自然言語処理 webスクレイピングによるトレーニングデータの集め方
今更ながらbotを作りたいなと思ったのですが、機械学習によりモデルを作るためのトレーニングデータを集めるところに苦労したため、トレーニングデータを集めるところだけにフォーカスを当ててて自分が実行した手段を公開したいと思います。
今回自分がとったデータの集め方は、「http://ssmania.info/category/ 」 のサイトにアップされているキャラクターのやり取りをもとにトレーニングデータを抽出するやり方です。
全体の流れとしては、
1.リンクを集める
「http://ssmania.info/category/ 」 のサイトに掲載されているURLのリンクを一つのページにまとめる
2.リンクからやり取りを集める
まとめたURLからページのやり取りを「input.txt」「output.txt」二つのファイルに保存する。
3.やり取りを単語ごとに分ける
MeCabを使用して「input.txt」「output.txt」の二つの文章データを単語ごとに分ける。
前提条件
OS:Windows10
言語:Python 3.6.4
目次
1.リンクを集める
2.リンクからやり取りを集める
3.やり取りを単語ごとに分ける
4.結果
1.リンクを集める
「http://ssmania.info/category/ 」 のサイトの収集したいやり取りのアニメを選択する。
例1)以下のようにデータを取得したいアニメを選択する。
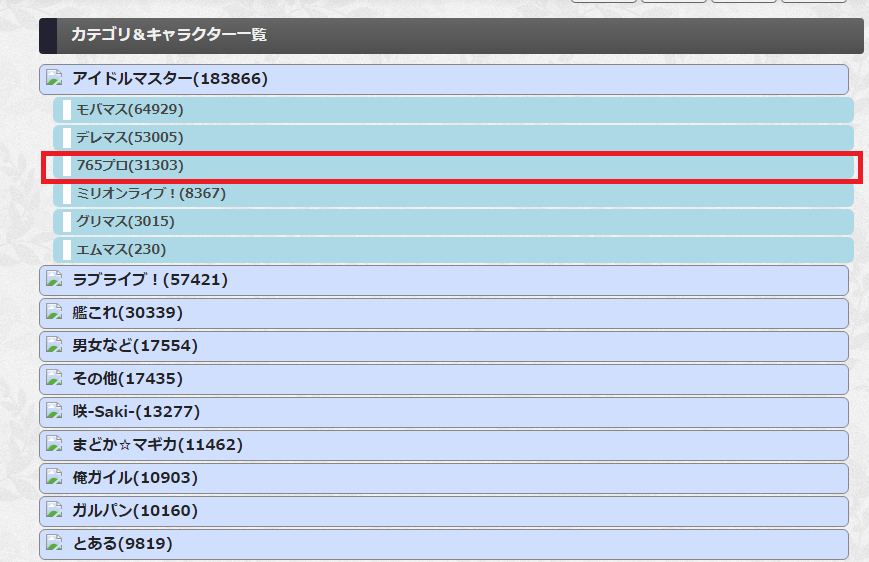
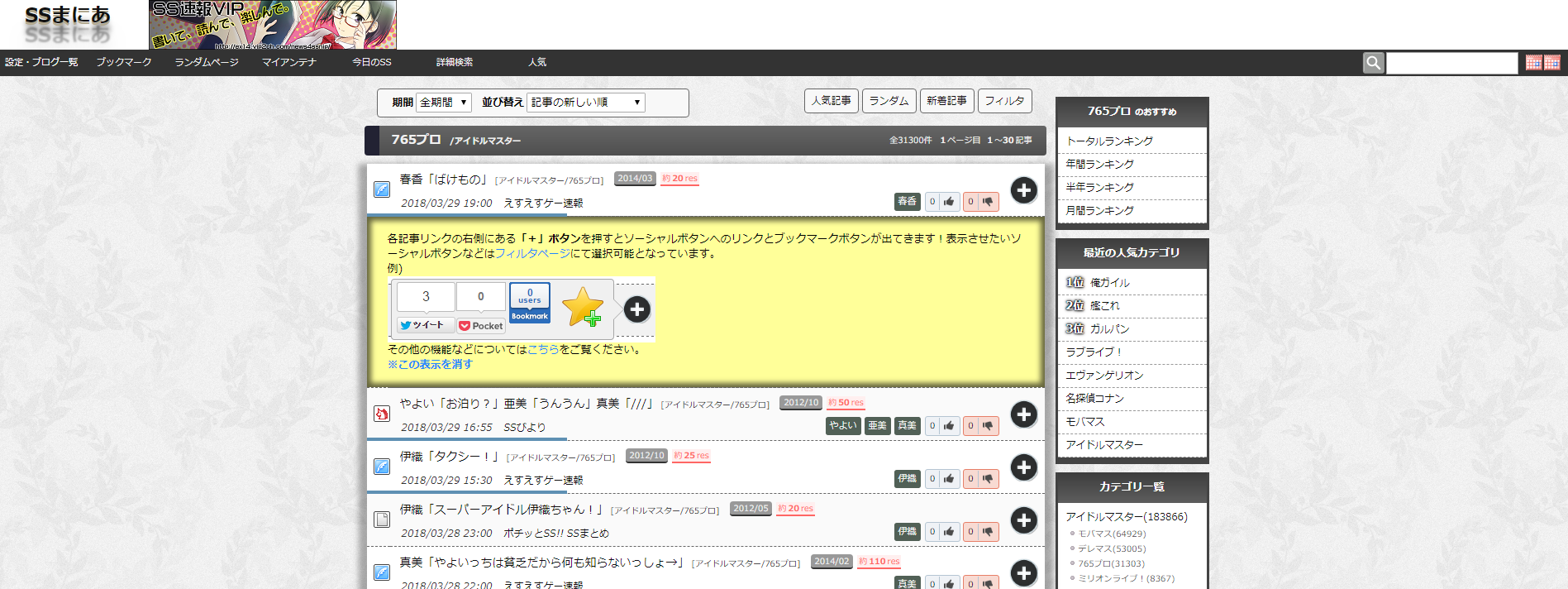
例2)以下のページに移動したら、URLをコピーしてプログラムCollectLinks.pyの11行目の[self.base_url='※※※'] の※※※のところにペーストする。
#!/Users/igaki/.pyenv/shims/python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import types
class CharaScraping(object):
def __init__(self):
self.exclusion_url = "http://ssmania.info/"
self.base_url ="http://ssmania.info/category/765%E3%83%97%E3%83%AD"
def _boardLinkSearch(self):
self.board_list_url = self.base_url+"?page={}"
page = 1
while True:
link = list()
print(page)
board_top_html = requests.get(self.board_list_url.format(page))
board_top_soup = BeautifulSoup(board_top_html.content, "html.parser")
main_contents = board_top_soup.find(id="contents")
if "該当記事はありませんでした" == board_top_soup.find(class_="alink").text:
print("finish")
break
for a in main_contents.find_all('a'):
tmp_link = a.get('href')
if self.exclusion_url not in tmp_link:
link.append(a.get('href'))
link_list = "\n".join(link)
link_list = "\n"+link_list
with open("./charaLink.txt", "a") as f:
f.write(link_list)
page += 1
def main():
scrpeing = CharaScraping()
scrpeing._boardLinkSearch()
if __name__ == "__main__":
main()
print("search Finish")
2.リンクからやり取りを集める
1で収集したリンクが保存されているファイルからキャラクター同士のやり取りを収集する。
#!/Users/igaki/.pyenv/shims/python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import types
class WordScraping(object):
def __init__(self):
self.urlList ={"blog.livedoor.jp":self._livedoor,"ssbiyori.blog.fc2.com":self._ssbiyori,"yomicom.jp":self._yomicom,"potittoss.blog.jp":self._potittoss,"ss-m.net":self._ss_m,"s2-log.com":self._s2_log,"ss-navi.com":self._ss_navi,"horahorazoon.blog134.fc2.com":self._horahorazoon,"ayame2nd.blog.jp":self._ayame2nd,"ssimas72.blog.jp":self._ssimas72,"elephant.2chblog.jp":self._elephant,"morikinoko.com":self._morikinoko,"amnesiataizen.blog.fc2.com":self._amnesiataizen,"ssblog614.blog.fc2.com":self._ssblog614,"sssokuhou.com":self._sssokuhou,"invariant0.blog130.fc2.com":self._invariant0,"darusoku.xyz":self._darusoku,"ss-station.2chblog.jp":self._ss_station,"minnanohimatubushi.2chblog.jp":self._minnanohimatubushi,"ssmansion.xyz":self._ssmansion,"142ch.blog90.fc2.com":self._142ch,"tangaron3.sakura.ne.jp":self._tangaron3,"ssmaster.blog.jp":self._ssmaster,"dousoku.net":self._dousoku,"ssflash.net":self._ssflash,"lclc.blog.jp":self._lclc,"www.lovelive-ss.com":self._www,"maoyuss.blog.fc2.com":self._maoyuss,"ssspecial578.blog135.fc2.com":self._ssspecial578}
