はじめに
コンピューターが自然言語を比較し、類似性や特徴などを計算する場合、文章を数値化して処理を行います。具体的には、ベクトル化 (Embedding) することで、非構造化データの類似度も計算できるようになります。
Yellowfin には、AI搭載の自然言語クエリ (NLQ) で質問する機能が搭載されています。同機能は、OpenAI の ChatGPT と連携して自然言語を処理していますが、ChatGPT などの生成 AI が自然言語を取り扱うためには、データのベクトル化技術が欠かせません。
本記事では、文章のベクトル化とベクトル DB に関して、簡単に記述したいと思います。
ベクトル
ベクトルとは向きと大きさを持った量のことを意味します。
以下のイメージでは、A 点と B 点は、それぞれ異なる向きと大きさを持っています。
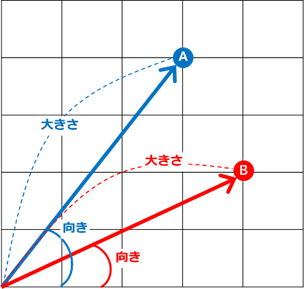
ベクトル化された文章や単語は、2 点間の距離や方向などを計算することで、類似度を計算することができます。
ベクトル間の類似度を算出する代表的な方法としては、以下の 3 つが挙げられます。
| 手法 | 説明 |
|---|---|
| ユークリッド距離 | ベクトルの距離 |
| コサイン類似度 | ベクトルの方向の類似度 |
| 内積 | ベクトルの方向と大きさの積 |
文章や画像の類似性を図る場合、コサイン類似度を用いることが一般的です。
上記以外にも、縦横の距離の合計で測るマンハッタン距離など、様々な手法があり、用途によって使い分けが必要です。
実践
実際に文章をベクトル化して、類似性を測ってみたいと思います。
文章や画像をベクトル化できる深層学習モデル Sentence Transformer を使って、Python でベクトル化の処理を行います。そのため、まずは Sentence Transformer のインストールを行います。
pip install sentence_transformers
Sentence Transformerには様々なモデルが実装されていますが、この中からマルチ言語に対応可能な distiluse-base-multilingual-cased-v2 を使用します。
モデル一覧に関しては、下記リンクをご参照ください。
上記モデルと採用して、文章をベクトル化するサンプルコードです。
from sentence_transformers import SentenceTransformer
#モデルの読み込み
model = SentenceTransformer('sentence-transformers/distiluse-base-multilingual-cased-v2')
#ベクトル化する文章
sentence = ['これはペンです']
#出力内容の確認
embedding = model.encode(sentence)
print(embedding.shape)
#ベクトルの表示
print(embedding)
上記を実行すると、下記がコンソールに表示され、512 次元のベクトルが 1 つ出力されたことが確認できます。
(1, 512)
続いて、512 次元のベクトル値が表示されます。これが、文章をベクトル化したデータです。
[[ 6.71954229e-02 2.75416337e-02 3.10154893e-02 3.42289940e-03
-4.85351831e-02 7.06919879e-02 -3.40428241e-02 2.51202807e-02
...
3.03332713e-02 4.38156258e-03 1.30295400e-02 3.87246497e-02
2.78264540e-03 -8.79379362e-03 3.05766687e-02 3.49475369e-02]]
今度は複数の文章を読み込んで、それぞれの類似性を算出します。
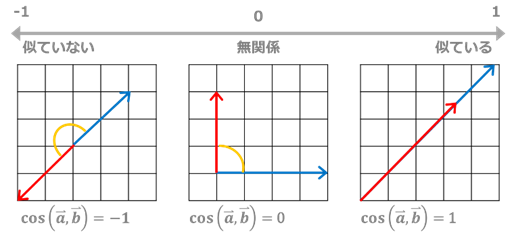
類似性を図る手法として、コサイン類似度を用います。コサイン類似度とは、2つのベクトルがなす角のコサイン値のことで、-1~1 の範囲に正規化されます。-1なら反対向きのベクトルで「完全に似ていない」、1 なら同じ向きのベクトルで「完全に似ている」ことになります。
コサイン類似度で算出した結果を、ヒートマップに表示します。
import numpy as np
import seaborn as sns
import matplotlib.pylab as plt
from sklearn.metrics.pairwise import cosine_similarity
from sentence_transformers import SentenceTransformer
#モデルの読み込み
model = SentenceTransformer('sentence-transformers/distiluse-base-multilingual-cased-v2')
#比較する複数文章を配列に格納
sentences = [
"This is a pen",
"これはぺんです",
"That is a penguin",
"あれはペンギンです",
"I love The Penguin Band",
"私はペンギンバンドの大ファンです",
]
