はじめに
本記事は言語処理100本ノックの解説です。
100本のノックを全てこなした記録をQiitaに残します。
使用言語はPythonです。
今回は第7章: 単語ベクトル(60~64)までの解答例をご紹介します。
単語の意味を実ベクトルで表現する単語ベクトル(単語埋め込み)に関して,以下の処理を行うプログラムを作成せよ.
60. 単語ベクトルの読み込みと表示
Google Newsデータセット(約1,000億単語)での学習済み単語ベクトル(300万単語・フレーズ,300次元)をダウンロードし,”United States”の単語ベクトルを表示せよ.ただし,”United States”は内部的には”United_States”と表現されていることに注意せよ.
from gensim.models import KeyedVectors
model = KeyedVectors.load_word2vec_format("[PATH]/GoogleNews-vectors-negative300.bin", binary=True)
print(model.get_vector("United_States"))
[-3.61328125e-02 -4.83398438e-02 2.35351562e-01 1.74804688e-01
-1.46484375e-01 -7.42187500e-02 -1.01562500e-01 -7.71484375e-02
1.09375000e-01 -5.71289062e-02 -1.48437500e-01 -6.00585938e-02
1.74804688e-01 -7.71484375e-02 2.58789062e-02 -7.66601562e-02
-3.80859375e-02 1.35742188e-01 3.75976562e-02 -4.19921875e-02
-3.56445312e-02 5.34667969e-02 3.68118286e-04 -1.66992188e-01
-1.17187500e-01 1.41601562e-01 -1.69921875e-01 -6.49414062e-02
~~~~~~~~~~~~~~~~~~~~~~~~~~省略~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
コメント
単語ベクトルはその潜在的な意味をベクトルで表現できるところが面白いです。Pythonにはgensimという単語をベクトルに変換してくれるモジュールがあります。
61. 単語の類似度
“United States”と”U.S.”のコサイン類似度を計算せよ.
model.similarity("United_States", "U.S.")
0.73107743
コメント
コサイン類似度自体は自分で計算式書いても簡単に求められます。本問のように同じ意味の単語でも、1近傍にはならないのですね。
62. 類似度の高い単語10件
“United States”とコサイン類似度が高い10語と,その類似度を出力せよ.
model.most_similar("United_States", topn = 10)
[('Unites_States', 0.7877248525619507),
('Untied_States', 0.7541370987892151),
('United_Sates', 0.7400724291801453),
('U.S.', 0.7310774326324463),
('theUnited_States', 0.6404393911361694),
('America', 0.6178410053253174),
('UnitedStates', 0.6167312264442444),
('Europe', 0.6132988929748535),
('countries', 0.6044804453849792),
('Canada', 0.601906955242157)]
コメント
上位は“United States”と同義語で占められてます。下位には国というカテゴリでアメリカに近いものが出てきましたね。
63. 加法構成性によるアナロジー
“Spain”の単語ベクトルから”Madrid”のベクトルを引き,”Athens”のベクトルを足したベクトルを計算し,そのベクトルと類似度の高い10語とその類似度を出力せよ.
model.most_similar_cosmul(positive=["Spain", "Athens"], negative=["Madrid"], topn=10)
[('Greece', 0.9562304615974426),
('Aristeidis_Grigoriadis', 0.8694582581520081),
('Ioannis_Drymonakos', 0.8600283265113831),
('Ioannis_Christou', 0.8544449806213379),
('Greeks', 0.8521003127098083),
('Hrysopiyi_Devetzi', 0.8383886814117432),
('Panagiotis_Gionis', 0.8323913216590881),
('Heraklio', 0.8297829627990723),
('Lithuania', 0.8291547298431396),
('Periklis_Iakovakis', 0.8289120197296143)]
コメント
「スペイン」から「マドリード」を引いて、「アテネ」を足した単語は?という問題。上位はギリシャとそこのスポーツ選手ですかね。スペインの首都がアテネになったら、実質スペインはギリシャですよということ?
64. アナロジーデータでの実験
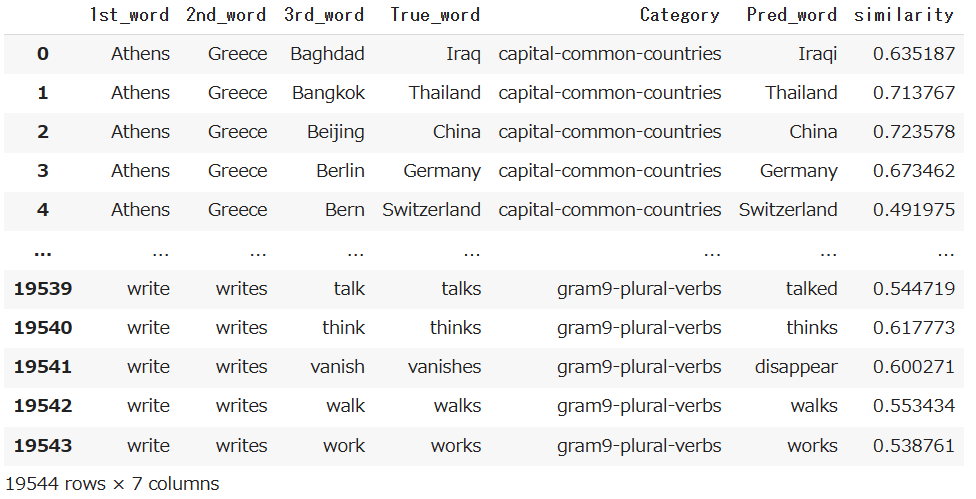
単語アナロジーの評価データをダウンロードし,vec(2列目の単語) - vec(1列目の単語) + vec(3列目の単語)を計算し,そのベクトルと類似度が最も高い単語と,その類似度を求めよ.求めた単語と類似度は,各事例の末尾に追記せよ.
import pandas as pd
with open("[PATH]/questions-words.txt", "r") as f:
lines = f.readlines()
word1 = []
word2 = []
word3 = []
word4 = []
df = pd.DataFrame()
for i, line in enumerate(lines, 1):
if line[0]==":":
if len(word1)!=0:
df_temp = pd.DataFrame({"1st_word":word1, "2nd_word":word2,
"3rd_word":word3, "True_word":word4})
df_temp["Category"] = category.replace("\n", "").replace(":", "")
df = pd.concat([df, df_temp])
word1 = []
word2 = []
word3 = []
word4 = []
category = line
else:
word = line.split(" ")
word1.append(word[0])
word2.append(word[1])
word3.append(word[2])
word4.append(word[3].replace("\n", ""))
if len(lines)==i:
df_temp = pd.DataFrame({"1st_word":word1, "2nd_word":word2,
"3rd_word":word3, "True_word":word4})
df_temp["Category"] = category.replace("\n", "").replace(":", "")
df = pd.concat([df, df_temp])
df = df.reset_index()
def CaculateWordVec(X):
result = model.most_similar(positive=[X["2nd_word"], X["3rd_word"]],
negative=[X["1st_word"]], topn=1)[0]
return result[0], result[1]
df[["Pred_word", "similarity"]] = df.apply(CaculateWordVec, axis=1, result_type="expand")
df = df.drop("index", axis=1)
df.to_csv("[PATH]/Anology_example.csv")
df
出力結果
コメント
実行時間が2~3時間かかりました。単語ベクトルを使えば、単語同士の意味合いで加減算ができるところが面白いです。
後半の解答
他章の解答例