はじめに。
新型コロナウイルスの影響で、上海総合株価指数が7%引きの大バーゲンセール。

ここまで無茶苦茶下がると政府がたぶんお金を入れてくるので、このあと短期的に多少戻りそうな気がしますよね。(外してたら…残念でした)
バーゲンセールを愛してやまない私の妻(中国人)が全力で買いを推奨しているので、ちょっとquantitativeに分析してみましょう。
知りたいのは、「大暴落した翌日~翌月の反動で儲かるかどうか」。
定量モデルのフレームワーク
ということで、まずは日々のリターンをzscore化し、-2σ超えてる日だけを取り出します。
t\in\{t~|~{\rm zscore}(r_t)\leq -2\},~{\rm zscore}(r_t)=\frac{r_t - \mu}{\sigma}
そして、その日の翌日、1週間後、2週間後、3週間後、1か月後のリターンとの関係を求めます。
E[r_{t+d}]=f(r_t), ~d\in\{1, 5, 10, 15, 20\}
モデル① 自己相関
まずは自己相関をみてみます。上海総合は中国らしく外れ値ばかりで、通常のpearsonの積率相関(外れ値に影響されやすい)はいまいちな気がするので、ここはspearmanの順位相関(rank化されるため外れ値に影響されにくい)で求めました。
\rho=1-\frac{6\sum D^2}{N^3-N}
ここでDは対応するXとYの順位の差、Nは値のペアの数です(詳しくはWikiってちょ)。
順位相関をExcelで求めるのはそれなりに骨が折れますが、pandasであれば以下のコードで一発です。素晴らしいですね!
rho_spearman = df.corr(method='spearman')
実際にpandasで相関を計算した結果は図の通りで、全体的に負の自己相関が確認されます(=平均が0であるとすれば反発する傾向)。

モデル② 回帰分析
次に回帰分析を使って、今日の暴落(引けで-7.72%)から、翌日~翌月までのリターンを予測してみます。例によって、外れ値による回帰係数の影響を緩和するため、まずはリターン(事前&事後)を±2σの範囲でwinsorizeします。
{\rm winsorize}(r_{t+d})={\rm min}({\rm max}(r_{t+d},~\mu-2\sigma),~\mu+2\sigma)
その上で、xを暴落日当日リターン、yをその翌d日後リターンとする線形回帰を行い、本日のリターンx=-7.72%に対する予測値yを各dについて求めました。
{\rm winsorize}(r_{t+d})=\beta_d*{\rm winsorize}(r_{t})+\alpha_d+\epsilon_{t+d}
以上の回帰分析をscikit-learn.linear_modelsのLinearRegressionで実施した結果、予測されたd日後リターン(1日あたりの日率)はこちら。

この図からわかるように、反発するにしてもだいたい1週間~2週間が寿命のようです。
ここでの注意点として、1か月後も自己相関は負だったのにも関わらず予測値がマイナスであることに矛盾を感じる方もいるかもしれませんが、そもそも条件に該当する期間(=当日リターンが-2σ以下の暴落日)の1か月後リターンの平均が大きくマイナスであったことからこのような現象が起きます。相関は平均を0にして考えるのに対して、回帰分析であれば切片項により平均も考慮されます。
リターンの平均が0でない場合は往々にしてあることなので、相関だけで理解しようとするのは危険です。
さらに以下の図はx: 当日リターン(暴落日のみ)、y: 翌n日の累積リターン(n=1, 5, 10, 15, 20)の散布図です。
seabornのsns.regplot()を使えば、散布図の上に回帰直線と、その予測範囲も含めて一気にプロットしてくれちゃう!便利!

pythonコード
※上海総合株価指数のヒストリカルデータはyahoo financeからダウンロードしました。
https://finance.yahoo.com/quote/000001.SS/history?p=000001.SS
これを使って、こんな感じ↓にデータを整形し、pandasに読み込みました。
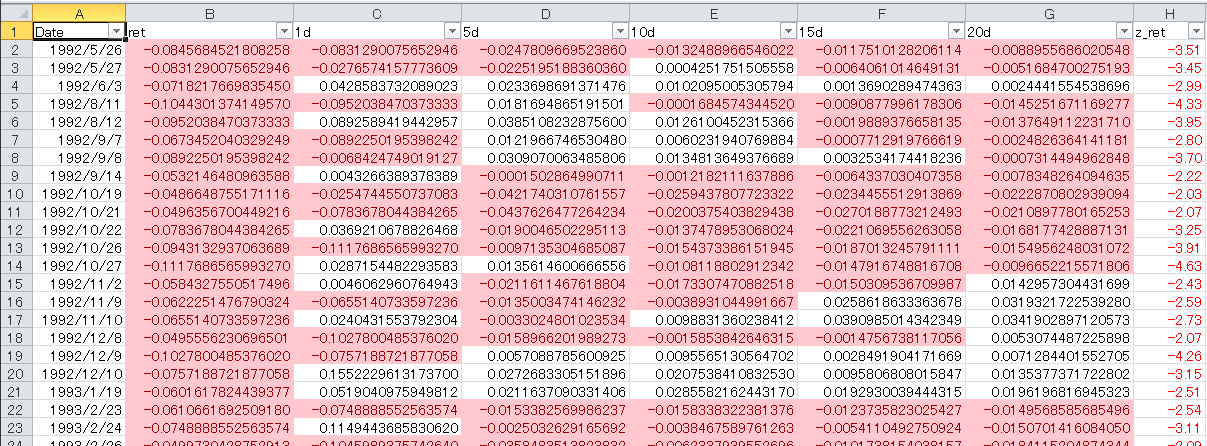
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
df = pd.read_clipboard()
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index('Date').astype('float')
df_clip = df.apply(lambda x: np.clip(x, x.mean() - x.std() * 2, x.mean() + x.std() * 2), axis='index')
span_list = df_clip.columns[1:-1]
pred = pd.Series(index=span_list)
X_pred = -0.0772
for span in span_list:
X = df_clip['ret'].values.reshape(-1, 1)
Y = df_clip[span].values.reshape(-1, 1)
reg.fit(X, Y)
pred[span] = reg.predict(np.array(X_pred).reshape(-1, 1)).flatten() * int(span[:-1])
plt.clf()
sns.regplot(x=df_clip['ret'], y=df_clip[span])
plt.title('x: ret(t), y:average_ret(t+1:t+' + span[:-1] + ')')
plt.savefig('span + '.png')
plt.clf()
fig, [ax1, ax2] = plt.subplots(ncols=1, nrows=2)
df_clip.corr(method='spearman').iloc[0, 1:-1].plot(kind='bar', ax=ax1)
ax1.set_title('conditional autocorrelation when ret < -2σ')
pred.plot(kind='bar', ax=ax2)
ax2.set_title('conditional predicted return when ret < -2σ')
plt.tight_layout()
plt.savefig('pred_ret.png')