NeurIPS2024では"Multi-Agent"が題名に入っている研究が34件ありました。
それらのいくつかをトピックごとに紹介します。
マルチエージェント深層強化学習
訓練方法/最適化手法についての提案・改善
- Li et al.の研究では、パラメータ共有によってポリシーが均質化してしまうことを防ぐ新しいアプローチを提案しています。パラメータ共有による訓練の効率化を維持しながらポリシーの多様性を促進できます。
- マルチエージェント強化学習を模倣学習に応用した研究が二つあったのも興味深いです(Bui et al.とTang et al.)。人間の行動履歴をエキスパートデータとして学習し、人間が思いつかないようなチームプレーを創出するのが目的です。
- Hu et al.では、大きなモデルをいかに効率よく学習させるかとして、Dynamic Sparse Training (DST)のマルチエージェントへの拡張を提案しています。DSTとは最適な「疎な」ニューラルネットワークのパラメータを見つけるテクニックのことです。
- Heterogeneousなエージェント群についての学習手法についても研究があります。Heterogeneous設定では、エージェントの方策を一個ずつ逐次的に更新していきます。一個前までのエージェントの方策を見て更新していきますが、これでは一個前までのエージェントの方策に自分の方策の更新が強く依存してしまいます。この問題を防ぐために適切にエントロピー項を設計し、より幅広く探索させることを意図した研究があります(Dou et al.)。
- 拡散モデルを用いた手法も出始めています。Zhu et al.では、拡散モデルによってオフラインデータにはないようなtrajectoryを生成し、マルチエージェントの学習を効率化させています。
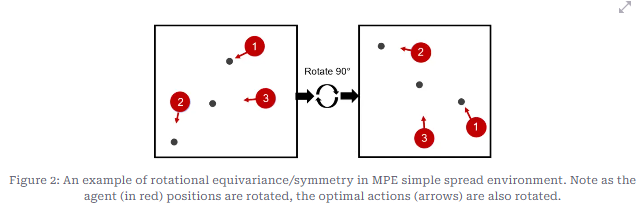
