ディープラーニング入門でMNISTを使った例をやった後、なにか応用的なことをやってみたいけど良い例が思いつかないという方はいるんじゃないでしょうか。
今回はそういった方の手助けになればと思い、Webカメラに映った数字を判別するものをつくってみようと思います。
※chainerでMLPくらいは試したことがある方を想定しており、本記事ではそのモデル部分や学習のさせ方などについては触れません。
Webカメラの映像を映す
まずはWebカメラの映像を表示させてみましょう。OpenCVを使えば簡単にできるようです。
なお、今回はLogicoolさんの"HD Webcam C270"を使用しています。
# !/usr/bin/python
# coding: utf-8
import cv2
def main():
#Webカメラの映像表示
capture = cv2.VideoCapture(0)
if capture.isOpened() is False:
raise("IO Error")
while True:
#Webカメラの映像とりこみ
ret, image = capture.read()
if ret == False:
continue
#Webカメラの映像表示
cv2.imshow("Capture", image)
k = cv2.waitKey(10)
#ESCキーでキャプチャー画面を閉じる
if k == 27:
break
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
実行時にセキュリティソフトにWebカメラへのアクセスを許可するか聞かれたら、許可してください。
画像を取得して処理する
常時数字の判別をするよりは何かキーを押したら、そのときの画像を取得して処理が行われるようにしておきたいです。最終的には数字判別処理に渡したいのですが、ここではとりあえず動作確認用にメッセージが表示されるだけにしておきます。
どのキーがどの数字に割り当てられているのかは参考記事を参照してください。
# !/usr/bin/python
# coding: utf-8
import cv2
def main():
#Webカメラの映像表示
capture = cv2.VideoCapture(0)
if capture.isOpened() is False:
raise("IO Error")
while True:
#Webカメラの映像とりこみ
ret, image = capture.read()
if ret == False:
continue
#Webカメラの映像表示
cv2.imshow("Capture", image)
k = cv2.waitKey(10)
#Eキーで処理実行
if k == 101:
print("処理を実行")
#ESCキーでキャプチャー画面を閉じる
if k == 27:
break
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
取得画像の前処理
取得した画像全体を入力として渡すのは大きいように思ったので、中央の100×100の部分を切り抜きたいと思います。
まずは、Webカメラで取得した画像の大きさを確認します。
if k == 101:
print(image.shape)
Eキーの処理部分を変えていきます。OpenCVでは画像がNumpy配列なのでhogehoge.shapeとすれば要素の長さを知ることができます。今回の例だと、(480, 640, 3)と出力されるので、縦480×横640の大きさだとわかります。
大きさがわかったので中央の100×100を切り抜く処理は以下のようになります。画像を保存してみて切り抜きがうまくいってるか確認しましょう。
if k == 101:
img = image[190:290,270:370]
cv2.imwrite("img.jpg",img)
あとは、この切り抜いた画像をMNISTのときと同じ入力形式に合わせるだけです。具体的には以下の処理です。
- Webカメラの画像はカラーなのでまずはこれをグレースケールにします。
- 画像を28×28に縮小
- MNISTのときと同じ処理を行う
先ほどの中央部分の切り抜きと合わせてpreprocessing関数にまとめておきます。
import numpy as np
def preprocessing(img):
#中央部分の切り抜き
img = img[190:290,270:370]
#グレースケールへの変換
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#画像を28x28に縮小
img = cv2.resize(img, (28, 28))
#以下、学習時と同じ処理を行う
img = 255 - img
img = img.astype(np.float32)
img /= 255
img = np.array(img).reshape(1,784)
return img
数字の判別に使うMLPの設定
今回の数字読み取りにはchainer入門でも使われる簡単なMLPを使うことにします。
from chainer import Chain, serializers
import chainer.functions as F
import chainer.links as L
# 多層パーセプトロンモデルの設定
class MyMLP(Chain):
# 入力784、中間層500、出力10次元
def __init__(self, n_in=784, n_units=500, n_out=10):
super(MyMLP, self).__init__(
l1=L.Linear(n_in, n_units),
l2=L.Linear(n_units, n_units),
l3=L.Linear(n_units, n_out),
)
# ニューラルネットの構造
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
y = self.l3(h2)
return y
数字の判別は複数回行うでしょうから、最初に学習済みモデル(この例ではmy.model2)を読み込んでおくことにします。
※2017年7月10日追記
今回は上記のように定義されたMLPにMNISTのデータを使って学習させた結果(my.model2)を使っています。
読者の方がご自分で用意された学習済みデータを用いる場合、class MyMLPの中身を学習に用いたときのものと同じものに書き換えるのがスムーズかと思います。
そして、Eキーが押されたらその学習済みモデルを使って数字を判別し、結果を表示する処理を加えましょう。
def main():
# 学習済みモデルの読み込み
net = MyMLP()###追加部分###
serializers.load_npz('my.model2', net)###追加部分###
#Webカメラの映像表示
capture = cv2.VideoCapture(0)
if capture.isOpened() is False:
raise("IO Error")
while True:
#Webカメラの映像とりこみ
ret, image = capture.read()
if ret == False:
continue
#Webカメラの映像表示
cv2.imshow("Capture", image)
k = cv2.waitKey(10)
#Eキーで処理実行
if k == 101:
img = preprocessing(image)
num = net(img)###追加部分###
print(num.data)###追加部分###
print(np.argmax(num.data))###追加部分###
#ESCキーでキャプチャー画面を閉じる
if k == 27:
break
cv2.destroyAllWindows()
これで必要なものはすべて組み込めたはずです。
切り抜かれる部分の表示
処理上は問題ありませんが、Webカメラを操作するうえでは切り抜き部位がどこかわかったほうが便利です。そのため、Webカメラの映像中に切り抜かれる部分を赤枠で示しておきます。
main()のWebカメラの映像表示部分
cv2.imshow("Capture", image)
ここを
cv2.rectangle(image,(270,190),(370,290),(0,0,255),3)
cv2.imshow("Capture", image)
こうするだけです。
試してみる
実行するとこのような感じでWebカメラに映ってる中心に赤枠が出るので、数字を枠に入れてEキーを押してみましょう。

しかし、うまく2と判定されるかと思ったらされない!
