はじめに
本記事は言語処理100本ノックの解説です。
100本のノックを全てこなした記録をQiitaに残します。
使用言語はPythonです。
今回は第9章: RNN, CNN(80~84)までの解答例をご紹介します。
80. ID番号への変換
コード
import re
import collections
def Process(lines):
sign_regrex = re.compile('[!"#$%&\'()*+,-./:;<=>?@[\\]^_`|$#@£â€™é\n]')
word_list = []
text_list = []
true_label = []
for text in lines:
true_label.append(text.split("\t")[0])
text = text.split("\t")[1]
text = sign_regrex.sub("", text)
text = re.sub("(\d+)", r" \1 ", text)
words = text.split(" ")
words = list(filter(lambda x:x, words))#空リスト削除
words = list(map(lambda x:x.lower(), words))#小文字にする
word_list.extend(words)
text_list.append(words)
return word_list, text_list, true_label
def MakeDict(name):
f = open("[PATH]/{}.txt".format(name), "r")
lines = f.readlines()
f.close()
word_list, _, _ = Process(lines)
c = collections.Counter(word_list).most_common()
word_dic = {}
for id, word in enumerate(c, 1):
if int(word[1]) < 2:
word_dic[word[0]] = 0
else:
word_dic[word[0]] = id
return word_dic
def Word2Code(name, word_dic):
f = open("[PATH]/{}.txt".format(name), "r")
lines = f.readlines()
lines.pop(0)#カラムの行を除く
_, text_list, true_label = Process(lines)
true_label = list(map(EncoderNN, true_label))
result_list = []
for text in text_list:
code_list = []
for word in text:
try:
code = word_dic[word]
except:
code = 0
code_list.append(code)
result_list.append(code_list)
f = open("[PATH]/{}_code.txt".format(name), "w")
i = 0
for t1, t2, t3 in zip(true_label, text_list, result_list):
if i==0:
f.write(str(t1)+"\t"+" ".join(t2)+"\t"+" ".join(map(str, t3)))
i = 1
else:
f.write("\n"+str(t1)+"\t"+" ".join(t2)+"\t"+" ".join(map(str, t3)))
f.close()
def EncoderNN(sign):
if sign == "b":
code = 0
elif sign == "t":
code = 1
elif sign == "e":
code = 2
elif sign == "m":
code = 3
return code
word_dic = MakeDict("train")
Word2Code("train", word_dic)
Word2Code("test", word_dic)
Word2Code("valid", word_dic)
出力結果
test_code.txt
2 bowe bergdahls platoonmate testifies before congress that he should face 6823 0 0 4618 106 1557 44 91 410 286
0 update 3 barclays slapped with 44 mln fine over gold price fix 8 23 552 7286 13 0 240 815 24 253 518 1040
1 google smart lenses get boost from alcon owner novartis 92 1247 5844 209 394 20 0 5061 1840
2 a perfect match khloe kardashian and french montana both step out in i heart 11 1160 3646 481 26 10 316 1063 3346 539 46 2 151 367
2 john greens paper towns is headed to the big screen 457 4601 6090 5898 16 3214 1 3 167 3396
~~~~~~~~~~~~~~~~~省略~~~~~~~~~~~~~~~~~~~~~
コメント
文字を数値に置き換えます。ここでの前処理が予測精度に影響してきます。
81. RNNによる予測
コード
import torch.nn as nn
import torch
class RNN(nn.Module):
def __init__(self, vocab_size, dw, dh, output):
super().__init__()
self.embed = nn.Embedding(vocab_size, dw, padding_idx=vocab_size-1)
self.rnn = nn.RNN(dw, dh, batch_first=True)
self.fc1 = nn.Linear(dh, output, bias=True)
self.fc2 = nn.Softmax(dim=1)
nn.init.xavier_normal_(self.rnn.weight_ih_l0)
nn.init.xavier_normal_(self.rnn.weight_hh_l0)
nn.init.xavier_normal_(self.fc1.weight)
def forward(self, x):
x = self.embed(x)
x, _ = self.rnn(x)
x = self.fc1(x[:, -1, :])
x = self.fc2(x)
return x
def CountVocab(name):
