はじめに
データ分析で直面する課題の一つに、自然言語の扱いがあります。
例えば、コールセンターでの音声のやり取りが、そのままデータベースに格納されている場合、BI で分析することがとても難しかったりしますよね。「今朝、パソコンを立ち上げたんですが、会社のネットワークにつながらなくて困ってしまっています・・・」 なんていう文面がそのままフィールドに格納されていることも少なくないと思います。
そんな時、日本語文章を形態素解析して、問い合わせの内容にどのような言葉が使われがちか可視化できたら素敵ですよね。
本記事では、データベース上に自然言語の形で格納されているデータを、Python によって形態素解析し、ワードクラウドで可視化したものを、Yellowfin の ダッシュボードに表示するまでの手順を紹介します。
環境準備と前提
Python パッケージ
Python にパッケージをインストールします。必要なパッケージは以下の 3 点です。
| パッケージ | 用途 | インストールコマンド |
|---|---|---|
| psycog2 | PostgreSql 接続 | pip install psycopg2 |
| janome | 形態素解析 | pip install janome |
| wordcloud | ワードクラウド作成 | pip install wordcloud |
データベース
PostgreSql 上のテーブルに、以下のような感じで日本語の自然言語がそのまま格納されているとします。このデータを形態素解析で品詞に分解し、ワードクラウドを作成します。

自然言語のサンプルとしては、『第二百十回国会における岸田内閣総理大臣所信表明演説首相官邸』の (はじめに) の文章を活用させていただきました。
処理概要
処理の全容は以下の通りです。
- Python 処理
・データベースから該当列の値を取得して文字列として連結
・上の手順で連結した文字列を形態素解析で品詞に分解
・ワードクラウドで解析結果を可視化 - Yellowfin ダッシュボードに表示
Python 処理
データ取得・連結
psycopg2 を活用し、PostgreSql に接続した後、データを取得し、全データを連結します。連結したデータは、後の手順で形態素解析する対象となります。
import psycopg2
from psycopg2 import Error
#PostgreSql接続
connector = psycopg2.connect('postgresql://{user}:{password}@{host}:{port}/{dbname}'.format(
user="postgres",
password="password",
host="localhost",
port="5432",
dbname="demo"))
#該当列からデータを取得および連結
cursor = connector.cursor()
cursor.execute('SELECT string_agg(sentence,\'\') AS sentence FROM public."sentences";')
rows = str(cursor.fetchone())
#クローズ処理
cursor.close()
connector.close()
形態素解析
janome を活用して、データベースから取得したデータを形態素解析するためのメソッドに受け渡します。
データを名詞・動詞・形容詞・副詞の単位で区分して空白で連結します。データの中には「ため」「できる」のような、ワードクラウドに表示したくない言葉も含まれます。不要な単語を抽出して、ワードクラウドに受け渡せるようにします。
from janome.tokenizer import Tokenizer
#rows を tokenize() メソッドに受け渡し
tok = Tokenizer()
tokens = tok.tokenize(rows)
#名詞・動詞・形容詞・副詞の単位で文章を区分して空白で連結
words = ""
for token in tokens:
if token.part_of_speech.split(',')[0] in ['名詞', '動詞', '形容詞', '副詞']:
words = words + " " + token.base_form
#不要な単語を抽出
drop_words = [u'いく', u'ある', u'くれる', u'さらに', u'くる', u'そう', u'まいる', u'曽', u'的', u'半',
u'もつ', u'さらに', u'回', u'せる', u'ひる', u'いたす', u'くい', u'こと', u'さ', u'以上',
