自分用にMediaPipeのHolisticでlandmarkを取得した結果をまとめました。
holisticを使うと画像中の人物に対してpose, face, right_hand, left_handのランドマーク推定をまとめて行ってくれます。
下準備
imageに対してmediapipeを適用します。
import mediapipe as mp
import cv2
# 初期設定
mp_holistic = mp.solutions.holistic
holistic = mp_holistic.Holistic(
static_image_mode=True,
min_detection_confidence=0.5)
image = cv2.imread('画像パス')
results = holistic.process(
cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
resultsにすべての結果が格納されています。
以下、resultsからそれぞれのランドマークを抽出します。
pose
公式ドキュメント (https://google.github.io/mediapipe/solutions/holistic.html#python-solution-api) に載っていますが、以下の2つどちらを実行しても、姿勢推定からの「鼻のx座標」を取得できるようです。
results.pose_landmarks.landmark[mp_holistic.PoseLandmark.NOSE].x
results.pose_landmarks.landmark[0].x
鼻は0番目らしい。
上記の "[mp_holistic.PoseLandmark.NOSE]" は、以下の図のランドマークの名前に対応しています。"NOSE"のように大文字にするといいです。
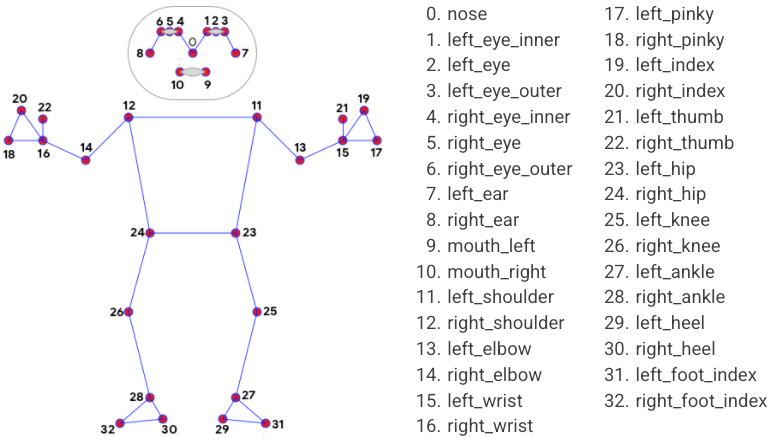
出典:https://google.github.io/mediapipe/solutions/pose.html#pose-landmark-model-blazepose-ghum-3d
また、以下のコードからランドマークの名前一覧を取得することもできます。
for index in range(len(mp_holistic.PoseLandmark)):
print(mp_holistic.PoseLandmark(index).name)
NOSE
LEFT_EYE_INNER
LEFT_EYE
LEFT_EYE_OUTER
RIGHT_EYE_INNER
RIGHT_EYE
RIGHT_EYE_OUTER
LEFT_EAR
RIGHT_EAR
MOUTH_LEFT
MOUTH_RIGHT
LEFT_SHOULDER
RIGHT_SHOULDER
LEFT_ELBOW
RIGHT_ELBOW
LEFT_WRIST
RIGHT_WRIST
LEFT_PINKY
RIGHT_PINKY
LEFT_INDEX
RIGHT_INDEX
LEFT_THUMB
RIGHT_THUMB
LEFT_HIP
RIGHT_HIP
LEFT_KNEE
RIGHT_KNEE
LEFT_ANKLE
RIGHT_ANKLE
LEFT_HEEL
RIGHT_HEEL
LEFT_FOOT_INDEX
RIGHT_FOOT_INDEX
face
faceについては、以下の画像のように468点取得しているようです。本当に小さすぎて見えませんが、ランドマークに赤の数字で、0〜467のインデックスが書かれています。それぞれに固有の名前はおそらくありません。

出典:https://github.com/google/mediapipe/blob/a908d668c730da128dfa8d9f6bd25d519d006692/mediapipe/modules/face_geometry/data/canonical_face_model_uv_visualization.png
座標を出力してみます。
print(results.face_landmarks.landmark)
[x: 0.2543584108352661
y: 0.7283821105957031
z: 7.437561180267949e-07
, x: 0.3921686112880707
y: 0.7136784195899963
z: -0.05727102980017662
,
︙
, x: 0.21709156036376953
y: -0.0903255045413971
z: -0.17543014883995056
]
ランドマーク0〜467のx, y, z座標が順番に表示されます。
right_hand
上記のように取得した座標を一個ずつ取り出して、listに格納してみます。
import pandas as pd
label = []
csv = []
if results.right_hand_landmarks:
for index, landmark in enumerate(results.right_hand_landmarks.landmark):
label.append("rHand_" + str(index) + "_x")
label.append("rHand_" + str(index) + "_y")
label.append("rHand_" + str(index) + "_z")
csv.append(landmark.x)
csv.append(landmark.y)
csv.append(landmark.z)
df = pd.DataFrame([csv], columns=label)
handについては個々のランドマークに名前がついています。

出典:https://google.github.io/mediapipe/solutions/hands.html#hand-landmark-model
left_hand
右手と同様です。
results.left_hand_landmarks.landmark
まとめ
'画像パス'に対してmediapipeを適用し、上記すべてのランドマークの描画と座標を取得します。
以下のコードを実行するとランドマーク付き画像とDataFrameが出力されます。
・入力画像

