はじめに
本記事は言語処理100本ノックの解説です。
100本のノックを全てこなした記録をQiitaに残します。
使用言語はPythonです。
今回は第8章: ニューラルネット(75~79)までの解答例をご紹介します。
8章前半(70~74)の解答例はこちらです。
75. 損失と正解率のプロット
コード
# Load the TensorBoard notebook extension
%load_ext tensorboard
%tensorboard --logdir logs
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import TensorDataset, DataLoader
import torch
import torch.nn as nn
import torch.optim as optim
def TensorboardWriter(model, X, Y, epoch, loss, name) :
Y_pred = model(X)
CEloss = loss(Y_pred, Y)
result = torch.max(Y_pred.data, dim=1).indices
accuracy = result.eq(Y).sum().numpy()/len(Y_pred)
writer.add_scalar("Loss/{}_Loss".format(name), CEloss, epoch)
writer.add_scalar("Accuracy/{}_Accuracy".format(name), accuracy, epoch)
class NetWork(nn.Module):
def __init__(self, input_feature, output):
super().__init__()
self.fc1 = nn.Linear(input_feature, output, bias=False)
nn.init.xavier_normal_(self.fc1.weight)#重みをXavierの初期化
self.fc2 = nn.Softmax(dim=1)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
X_train = torch.load("[PATH]/X_train.pt")
Y_train = torch.load("[PATH]/Y_train.pt")
X_valid = torch.load("[PATH]/X_valid.pt")
Y_valid = torch.load("[PATH]/Y_valid.pt")
model = NetWork(300, 4)
loss = nn.CrossEntropyLoss(reduction="mean")
ds = TensorDataset(X_train, Y_train)
DL = DataLoader(ds, batch_size=128, shuffle=True)
optimizer = optim.SGD(params=model.parameters(), lr=0.01)
writer = SummaryWriter(log_dir="logs")
epoch = 1000
for ep in range(epoch):
for X, Y in DL:
Y_pred = model(X)
CEloss = loss(Y_pred, Y)
optimizer.zero_grad()
CEloss.backward()
optimizer.step()
TensorboardWriter(model, X_train, Y_train, ep, loss, "Train")
TensorboardWriter(model, X_valid, Y_valid, ep, loss, "Valid")
torch.save(model.state_dict(), "[PATH]/SigleLayer.pth")#モデルの保存
writer.close()
出力結果
訓練データの正解率
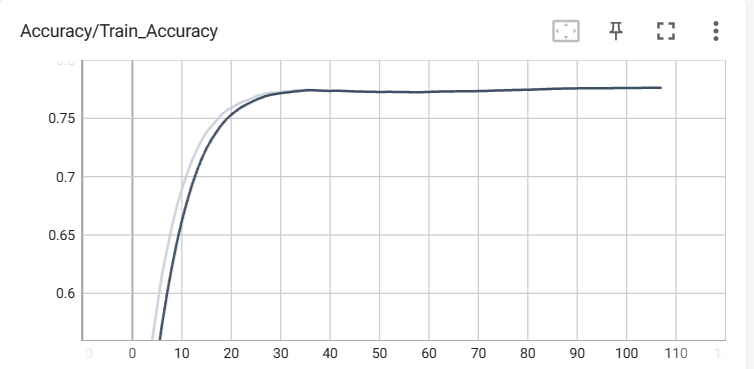
検証データの正解率
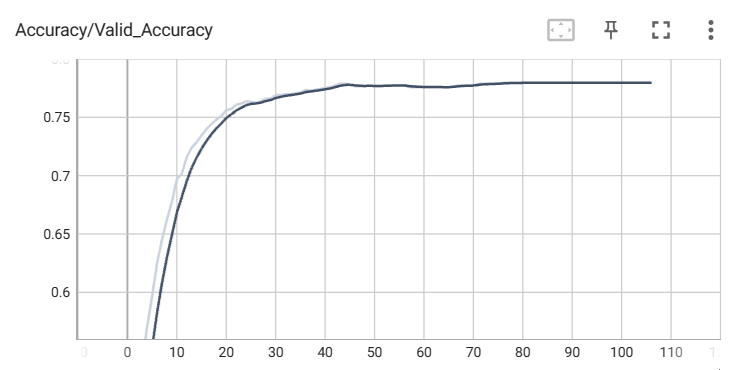
訓練データの損失
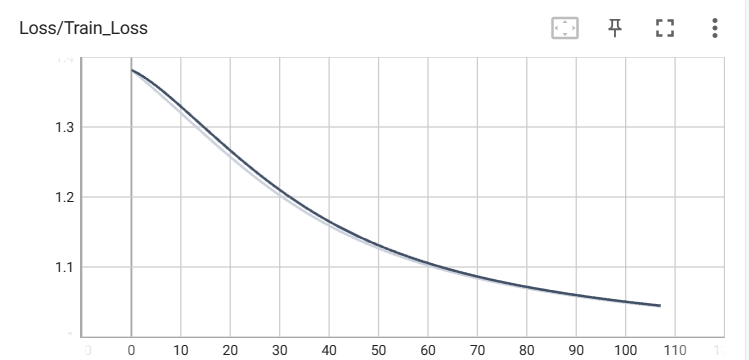
検証データの損失
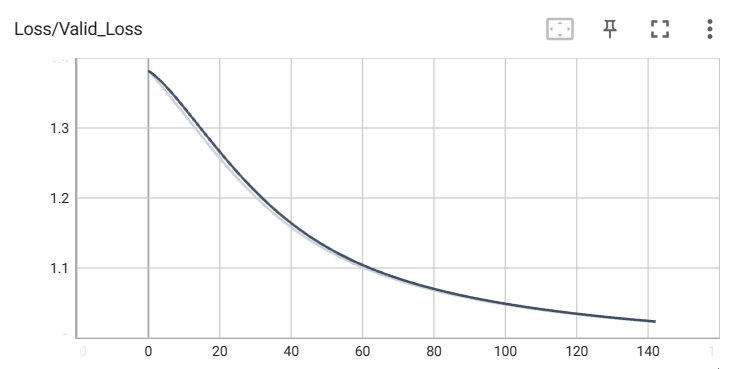
コメント
機械学習初心者あるある、Tensorboard出すのに苦労しがち。
まだ損失下がりそうな気がする。
76. チェックポイント
コード
from torch.utils.data import TensorDataset, DataLoader
import torch
import torch.nn as nn
import torch.optim as optim
class NetWork(nn.Module):
def __init__(self, input_feature, output):
super().__init__()
self.fc1 = nn.Linear(input_feature, output, bias=False)
