はじめに
この記事はUnreal Engine 4 (UE4) Advent Calendar 2019の8日目の記事です。そしてUE4アドカレ「勉強してみましたシリーズ」の第1回(全2回)です。
2016年のUE4アドカレにてUE4でGOAP的なシステムを作ってみる その1という記事を書きましたが、その1とナンバリングしておきながら結局続きが書かれることなく3年も経ってしまいました。前回の記事を待っていた方には大変申し訳なく思います。
今回はそのような不甲斐ない結果に終わってしまったGOAP記事への再挑戦ということで記事を書きました。また、この記事を書いたことにより過去の記事は非推奨となります。
GOAPについて
GOAPとは?
Goal
Oriented
Action
Planning
から単語の頭文字を取ってGOAPです。(発音は石鹸のSoapと同じ)日本ではゴール指向アクションプランニングと呼ばれています。MITメディアラボが発表したC4アーキテクチャとスタンフォード大学が発表したSTRIPSがベースとなり、Jeff Orkin氏が発表した論文によって広まりました。GOAPが搭載されたゲームとしては**F.E.A.R.**が最も有名です。
C4アーキテクチャについてはゲームの中の人工知能も参考になります
この技術はルールベースやステートベース、ビヘイビアベースと並ぶ意思決定アルゴリズムの1つであるゴールベースに該当します。ゴールベースでのAIは**何らかのゴール(目標)**が与えられ、ゴールへ到達するためのアクションをグラフ探索アルゴリズムによって導き出し実行します。(F.E.A.Rにおけるゴール指向プランニング)
STRIPS
1971年にスタンフォード大学によって発表された「 STanford Research Institute Problem Solver 」の略語であり、戦略や行動順序に関する分野である自動計画に含まれる技術です。
STRIPSは**目標(Goal)と行動(Action)**を人間にとってわかりやすく定義するための記述方式(もしくは言語)でありSTRIPSによって定義された目標と行動をソルバ(もしくはプランナ)によって連鎖するようにつなぎ合わせ問題を解決します。(GOAP(ゴール指向プランニング) - hasht's noteやWhat is STRIPS in artificial intelligence? [closed] - Stack Overflowを参考)
STRIPSの原著:STRIPS: A New Approach to the Application of Theorem Proving to Problem Solving
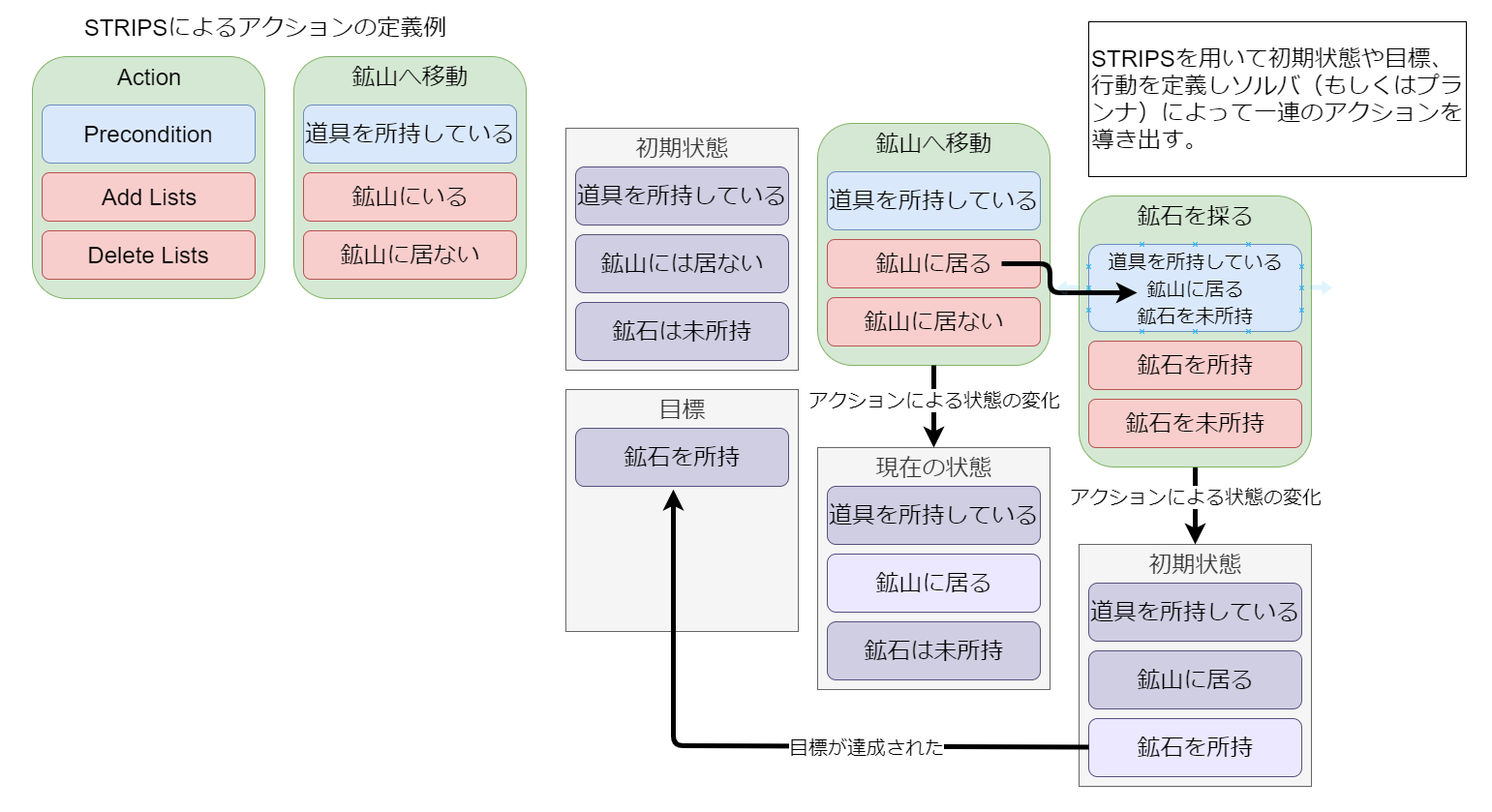
STRIPSによる行動の定義例とプランニングの流れ
プロジェクト配布中
いつものようにOneDriveにてプロジェクトを配布しています。Unreal C++を使用しているのでVisual Studioの導入が必要だと思われます。
UE4バージョン:4.23.1
Visual Studio Community 2019 - Version 16.1.3
https://1drv.ms/u/s!Au-8FqgREBKZiGqe9if_QDb0RN28?e=DEKqLL
もしプロジェクトを眺めている時に「こんな風に書いたほうがいいんじゃないか」「こういう設計にしたほうがいいんじゃないか」みたいなのがあればひっそり教えてくれると助かります。
まずは動かしてみる
配布しているプロジェクトを開く際にプロジェクトのリビルドが求められますのでリビルドしてください。リビルドが無事に終了しプロジェクトが開くとレベル中央にグレイマンがおり、グレイマンを囲うように「Mine」「Tool Storage」「Storage」と書かれたパネルが床に設置されている非常にシンプルなレベルが表示されます。

そのまま実行するとグレイマンが動き始めOutput Logに多くのログが追加されていく様子が見れます。

サンプルではグレイマンがStorageに鉱石を4つ以上運んだ状態を目標としています。グレイマンの初期状態はStorageに居る状態です。サンプルを実行するとOutput Logに次のようなログが表示されます。
LogTemp: Warning: ------ Action Path ------
LogTemp: Warning: MoveToToolStorage
LogTemp: Warning: ->
LogTemp: Warning: PickupTool
LogTemp: Warning: ->
LogTemp: Warning: MoveToMine
LogTemp: Warning: ->
LogTemp: Warning: PickupOre
LogTemp: Warning: ->
LogTemp: Warning: MoveToStorage
LogTemp: Warning: ->
LogTemp: Warning: DropOre
LogTemp: Warning: -------------------------