def _fileRead(self):
with open("./charaLink.txt", "r") as f:
num = 1
for link in f.readlines():
self.urlList[link.split("/")[2]](link)
num += 1
def _takeCharaWord(self,word):
char_num = len(word)
flag = 0
with open("./input.txt", "a") as inputfile:
with open("./output.txt", "a") as outputfile:
for num in range(char_num):
if word[num] == "「":
num += 1
if flag == 0:
while num < char_num and word[num] != "」":
inputfile.write(word[num])
num += 1
inputfile.write("\n")
flag = 1
else:
while num < char_num and word[num] != "」":
outputfile.write(word[num])
num += 1
outputfile.write("\n")
flag = 0
elif word[num] == "『":
num += 1
if flag%2 == 0:
while num < char_num and word[num] != "』":
inputfile.write(word[num])
num += 1
inputfile.write("\n")
flag = 1
else:
while num < char_num and word[num] != "』":
outputfile.write(word[num])
num += 1
outputfile.write("\n")
flag = 0
def _livedoor(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="article-body-inner").text)
except:
pass
def _ssbiyori(self,url):
pass
def _yomicom(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(_class="sh_heading_main_b") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="ently_text").text)
except:
pass
def _potittoss(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="article-body-inner").text)
except:
pass
def _ss_m(self,url):
pass
def _s2_log(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="article-body-inner").text)
except:
pass
def _ss_navi(self,url):
pass
def _horahorazoon(self,url):
pass
def _ayame2nd(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="article-body-inner").text)
except:
pass
def _ssimas72(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="article-body-inner").text)
except:
pass
def _elephant(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
self._takeCharaWord(livedoor_html_soup.find(class_="article").text)
def _morikinoko(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="article-body-inner").text)
except:
pass
def _amnesiataizen(self,url):
pass
def _ssblog614(self,url):
pass
def _sssokuhou(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="article-body-inner").text)
except:
pass
def _invariant0(self,url):
pass
def _darusoku(self,url):
pass
def _ss_station(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="article-body-inner").text)
except:
pass
def _minnanohimatubushi(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="article-body-inner").text)
except:
pass
def _ssmansion(self,url):
pass
def _142ch(self,url):
pass
def _tangaron3(self,url):
pass
def _ssmaster(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="article-body-inner").text)