f = open("[PATH]/{}_code.txt".format(name), "r")
lines = f.readlines()
f.close()
max_num = []
for line in lines:
line_t = line.split("\t")[2].replace("\n", "").split(" ")
max_num.extend(map(int, line_t))
vocab_max = max(max_num)+1
return vocab_max
def GetCodeLow(name):
f = open("[PATH]/{}_code.txt".format(name), "r")
lines = f.readlines()
f.close()
num_list = []
code_list = []
pad_list = []
for line in lines:
line_s = line.split("\t")
code_list.append(int(line_s[0]))
num = line_s[2].replace("\n", "").split(" ")
num = list(map(int, num))
num_list.append(num)
num_tensor = torch.tensor(num)
pad_list.append(num_tensor)
max_vocab = CountVocab("train")
mlen = max([len(x) for x in num_list])
pad_list = list(map(lambda x:x + [max_vocab]*(mlen-len(x)), num_list))
pad_list = torch.tensor(pad_list)
code_list = torch.tensor(code_list)
return pad_list, code_list
X_valid, Y_valid = GetCodeLow("valid")
VOCAB_SIZE = CountVocab("train")+1
EMB_SIZE = 300
OUTPUT_SIZE = 4
HIDDEN_SIZE = 50
lr = 1e-3
model = RNN(VOCAB_SIZE, EMB_SIZE, HIDDEN_SIZE, OUTPUT_SIZE)
Y_pred = model(X_valid)
pred = torch.argmax(Y_pred, dim=-1)
print("accuracy: ", sum(1 for x,y in zip(Y_valid, pred) if x == y) / float(len(Y_pred)))
出力結果
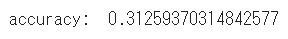
コメント
こんな感じのモデルを作りました。RNNをそのまま使っている人なんてもういないですかね。一昔前の系列データ用のモデルですから。
82. 確率的勾配降下法による学習
コード
from torch.utils.data import TensorDataset, DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn
import torch
class RNN(nn.Module):
def __init__(self, vocab_size, dw, dh, output):
super().__init__()
self.embed = nn.Embedding(vocab_size, dw, padding_idx=vocab_size-1)
self.rnn = nn.RNN(dw, dh, batch_first=True)
self.fc1 = nn.Linear(dh, output, bias=True)
self.fc2 = nn.Softmax(dim=1)
nn.init.xavier_normal_(self.rnn.weight_ih_l0)
nn.init.xavier_normal_(self.rnn.weight_hh_l0)
nn.init.xavier_normal_(self.fc1.weight
def forward(self, x):
x = self.embed(x)
x, _ = self.rnn(x)
x = self.fc1(x[:, -1, :])
x = self.fc2(x)
return x
def calculate_loss_and_accuracy(model, dataset, device=None, criterion=None):
dataloader = DataLoader(dataset, batch_size=1, shuffle=False)
loss = 0.0
total = 0
correct = 0
with torch.no_grad():
for X, Y in dataloader:
Y_pred = model(X)
if criterion != None:
loss += criterion(Y_pred, Y).item()
pred = torch.argmax(Y_pred, dim=-1)
total += len(Y)
correct += (pred == Y).sum().item()
return loss / len(dataset), correct / total
def train_model(X_train, y_train, X_test, y_test, batch_size, model, lr, num_epochs, collate_fn=None, device=None):
dataset_train = TensorDataset(X_train, y_train)
dataset_test = TensorDataset(X_test, y_test)
dataloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True)
dataloader_test = DataLoader(dataset_test, batch_size=batch_size, shuffle=True)
criterion = nn.CrossEntropyLoss()
for ep in range(num_epochs):
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
if ep==10:
lr = lr * 0.1
model.train()
for X, Y in dataloader_train:
optimizer.zero_grad()
Y_pred = model(X)
loss = criterion(Y_pred, Y)
loss.backward()
optimizer.step()
model.eval()
loss_train, acc_train = calculate_loss_and_accuracy(model, dataset_train, device, criterion=criterion)