これは初期状態から目標の状態へと変化するために必要な一連のアクションです。下のDropOreアクションから見ていきます。
DropOreアクションはStorageに鉱石を運ぶアクションです。目標である「Storageに鉱石を4つ以上運んだ状態」には、このアクションを実行する必要があります。
しかし、DropOreアクションを実行するためには前提条件としてOre(鉱石)を所持している かつ Storageに居る必要があります。まずはStorageに居る状態を満たすためにMoveToStorageアクションを実行します。続いてOre(鉱石)を所持している状態を満たすためにPickupOreアクションを実行します。
更にPickupOreアクションを実行するためには前提条件としてMine(鉱山)に居る必要があります。その状態であるためにはMoveToMineアクションを実行します。
さらにさらにMoveToMineアクションを実行するには前提条件として採掘道具を所持している必要があります。その状態であるためにはPickupToolアクションを実行します。
さらにさらにさらにPickupToolアクションを実行するためには採掘道具置き場に居る必要があります。その状態であるためにはMoveToToolStorageアクションを実行します。
アクションの前提条件と効果を連鎖させ一連のアクションを得るというSTRIPSの動作が非常にわかりやすく出ています。
LogTemp: Warning: -------------------------
LogTemp: Warning: ----- Check Precondition -----
LogTemp: Warning: ----- Passed -----
LogTemp: Warning: MoveToToolStorage
LogTemp: Warning: -------------------------
アクションを実行する前にプランニング時とは別に再度、前提条件を満たしているかチェックします。これはリアルタイムな環境において「プランニング時には実行可能だったアクションを実行する際には環境が大きく変化してしまい実行出来なくなってしまった」という場合に再プランニングを行うためのチェックです。(「敵を倒そうと思ったら味方が先に倒してしまった」という場合に再プランニングを行う)
ログではMoveToToolStorageアクションはPassedとなっていますので「MoveToToolStorageは実行可能である」を意味しています。
LogTemp: Warning: ----- Check Precondition -----
LogTemp: Warning: ----- Passed -----
LogTemp: Warning: PickupTool
LogTemp: Warning: ----- Check Precondition -----
LogTemp: Warning: ----- Failed -----
LogTemp: Warning: PickupOre
LogTemp: Warning: ------ Action Path ------
LogTemp: Warning: MoveToMine
LogTemp: Warning: ->
LogTemp: Warning: PickupOre
LogTemp: Warning: ->
LogTemp: Warning: MoveToStorage
LogTemp: Warning: ->
LogTemp: Warning: DropOre
LogTemp: Warning: -------------------------
ここでは再プランニングが行われている様子が見られます。PickupToolの前提条件は満たしているので通常通り実行されましたが次のPickupOreでは失敗しています。これはPikcupOreの前提条件には鉱石を未所持以外にもMineに居る状態である必要があるからです。
前提条件のチェックが失敗し、再プランニングを行ったためPickupOreの前提条件の1つであるMineに居る状態を満たすためにMoveToMineアクションが追加されました。
プログラムの解説
サンプルを動かしOutput Logにどのような内容が表示されるのか、どのようなことが起きているのかを解説しました。以降ではGOAPシステムがどのように実装されているかを解説していきます。
ここでの実装は@yhase7さんのゲームAIの勉強に有用なオープンソースソフトウェアにて紹介されているlua_plannerを参考にしました。
ここで載せているプログラムは実際のプロジェクトからデバッグに関する箇所やアクセサ等を省略したものとなっています。
GOAPWorldState.h/cpp