except:
pass
def _dousoku(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="article-body-inner").text)
except:
pass
def _ssflash(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="article-body-inner").text)
except:
pass
def _lclc(self,url):
livedoor_html = requests.get(url)
livedoor_html_soup = BeautifulSoup(livedoor_html.content, "html.parser")
if livedoor_html_soup.find(id="character") == None:
try:
self._takeCharaWord(livedoor_html_soup.find(class_="article-body-inner").text)
except:
pass
def _www(self,url):
pass
def _maoyuss(self,url):
pass
def _ssspecial578(self,url):
pass
def _boardLinkSearch(self):
self.board_list_url = "http://ssmania.info/category/765%E3%83%97%E3%83%AD?page={}"
page = 1
while True:
link = list()
print(page)
board_top_html = requests.get(self.board_list_url.format(page))
board_top_soup = BeautifulSoup(board_top_html.content, "html.parser")
main_contents = board_top_soup.find(id="contents")
if "該当記事はありませんでした" == board_top_soup.find(class_="alink").text:
print("finish")
break
for a in main_contents.find_all('a'):
tmp_link = a.get('href')
if self.exclusion_url not in tmp_link:
link.append(a.get('href'))
link_list = "\n".join(link)
link_list = "\n"+link_list
with open("./charaLink.txt", "a") as f:
f.write(link_list)
page += 1
def temp():
link_list = list()
with open("./charaLink.txt", "r") as f:
for link in f:
link_list.append(link)
link_type = list()
for link in link_list:
if link.split("/")[2] not in link_type:
link_type.append(link.split("/")[2])
print(len(link_type))
for link in link_type:
print(link)
def main():
scrpeing = WordScraping()
scrpeing._fileRead()
if __name__ == "__main__":
main()
print("search Finish")
3.やり取りを単語ごとに分ける
seq2seqにより学習するためには文章を単語ごとに分ける必要があります。そのため今回はMeCabというオープンソースである形態素解析器を使用しました。
取得したデータが格納されている「input.txt」と「output.txt」からデータを抽出して「input_result.txt」「output_result.txt」にそれぞれ出力しました。
# -*- coding: utf-8 -*-
import MeCab
import sys
mode = MeCab.Tagger("-Ochasen")
num = 0
with open("./input.txt","r",encoding="utf-8_sig") as f:
for line in f.readlines():
num += 1
line_result = mode.parse(line).split("\n")
with open("./input_result.txt","a",encoding="utf-8") as result_file:
for word in line_result:
if word.split("\t")[0] != "EOS":
result_file.write(word.split("\t")[0])
result_file.write(" ")
result_file.write("\n")
num = 0
with open("./output.txt","r",encoding="utf-8_sig") as f:
for line in f.readlines():
num += 1
line_result = mode.parse(line).split("\n")
with open("./output_result.txt","a",encoding="utf-8") as result_file:
for word in line_result:
if word.split("\t")[0] != "EOS":
result_file.write(word.split("\t")[0])
result_file.write(" ")
result_file.write("\n")
4.結果
結果以下のような内容のデータが収集できました。
...
うーん 、 ブラック の 缶 珈琲 って なんとなく 味気 ない 気 が し て
で さぁ 春香
今日 な んで 事務所 来 た の ?
いや 、 今日 春香 オフ じゃん
… それ 、 先週 別 の 日 に なっ たって 言っ た と 思う ん だ けど …
...