loss_test, acc_test = calculate_loss_and_accuracy(model, dataset_test, device, criterion=criterion)
print(f'epoch: {ep + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_Test: {loss_test:.4f}, accuracy_Test: {acc_test:.4f}')
TensorboardWriter(model, X_train, Y_train, ep, loss_train, "Train")
TensorboardWriter(model, X_test, Y_test, ep, loss_test, "Test")
def TensorboardWriter(model, X, Y, epoch, loss, name):
writer = SummaryWriter(log_dir="RNN_CNN/logs")
Y_pred = model(X)
result = torch.max(Y_pred.data, dim=1).indices
accuracy = result.eq(Y).sum().numpy()/len(Y_pred)
writer.add_scalar("Loss/{}_Loss".format(name), loss, epoch)
writer.add_scalar("Accuracy/{}_Accuracy".format(name), accuracy, epoch)
writer.close()
def CountVocab(name):
f = open("[PATH]/{}_code.txt".format(name), "r")
lines = f.readlines()
f.close()
max_num = []
for line in lines:
line_t = line.split("\t")[2].replace("\n", "").split(" ")
max_num.extend(map(int, line_t))
vocab_max = max(max_num)+1
return vocab_max
def GetCodeLow(name):
f = open("[PATH]/{}_code.txt".format(name), "r")
lines = f.readlines()
f.close()
num_list = []
code_list = []
pad_list = []
for line in lines:
line_s = line.split("\t")
code_list.append(int(line_s[0]))
num = line_s[2].replace("\n", "").split(" ")
num = list(map(int, num))
num_list.append(num)
num_tensor = torch.tensor(num)
pad_list.append(num_tensor)
max_vocab = CountVocab("train")
mlen = max([len(x) for x in num_list])
pad_list = list(map(lambda x:x + [max_vocab]*(mlen-len(x)), num_list))
pad_list = torch.tensor(pad_list)
code_list = torch.tensor(code_list)
return pad_list, code_list
X_train, Y_train = GetCodeLow("train")
X_test, Y_test = GetCodeLow("test")
BATCH_SIZE = 1
NUM_EPOCHS = 20
VOCAB_SIZE = CountVocab("train")+1
EMB_SIZE = 300
OUTPUT_SIZE = 4
HIDDEN_SIZE = 50
lr = 1e-3
model = RNN(VOCAB_SIZE, EMB_SIZE, HIDDEN_SIZE, OUTPUT_SIZE)
train_model(X_train, Y_train, X_test, Y_test, BATCH_SIZE, model, lr, NUM_EPOCHS)
出力結果

コメント
lossはまだ下がりそうですがいったん10epochでストップ。次の問題でこのモデル+学習データのMAX性能を見ましょう。
83. ミニバッチ化・GPU上での学習
コード
%load_ext tensorboard
%tensorboard --logdir logs
from torch.utils.data import TensorDataset, DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn
import numpy as np
import torch
class RNN(nn.Module):
def __init__(self, vocab_size, dw, dh, output):
super().__init__()
self.embed = nn.Embedding(vocab_size, dw, padding_idx=vocab_size-1)
self.rnn = nn.RNN(dw, dh, batch_first=True)
self.fc1 = nn.Linear(dh, output, bias=True)
self.fc2 = nn.Softmax(dim=1)
nn.init.xavier_normal_(self.rnn.weight_ih_l0)
nn.init.xavier_normal_(self.rnn.weight_hh_l0)
nn.init.xavier_normal_(self.fc1.weight)
def forward(self, x):
x = self.embed(x)
x, _ = self.rnn(x)
x = self.fc1(x[:, -1, :])
x = self.fc2(x)
return x
def calculate_loss_and_accuracy(model, dataset, device, criterion=None):
dataloader = DataLoader(dataset, batch_size=1, shuffle=False)
loss = 0.0
total = 0
correct = 0
model = model.to(device)
with torch.no_grad():
for X, Y in dataloader:
X = X.to(device)
Y = Y.to(device)
Y_pred = model(X)
if criterion != None:
loss += criterion(Y_pred, Y).item()
