はじめに
本記事は言語処理100本ノックの解説です。
100本のノックを全てこなした記録をQiitaに残します。
使用言語はPythonです。
今回は第7章: 単語ベクトル(65~69)までの解答例をご紹介します。
7章前半(60~64)の解答例はこちらです。
65. アナロジータスクでの正解率
64の実行結果を用い,意味的アナロジー(semantic analogy)と文法的アナロジー(syntactic analogy)の正解率を測定せよ.
前章の問題64の解答例で作成した「Anology_example.csv」を使います。
import pandas as pd
df = pd.read_csv("[PATH]/Anology_example.csv")
df_se = df[df["Category"].str.contains("gram")]
df_sy = df[~df["Category"].str.contains("gram")]
df_se_true = df_se[df_se["True_word"]==df_se["Pred_word"]]
df_sy_true = df_sy[df_sy["True_word"]==df_sy["Pred_word"]]
print("semantic analogy:", len(df_se_true)/len(df_se))
print("syntactic analogy:", len(df_sy_true)/len(df_sy))
semantic analogy: 0.7400468384074942
syntactic analogy: 0.7308602999210734
コメント
「semantic analogy」→意味的に近いか?、「syntactic analogy」→文法的に近いか?ですかね。単語ベクトルでは意味も文法も表せるんですね。
66. WordSimilarity-353での評価
The WordSimilarity-353 Test Collectionの評価データをダウンロードし,単語ベクトルにより計算される類似度のランキングと,人間の類似度判定のランキングの間のスピアマン相関係数を計算せよ.
from gensim.models import KeyedVectors
from scipy.stats import spearmanr
import pandas as pd
model = KeyedVectors.load_word2vec_format("[PATH]/GoogleNews-vectors-negative300.bin", binary=True)
df = pd.read_csv("[PATH]/combined.csv")
Cossim = lambda X:model.similarity(X["Word 1"], X["Word 2"])
wordvec = df.apply(Cossim, axis=1)
correlation, pvalue = spearmanr(wordvec, df["Human (mean)"])
print("スピアマン相関係数:", correlation)
print("p値:", pvalue)
スピアマン相関係数: 0.7000166486272194
p値: 2.86866666051422e-53
コメント
相関係数見るとほぼ人間と同じ予測ができていることが分かります。プログラミングのテクニックですが、DataFrameの値を関数で処理する時に、applyを使うとFor文で一個ずつ処理するより爆速になります。
67. k-meansクラスタリング
国名に関する単語ベクトルを抽出し,k-meansクラスタリングをクラスタ数k=5として実行せよ.
準備
国名の単語を一覧を取得するのですが、以下の記事を参考にさせていただきました。
この記事で取得した国名一覧は「country_map.csv」で保存しました。
coutry_map.csv
コード
from gensim.models import KeyedVectors
from sklearn.cluster import KMeans
import numpy as np
import pandas as pd
model = KeyedVectors.load_word2vec_format("[PATH]/GoogleNews-vectors-negative300.bin", binary=True)
df = pd.read_csv("[PATH]/country_map.csv")
df["Country"]=df["Country"].replace(["United Arab Emirates", "United Kingdom","United States of America", "Saudi Arabi","Syrian Arab Republic","Czech Republic","Vatican City State","Russian Federation"],
["UAE", "UK","USA", "SAU","SYR", "Czech","Vatican","Russia"])
country_name = df["Country"].tolist()
country_name.append("Japan")
vec_list = []
country_name_fix = []
for name in country_name:
try:
vec = np.array(model.get_vector(name),"float64")
vec_list.append(vec)
country_name_fix.append(name)
except:
pass
pred = KMeans(n_clusters = 5).fit_predict(vec_list)
dic = {}
for cat, name in zip(pred, country_name_fix):
dic.setdefault(cat, []).append(name)
dic
{0: ['Iceland',
'Ireland',
'Azerbaijan',
~~~省略~~~
1: ['Algeria',
'Angola',
'Yemen',
~~~省略~~~
2: ['Afghanistan',
'UAE',
'Israel',
~~~省略~~~
3: ['Aruba',
'Anguilla',
'Guyana',
~~~省略~~~
4: ['Argentina',
'Uruguay',
'Ecuador',
コメント
取得した国名リストの表記がmodelに無いものもあったので、それは略称に変換した。出力結果を見ると、0.ヨーロッパ、1.アフリカ、2.アジア、3.オセアニア、4.南アフリカあたりですかね。country_name.append("Japan")で加えた日本も2.アジアに分類されていました。
68. Ward法によるクラスタリング
国名に関する単語ベクトルに対し,Ward法による階層型クラスタリングを実行せよ.さらに,クラスタリング結果をデンドログラムとして可視化せよ.
