
こんにちは!
仕事でLambdaを使っているんですが、S3内のCSVの中身をさくっとクエリできちゃうAthenaのことを知ったので興味を持って調べてみました。この記事ではLambdaを使ってS3の中にあるCSVデータをクエリできるところまで持っていきます。実装はTypescriptで行います。
まずは仕組みをさくっと。
仕組みとしては単純で、AWS Glueに依存した仕組みです。GlueはAWSやJDBC準拠のソースに保存されたデータをクエリできるシステムなのですが、それをするには事前にDataCatalogを作成し、クエリするためのテーブル定義やスキーマ情報などのメタデータを格納しておきます。
Athenaでは、クエリの対象とするデータを格納するS3内のフォルダのパスを指定し、諸設定を行うと自動的にAWS Glueに新しいデータテーブルを生成してくれます。データテーブルのスキーマ情報は基本的にここで手動で書き込むんですが、面倒なので自動で実施するように設定することも可能です。あとはSQLで指示を送ればクエリ結果が返ってきます。この際のレスポンスタイムなどは下記にて実験していきます。
さっそく実践!!
この記事は基本的にオフィシャルのチュートリアルに基づいて作成しています。
⓪上記、オフィシャルのチュートリアルを一通り済ませ、自分でCSVやS3バケットをアレンジして別のデータベースやテーブルを作成してクエリを試してみる
①⓪で作成したS3バケットに「test-input」フォルダを作成する
②score.csvというファイルに300名分の学生ID、国語、数学、理科、社会、英語の5教科の点数を格納し、test-inputフォルダに置く(置く前にgzip圧縮してもいい)
③新規でmytestデータベースにtest_tableという名前のテーブルを作成し、先ほど作成したS3バケットのtest-inputフォルダをデータソースとして指定する。
test_tableのテーブル構成は下記のようにする。
● "id" → string
● "japanese" → int
● "math" → int
● "science" → int
● "socialstudies" → int
● "english" → int
④Githubからプロジェクトをクローン。Athena-tutorialというディレクトリが生成されるはずなので、エディタなどで表示してご活用ください。
まずはコマンドラインでnpm installしてモジュールをインストールする。
※ もしtscコマンドなどが使えなければドキュメントを参照ください
⑤早速コードを見ていきます。
import * as AWS from 'aws-sdk';
import { Athena } from 'aws-sdk';
const athena = new AWS.Athena({
region: 'ap-northeast-1'
});
export async function query(queryString: string): Promise<any> {
const id = await startQuery(queryString);
if (!id) throw new Error('cannot get the QueryExecutionId.')
await waitForComp(id);
return await getResult(id);
}
async function startQuery(queryString: string): Promise<Athena.QueryExecutionId | undefined> {
const data = await athena.startQueryExecution({
QueryString: queryString,
ResultConfiguration: {
OutputLocation: 's3://{作成したS3バケット}/queried'
}
}).promise();
return data.QueryExecutionId;
}
async function waitForComp(id: Athena.QueryExecutionId): Promise<void> {
let status = await athena.getQueryExecution({
QueryExecutionId: id
}).promise();
while(status.QueryExecution?.Status?.State != 'SUCCEEDED') {
await sleep(100);
status = await athena.getQueryExecution({
QueryExecutionId: id
}).promise();
}
}
async function getResult(id: Athena.QueryExecutionId): Promise<any> {
const data = await athena.getQueryResults({
QueryExecutionId: id