**世界の状態(以下World Stateと呼ぶ)**とは文字通り世界の状態のことです。例えば鉱石を所持しているWorld Stateを表す場合は <HasOre, True> 等と表現します。GOAPやSTRIPSではWorld Stateを通じてAIが居る世界がどのような状態か状況かを把握し、アクションごとにWorld Stateで定義された前提条件とエフェクトを連鎖的につなぎ合わせてプランニングします。
今回のプロジェクトでは**<状態名, 真理値>**という表現を採用していますが、ここはプロジェクトごとに変わることもあります。(F.E.A.R.では真理値以外にも列挙型やオブジェクトのポインタを格納出来るようになっています)
GOAPWorldState.hにて定義されている構造体FWorldStateはTMap(UE4での連想配列)を操作するためのインターフェースを備えます。TMapは状態名を表す列挙型のEWSKeyNameとboolで定義されています。
USTRUCT(BlueprintType)
struct FWorldState
{
GENERATED_USTRUCT_BODY()
protected:
UPROPERTY(EditDefaultsOnly, BlueprintReadWrite, Category = "GOAP")
TMap<EWSKeyName, bool> StateMap;
public:
FWorldState()
: StateMap({})
{}
explicit FWorldState(const TMap<EWSKeyName, bool>& NewState)
: StateMap(NewState)
{}
bool Update(const FWorldState& NewState);
bool IsInState(const FWorldState& Other) const;
bool operator==(const FWorldState& Rhs) const;
const FWorldState operator-(const FWorldState& Rhs) const;
const FWorldState operator+(const FWorldState& Rhs) const;
// ... アクセサは省略 ...
};
同ファイルにて定義されている列挙型のEWSKeyNameですがC++側で直接定義するのは避けたかったのが正直なところです。現状ではプロジェクトごとにEWSKeyNameを変更しビルドする必要があります。
理想はエディタ側で定義したENUMをGOAPComponentに渡してWorld StateをそのENUMで定義することだったのですが、自分の頭ではどうも難しかった。
これを読んでいる方で「こんな方法を使えば..もしや...」と思いついた方がいれば教えていただければ幸いです。
GOAPAction.h/cpp
UGOAPActionはAIが実際に行うアクションを通じてWorld Stateに変化を与える役割を担い、アクションを実行する際のコストやアクションを実行するための前提条件、アクションを実行した後に変化を与える状態である効果を持ち、ブループリント側でアクションを実装するための公開関数やC++側から実行するためのインターフェースを備えます。
UCLASS(Blueprintable)
class GOAP_EXAMPLE_API UGOAPAction : public UObject
{
GENERATED_BODY()
protected:
UPROPERTY(EditDefaultsOnly, Category = "GOAP", meta = (ClampMin = 1))
int Cost;
UPROPERTY(EditDefaultsOnly, Category = "GOAP")
FString Name;
UPROPERTY(EditDefaultsOnly, Category = "GOAP")
FWorldState Precondition;
UPROPERTY(EditDefaultsOnly, Category = "GOAP")
FWorldState Effect;
EActionResult ActionResult;
protected:
UFUNCTION(BlueprintImplementableEvent, Category = "GOAP")
void ReceiveExecuteAction(AAIController* OwnerController, APawn* ControlledPawn);
UFUNCTION(BlueprintCallable, Category = "GOAP")
void FinishExecute(bool bSuccess);
UFUNCTION(BlueprintCallable, Category = "GOAP")
void FinishAbort();
public:
UGOAPAction(const FObjectInitializer& ObjectInitializer);
void ExecuteAction(AAIController* OwnerController, APawn* ControlledPawn);
bool CheckPrecondition(const FWorldState& Other);
// ... 以下省略 ...
