はじめに
本記事は言語処理100本ノックの解説です。
100本のノックを全てこなした記録をQiitaに残します。
使用言語はPythonです。
今回は第5章: 係り受け解析(40~44)までの解答例をご紹介します。
5章から解答例が長くなるので記事を分割します。
日本語Wikipediaの「人工知能」に関する記事からテキスト部分を抜き出したファイルがai.ja.zipに収録されている. この文章をCaboChaやKNP等のツールを利用して係り受け解析を行い,その結果をai.ja.txt.parsedというファイルに保存せよ.このファイルを読み込み,以下の問に対応するプログラムを実装せよ.
準備
CaboChaを環境に入れる
CaboChaを入れるために下記の記事を参考にさせていただきました。
しかし、crfppダウンロードのところが上手くいっていないようなので、ドライブにCRF++-0.58を落として、それを展開する形でやると上手くいきました。
%%bash
# mecabとmecab-python3の依存関係をインストール
apt-get install mecab swig libmecab-dev mecab-ipadic-utf8
# mecab-pythonのインストール
pip install mecab-python3
# crfppダウンロード(cabochaの依存関係)
#curl -sL -o CRF++-0.58.tar.gz "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7QVR6VXJ5dWExSTQ" #コメントアウト
tar -zxf "[PATH]/CRF++-0.58.tar.gz" #新規追加
# crfppインストール
cd CRF++-0.58
./configure && make && make install && ldconfig
cd ..
# cabochaダウンロード
url="https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7SDd1Q1dUQkZQaUU"
curl -sc /tmp/cookie ${url} >/dev/null
code="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
curl -sLb /tmp/cookie ${url}"&confirm=${code}" -o cabocha-0.69.tar.bz2
tar -jxf cabocha-0.69.tar.bz2
# cabochaインストール
cd cabocha-0.69
./configure -with-charset=utf-8 && make && make check && make install && ldconfig
# cabocha-pythonのインストール
pip install python/
cd ..
ai.ja.txt.parsedの作成
上記で入れたCabochaを使って係り受け解析の結果をai.ja.txt.parsedに保存する。
import CaboCha
CBC = CaboCha.Parser()
divtext = []
with open("[PATH]/ai.ja.txt", "r") as f, open("[PATH]/ai.ja.txt.parsed", "w") as f2:
lines = f.readlines()
for text in lines:
if "。" in text:
temp = text.split("。")
temp = [x + "。" for x in temp if x != '']
divtext.extend(temp)
for text in divtext:
tree = CBC.parse(text)
f2.write(tree.toString(CaboCha.FORMAT_LATTICE))
40. 係り受け解析結果の読み込み(形態素)
形態素を表すクラスMorphを実装せよ.このクラスは表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をメンバ変数に持つこととする.さらに,係り受け解析の結果(ai.ja.txt.parsed)を読み込み,各文をMorphオブジェクトのリストとして表現し,冒頭の説明文の形態素列を表示せよ.
class Morph(object):
def __init__(self, pos):
self.surface = pos[0]
self.base = pos[7]
self.pos = pos[1]
self.pos1 = pos[2]
with open("[PATH]/ai.ja.txt.parsed", "r") as f:
lines = f.readlines()
ai_list = []
morph_list = []
for text in lines:
if text[0:3]=="EOS":
if ai_list:
morph_list.append(ai_list)
ai_list = []
continue
if text[0]=="*":
continue
pos = text.split("\t")
temp = pos[1].split(",")
pos.pop()
pos.extend(temp)
ai_list.append(Morph(pos).__dict__)
morph_list
[[{'surface': '人工', 'base': '人工', 'pos': '名詞', 'pos1': '一般'},
{'surface': '知能', 'base': '知能', 'pos': '名詞', 'pos1': '一般'},
{'surface': '(', 'base': '(', 'pos': '記号', 'pos1': '括弧開'},
{'surface': 'じん', 'base': 'じん', 'pos': '名詞', 'pos1': '一般'},
{'surface': 'こうち', 'base': 'こうち', 'pos': '名詞', 'pos1': '一般'},
{'surface': 'のう', 'base': 'のう', 'pos': '助詞', 'pos1': '終助詞'},
~~~~~~~~~~~~~~~~~~~~~~省略~~~~~~~~~~~~~~~~~~~~~~~~~
コメント
これを見ている人はもっとコードを分かりやすく書いてください。
41. 係り受け解析結果の読み込み(文節・係り受け)
40に加えて,文節を表すクラスChunkを実装せよ.このクラスは形態素(Morphオブジェクト)のリスト(morphs),係り先文節インデックス番号(dst),係り元文節インデックス番号のリスト(srcs)をメンバ変数に持つこととする.さらに,入力テキストの係り受け解析結果を読み込み,1文をChunkオブジェクトのリストとして表現し,冒頭の説明文の文節の文字列と係り先を表示せよ.本章の残りの問題では,ここで作ったプログラムを活用せよ.