}).promise();
let res: any[] = [];
let keys: any[] = [];
if (!data.ResultSet?.Rows) return res;
for (let i = 0; i < data.ResultSet.Rows.length; i++) {
let items = [];
const rowData = data.ResultSet.Rows[i].Data;
if (rowData == undefined) continue;
for (const d of rowData) {
if (i == 0) keys.push(d.VarCharValue);
else items.push(d.VarCharValue);
}
if (i == 0) continue;
const item = items.reduce((result: any, current, index: number) => {
result[keys[index]] = current;
return result;
}, {});
res.push(item);
}
return res;
}
function sleep (msec: number) {
return new Promise(resolve => setTimeout(resolve, msec));
}
さて、athena.tsの19行目の{作成したS3バケット}を上記で作成したバケット名に変更して保存してください。
これらのコードの説明は以下に説明があるので省きます。
import * as athena from '../athena';
(async () => {
const queryString = 'SELECT * from mytest.test_table;'
// const queryString = 'SELECT * from mytest.test_input;'
// const queryString = 'SELECT * from athena_tutorial_db.test_input;'
const aa = await athena.query(queryString);
console.log(aa);
})();
ここでコメントアウトされているクエリの文字列ですが、後ほど使うので放置してください。
⑦早速実行してみる
ts-node query-tester
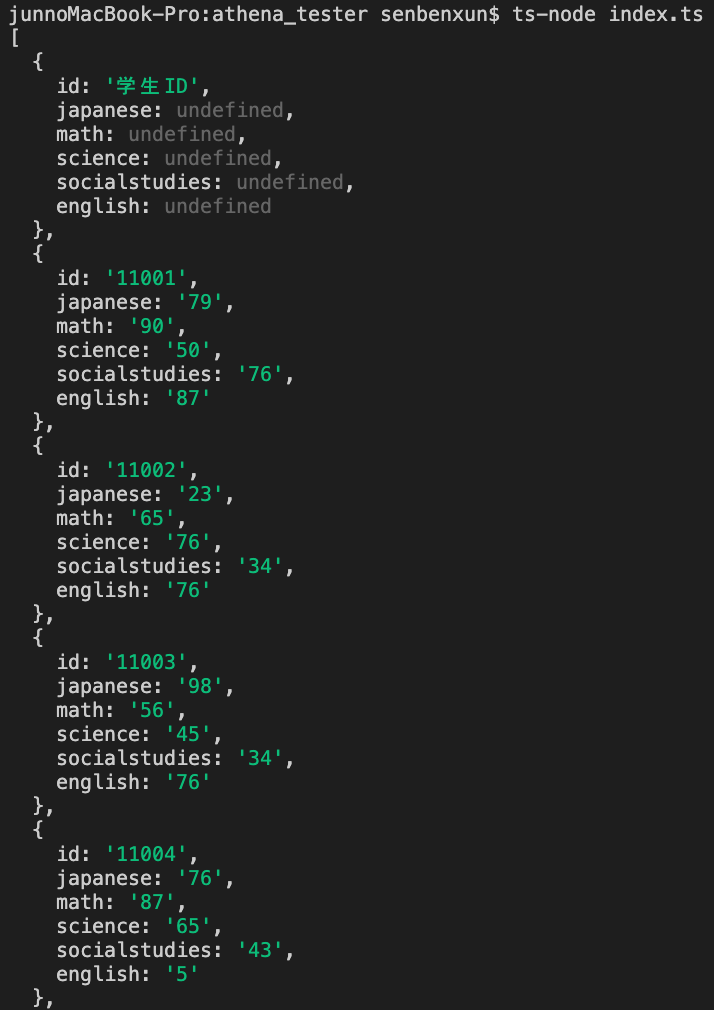
さて、コンソール上には下記のように結果が返ってきます。
何が起きたのか?ざっくりとクエリの際のメカニズムを解説していきます。
Athenaではクエリに要する時間はデータ量などによってまちまちなので、クエリの送信と進捗確認と結果取得とが切り分けられています。要はデータクエリには**「クエリを送信する」「完了を待つ」「結果を取得する」の三段階を踏むわけです。
まずstartQuery関数ですが、ご覧の通りクエリを送信するだけの機能です。ここで返却されるQueryExecutionIdは、結果待ち及び結果の取得に必要なものになるので、これだけ返却します。
なお、クエリの際にテーブル名を指定する際には{DB名}.{テーブル名}とするようになっています。
次のwaitForCompではQueryExecutionIdを渡し、ステータス確認を繰り返しています。合間にsleep関数を挟むのが奨励されています。
次のgetResultでは少しデータをいじくりまわしています。理由は返却されるデータ構造です。
クエリ結果にたどり着くにはdata.ResultSet.Rowsにアクセスする必要があります。Rowsにはクエリ結果の配列が入っていますが、個々の要素はオブジェクトになっていて、Dataプロパティに要素の各値が配列で入っています。この値も独特で、全てVarCharValueプロパティの中に文字列化して格納されています。
格納される順番は、「スキーマにある列名」→「CSVの先頭行から順に」**という感じですので、forループではインデックスが0の場合にはkeyとして格納することにしているわけです。
さて、ここで重要なことはアウトプットされた先頭の要素です。
{
id: '学生ID',
japanese: undefined,
math: undefined,
science: undefined,
socialstudies: undefined,
english: undefined
}
となっていますが、これはAthenaで作ったスキーマにしたがって、列名の行から読み込んでいるために起こる現象です。japaneseなど、undefinedが返っているのは、スキーマ定義と実値のデータ型に齟齬があるためです。この場合にはintで定義したのにstringが格納されていたからこうなっています。
Athenaでは、指定したデータソースのS3バケット内のファイルを昇順に読み込む性質がありますが、そのせいでこのような列名の行まで要素として読み込んでしまいます。これはどうすれば解消するでしょうか?