};
UGOAPActionにはSTRPSからGOAPへ発展する際に加えられた大きな変更点が2つあります。1つはコスト、もう一つは手続き的な前提条件です。
GOAPではプランニングにA*(エースターと読む)アルゴリズムを採用していますが(F.E.A.R.も同様です)これはコストの概念を追加したことによりアクションをA*アルゴリズムにおけるエッジと捉えることが出来るようになったためです(ちなみにノードはWorld Stateが相当します)。コストは優先度とも捉えることが可能(低いほうが優先度が高い)なのでゴールを達成するための経路が複数あった時にいくらか制御することが出来ます。例えば敵を倒す方法に銃で撃つアクションと殴るアクションがあった場合、殴るアクションのコストを高くすれば銃で撃つアクションが優先されます。しかし銃に弾が無く、弾を手に入れるために補給場所へ移動しなければならない場合はいっそ殴りに行った方がコストが低い場合があります。
※ナビメッシュとGOAPで使われるA*アルゴリズムの対比
| A* | Navigation | GOAP |
|---|---|---|
| Nodes | NavMesh Polys | World States |
| Edges | NavMesh Poly Edges | Actions |
| Goal | NavMesh Poly | World State |
ゲームでのAアルゴリズムは経路探索が非常に有名な使用例ですが、実際には一般的な探索アルゴリズムなのでノードやエッジに相当するオブジェクトとヒューリスティックとなる要素が用意できればAアルゴリズムを適用することが出来ます。
もう1つの変更点、手続き的な前提条件(Procedural Precondition)はCheckPrecondition関数が該当します。リアルタイム環境のゲームである場合、プランニング時にはクリアしていた前提条件が実際にアクションを実行する際には何らかの理由により前提条件を満たせなくなってしまうことがあります。そのままアクションを実行してしまえば何らかの不具合が起きる可能性があるので、これを防ぐためにプランニング時の前提条件のチェックとは別にランタイムで動作する前提条件チェック機能が追加されました。
GOAPActionPlanner.h/cpp
最初に構造体FGOAPNodeから見ていきます。
構造体FGOAPNodeはプランニングに必要なデータをまとめた構造体です。構造体のメンバーにはgCostやhCost、fCostといったA*アルゴリズムではお馴染みの変数があり、グラフ探索時にいくつかのヒントをもたらすFWorldState型のStateやDiffを持ちます。
USTRUCT()
struct FGOAPNode
{
GENERATED_USTRUCT_BODY()
private:
FWorldState State; // アクション実行後の状態を記録(ゴール状態を満たす時、ここは探索開始時の状態と同一になる)
FWorldState Diff; // 探索開始時の状態とStateとの差分
uint16 GCost; // 「目標ノード」から「現在探索中のノード」までの距離(実行コストの累計とも言える)
uint16 HCost; // 「現在探索中のノード」から「探索開始時の状態」までの距離(ヒューリスティックコスト)
uint16 FCost; // gCostとヒューリスティックコストの合計
TSharedPtr<FGOAPNode> Next; // 次に実行されるアクションを持つノードへのポインタ
UGOAPAction* Action; // 実行するアクション
public:
FGOAPNode()
: State()
, Diff()
, GCost(0)
, HCost(0)
, FCost(0)
, Next(nullptr)
, Action(nullptr)
{}
FGOAPNode(const FWorldState& NewState,
const FWorldState& NewDiff,
uint16 NewGCost,
uint16 NewFCost,
TSharedPtr<FGOAPNode> NewNext,
UGOAPAction* NewAction)
: State(NewState)
, Diff(NewDiff)
, GCost(NewGCost)
, HCost(NewDiff.GetStateSize())
, FCost(NewFCost)
, Next(NewNext)
, Action(NewAction)
{}
const FWorldState& GetState()const { return State; }
const FWorldState& GetDiff()const { return Diff; }
uint16 GetGCost()const { return GCost; }
uint16 GetHCost()const { return HCost; }
uint16 GetFCost()const { return FCost; }
const TSharedPtr<FGOAPNode> GetNext()const { return Next; }
UGOAPAction* GetAction()const { return Action; }
bool IsMeetGoal() const { return HCost == 0; }
};
続いてGOAPの核とも言えるUGOAPActionPlannerです。
GetActionPath関数のみを外部へ公開します。GetActionPath関数にAIが行える全アクション(ドメインと呼ばれる)、現在のWorld Stateと目標とするWorld Stateを渡すことで一連のアクションを取得することが出来ます。
privateで宣言されている各関数はAアルゴリズムではいくらか馴染みのあるものだと思います。GetNeighborActions関数はドメインから引数TargetStateを一部分でも満たすアクションをNeighbors配列へ格納していきます。このGetNeighborActions関数で得られたご近所アクションは未探索の場合、探索予定リストに格納され既に探索済みで良い経路が得られないと分かっているものは無視されます。
ヒューリスティック関数では探索開始状態との差の要素数をヒューリスティック値として返します。後に詳しく説明しますがAアルゴリズムでWhileループを抜け出した時、取り出されたノードのStateは探索開始時の状態と同一となります。
UCLASS()
class GOAP_EXAMPLE_API UGOAPActionPlanner : public UObject