#文章をベクトル化してコサイン類似度で比較
embedding = model.encode(sentences)
comparison = cosine_similarity(embedding)
#比較した結果をヒートマップで表示
ax = sns.heatmap(comparison, annot=True, cmap="Reds")
plt.show()
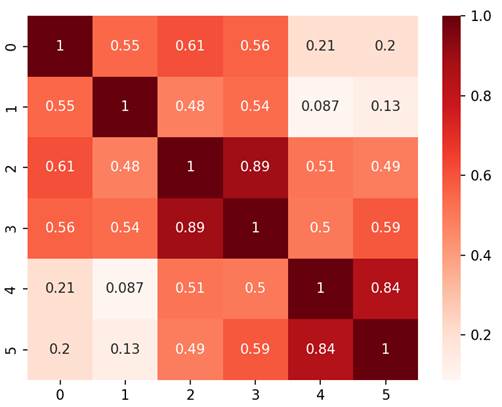
ヒートマップで類似性を確認する限り、日本語と英語の類似性は高い様子です。
「That is a penguin」と「あれはペンギンです」は 0.89 と高い類似性を見せています。
他方「This is a pen」 と 「これはペンです」の類似性だけ低い結果が出ています。荒井注がご存命であれば、この事実をどのように捉えるでしょうか。
ベクトル DB
最後に、ベクトル DB に関して記述します。
世の中には、pinecone などの無料で利用できるベクトル DB がいくつかあります。クラウド上のサービスなので、自分で環境構築する必要がなく、お手軽に利用できます。私も pinecone を活用していますが、このようなサービスが無料で利用できるのもすごいことですね。
一方、本記事の中では、Windows OS 上で稼働する PostgreSQL をベクトル DB として活用する手段を取り扱います。
PostgreSQL に pgvector を適用することで、PostgreSQL をベクトル DB として利用できるようになります。
事前準備
後述の手順を実行する上で、Build Tools for Visual Studio の x64 Native Tools Command Prompt と、Git のインストールが必要となります。
それぞれのインストール手順は、下記を参考にさせていただきました。
- Build Tools for Visual Studio - x64 Native Tools Command Prompt
- Git
インストールとビルド
x64 Native Tools Command Prompt を管理者権限で開き、下記コマンドを順に実行します。
set "PGROOT=C:\Program Files\PostgreSQL\16"
cd %TEMP%
git clone --branch v0.7.1 https://github.com/pgvector/pgvector.git
cd pgvector
nmake /F Makefile.win
nmake /F Makefile.win install
psql を開き、対象となるデータベースに接続したのち、下記コマンドを実行します。
demo-# CREATE EXTENSION vector;
ここまでの手順は、下記を参考にさせていただきました。
データ格納
ベクトルデータを格納するテーブルを作成します。
pgvector を有効にすると、vector 型が使えるようになります。カッコ内で指定する数値は次元数で、先のプログラムの出力に合わせて 512 を指定しています。
CREATE TABLE embedding (sentence varchar(100), embedding vector(512));
自然言語を sentence 列に、ベクトルデータを vector 列にそれぞれ登録します。
insert で登録する場合は以下の構文です。データ量が大きいときは、import した方が良いかと思います。
insert into embedding values ('I love The Penguin Band', '[1.50379296e-02, ... ,-5.78176863e-02]'
psql のプロンプトから insert を実行しようとすると、文字数制限に引っかかって大変だったため、この処理は PgAdmin から実施しました。
検索
格納したデータから類似性の高いデータを、最近傍検索で検索します。
pgvector には、ベクトル用に以下の演算子が準備されています。
| 演算子 | 説明 |
|---|---|
| <-> | ユークリッド距離 |
| <=> | コサイン類似度 |
| <#> | 内積に-1を乗算 |
| + | 加算 |
| – | 減算 |
| * | 乗算 |
この中から、コサイン類似度を使って、「これはペンですか?」に類似度の高い上位 2 文章を検索します。
そのためのクエリが以下になります。
order by に指定したベクトルは「これはペンですか?」をベクトル化したデータです。
SELECT * FROM public.embedding
order by embedding <=>
'[5.72404340e-02, ... , 3.56294364e-02]'
LIMIT 2;
クエリは下記の結果を返しました。
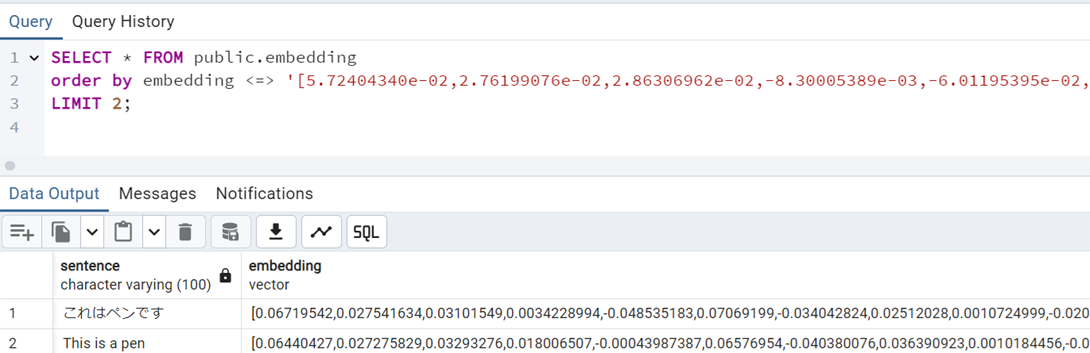
見事、ベクトル化されたデータを使って、自然言語の類似性検索を実行することができました。めでたし。
最後に
文章をベクトル化し、ベクトル化したデータをベクトル DB に格納して活用するまでの流れを説明しました。
今後、類似の内容をさらに深堀して、記事にできればと思います。
では皆様、良いデータ分析を!!
参考情報