クローラによるテーブルの自動生成
Athenaでテーブルを定義する際には手動生成が前提になりますが、これには型定義を自分で自由に設定できる利点の一方で、上述のように要素名の行と具体的な値の行とを区別なくクエリしてしまう欠点があります。テーブル定義を完全に省こうとした場合、どうすればいいのか? 「クローラを使え」が答えです。
クローラとはAthenaの背後で使われているAWS Glueの中の機能であり、簡単にいうと必要なデータにアクセスして自動的にテーブルを形成してくれるためのデータセットです。この場合、アクセスするデータソースはS3以外にもDynamoDBなど複数から選択でき、分析を楽にしてくれるものです。Athenaで作るデータカタログも、全てはGlueに作成されるものです。
テーブルを生成する際、クローラを使ってテーブル生成を行うと、返り値はどのように変わるのか?さっそくやってみます。
⓪AWS Glueにアクセスし、テーブルのリストをみてみる。
Athenaで作成したテーブルもここに入っています。
AthenaはGlueのテーブルにアクセスしてクエリする機能だということがわかります。
クローラは、このテーブルを自動生成するために予め諸々のデータを設定しておくためのメタ情報になります。
①AWS Glueにアクセスし、「クローラの追加」をクリック
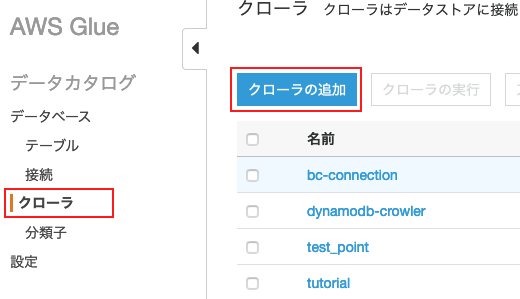
②クローラの名前を適当に入力してデータソースは新規作成を選択
※ 既存のテーブルで使っているパスにアクセスしたいなら「Existing catalog tables」から選択する
③クエリ対象としたいデータのパスを設定する。この際に接続を細かく設定しない。

④クエリによって使用するIAMロールを設定する。デフォルトは新規作成。
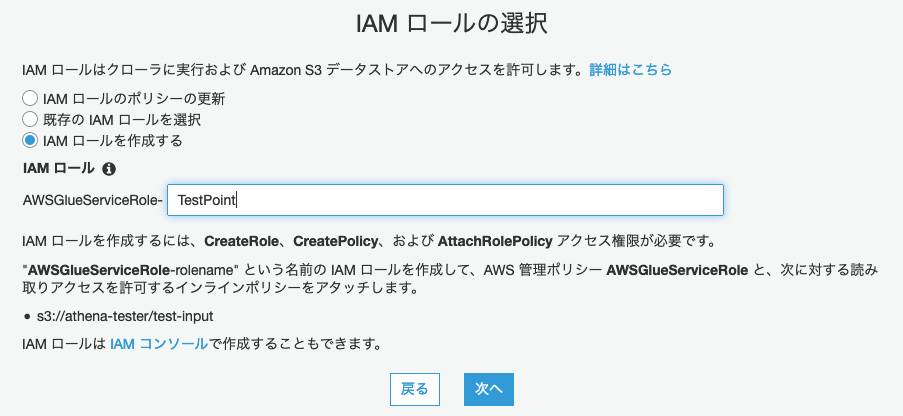
⑤スケジュールはオンデマンドとし、出力先のデータベースを選択、もしくは作成する。今回は先ほど作ったDBにテーブルを追加することにしたいので、ここは先ほど決めたDB名を選択する。
⑥あとは入力を確認すればクローラが出来上がるので、あとは「クローラの実行」をクリックしてしばらく待ちます。
⑦ローカルで作ったスクリプトに戻ります。今回は先ほどと同じDBに違うテーブルとして生成しているので、query-tester/index.tsのクエリ文をテーブル名だけtest_inputに書き換えて実行します。(4行目をコメントアウトして5行目のコメントアウトを解除)
コマンドはts-node query-tester
結果はどうでしたか?
おそらくは下記のようになり、要素名定義の行が無視されて出力されているでしょう。これはS3内にデータがいくつあっても同じ挙動となります。
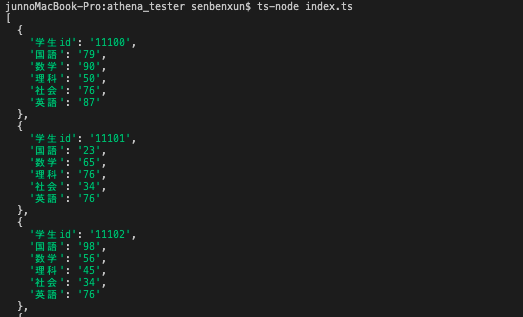
理由は、クローラを使ってテーブルを自動生成する際、要素名をファイル内から取得し、要素名を定義している行をデータの値と区別してくれるからです。
さて、ここまでくればAthenaで最低限のクエリを実行するための最低限の知見がたまったことと思います。
ここからはaws-cdkを使ってAWS Glueにクローラを生成し、Typescriptから呼び出してテーブルを作成し、クエリを行います。
CDKを使ってクローラをデプロイする
先ほどクローンしたリポジトリにはaws-cdkディレクトリがあり、この中がCDKコードです。
今回はCDKの勉強がメインではないので割愛しますが、中の構造は下記のようになっています。
aws-cdk
bin デプロイの際のエントリ
lib cdkのコンストラクチャをスクリプトで記述したコード
cdk.json デプロイの際のエントリを指定
package.json パッケージ
tsconfig.json typescriptの設定情報
では進めていきましょう。まずはコマンドラインで
cd aws-cdk
npm install
を実行してモジュールをインストールします。