{
GENERATED_BODY()
public:
bool GetActionPath(const TArray<UGOAPAction*>& Domain,
const FWorldState& StartState,
const FWorldState& GoalState,
TArray<UGOAPAction*>& OutActions);
private:
void GetNeighborActions(const TArray<UGOAPAction*>& Domain,
const FWorldState& TargetState,
TArray<UGOAPAction*>& Neighbors);
int FindIndex(const TArray<TSharedPtr<FGOAPNode>>& List,
const TSharedPtr<FGOAPNode> Target) const;
TSharedPtr<FGOAPNode> SearchActionPath(const TArray<UGOAPAction*>& Domain,
const FWorldState& StartState,
const FWorldState& GoalState);
FORCEINLINE int CalcHeuristicCost(const FWorldState& Other) const { return Other.GetStateSize(); }
};
A*アルゴリズムを実装しているSearchActionPath関数を見ていきます。
OpenListやCloseListもA*ではお馴染みのものです。OpenListには探索予定のノードが格納されノードのfCostを基準に昇順に整列されます。これによりOpenListの先頭要素には常に最も目標状態に近いノードが存在することになります。CloseListは探索済みのノードが格納されます。
// 「探索予定のノード」が格納される
TArray<TSharedPtr<FGOAPNode>> OpenList = {};
// 「探索済みのノード」が格納される
TArray<TSharedPtr<FGOAPNode>> CloseList = {};
探索を開始するためにスタートノードを作成します。実装を見てみるとスタートノードは現在のWorld Stateから作成されずに目標状態から作成されます。これは**後ろ向き連鎖**(後ろ向き推論、ゴール駆動型とも)と呼ばれる推論方法に基づいて実装されているためです。(プレイヤーに反応するだけのAIはもう古い!ゲームAIへのプランニング技術の導入にて解説されています)
FWorldState Diff = GoalState - StartState;
const TSharedPtr<FGOAPNode> StartNode(new FGOAPNode(GoalState, Diff, 0, Diff.GetStateSize(), nullptr, nullptr));
後ろ向き連鎖の逆は前向き連鎖と言います。
スタートノードが作成されるとWhileループに入ります。whileループはOpenList未だ要素が格納されている間、つまり探索予定のノードが存在する間ループし続けます。いくつかの処理の後、GetNeighborActions関数によって最短経路を取る可能性のあるアクションを取得しNeighborごとに新しくノードを作成して探索予定リストに格納するか、コストを更新するか判断します。
取得したNeighborsに対する処理が終了するとOpenListの要素をFCost(総コスト)に基づいてソートを行います。ソートによってOpenListの先頭要素には最もコストの少ない親アクションノードが存在することになります。
while (OpenList.Num() != 0)
{
if (OpenList[0]->IsMeetGoal())
return OpenList[0];
CurrentNode = OpenList[0];
OpenList.RemoveAt(0);
// 探索済みとする
CloseList.Emplace(CurrentNode);
// CurrentNodeの状態を満たす可能性のあるアクション群を取得
TArray<UGOAPAction*> Neighbors;
GetNeighborActions(Domain, CurrentNode->GetState(), Neighbors);
FWorldState DiffState, NewState;
for (const auto& Neighbor : Neighbors)
{
// CurrentNodeの状態とNeighborのエフェクトの差分とNeighborの前提条件を結合する.
NewState = (CurrentNode->GetState() - Neighbor->GetEffect()) + Neighbor->GetPrecondition();
// StartStateとの差分を求める(後に求めるヒューリスティック値の手がかりとなる)
DiffState = NewState - StartState;
// 新たな探索候補となるノードを作成
int gCost = CurrentNode->GetGCost() + Neighbor->GetCost();
int fCost = gCost + CalcHeuristicCost(DiffState);
TSharedPtr<FGOAPNode> NewNode(new FGOAPNode(NewState, DiffState, gCost, fCost, CurrentNode, Neighbor));
// NewNodeはすでにOpenList内にあるかチェック
int indexOpen = FindIndex(OpenList, NewNode);
if (indexOpen > 0)
{
if (OpenList[indexOpen - 1]->GetFCost() > NewNode->GetFCost())
OpenList[indexOpen - 1] = NewNode;
}
// OpenListにはなかった
else
{
// CloseListから探してみる
int indexClose = FindIndex(CloseList, NewNode);
if (indexClose == 0)
// OpenListへ追加(探索予定とする)
OpenList.Emplace(NewNode);
}
}
// fCostを基準とした昇順(小さい順、0,1,2,3みたいな)で並び替える.