from scipy.cluster.hierarchy import dendrogram, linkage
import matplotlib.pyplot as plt
#####ここから67と同じ###########
from gensim.models import KeyedVectors
import numpy as np
import pandas as pd
model = KeyedVectors.load_word2vec_format("[PATH]/GoogleNews-vectors-negative300.bin", binary=True)
df = pd.read_csv("[PATH]/country_map.csv")
df["Country"]=df["Country"].replace(["United Arab Emirates", "United Kingdom","United States of America", "Saudi Arabi","Syrian Arab Republic","Czech Republic","Vatican City State","Russian Federation"],
["UAE", "UK","USA", "SAU","SYR", "Czech","Vatican","Russia"])
country_name = df["Country"].tolist()
country_name.append("Japan")
vec_list = []
country_name_fix = []
for name in country_name:
try:
vec = np.array(model.get_vector(name),"float64")
vec_list.append(vec)
country_name_fix.append(name)
except:
pass
##############################
fig = plt.figure(figsize=(20, 10))
Z = linkage(vec_list, 'ward')
dn = dendrogram(Z, labels = country_name_fix)
plt.show()
fig.savefig("[PATH]/dendrogram.pdf")
出力結果
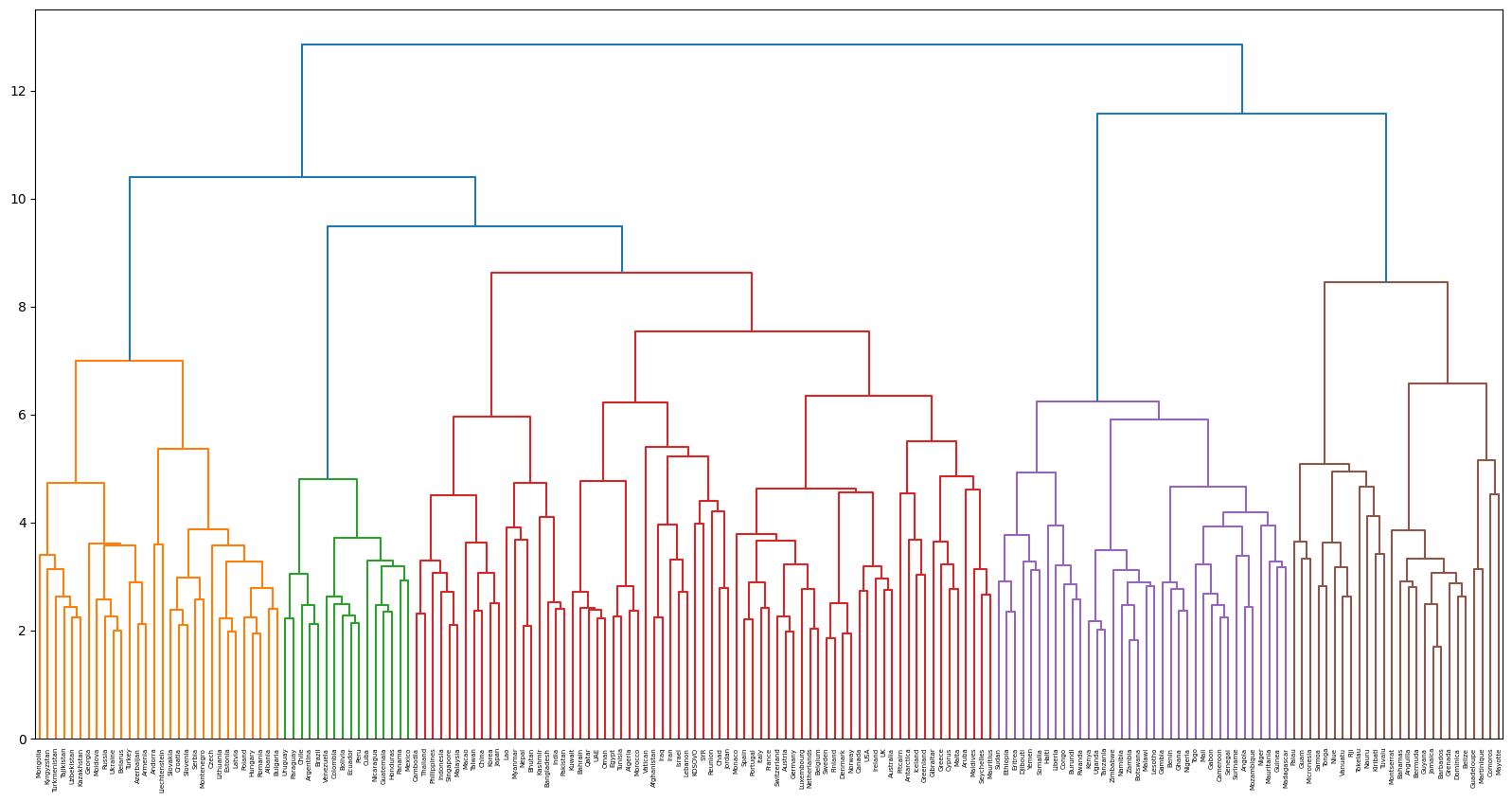
コメント
階層型クラスタリングは何個に集団を分類したいか自分で決められるのがいいですよね。
69. t-SNEによる可視化
ベクトル空間上の国名に関する単語ベクトルをt-SNEで可視化せよ.
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
#####ここから67と同じ###########
from gensim.models import KeyedVectors
import numpy as np
import pandas as pd
#model = KeyedVectors.load_word2vec_format("[PATH]/GoogleNews-vectors-negative300.bin", binary=True)
df = pd.read_csv("[PATH]/country_map.csv")
df["Country"]=df["Country"].replace(["United Arab Emirates", "United Kingdom","United States of America", "Saudi Arabi","Syrian Arab Republic","Czech Republic","Vatican City State","Russian Federation"],
["UAE", "UK","USA", "SAU","SYR", "Czech","Vatican","Russia"])