u'ため', u'なる', u'わたる', u'化', u'百', u'十', u'五', u'四', u'三', u'二', u'一', u'ら',
u'よう', u'れる', u'いる', u'する', u'できる', u'うち', u'できる', u'いける']
ワードクラウド
日本語フォントとしてメイリオを使用するように明示します。日本語フォントを使用しないと、文字化けしてしまいます。
ワードクラウドのメソッドに対して、処理データ、不要なデータ、フォントなどの情報を受け渡し、処理結果を画像ファイルとして出力するように命令します。
#日本語フォントの選択
jpn_font = "C:\\Windows\\Fonts\\meiryo.ttc"
#wordcloud を描画して画像ファイルとして保存
wordcloud = WordCloud(background_color="white",
font_path=jpn_font,
height=600,
width=800,
stopwords=set(drop_words)
).generate(words)
wordcloud.to_file("wordcloud.png")
全容
コードの全容は以下の通りです。
import psycopg2
from psycopg2 import Error
from janome.tokenizer import Tokenizer
from wordcloud import WordCloud
connector = psycopg2.connect('postgresql://{user}:{password}@{host}:{port}/{dbname}'.format(
user="postgres",
password="password",
host="localhost",
port="5432",
dbname="demo"))
cursor = connector.cursor()
cursor.execute('SELECT string_agg(sentence,\'\') AS sentence FROM public."sentences";')
rows = str(cursor.fetchone())
cursor.close()
connector.close()
tok = Tokenizer()
tokens = tok.tokenize(rows)
words = ""
for token in tokens:
if token.part_of_speech.split(',')[0] in ['名詞', '動詞', '形容詞', '副詞']:
words = words + " " + token.base_form
drop_words = [u'いく', u'ある', u'くれる', u'さらに', u'くる', u'そう', u'まいる', u'曽', u'的', u'半',
u'もつ', u'さらに', u'回', u'せる', u'ひる', u'いたす', u'くい', u'こと', u'さ', u'以上',
u'ため', u'なる', u'わたる', u'化', u'百', u'十', u'五', u'四', u'三', u'二', u'一', u'ら',
u'よう', u'れる', u'いる', u'する', u'できる', u'うち', u'できる', u'いける']
jpn_font = "C:\\Windows\\Fonts\\meiryo.ttc"
wordcloud = WordCloud(background_color="white",
font_path=jpn_font,
height=600,
width=800,
stopwords=set(drop_words)
).generate(words)
wordcloud.to_file("wordcloud.png")
Yellowfin ダッシュボードに配置
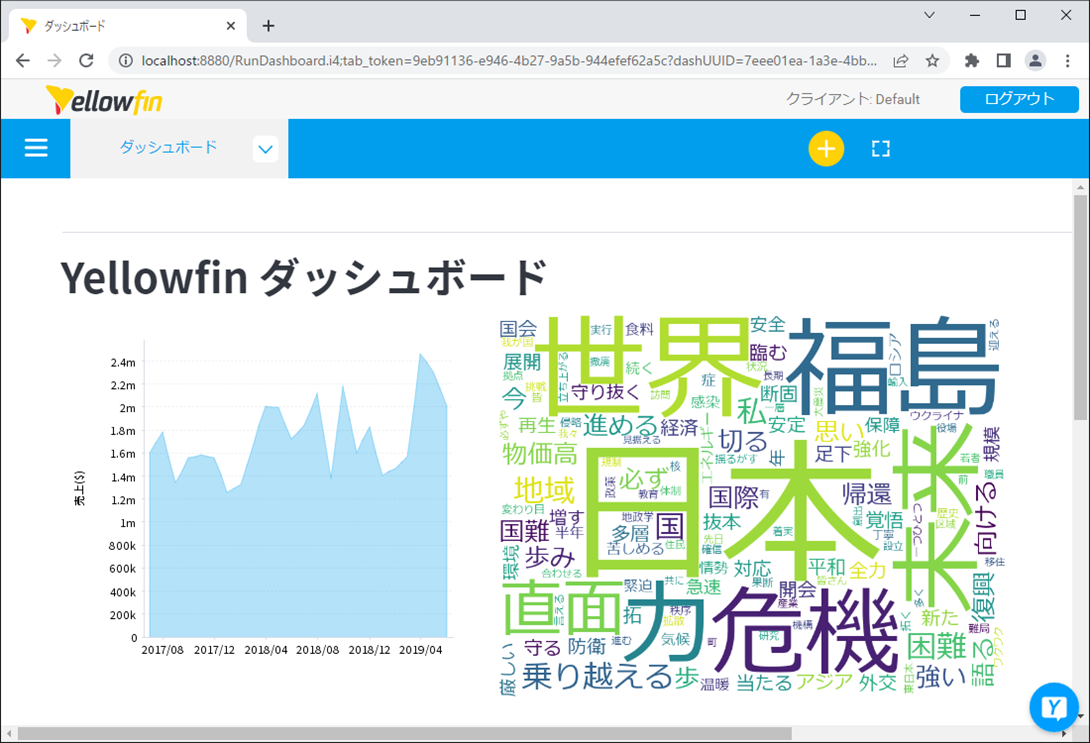
出力されたファイルを、Yellowfin ダッシュボードに配置します。見事、ワードクラウドがダッシュボードに組み込まれました。
最後に
形態素解析で文章を分解したものを、今回は分かりやすくワードクラウドで表現してみました。ここまでの処理を振り返ると分かる通り、ワードクラウドは静的な画像コンテンツとしてダッシュボードに配置されています。他の Yellowfin コンテンツと同様に、動的なコンテンツとして動作させるには、もう一工夫必要ですね。
何はともあれ、他のアプリやプラットフォームと連携することで、Yellowfin の機能をさらに拡張することができます。今後も、様々なアプリやサービスなどとの連携を模索していこうと思います。
では皆様、良いデータ分析を! See you then! Cheers!!
参考記事