nn.init.xavier_normal_(self.fc1.weight)#重みをXavierの初期化
self.fc2 = nn.Softmax(dim=1)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
X_train = torch.load("[PATH]/X_train.pt")
Y_train = torch.load("[PATH]/Y_train.pt")
X_valid = torch.load("[PATH]/X_valid.pt")
Y_valid = torch.load("[PATH]/Y_valid.pt")
model = NetWork(300, 4)
loss = nn.CrossEntropyLoss(reduction="mean")
ds = TensorDataset(X_train, Y_train)
DL = DataLoader(ds, batch_size=256, shuffle=True)
optimizer = optim.SGD(params=model.parameters(), lr=0.01)
epoch = 1000
for ep in range(epoch):
for X, Y in DL:
Y_pred = model(X)
CEloss = loss(Y_pred, Y)
optimizer.zero_grad()
CEloss.backward()
optimizer.step()
if ep % 100 == 0:
torch.save(model.state_dict(), "[PATH]/checkpoint{}.pth".format(str(ep).zfill(4)))
コメント
100エポックごとに保存できるようにしました。モデル1個1個の容量が大きいので共有ドライブを使っている人は特にご注意を。私の研究室にはMax4.2TB使った人がいました。
77. ミニバッチ化
コード
from torch.utils.data import TensorDataset, DataLoader
import torch
import torch.nn as nn
import torch.optim as optim
import time
class NetWork(nn.Module):
def __init__(self, input_feature, output):
super().__init__()
self.fc1 = nn.Linear(input_feature, output, bias=False)
nn.init.xavier_normal_(self.fc1.weight)#重みをXavierの初期化
self.fc2 = nn.Softmax(dim=1)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
X_train = torch.load("[PATH]/X_train.pt")
Y_train = torch.load("[PATH]/Y_train.pt")
loss = nn.CrossEntropyLoss(reduction="mean")
ds = TensorDataset(X_train, Y_train)
bs_list = [2**i for i in range(15)]
for bs in bs_list:
DL = DataLoader(ds, batch_size=bs, shuffle=True)
optimizer = optim.SGD(params=model.parameters(), lr=0.01)
model = NetWork(300, 4)
epoch = 10
t1 = time.time()
for ep in range(epoch):
for X, Y in DL:
Y_pred = model(X)
CEloss = loss(Y_pred, Y)
optimizer.zero_grad()
CEloss.backward()
optimizer.step()
t2 = time.time()
lenght = (t2 - t1)/epoch
print("Batch Size:", bs)
print("Time:", lenght)
出力結果
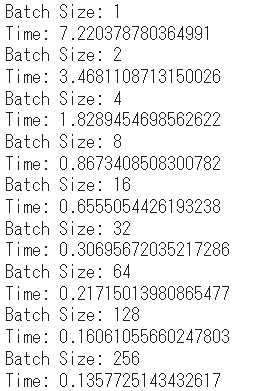
コメント
バッチサイズを大きくすればするほど、早くなりますがメモリを消費します。バッチサイズは2のべき乗が採用されることが多いです。このような慣習があるのって面白いですよね。
78. GPU上での学習
コード
from torch.utils.data import TensorDataset, DataLoader
import torch
import torch.nn as nn
import torch.optim as optim
class NetWork(nn.Module):
def __init__(self, input_feature, output):
super().__init__()
self.fc1 = nn.Linear(input_feature, output, bias=False)