- McClellan et al.ではマルチエージェント環境が時に対象性を持つことに着目します(下図参照。本文より引用)対称性といえばGraph Neural Networkですが、本論文ではGNNがマルチエージェント深層強化学習の学習を助けることを紹介しています。
- 他にもマルチエージェント深層強化学習のためのドメイン適応を行う研究(Jiang et al.)や安全性を担保する研究(https://nips.cc/virtual/2024/poster/93564)もあります。
新モデルの提案
- D. Lee et al.は動物の認知プロセスから着想を得て、各エージェントがあるキャラクター(特性のようなもの)を帯びていると考えます。そして、エージェントたちは他のエージェントの観測と行動のペアからそのエージェントのキャラクターを推測し、今後の行動を予測します。
- 階層型のチームの研究として、Ding et al.があります。この論文では、上位レベルのエージェントは下位レベルのエージェントよりも先に意思決定を行い、上位エージェントがその行動を下位エージェントに伝達します。こうすることで、チームプレーの実現をスムーズにしています。理論的には、SeqCommによって学習されたポリシーは、単調に改善され、収束することが保証されていることを証明しています
マルチエージェント×LLM
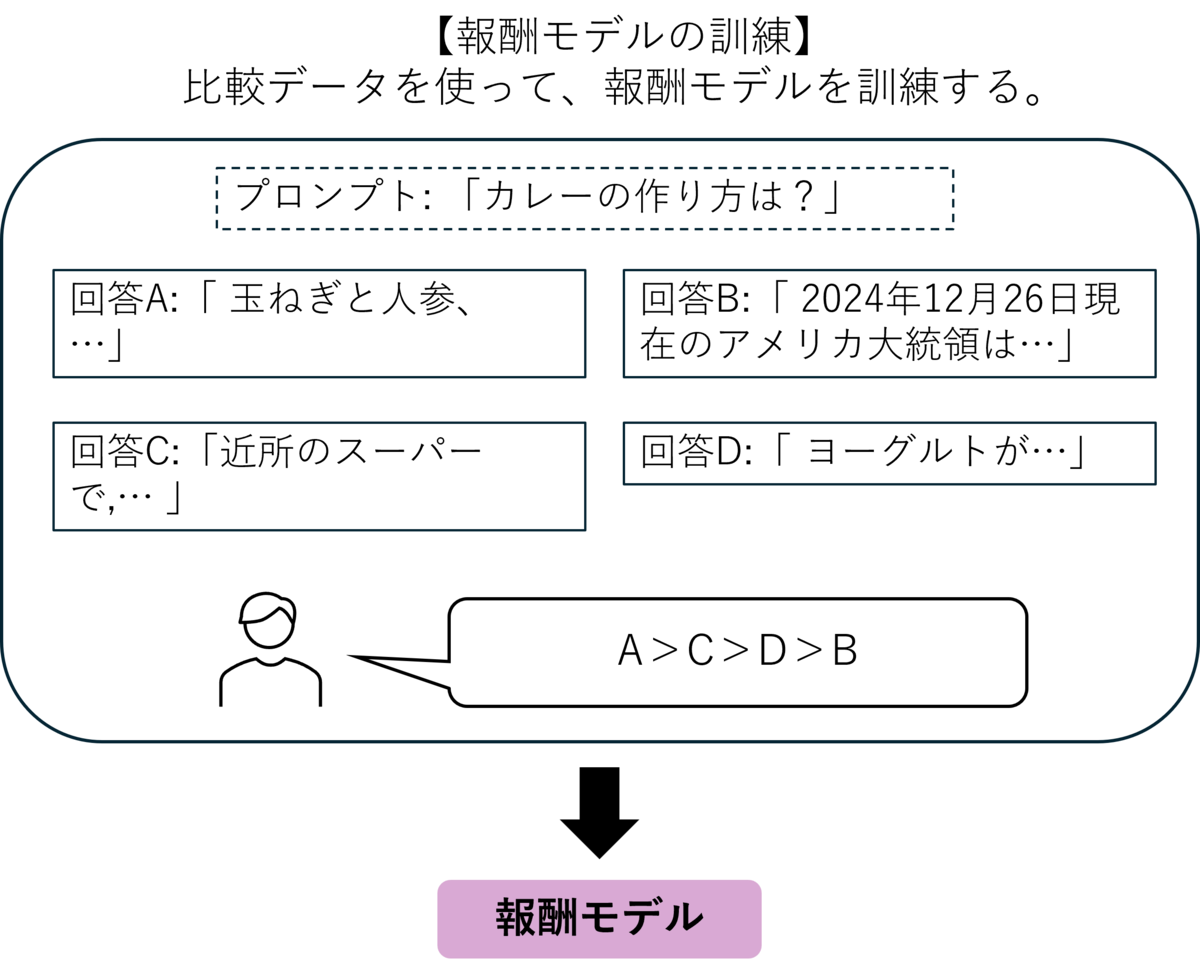
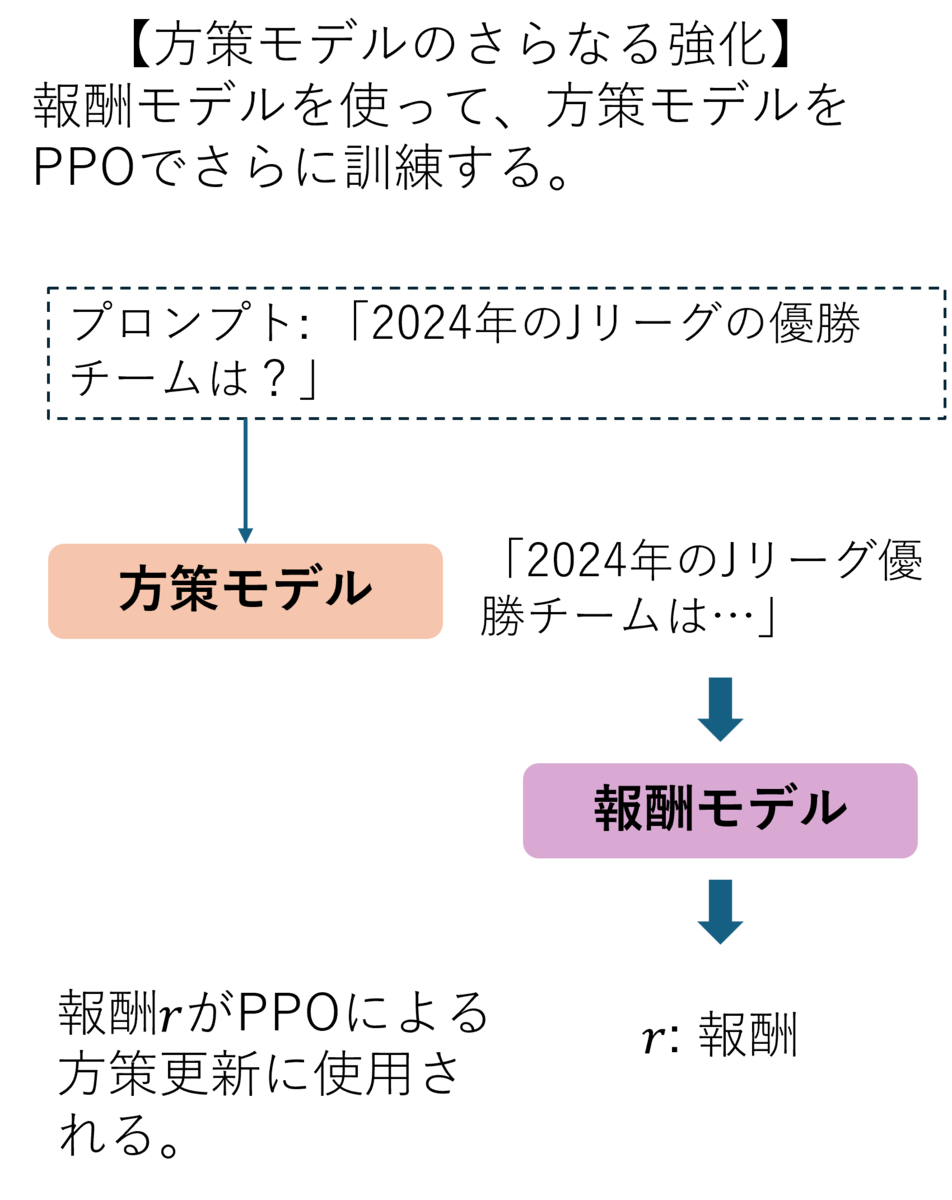
- 最近の研究では、LLMにRLHF(Reinforcement Learning from Human Feedback)が効果的といわれています。特にPPOを使用した一般的なRLHFは下の3つの図で説明できます。
