pipeline=pipe)
パイプオブジェクトをHuggingFacePipelineでラップします。このクラスはLangChainフレームワークの一部であり、AIアプリケーションの構築に向けてLangChainのワークフローにシームレスに統合されるようにします。パイプラインをラップすることで、リトリバーやパーサーなど他のLangChainのコンポーネントと組み合わせて、より複雑なAIシステムを作成することが可能になります。
これらのパラメーターを慎重に選択することで、クリエイティブで多様な出力を求めているのか、一貫性があり焦点を絞ったテキストを目指しているのかにかかわらず、アプリケーションの特定のニーズに合わせてテキスト生成の挙動を微調整することができます。
RAGチェーンの構築と実行
以下のコードスニペットは、初期の質問が関連情報の検索を促し、それが生成プロセスを増強するために使用され、入力された質問に対して情報に基づき文脈に関連する回答が得られる完全なエンドツーエンドのRAGシステムを表しています。
1. Cチェーン構築:
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| hf
| StrOutputParser()
)
このコードのこの部分で何が起こっているかを以下に示します:
-
リトリーバーは、クエリに基づいて関連情報を取得するために使用されます。リトリーバーの役割は、データセットや文書のコレクションを調べ、質問に最も関連性のある情報を見つけることです。これは効率性のためにおそらくベクターデータベースを使用しているでしょう。
-
_RunnablePassthrough() _ は質問を変更せずにそのまま渡すコンポーネントです。これは、おそらくユーザーが入力した質問を直接処理するためにチェーンが設計されていることを示しています。
-
prompt はここでは詳細には表示されていませんが、おそらく入力質問と取得されたコンテキストを次の段階であるHugging Faceモデルに適した形式に整形するテンプレートまたは手順書として機能するでしょう。
-
hf variable はHugging Faceパイプラインを表し、おそらく応答を生成することができる事前トレーニング済みの言語モデルです。このパイプラインは前のステップからの整形された入力を受け取り、その生成能力を使用して回答を生成します。
-
StrOutputParser() は出力パーサーであり、その仕事はHugging Faceパイプラインからの生の出力をよりユーザーフレンドリーな形式、おそらく文字列に解析することです。
パイプ(|)演算子の使用は、このコードが関数型プログラミングスタイルを使用していることを示唆しており、具体的には関数の合成やパイプラインパターンの概念を指していて、一つの関数の出力が次の関数の入力になります。
2. チェーンの呼び出し:
results = chain.invoke("Where did Harrison work?")
この行では、特定の質問「"Where did Harrison work?"」でチェーンが呼び出されています。この呼び出しは、チェーンで定義された一連の操作をトリガーします。リトリーバーは関連情報を検索し、その情報は質問と一緒にプロンプトを通過してHugging Faceモデルに入力されます。モデルは、受け取った入力に基づいて応答を生成します。
3. 結果:
print(results)
生成された応答は、StrOutputParser()によって解析され、最終結果として返され、それがコンソールまたは他の出力に出力されます。
最後に、リトリーバー、プロンプトテンプレート、Hugging Faceパイプライン、および出力パーサーをリンクしてRAGチェーンを構築します。質問でチェーンを呼び出し、結果を出力します。

結論:AIマスタリーへのゲートウェイ
あなたはRAGとLangChainを用いてAIの世界への巨大な一歩を踏み出しました。このコードを理解し実行することで、前例のない方法で情報を理解し対話することができるインテリジェントなシステムを作り出す可能性を解き放つことができます。
これは始まりに過ぎません。RAGを使って実験し、いじくり回すほどに、あなたの理解は深まり、革新する能力は高まります。
本文はAIによって翻訳されました。ここで表明されている意見は参考までにお読みいただくものであり、必ずしもAlibaba Cloudの公式の意見を代表するものではありません。原文はこちらです。