nn.init.xavier_normal_(self.fc1.weight)#重みをXavierの初期化
self.fc2 = nn.Softmax(dim=1)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
X_train = torch.load("[PATH]/X_train.pt")
Y_train = torch.load("[PATH]/Y_train.pt")
X_train = X_train.to("cuda:0")
Y_train = Y_train.to("cuda:0")
loss = nn.CrossEntropyLoss(reduction="mean")
model = NetWork(300, 4).to("cuda:0")
ds = TensorDataset(X_train, Y_train)
DL = DataLoader(ds, batch_size=256, shuffle=True)
optimizer = optim.SGD(params=model.parameters(), lr=0.01)
epoch = 100
for ep in range(epoch):
for X, Y in DL:
Y_pred = model(X)
CEloss = loss(Y_pred, Y)
optimizer.zero_grad()
CEloss.backward()
optimizer.step()
コメント
GPUに値を渡すには.to(cuda:0)などの記述が必要です。この辺も機械学習をやるうえで詰まるところかなと思います。GPUサーバのCPUで学習してましたってことにならないように気をつけてください。
79. 多層ニューラルネットワーク
コード
from torch.utils.data import TensorDataset, DataLoader
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
class NetWork(nn.Module):
def __init__(self, input_feature, output):
super().__init__()
self.fc1 = nn.Linear(input_feature, 300, bias=True)
self.fc2 = nn.Linear(300, output, bias=True)
self.fc3 = nn.Softmax(dim=1)
nn.init.xavier_normal_(self.fc1.weight)
nn.init.xavier_normal_(self.fc2.weight)
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = self.fc3(x)
return x
X_train = torch.load("[PATH]/X_train.pt")
Y_train = torch.load("[PATH]/Y_train.pt")
X_test = torch.load("[PATH]/X_test.pt")
Y_test = torch.load("[PATH]/Y_test.pt")
X_train = X_train.to("cuda:0")
Y_train = Y_train.to("cuda:0")
loss = nn.CrossEntropyLoss(reduction="mean")
model = NetWork(300, 4).to("cuda:0")
ds = TensorDataset(X_train, Y_train)
DL = DataLoader(ds, batch_size=256, shuffle=True)
optimizer = optim.SGD(params=model.parameters(), lr=0.001)
writer = SummaryWriter(log_dir="logs")
epoch = 1000
for ep in range(epoch):
for X, Y in DL:
Y_pred = model(X)
CEloss = loss(Y_pred, Y)
optimizer.zero_grad()
CEloss.backward()
optimizer.step()
X = X.to("cpu")
Y = Y.to("cpu")
model = model.to("cpu")
Y_pred = model(X)
result = torch.max(Y_pred.data, dim=1).indices
accuracy = result.eq(Y).sum().numpy()/len(Y_pred)
print("学習データ:", accuracy)
Y_pred = model(X_test)
result = torch.max(Y_pred.data, dim=1).indices
accuracy = result.eq(Y_test).sum().numpy()/len(Y_pred)
print("評価データ:", accuracy)
出力結果

コメント
これまでのモデルの中間層を1つ追加しました。単純な多層パーセプトロンに層を増やしまくるのは精度向上に寄与するのかは疑問ですね。
他章の解答例