OpenList.Sort([](const TSharedPtr<FGOAPNode> A, const TSharedPtr<FGOAPNode> B) -> bool
{
return A->GetFCost() < B->GetFCost();
});
}
コードを見るだけではノードの状態がどのように変化しているのかDiff Stateの関連はどうなっているのかが分かりづらいと思いますので、Whileループでのコードの動きを簡易的な図で表してみました。
Node Stateの要素で背景が明るいものがありますが、これは前ノードからの変更があった要素です。Diff Stateの横にある数字はDiff Stateの要素数と対応しています。同じくDiff Stateで文字が薄くなっている要素がありますが、これはノードが作成されたときに前回のノードから削除された要素です。

GetActionPath関数ではSearchActionPath関数によって発見された一連のアクションの先頭ノードからNextをたどりつつActionを取り出します。
// ゴール状態へ到達可能なアクションノードを取得
TSharedPtr<FGOAPNode> Result = SearchActionPath(Domain, StartState, GoalState);
if (Result == nullptr)
{
UE_LOG(LogTemp, Error, TEXT("Not found action path"));
return false;
}
// アクション経路を取り出す
while (Result->GetAction() != nullptr)
{
OutActions.Emplace(Result->GetAction());
Result = Result->GetNext();
}
GOAPComponent.h/cpp
GOAPComponentはActorComponentとして作成されておりGOAPシステムとブループリントとの接点となる場所です。そのためブループリントに公開&実装するためのプロパティ指定子が多く宣言されています。AIのWorldStateは実行中に追加されたり削除されたりすることが無いのでAIが取りうる状態は全てブループリント編集時に設定する必要があります。対しGoalStateは実行中に変更が可能でAIが取りうる全ての状態を設定する必要はありません。採掘道具を所持していないときはGoalStateとすれば採掘道具を取るための一連のアクションを導き出し、全てのアクションの実行が終了した時、GoalStateとして鉱石を採りに向かわせることも出来ます。
NewestWorldは最新のWorld Stateのことであり、アクション実行直後のWorld Stateが格納されます。
// ... 省略 ...
UPROPERTY(EditDefaultsOnly, BlueprintReadOnly, Category = "GOAP")
FWorldState WorldState;
UPROPERTY(EditDefaultsOnly, BlueprintReadWrite, Category = "GOAP")
FWorldState GoalState;
UPROPERTY(BlueprintReadWrite, Transient, Category = "GOAP")
FWorldState NewestWorldState;
// ... 省略 ...
Tickごとに呼ばれるTickComponentを見ていきます。TickComponentでは目標状態へ到達したかチェック、プランニングの実行、アクションの前提条件チェック、アクションの実行と実行結果に応じた処理の分岐が行われます。以下はアクションの実行部分のコードです。(デバッグ部分は省略)
まだ実行中のアクションがある場合、CheckPrecondition関数によって現在の状態はアクションの前提条件をクリアしているかチェックします。これは手続き的な前提条件に該当します。前提条件チェックがクリア出来なかった場合は再プランニングを次のTickで行います。実行の呼び出しが終わると結果を確認しInProgress以外であればアクションは完了(もしくは中断)したとみなしCurrentActionの消去と最新のWorld Stateを入手し次のTickで再び新しいアクションを手に入れます。InProgressの場合は次のTickでも同一アクションを実行します。(この辺はBehavior Tree Taskの実装を参考にしました)
このようなアクションの実行結果を取得するようになっているのは実際にはアクションというものは一瞬で終わることが無いためです。MoveTo等の移動が伴うアクションでは目的地へ到達するまで実際にいくらか時間がかかります。しかしその時間を無視して次のアクションを実行してしまうと鉱山へ到達していないのにツルハシを振るといった奇妙な動きをしてしまいます。
if (CurrentAction)
{
// WorldStateがCurrentActionの前提条件をクリアしているかチェック
if (CurrentAction->CheckPrecondition(WorldState))
{
// アクションの実行
CurrentAction->ExecuteAction(AIOwnerController, AIOwnerPawn);
EActionResult Result = CurrentAction->GetActionResult();
if (Result != EActionResult::InProgress)
{
if (Result == EActionResult::Aborted)
bReplanning = true;
CurrentAction = nullptr;
// 自身の状態を更新
OnUpdateNewestWorldState.Broadcast();
WorldState.Update(NewestWorldState);
}
// 実行結果が「InProgress」の場合、CurrentActionを次のTickでも実行する
}
else
{
// 前提条件がクリア出来ない場合、次のフレームにてリプランニングを行う
CurrentAction = nullptr;
bReplanning = true;