pred = torch.argmax(Y_pred, dim=-1)
total += len(Y)
correct += (pred == Y).sum().item()
return loss / len(dataset), correct / total
def train_model(X_train, y_train, X_test, y_test, batch_size, model, lr, num_epochs, device, collate_fn=None):
dataset_train = TensorDataset(X_train, y_train)
dataset_test = TensorDataset(X_test, y_test)
model = model.to(device)
dataloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True)
dataloader_test = DataLoader(dataset_test, batch_size=batch_size, shuffle=True)
criterion = nn.CrossEntropyLoss()
criterion = criterion.to(device)
for ep in range(num_epochs):
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
if ep%30==0:
lr = lr * 0.1
model.train()
for X, Y in dataloader_train:
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
Y_pred = model(X)
loss = criterion(Y_pred, Y)
loss.backward()
optimizer.step()
model.eval()
loss_train, acc_train = calculate_loss_and_accuracy(model, dataset_train, device, criterion=criterion)
loss_test, acc_test = calculate_loss_and_accuracy(model, dataset_test, device, criterion=criterion)
print(f'epoch: {ep + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_Test: {loss_test:.4f}, accuracy_Test: {acc_test:.4f}')
TensorboardWriter(model, X_train, Y_train, ep, loss_train, "Train", device)
TensorboardWriter(model, X_test, Y_test, ep, loss_test, "Test", device)
def TensorboardWriter(model, X, Y, epoch, loss, name, device):
writer = SummaryWriter(log_dir="logs")
model = model.to(device)
X = X.to(device)
Y_pred = model(X)
result = torch.max(Y_pred.data, dim=1).indices
result = result.cpu().data.numpy()
Y_pred = np.array([np.argmax(y) for y in Y_pred.cpu().data.numpy()])
Y = np.array([np.argmax(y) for y in Y.cpu().data.numpy()])
result = torch.tensor(result)
Y = torch.tensor(Y)
Y_pred = torch.tensor(Y_pred)
accuracy = result.eq(Y).sum().numpy()/len(Y_pred)
writer.add_scalar("Loss/{}_Loss".format(name), loss, epoch)
writer.add_scalar("Accuracy/{}_Accuracy".format(name), accuracy, epoch)
writer.close()
def CountVocab(name):
f = open("[PATH]/{}_code.txt".format(name), "r")
lines = f.readlines()
f.close()
max_num = []
for line in lines:
line_t = line.split("\t")[2].replace("\n", "").split(" ")
max_num.extend(map(int, line_t))
vocab_max = max(max_num)+1
return vocab_max
def GetCodeLow(name):
f = open("[PATH]/{}_code.txt".format(name), "r")
lines = f.readlines()
f.close()
num_list = []
code_list = []
pad_list = []
for line in lines:
line_s = line.split("\t")
code_list.append(int(line_s[0]))
num = line_s[2].replace("\n", "").split(" ")
num = list(map(int, num))
num_list.append(num)
num_tensor = torch.tensor(num)
pad_list.append(num_tensor)
max_vocab = CountVocab("train")
mlen = max([len(x) for x in num_list])
pad_list = list(map(lambda x:x + [max_vocab]*(mlen-len(x)), num_list))
pad_list = torch.tensor(pad_list)
code_list = torch.tensor(code_list)
return pad_list, code_list
X_train, Y_train = GetCodeLow("train")
X_test, Y_test = GetCodeLow("test")
BATCH_SIZE = 8
NUM_EPOCHS = 100
VOCAB_SIZE = CountVocab("train")+1
EMB_SIZE = 300
OUTPUT_SIZE = 4
HIDDEN_SIZE = 50
lr = 1e-2
device = "cuda:0"