#41
class Chunk(object):
def __init__(self, bun, num, chunk_list):
self.morphs = bun
self.dst = num
self.srcs = chunk_list
with open("[PATH]/ai.ja.txt.parsed", "r") as f:
lines = f.readlines()
all_sentense = []
sentense = []
Flag = 0
chunk_dic = {} #その文かかり先辞書{先:元}
pnum = -2 #初期値がないと一週目の処理ができないから
bnum = -2 #初期値がないと一週目の処理ができないから
for text in lines:
if text[0]=="*":
chunk_dic.setdefault(pnum, []).append(bnum)#かかり先辞書がなければ空、あれば追加
if bnum not in chunk_dic:#自分がかかり先になっていない場合、辞書が用意されてないので自分がキーの空リストを作る
chunk_dic[bnum] = []
if sentense:#sentense:この該当文全てがあれば、all_sentenseに追加
all_sentense.append(Chunk(sentense, pnum, chunk_dic[bnum]).__dict__)
sentense = []
pnum = int(text.split(" ")[2][:-1])#かかり先
bnum = int(text.split(" ")[1])#かかり元
if Flag == 1: #前行がEOSなら新しい文なのでかかり先辞書をからにする
chunk_dic = {}
Flag = 0
continue
if text[0:3]=='EOS':#EOSで文が変わることのFlagをあげる
Flag = 1
else:#単語を追加する
word = text.split("\t")
sentense.append(word[0])
all_sentense
[{'morphs': ['人工', '知能'], 'dst': 17, 'srcs': []},
{'morphs': ['(', 'じん', 'こうち', 'のう', '、', '、'], 'dst': 17, 'srcs': []},
{'morphs': ['AI'], 'dst': 3, 'srcs': []},
{'morphs': ['〈', 'エーアイ', '〉', ')', 'と', 'は', '、'], 'dst': 17, 'srcs': [2]},
{'morphs': ['「', '『', '計算'], 'dst': 5, 'srcs': []},
{'morphs': ['(', ')', '』', 'という'], 'dst': 9, 'srcs': [4]},
{'morphs': ['概念', 'と'], 'dst': 9, 'srcs': []},
{'morphs': ['『', 'コンピュータ'], 'dst': 8, 'srcs': []},
{'morphs': ['(', ')', '』', 'という'], 'dst': 9, 'srcs': [7]},
{'morphs': ['道具', 'を'], 'dst': 10, 'srcs': [5, 6, 8]},
{'morphs': ['用い', 'て'], 'dst': 12, 'srcs': [9]},
{'morphs': ['『', '知能', '』', 'を'], 'dst': 12, 'srcs': []},
{'morphs': ['研究', 'する'], 'dst': 13, 'srcs': [10, 11]},
{'morphs': ['計算', '機', '科学'], 'dst': 14, 'srcs': [12]},
{'morphs': ['(', ')', 'の'], 'dst': 15, 'srcs': [13]},
{'morphs': ['一', '分野', '」', 'を'], 'dst': 16, 'srcs': [14]},
{'morphs': ['指す'], 'dst': 17, 'srcs': [15]},
{'morphs': ['語', '。'], 'dst': -1, 'srcs': [0, 1, 3, 16]},