前処理中に画像がどうなっているのかを見てみると、
def preprocessing(img):
img = img[190:290,270:370]
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.GaussianBlur(img, (3, 3), 0)
img = cv2.resize(img, (28, 28))
img = 255 - img
img = img.astype(np.float32)
cv2.imwrite("img.jpg",img)###前処理中の状態###
img /= 255
img = np.array(img).reshape(1,784)
return img
 前処理中の状態
前処理中の状態
どうも背景が暗いのが原因で数字部分の抽出がうまくいってなさそうです。
試しに閾値を設定して黒色が濃い部分だけを抜き出すようにしてみます。
def preprocessing(img):
img = img[190:290,270:370]
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.GaussianBlur(img, (3, 3), 0)
img = cv2.resize(img, (28, 28))
res, img = cv2.threshold(img, 70 , 255, cv2.THRESH_BINARY)###閾値による処理を追加###
img = 255 - img
img = img.astype(np.float32)
cv2.imwrite("img.jpg",img)
img /= 255
img = np.array(img).reshape(1,784)
return img
閾値処理を追加したことで数字部分を抽出し、うまく判定できるようになりました。
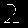 前処理中の状態(閾値処理追加後)
前処理中の状態(閾値処理追加後)

ほかの数字も書いて試してみましたが、位置や大きさを調節しないと読み取りが難しいものもありました。次のステップでどうすればもっと良いものができるのか考えるのもおもしろいかもしれませんね。
また、Webカメラと連携させることで遊びの幅が広がると思うので、なにかつくってみるきっかけになれば幸いです。
最後に今回つくったもののコード全体を載せておきます。
# !/usr/bin/python
# coding: utf-8
import cv2
import numpy as np
from chainer import Chain, serializers
import chainer.functions as F
import chainer.links as L
# 多層パーセプトロンモデルの設定
class MyMLP(Chain):
# 入力784、中間層500、出力10次元
def __init__(self, n_in=784, n_units=500, n_out=10):
super(MyMLP, self).__init__(
l1=L.Linear(n_in, n_units),
l2=L.Linear(n_units, n_units),
l3=L.Linear(n_units, n_out),
)
# ニューラルネットの構造
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
y = self.l3(h2)
return y
def preprocessing(img):
img = img[190:290,270:370]
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.GaussianBlur(img, (3, 3), 0)
img = cv2.resize(img, (28, 28))
res, img = cv2.threshold(img, 70 , 255, cv2.THRESH_BINARY)
img = 255 - img
img = img.astype(np.float32)
cv2.imwrite("img.jpg",img)
img /= 255
img = np.array(img).reshape(1,784)
return img
def main():
# 学習済みモデルの読み込み
net = MyMLP()
serializers.load_npz('my.model2', net)
#Webカメラの映像表示
capture = cv2.VideoCapture(0)
if capture.isOpened() is False:
raise("IO Error")
while True:
#Webカメラの映像とりこみ
ret, image = capture.read()
if ret == False:
continue
#Webカメラの映像表示
cv2.rectangle(image,(270,190),(370,290),(0,0,255),3)
cv2.imshow("Capture", image)
k = cv2.waitKey(10)
#Eキーで処理実行
if k == 101:
img = preprocessing(image)
num = net(img)
#cv2.imwrite("img.jpg",img)
print(num.data)
print(np.argmax(num.data))
#ESCキーでキャプチャー画面を閉じる
if k == 27:
break
cv2.destroyAllWindows()
if __name__ == '__main__':
main()