country_name = df["Country"].tolist()
country_name.append("Japan")
vec_list = []
country_name_fix = []
for name in country_name:
try:
vec = np.array(model.get_vector(name),"float64")
vec_list.append(vec)
country_name_fix.append(name)
except:
pass
##############################
vec_list = np.array(vec_list)
tsne = TSNE(n_components=2)
X_tsne = tsne.fit_transform(vec_list)
pred = KMeans(n_clusters = 5, random_state=42).fit_predict(vec_list)
plt.figure(figsize=(15, 13))
col_list = ["Blue", "Red", "Green", "Black"]
for X, name, km in zip(X_tsne, country_name_fix, pred):
plt.plot(X[0], X[1], color = col_list[km-1], marker="o")
plt.annotate(name, xy=(X[0], X[1]))
plt.title("T-SNE")
plt.savefig("[PATH]/TSNE.png")
plt.show()
出力結果
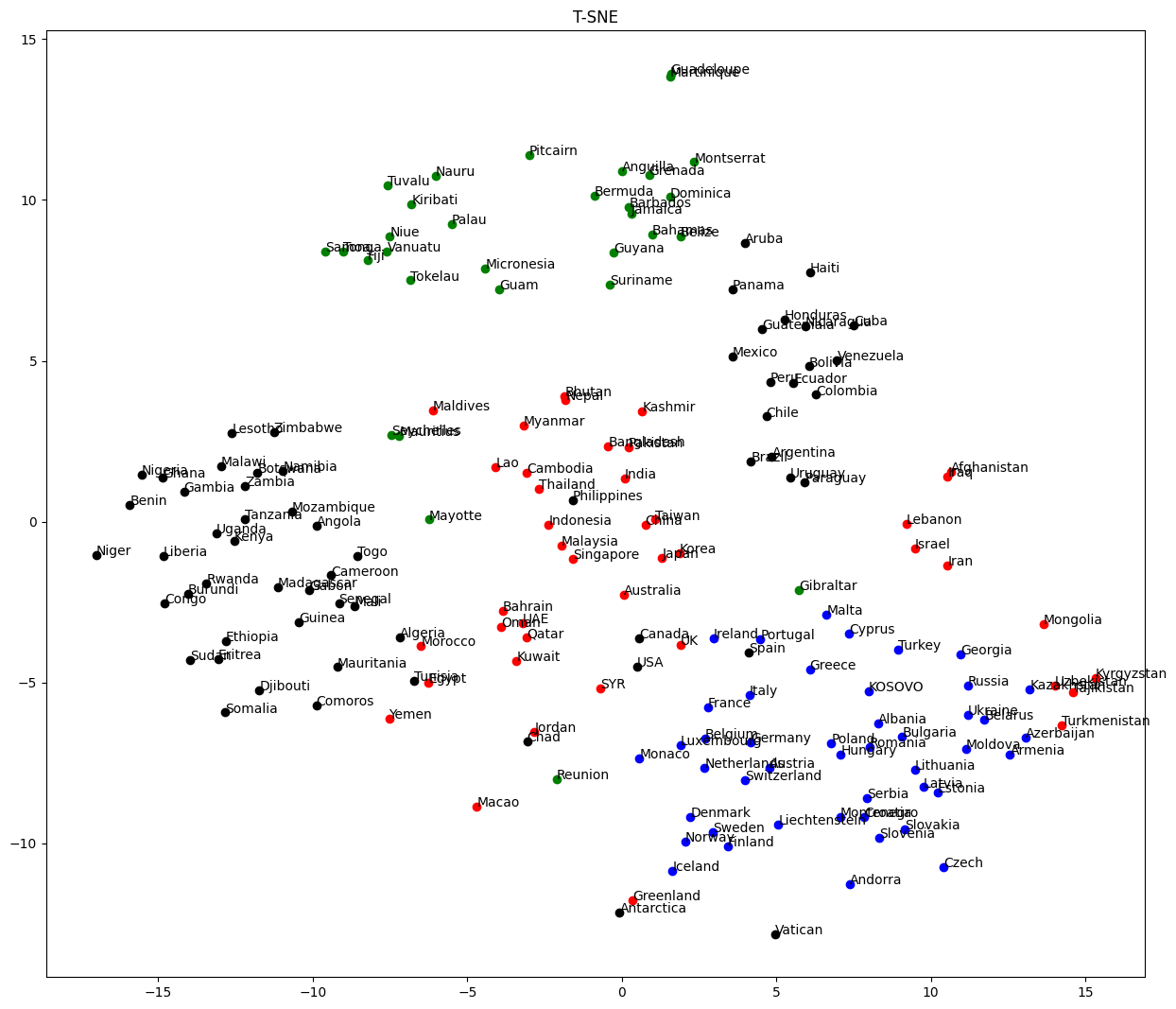
コメント
一応、地域ごとにまとまりました。仲間はずれがあるとどうしてそこにいるのか考察したくなりますね。
他章の解答例