そしてaws-cdk/bin/index.tsを開いてください。
import 'source-map-support/register';
import * as cdk from '@aws-cdk/core';
import { AthenaStack } from '../lib/AthenaStack';
const account = 'AWS_ID';
const app = new cdk.App();
new AthenaStack(app, 'AthenaStack', {tags: {stage: 'dev'}, env: {region: 'ap-northeast-1', account}});
5行目のaccount定数に代入されている文字列AWS_IDを、お使いのAWSアカウントのIDと入れ替えてください。
aws-cdk/package.jsonの8行目も同様に対応してください。
そして本番。aws-cdk/lib/AthenaStack/index.tsを開いてください。
こちらが今回Glueにクローラを生成しているコードになります。
import * as cdk from '@aws-cdk/core';
import * as glue from '@aws-cdk/aws-glue';
import * as s3 from '@aws-cdk/aws-s3';
import * as iam from '@aws-cdk/aws-iam';
export class AthenaStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const bucket = s3.Bucket.fromBucketArn(this, 'AthenaTestBucket', 'arn:aws:s3:::{作成したS3バケット}');
const role = new iam.Role(this, 'AthenaTutorialrole', {
assumedBy: new iam.ServicePrincipal('glue.amazonaws.com')
});
role.addManagedPolicy(iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSGlueServiceRole'))
bucket.grantRead(role);
bucket.grantPut(role);
new glue.Database(this, 'athena_tutorial', {
databaseName: 'athena_tutorial_db'
});
new glue.CfnCrawler(this, 'athenatutorialcrawler', {
targets: {
s3Targets: [{path: 's3://{作成したS3バケット}/test-input'}]
},
role: role.roleArn,
databaseName: 'athena_tutorial_db',
name: 'athena_tutorial',
});
}
}
こちらのコードにも手を加えます。お気づきかと思いますが、10行目と25行目に{作成したS3バケット}という文字列があるので、こちらも先ほど作成したバケット名に変更してください。
さて、その上でコードの内容を説明していきます。
S3バケットとロールを定義して、ロールに必要な権限を付与していっている部分は説明がなくてもお分かりかと思います。
このコードでデータベースやクローラを宣言しているのは19-30行目の間です。
ここではathena_tutorial_dbというデータベースを作成し、athena_tutorialという名前のクローラを生成しています。
npm run build
npm run bootstrap
npm run deploy
上記のコマンドを打ち込むと、CDKデプロイが完了するはずです。途中でデプロイ内容を確認してきますが、yで問題ありません。