~~~~~~~~~~~~~~~~~~~~~~省略~~~~~~~~~~~~~~~~~~~~~~~~~
コメント
係り受けを文章をまたいで行わないようにEOSごとに区切るようにした。とても複雑なプログラムになってしまった。
変数「all_sentense」は問題42で使います。
42. 係り元と係り先の文節の表示
係り元の文節と係り先の文節のテキストをタブ区切り形式ですべて抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
import MeCab
import unidic
mecab= MeCab.Tagger("")
text_dic = {}
i = 0
kakari_prelist = []
kakari_list = []
for line in all_sentense:
text = ""
for sign_check in line["morphs"]:
if mecab.parse(sign_check).split("\t")[1].split(",")[0] in "補助記号":#記号の除去
pass
else:
text += sign_check.split("\t")[0]
#辞書に追加、かかり元を参照する
text_dic[i] = text
i += 1
##出力
if line["srcs"]==[]:
pass
else:
pnum = line["srcs"]
for j in pnum:
kakari_prelist.append(text_dic[int(j)] + '\t' + text)
if line["dst"]==-1:
if kakari_prelist:
kakari_list.append(kakari_prelist)
kakari_prelist = []
text_dic = {}
i = 0
kakari_list
[['AI\tエーアイとは',
'計算\tという',
'コンピュータ\tという',
'という\t道具を',
'概念と\t道具を',
'という\t道具を',
'道具を\t用いて',
'用いて\t研究する',
'知能を\t研究する',
'研究する\t計算機科学',
'計算機科学\tの',
'の\t一分野を',
'一分野を\t指す',
'人工知能\t語',
'じんこうちのう\t語',
'エーアイとは\t語',
'指す\t語'],
~~~~~~~~~省略~~~~~~~~~
コメント
句読点の判定だけにMeCabを使用。句読点だけじゃなく括弧などの記号も除去できる。
変数「kakari_list」は問題43で使用。
43. 名詞を含む文節が動詞を含む文節に係るものを抽出
名詞を含む文節が,動詞を含む文節に係るとき,これらをタブ区切り形式で抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
import MeCab
import itertools
mecab= MeCab.Tagger("")
NV_list = []
Flag1 = 0
Flag2 = 0
kakari_list_flatten = list(itertools.chain.from_iterable(kakari_list))#文章ごとにリストになっているため、1次元配列にする
for line in kakari_list_flatten:
text = line.split('\t')
pretext = mecab.parse(text[0]).split("\t")
backtext = mecab.parse(text[1]).split("\t")
for ptemp in pretext:
pp = ptemp.split(",")[0]
if pp == "名詞":
Flag1 = 1
for btemp in backtext:
bb = btemp.split(",")[0]
if bb == "動詞":
Flag2 = 1
if Flag1 == 1 and Flag2 == 1:
NV_list.append(line)
Flag1 = 0
Flag2 = 0
NV_list
['計算\tという',
'コンピュータ\tという',
'道具を\t用いて',
'知能を\t研究する',
'一分野を\t指す',
'知的行動を\t代わって',
'人間に\t代わって',
'コンピューターに\t行わせる',