}
}
BuildActionPathでは必要に応じてプランニングを行います。プランニングの必要がないときはActionPathから新しいアクションを取り出します。
プランニングが必要な時は前提条件がクリア出来なかった時と**ActionPathが空(アクションを全て実行し終えた)**時です。
if (bForcePlanning)
{
ActionPlanner->GetActionPath(AvaliableActions, WorldState, GoalState, ActionPath);
if (ActionPath.Num() <= 0)
{
CurrentAction = nullptr;
return false;
}
CurrentAction = ActionPath[0];
ActionPath.RemoveAt(0);
}
else
{
if (CurrentAction == nullptr)
{
if (ActionPath.Num() <= 0)
{
ActionPlanner->GetActionPath(AvaliableActions, WorldState, GoalState, ActionPath);
if (ActionPath.Num() <= 0)
{
CurrentAction = nullptr;
return false;
}
}
CurrentAction = ActionPath[0];
ActionPath.RemoveAt(0);
}
}
BP_GOAP_Character
以上でC++側の実装の紹介は終了です。ここからはブループリント側の実装紹介となります。最初はUGOAPComponentを備えるBP_GOAP_Characterから見ていきます。
UGOAPComponentでの必須設定項目はTickInterval、Avaliable Action Classess、WorldState、GoalStateの4つ。必ず実装しなければならないOn Update Newest World Stateイベントがあります。コンポーネントでのWorldStateは初期のWorld Stateを表し、GoalStateは今まで説明と同様に目標の状態を表します。Avaliable Action Classessには、このAIが実行できるアクションのクラス全てが設定されます。

続いてアクション実行直後のWorld Stateを取得するためのイベントであるOn Update Newest World Stateです。少し不格好な実装ですがUGOAPComponentからNewestWorldStateを引き出して直接データを設定するようにしています。本当はconst無し引数のBlueprintNativeEventで公開したかったのですがActorComponentでは出来ないようなので諦めました。

BP_Action_XXX
UGOAPActionクラスから派生したブループリントです。文字通りAIが世界で実行する行動が定義されます。Behavior TreeでいうところのTaskに該当するものです。
アクションの中で最もシンプルな実装であるBP_Action_DropOreを取り上げます。UGOAPActionから派生したブループリントには必ずCost、Precondition、Effectを設定する必要があります。(Nameは設定しなくても影響はありません。ログ出力時にどのようなアクションを実行しているかをわかりやすくするために付けたものです)
BP_Action_DropOreの前提条件として、である必要があります。つまり「鉱石を所持」しており「鉱石置き場に居る」必要があるわけです。アクションの効果として、がWorld Stateへ与えられます。つまり「鉱石は未所持」となり「鉱石を集め終えた」となります。
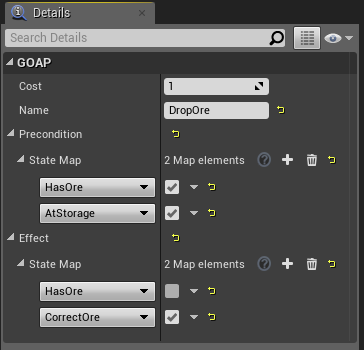
少し混乱するかもしれませんがEffectのとはプランニング時に参照されるパラメータであり実際にWorld Stateに変化を与えるものではありません。BP_GOAP_Characterで実装したOn Update Newest World Stateを見ればわかりますが「Num Drop Oreが4以上」のときに初めてとなります。ですので、このアクションが一度呼ばれただけでは実際のWorld Stateはにならないので再プランニングを行い、再び鉱山へ向かい鉱石を採り、鉱石置き場へ向かい、鉱石を置くといった行動します。
BP_Action_シリーズではアクション実行のためにReceive Execute Actionをオーバーライドする必要があります。そしてアクションの実行が終了したときはFinish Executeを呼び成功や失敗を通知します。(中断するときはFinish Abortを呼びます)
この実装はBehavior Tree Taskと同様なので馴染みのある処理の流れだと思います。

BP_Action_PickupOreはちょっとしたハプニングのようなイベントを実装しています。鉱石を採るには採掘道具を使用するのでアクション実行の度に採掘道具は耐久力が減り、最後には採掘道具が壊れてしまいます。そのような場合はBP_GOAP_Characterのプロパティを変更してFinish Abortを呼び出しアクションを中断させます。アクションが中断されたときGOAPシステムは次のTickで再プランニングを行うのでAIは再び採掘道具置き場に向かい道具を取って鉱石を採りに鉱山へと向かいます。

BP_Action_MoveToMineはいくつかあるMoveTo系アクションの1つです。MoveTo系アクションは実際の移動に多少の時間がかかるため移動が完了/失敗するまではアクションの結果をInProgressとし、他のアクションを実行しないようにしています。Move To Location or Actorノードの前にDo Onceノードを置いていますが、これはMove To Location or Actorを実行する度に一旦現在の歩行がリセットされるために生じるカクカクとした動きを抑制するためにあります。
このプロジェクトでは移動する用のアクションとしてそれぞれ定義していますが例えばPickupOreやPickupTool等のアクションに組み込んでしまっても良いです。その場合はPickupOreやPickupToolの前提条件や効果をいくつか書き換える必要があります。