model = RNN(VOCAB_SIZE, EMB_SIZE, HIDDEN_SIZE, OUTPUT_SIZE)
train_model(X_train, Y_train, X_test, Y_test, BATCH_SIZE, model, lr, NUM_EPOCHS, device)
出力結果

コメント
バッチサイズは4で精度は約74%でした。バッチサイズを大きくするほど精度が下がってしまいました。特に少ないデータセットに対しては小さい方がいいかも。
84. 単語ベクトルの導入
コード
from gensim.models import KeyedVectors
from torch.utils.data import TensorDataset, DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn
import numpy as np
import torch
import re
import collections
class RNN(nn.Module):
def __init__(self, vocab_size, dw, dh, output, init_weight=None):
super().__init__()
if init_weight != None:
self.embed = nn.Embedding.from_pretrained(init_weight, freeze=False, padding_idx=vocab_size-1)
else:
self.embed = nn.Embedding(vocab_size, dw, padding_idx=0)
self.rnn = nn.RNN(dw, dh, batch_first=True)
self.fc1 = nn.Linear(dh, output, bias=True)
self.fc2 = nn.Softmax(dim=1)
nn.init.xavier_normal_(self.rnn.weight_ih_l0)
nn.init.xavier_normal_(self.rnn.weight_hh_l0)
nn.init.xavier_normal_(self.fc1.weight)
def forward(self, x):
x = self.embed(x)
x, _ = self.rnn(x)
x = self.fc1(x[:, -1, :])
x = self.fc2(x)
return x
def calculate_loss_and_accuracy(model, dataset, device, criterion=None):
dataloader = DataLoader(dataset, batch_size=1, shuffle=False)
loss = 0.0
total = 0
correct = 0
model = model.to(device)
with torch.no_grad():
for X, Y in dataloader:
X = X.to(device)
Y = Y.to(device)
Y_pred = model(X)
if criterion != None:
loss += criterion(Y_pred, Y).item()
pred = torch.argmax(Y_pred, dim=-1)
total += len(Y)
correct += (pred == Y).sum().item()
return loss / len(dataset), correct / total
def TensorboardWriter(model, X, Y, epoch, loss, name, device):
writer = SummaryWriter(log_dir="logs")
model = model.to(device)
X = X.to(device)
Y_pred = model(X)
result = torch.max(Y_pred.data, dim=1).indices
result = result.cpu().data.numpy()
Y_pred = np.array([np.argmax(y) for y in Y_pred.cpu().data.numpy()])
Y = np.array([np.argmax(y) for y in Y.cpu().data.numpy()])
result = torch.tensor(result)
Y = torch.tensor(Y)
Y_pred = torch.tensor(Y_pred)
accuracy = result.eq(Y).sum().numpy()/len(Y_pred)
writer.add_scalar("Loss/{}_Loss".format(name), loss, epoch)
writer.add_scalar("Accuracy/{}_Accuracy".format(name), accuracy, epoch)
writer.close()
def CountVocab(name):
f = open("[PATH]/{}_code.txt".format(name), "r")
lines = f.readlines()
f.close()
max_num = []
for line in lines:
line_t = line.split("\t")[2].replace("\n", "").split(" ")
max_num.extend(map(int, line_t))
vocab_max = max(max_num)+1
return vocab_max
def GetCodeLow(name):
f = open("[PATH]/{}_code.txt".format(name), "r")
lines = f.readlines()
f.close()
num_list = []
code_list = []
pad_list = []
for line in lines:
line_s = line.split("\t")
code_list.append(int(line_s[0]))
num = line_s[2].replace("\n", "").split(" ")
num = list(map(int, num))
num_list.append(num)
num_tensor = torch.tensor(num)
pad_list.append(num_tensor)
max_vocab = CountVocab("train")
mlen = max([len(x) for x in num_list])
pad_list = list(map(lambda x:x + [max_vocab]*(mlen-len(x)), num_list))
pad_list = torch.tensor(pad_list)
code_list = torch.tensor(code_list)
return pad_list, code_list