~~~~~~~~~省略~~~~~~~~~
コメント
Flagを使って名詞と動詞のペアをリストに入れました。本章の解答例としては綺麗にコードを書けた気がする。
44. 係り受け木の可視化
与えられた文の係り受け木を有向グラフとして可視化せよ.可視化には,Graphviz等を用いるとよい.
準備(1): 処理する変数の修正
文章中に同じ単語が複数回出現する場合、グラフがその単語を1つのノードとして処理してしまいます。そこで文章中の単語が一意になるように番号を単語の先頭に付与します。この処理を反映するために「42. 係り元と係り先の文節の表示」のプログラムを以下のように改変しました。
import MeCab
import unidic
mecab= MeCab.Tagger("")
text_dic = {}
i = 0
kakari_prelist = []
kakari_list = []
for line in all_sentense:
text = ""
for sign_check in line["morphs"]:
if mecab.parse(sign_check).split("\t")[1].split(",")[0] in "補助記号":#記号の除去
pass
else:
text += sign_check.split("\t")[0]
#辞書に追加、かかり元を参照する
text = str(i) + " "+ text #44番かかり受け木作成用に追加
text_dic[i] = text
i += 1
##出力
if line["srcs"]==[]:
pass
else:
pnum = line["srcs"]
for j in pnum:
kakari_prelist.append(text_dic[int(j)] + '\t' + text)
if line["dst"]==-1:
if kakari_prelist:
kakari_list.append(kakari_prelist)#44番用, #45番用
kakari_prelist = []
text_dic = {}
i = 0
kakari_list
[['2 AI\t3 エーアイとは',
'4 計算\t5 という',
'7 コンピュータ\t8 という',
'5 という\t9 道具を',
'6 概念と\t9 道具を',
'8 という\t9 道具を',
'9 道具を\t10 用いて',
'10 用いて\t12 研究する',
'11 知能を\t12 研究する',
'12 研究する\t13 計算機科学',
'13 計算機科学\t14 の',
'14 の\t15 一分野を',
'15 一分野を\t16 指す',
'0 人工知能\t17 語',
'1 じんこうちのう\t17 語',
'3 エーアイとは\t17 語',
'16 指す\t17 語'],
~~~~~~~~~省略~~~~~~~~~
準備(2): grahvizで日本語を表示できるようにする
$ apt install fonts-ipafont-gothic
これを入れないと日本語表記は全て□□□(豆腐)になります。
コード
from graphviz import Digraph
i = 0
for lines in kakari_list:
graph = Digraph(format="png")
graph.attr('edge', fontname = 'IPAGothic')
for line in lines:
text = line.split("\t")
graph.node(text[0])
graph.node(text[1])
graph.edge(text[0], text[1])
graph.render("[PATH]/output{}".format(str(i).zfill(3)))
i += 1
出力結果
元の文章:「第3次人工知能ブームでは、ディープラーニングが画像認識、テキスト解析、音声認識など様々な領域で第2次人工知能ブームの人工知能を上回る精度を出しており、ディープラーニングの研究が盛んに行われている。」
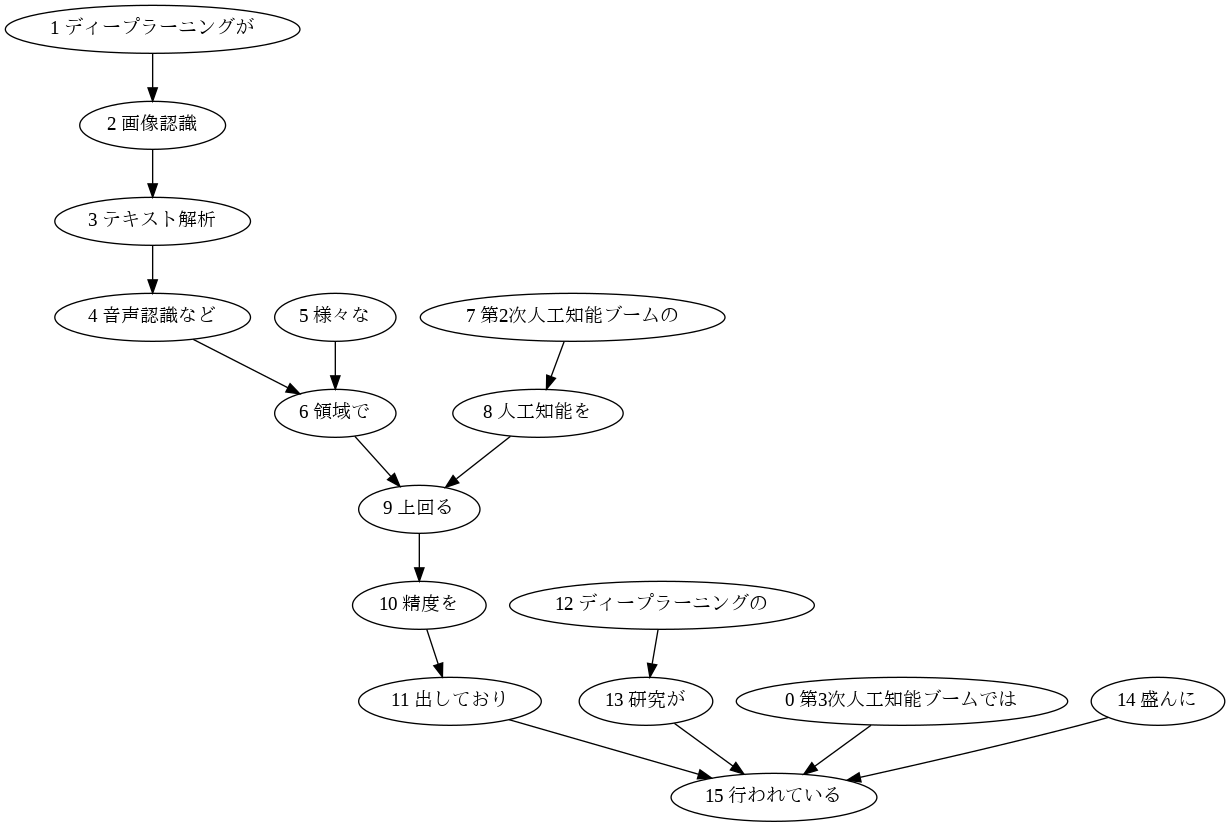
コメント
単語の先頭に数字を振るアイデアはなかなか良いと思っています。このプログラムを動かすと全ての文章に対して有向木が作成されるため注意。
第5章後半(45~49)の解答例
他章の解答例