環境
- JetsonTX2
- Jetpack4.2
- Ubuntu 18.04 LTS
- Darknet:Alexさんのリポジトリ
- OpenCV:3.3.1(Jetpack4.2標準)
インストール
Alexさんのリポジトリからプロジェクトをダウンロロード
git clone https://github.com/AlexeyAB/darknet.git
デバイスを動作モード変更
最速でデバイスを動作させるために設定を変更する。
sudo nvpmodel -m 0
sudo /usr/bin/jetson_clocks
Make
Darknetリポジトリをgit cloneしてきたら、darknet/Makefileの設定を以下に
GPU=1
CUDNN=1
CUDNN_HALF=1
OPENCV=1
AVX=0
OPENMP=0
LIBSO=1
USBカメラ使うんなら、OPENCVのフラグ、GPU使うならGPUのフラグを立てる。CUDNN_HALF=1とすることで、16ビット浮動小数点演算を行うことが可能となり高速な演算が可能となる。
Makeすると。。。
$ cd darknet
$ make -j4
…
/bin/sh: 1: nvcc: not found
Makefile:152: recipe for target 'obj/convolutional_kernels.o' failed
nvccどこだよーとパスで怒られたので、
$ sudo find / -name "nvcc"
[sudo] password for nvidia:
/usr/local/cuda-10.0/bin/nvcc
ってことで、/usr/local/cuda-10.0/bin/nvccにあることがわかりました。Makefileにパスを追加して、
CC=gcc
CPP=g++
# NVCC=nvcc
NVCC=/usr/local/cuda-10.0/bin/nvcc
OPTS=-Ofast
再度コンパイルすれば通ります。
実行する前に、学習済み重みをダウンロードする。ダウンロードするのは、一般的なyolov3.weightとyolov3-tiny.weight
$ cd darknet
$ wget https://pjreddie.com/media/files/yolov3.weights
$ wget https://pjreddie.com/media/files/yolov3-tiny.weights
静止画(犬と車)の認識
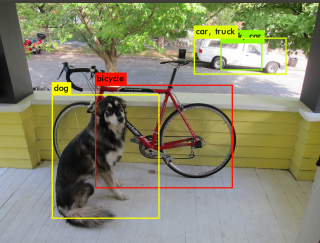
yolov3
実行
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
実行結果
[yolo] params: iou loss: mse, iou_norm: 0.75, cls_norm: 1.00, scale_x_y: 1.00
Total BFLOPS 65.864
Allocate additional workspace_size = 52.43 MB
Loading weights from yolov3.weights...
seen 64
Done!
data/dog.jpg: Predicted in 267.771000 milli-seconds.
bicycle: 99%
dog: 100%
truck: 94%
複数回実行した結果
data/dog.jpg: Predicted in 295.361000 milli-seconds.
data/dog.jpg: Predicted in 342.763000 milli-seconds.
data/dog.jpg: Predicted in 280.382000 milli-seconds
data/dog.jpg: Predicted in 314.492000 milli-seconds.
data/dog.jpg: Predicted in 342.232000 milli-seconds.
Yolov3-tiny
実行
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
実行結果
[yolo] params: iou loss: mse, iou_norm: 0.75, cls_norm: 1.00, scale_x_y: 1.00
Total BFLOPS 5.571
Allocate additional workspace_size = 52.43 MB
Loading weights from yolov3-tiny.weights...
seen 64
Done!
data/dog.jpg: Predicted in 93.378000 milli-seconds.
dog: 81%
bicycle: 38%
car: 71%
truck: 41%
truck: 62%
car: 39%
複数回実行した結果
data/dog.jpg: Predicted in 166.246000 milli-seconds.
data/dog.jpg: Predicted in 115.194000 milli-seconds.
data/dog.jpg: Predicted in 73.886000 milli-seconds.
data/dog.jpg: Predicted in 77.460000 milli-seconds.
data/dog.jpg: Predicted in 76.015000 milli-seconds.
data/dog.jpg: Predicted in 126.547000 milli-seconds.
data/dog.jpg: Predicted in 74.477000 milli-seconds.
USBカメラでリアルタイム認識
Webカメラでの実行で実行してみる。
手元にZEDしかなかったので、解像度は Video stream: 1344 x 376 。
yolov3
-cオプションを用いることで、入力のデバイスを指定可能。
device01として認識されているので、引数は-c 1としました。
deviceの確認はv4l2-ctl --list-devicesで確認できる。
$ ./darknet detector demo cfg/coco.data cfg/yolov3.cfg ./yolov3.weights -c 1

FPS:4.4
Objects:
surfboard: 30%
surfboard: 26%
person: 95%
person: 88%
大体4.3FPS~4.4FPSと安定
Yolov3-tiny
$ ./darknet detector demo cfg/coco.data cfg/yolov3-tiny.cfg ./yolov3-tiny.weights -c 1

FPS:27.8
Objects:
keyboard: 25%
person: 49%
FPS:32.3
Objects:
keyboard: 26%
person: 47%
FPS:27.0
Objects:
keyboard: 27%
person: 43%
大体27fps~32fps。JetPack3.2よりも高速化している?
動画による検証
検証用動画は
https://drive.google.com/file/d/1rdxV1hYSQs6MNxBSIO9dNkAiBvb07aun/view
を利用。
検出動画はyolov3***-res.avi、標準出力はyolov3***-res.txtとして保存。
yolov3-tiny
$ ./darknet detector demo cfg/coco.data cfg/yolov3-tiny.cfg ./yolov3-tiny.weights self_driving_valid.avi -out_filename yolov3-tiny-res.avi > yolov3-tiny-res.txt
yolov3
$ ./darknet detector demo cfg/coco.data cfg/yolov3.cfg ./yolov3.weights self_driving_valid.avi -out_filename yolov3-res.avi > yolov3-res.txt
TensorRTでYoloV3を試す
画像の連続読み込み
画像リストをもとに連続で画像を読みむ場合。-dont_showとすることで、処理結果が画像で表示されない。
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights -dont_show < test-list.txt > result-fp16-xavier-1920-1080.txt
処理速度の行だけ抽出。
cat result-fp16-xavier-1920-1080.txt | awk '/Enter/,/seconds./' > result-fp16-xavier-1920-1080-extract.txt