def Process(lines):
sign_regrex = re.compile('[!"#$%&\'()*+,-./:;<=>?@[\\]^_`|$#@£â€™é\n]')
word_list = []
text_list = []
true_label = []
for text in lines:
true_label.append(text.split("\t")[0])
text = text.split("\t")[1]
text = sign_regrex.sub("", text)
text = re.sub("(\d+)", r" \1 ", text)
words = text.split(" ")
words = list(filter(lambda x:x, words))#空リスト削除
words = list(map(lambda x:x.lower(), words))#小文字にする
word_list.extend(words)
text_list.append(words)
return word_list, text_list, true_label
def MakeDict(name):
f = open("[PATH]/{}.txt".format(name), "r")
lines = f.readlines()
f.close()
word_list, _, _ = Process(lines)
c = collections.Counter(word_list).most_common()
word_dic = {}
for id, word in enumerate(c, 1):
if int(word[1]) < 2:
word_dic[word[0]] = 0
else:
word_dic[word[0]] = id
return word_dic
def GetInitWeight():
vectors = KeyedVectors.load_word2vec_format('[PATH]/GoogleNews-vectors-negative300.bin', binary=True)
worddic = MakeDict("train")
init_weight = []
init_weight.append(list(np.zeros(300)))
for key, value in worddic.items():
if value == 0:
continue
else:
try:
init_weight.append(list(vectors[key]))
except:
init_weight.append(list(np.zeros(300)))
init_weight.append(list(np.zeros(300)))
weights = torch.tensor(init_weight)
weights = weights.float()
return weights
weights = GetInitWeight()
def train_model(X_train, y_train, X_test, y_test, batch_size, model, lr, num_epochs, device, collate_fn=None):
dataset_train = TensorDataset(X_train, y_train)
dataset_test = TensorDataset(X_test, y_test)
model = model.to(device)
dataloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True)
dataloader_test = DataLoader(dataset_test, batch_size=batch_size, shuffle=True)
criterion = nn.CrossEntropyLoss()
criterion = criterion.to(device)
for ep in range(num_epochs):
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
if ep%30==0:
lr = lr * 0.1
model.train()
for X, Y in dataloader_train:
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
Y_pred = model(X)
loss = criterion(Y_pred, Y)
loss.backward()
optimizer.step()
model.eval()
loss_train, acc_train = calculate_loss_and_accuracy(model, dataset_train, device, criterion=criterion)
loss_test, acc_test = calculate_loss_and_accuracy(model, dataset_test, device, criterion=criterion)
print(f'epoch: {ep + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_Test: {loss_test:.4f}, accuracy_Test: {acc_test:.4f}')
TensorboardWriter(model, X_train, Y_train, ep, loss_train, "Train", device)
TensorboardWriter(model, X_test, Y_test, ep, loss_test, "Test", device)
X_train, Y_train = GetCodeLow("train")
X_test, Y_test = GetCodeLow("test")
BATCH_SIZE = 2
NUM_EPOCHS = 100
VOCAB_SIZE = CountVocab("train")+1#paddingの値用
EMB_SIZE = 300
OUTPUT_SIZE = 4
HIDDEN_SIZE = 50
lr = 1e-3
device = "cuda:0"
model = RNN(VOCAB_SIZE, EMB_SIZE, HIDDEN_SIZE, OUTPUT_SIZE, weights)
train_model(X_train, Y_train, X_test, Y_test, BATCH_SIZE, model, lr, NUM_EPOCHS, device)
出力結果

コメント
テストデータの精度は79.61%でした。もっといろいろチューニングすると上がるんですかね。。。scikit-learnでやったときは90%くらい行っていたのでそれに比べると精度は低くなりました。機械学習の難しさが詰まっていますね。特徴量の選定、モデルの選定、モデルのハイパーパラメータの選定など最適な選択が必要です。
後半の解答例
他章の解答例