プロジェクトの弱点
配布しているプロジェクトには2つほど弱点があります。
- タスクに対して引数を与えることは出来ません
- これによりMoveTo系のタスクは目的地の数だけ用意してあげる必要があります。ブループリントも移動先の指定が違うだけのコピーが多く出来上がります。
- タスクを並列して実行することは出来ません
- 例えば「移動しながらリロードする」や「カバー位置へ移動しながら攻撃する」といったことが出来ません。どうにかしてブループリント側で実現する必要があります。
ゴールの設定
GOAP等のプランニングを組み込んだとしてもワールドにポンとAIを置いただけで勝手に動き回るということはなく外部もしくは自身によってゴールを設定することで初めて動く事が出来ます。いくつかゴールの選択に使えそうなシステムを紹介します。これらはプレイヤーに反応するだけのAIはもう古い!ゲームAIへのプランニング技術の導入でも紹介されています。
- ステートマシン
- 各ステートごとにゴールを設定しステートに入るとAIに新しいゴールを設定します。
- ビヘイビアツリー
- ビヘイビアツリーのシステムによってゴールを選択します。ゴールは事前にブラックボードに追加もしくはタスクに設定しておくと良いでしょう。
- ユーティリティシステム
- 「実例で学ぶゲームAIプログラミング」ではユーティリティシステムを通じてゴールを選択しています。ユーティリティは効用に基づく行動選択の方法です。
- 恐らくですがF.E.A.R.もユーティリティに基づくゴール選択を行っているように見えます。(Relevant(関連)値が最も高いゴールを選びプランナーにセットしている様子が見られる)
- ユーティリティについては次を参照:【UE4】Utility Based AI(プロジェクト付)
まとめ
GOAPシステムの優れた点として「AIのアクションの作成に集中出来る」「合理的なアクション経路を導き出す」の2点があります。「AIのアクションの作成に集中出来る」はBehavior Treeでのタスクと同様に他のタスクがどのような動作をするかを心配する必要はありません。「合理的なアクション経路を導き出す」はアルゴリズムによるプランニングによって人間が考える「目標を達成する一連のアクション」よりも合理的な(無駄のない)アクション経路を導き出す可能性があります。
次にGOAPシステムの弱点に完璧に振る舞いをコントロールすることが難しい点が挙げられます。「ボスキャラクター」のような「A攻撃をしたあとB攻撃をして叫んだ後にC攻撃をする」といった決まった手順で行動をさせる場合にはGOAPシステムは不向きです。もちろん前提条件や効果、実行可能なアクションをきちんと望ましいアクション経路を導き出すように設計は出来ます。しかしそのような「決められた手順に沿って行動させる」場合にはBehavior Treeの方がより良い解決法だと思います。
紹介した優れた点や弱点からGOAPシステムは自由な振る舞いが許されるキャラクター(例えば村人や動物、ザコ敵等)を作る際には非常に有用な技術だと思います。
おわりに
UE4アドカレ「勉強してみましたシリーズ」 第1回でした。
前回書ききれなかったGOAP記事のリベンジとして書いてみましたが、結構長くなってしまいました。文中にもありましたが自分の知識不足によって不格好な実装になってしまったところも多々あるため、よろしければ「こんな実装してみたらいいんでない?」といったアドバイスがあればTwitterやコメントにでも書いていただければ幸いです。
明日(12月9日)は@kinnaji_blogさんによる【UE4】EditorのLayoutについてのあれこれ【☆~★】です!
参考資料
-
- UE4で実装されたGOAP
-
- C++コンソールで動作するGOAP。これは別リポジトリにて同氏が開発するUE4のプラグインで呼び出される。the-ai-project - river34
-
- @yhase7 さんが公開しているリポジトリ。ここではGOAPではなくSTRIPSの実装。他にもHTNが実装されている。luaなのでZeroBrane Studioといったlua用のIDEを使ってステップ実行すると理解しやすい。
-
ゲームAIの勉強に有用なオープンソースソフトウェア - yhase7
- @yhase7 さんの記事。
-
プレイヤーに反応するだけのAIはもう古い!ゲームAIへのプランニング技術の導入
- GOAPやHTNといったプランニング技術についてまとめられている資料。GOAPのメリットやデメリット。課題等がまとめられているのでプロジェクトに組み込む前に読んでおくと吉。
-
GOAP(ゴール指向プランニング) - hasht's notes
- GOAPとGOAPのベースとなったSTRIPSについてまとめられた記事。
-
Goal-Oriented Action Planning (GOAP) - Jeff Orkin
- Jeff Orkin氏によるGOAPまとめページ。英語だが実例も多く載っているので、より詳細にGOAPについて知りたい方はおすすめ。
-
Three States and a Plan: The A.I. of F.E.A.R. - Jeff Orkin
- 上のGOAPまとめページで紹介されている資料の1つ。GOAPとSTRIPSの違いや変更点がまとめられている。他にも戦闘時の振る舞いについても触れられているのでF.E.A.R.のAIについて知りたい方はおすすめ。
-
- F.E.A.R.の全ソースが含まれるSDK。実行するにはF.E.A.R.本体が必要かも。AIの実装がどのようになっているかをコードレベルで知りたい方はおすすめ。
-
Goal Oriented Action Planning for a Smarter AI
- Unityでの実装例。
-
- STRIPSについての記事。
-
STRIPS: A New Approach to the Application of Theorem Proving to Problem Solving
- STRIPSの論文原著
-
GameAIPro Chapter04 Behavior Selection Algorithms
- 数あるゲームAIの意思決定アルゴリズムの概要がまとまった資料