Photo by Allef Vinicius on Unsplash
・出力画像

両手、顔、ポーズの一部が検出できてます。MediaPipeすごい。
・出力DataFrame
pose_0_x pose_0_y pose_0_z pose_1_x pose_1_y ... l_hand_19_y l_hand_19_z l_hand_20_x l_hand_20_y l_hand_20_z
0 0.50371 0.170424 -0.594914 0.524459 0.122455 ... 0.35628 -0.002404 0.521894 0.372454 0.003072
[1 rows x 1629 columns]
import mediapipe as mp
import cv2
import numpy as np
import pandas as pd
from PIL import Image
# 初期設定
mp_holistic = mp.solutions.holistic
holistic = mp_holistic.Holistic(
static_image_mode=True,
min_detection_confidence=0.5)
mp_drawing = mp.solutions.drawing_utils
drawing_spec = mp_drawing.DrawingSpec(thickness=1, circle_radius=1)
def main():
image = cv2.imread('画像パス')
results = holistic.process(
cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
# ランドマークのdataframeとarray_imageを取得
landmark_df, landmark_bgr = landmark(image)
# 画像を整形
landmark_rgb = cv2.cvtColor(landmark_bgr, cv2.COLOR_BGR2RGB) # BGRtoRGB
landmark_image = Image.fromarray(landmark_rgb.astype(np.uint8))
# 結果を出力
print(landmark_df)
landmark_image.show()
# 顔のランドマーク
def face(results, annotated_image, label, csv):
if results.face_landmarks:
# ランドマークを描画する
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=results.face_landmarks,
connections=mp_holistic.FACEMESH_TESSELATION,
landmark_drawing_spec=drawing_spec,
connection_drawing_spec=drawing_spec)
for index, landmark in enumerate(results.face_landmarks.landmark):
label.append("face_"+str(index) + "_x")
label.append("face_"+str(index) + "_y")
label.append("face_"+str(index) + "_z")
csv.append(landmark.x)
csv.append(landmark.y)
csv.append(landmark.z)
else: # 検出されなかったら欠損値nanを登録する
for index in range(468):
label.append("face_"+str(index) + "_x")
label.append("face_"+str(index) + "_y")
label.append("face_"+str(index) + "_z")
for _ in range(3):
csv.append(np.nan)
return label, csv
# 右手のランドマーク
def r_hand(results, annotated_image, label, csv):
if results.right_hand_landmarks:
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=results.right_hand_landmarks,
connections=mp_holistic.HAND_CONNECTIONS)
for index, landmark in enumerate(results.right_hand_landmarks.landmark):
label.append("r_hand_"+str(index) + "_x")
label.append("r_hand_"+str(index) + "_y")
label.append("r_hand_"+str(index) + "_z")
csv.append(landmark.x)
csv.append(landmark.y)
csv.append(landmark.z)
else:
for index in range(21):
label.append("r_hand_"+str(index) + "_x")
label.append("r_hand_"+str(index) + "_y")
label.append("r_hand_"+str(index) + "_z")
for _ in range(3):
csv.append(np.nan)
return label, csv
# 左手のランドマーク
def l_hand(results, annotated_image, label, csv):
if results.left_hand_landmarks:
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=results.left_hand_landmarks,
connections=mp_holistic.HAND_CONNECTIONS)
for index, landmark in enumerate(results.left_hand_landmarks.landmark):
label.append("l_hand_"+str(index) + "_x")
label.append("l_hand_"+str(index) + "_y")
label.append("l_hand_"+str(index) + "_z")
csv.append(landmark.x)
csv.append(landmark.y)
csv.append(landmark.z)
else:
for index in range(21):
label.append("l_hand_"+str(index) + "_x")
label.append("l_hand_"+str(index) + "_y")
label.append("l_hand_"+str(index) + "_z")
for _ in range(3):
csv.append(np.nan)
return label, csv
# 姿勢のランドマーク
def pose(results, annotated_image, label, csv):
if results.pose_landmarks:
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=results.pose_landmarks,
connections=mp_holistic.POSE_CONNECTIONS)
for index, landmark in enumerate(results.pose_landmarks.landmark):
label.append("pose_"+str(index) + "_x")
label.append("pose_"+str(index) + "_y")
label.append("pose_"+str(index) + "_z")
csv.append(landmark.x)
csv.append(landmark.y)
csv.append(landmark.z)
else:
for index in range(33):
label.append("pose_"+str(index) + "_x")
label.append("pose_"+str(index) + "_y")
label.append("pose_"+str(index) + "_z")
for _ in range(3):
csv.append(np.nan)
return label, csv
# imageに対してmediapipeでランドマークを表示、出力する
def landmark(image):
results = holistic.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
annotated_image = image.copy()
label = []
csv = []
# 姿勢→顔→右手→左手の順番でランドマーク取得
label, csv = pose(results, annotated_image, label, csv)
label, csv = face(results, annotated_image, label, csv)
label, csv = r_hand(results, annotated_image, label, csv)
label, csv = l_hand(results, annotated_image, label, csv)
df = pd.DataFrame([csv], columns=label)
return df, annotated_image
if __name__ == "__main__":
main()
偉大な先輩とストイックな同期に感謝します。