まず、事前学習時にはなかった情報をPretrained modelに教え込ませるSupervised Fine Tuning (SFT)を行います。その次に、あるプロンプトに対するある回答がどれくらい良いかを評価する報酬モデルを訓練します。これは人間が複数の回答候補をランク付けしたものを教師データとします。これがHuman Feedbackと言われる理由です。最後にSFTによって訓練された言語モデルを方策モデルとして、報酬モデルと合わせて強化学習の最適化アルゴリズムであるPPOによってそれらを訓練します。
Ma et al.ではこのFine Tuning作業を複数のエージェントで行うことで精度の向上をはかっています。

- また、"Language Grounded Multi-Agent"(言語に基づくマルチエージェント)の研究も盛んに行われています。エージェントどうしが人間には解読できない通信プロトコルでコミュニケーションを取ってほしくない状況もしばしばあります。たとえば、ロボットと人間の共同作業などです。Li et al.の研究ではチームワークに大事な抽象的なコミュニケーション空間と自然言語の埋め込み空間をうまく整合させることで、新しいタスクにもチームワークができるようにしています。
- ほかにも金融分野への応用(Yu et al.)やGithubのissue解決への応用(Tao et al.)もあります。
その他の応用研究
マルチエージェントの応用研究も複数あります。複数の風力発電機の協調制御を扱ったMonroc et al.や自動運転を扱ったLiu et al.やWu et al.、数学の問題を解くためのLLMプロンプト技術の提案したLei et al.などがあります。
ライブラリ/ベンチマーク
オープンソースのライブラリやベンチマーク環境の発表も目につきました。
RutherfordらのJAXによるマルチエージェント深層強化学習ライブラリ(JAXMARL)やマルチエージェント研究のためのベンチマークツール(BenchMARL)などがあります。
このブログは株式会社EfficiNet Xのテックブログです。