さて、あとはクローラを実行してテーブルを生成し、Athenaでクエリしてみましょう。先ほどと同様の結果が返ってくれば成功です。
aws-sdkでクローラを実行してみる
ルートディレクトリに戻ってください。クローラを実行するためのファイルはglue.ts、それを使ってテーブルを作るためのスクリプトはcrawler-tester/index.tsにそれぞれ格納されています。
import * as aws from 'aws-sdk';
const glue = new aws.Glue({
region: 'ap-northeast-1'
});
const crawlerConfig = { Name: 'athena_tutorial' }
export async function startCrawler(): Promise<void> {
await glue.startCrawler(crawlerConfig).promise();
}
export async function waitForCrawler(): Promise<string> {
let state = (await glue.getCrawler(crawlerConfig).promise()).Crawler?.State;
// if (!state) throw new Error('no crawler');
let i = 0;
while (state != 'STOPPING') {
i++
console.log('running:', i);
await sleep(1000);
state = (await glue.getCrawler(crawlerConfig).promise()).Crawler?.State;
}
i = 0;
while (state == 'STOPPING') {
i++
console.log('stopping:', i);
await sleep(1000);
state = (await glue.getCrawler(crawlerConfig).promise()).Crawler?.State;
}
if (!state) throw new Error('no crawler');
return state;
}
function sleep (msec: number) {
return new Promise(resolve => setTimeout(resolve, msec));
}
import * as glue from '../glue';
(async() => {
await glue.startCrawler();
console.log(await glue.waitForCrawler());
})();
クローラの実行も2分程度かかる作業なので、クローラをスタートする機能と終わるまで待つ機能は分かれています。この点でAthenaと似ていますね。違うところは結果を受け取る必要がないことと、時間がかかる処理なのでステータス確認の感覚を1秒程度空ける必要がある点です。特に後者は重要で、0.1秒間隔とかだとスロットリングを引き起こします。
ではターミナルで実行してみましょう。
ts-node crawler-tester
いかがでしたか?処理に2分程度かかっていることが実感できたのではないでしょうか。
さて、それでは新しく作ったテーブルに対してクエリをかけてみましょう。
・まずはquery-tester/index.tsの5行目をコメントアウトして、6行目のコメントを外しましょう。
・そしてコマンド実行!
ts-node query-tester
どうでしたか?先ほどと同様のクエリ結果が返却されていれば成功です。
総評
今回はクエリを実行するための基本的な手順を紹介しました。aws-cdkをうまく使えば、クローラなどを用いて効率的にAthenaの設定を行うことができるでしょう。
CDKの文法などご指摘などあればぜひコメントください!
ではでは。