使う必要が出てきたのでMini-batch-k-meansとk-meansとの比較お勉強し、備忘録
[Béjar Alonso, Javier. "K-means vs Mini Batch K-means: a comparison." (2013).]
(https://upcommons.upc.edu/bitstream/handle/2117/23414/R13-8.pdf)
どうやらk-meanと比べると同時にデータセットを分析に使わず固定されたサイズで
部分分にやる事で大規模データへの高速化をしているようだ。
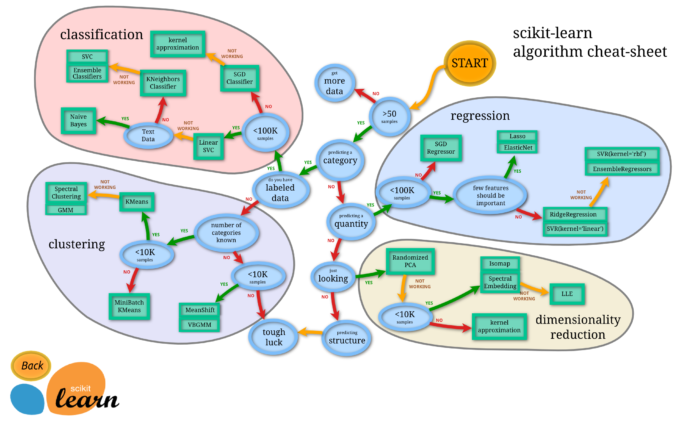
ただしPythonのScikit-learnのクラスタリングの使い分けを見ると小規模データ
への適用のときに勧められるアルゴリズムがMini-batch-k-means法になっている。
論文の最後の方にも10未満のクラスターは2%クオリティーが落ち、20以上のクラスターは8%クオリティーが落ちるとあり、大きなクラスタリングのときや精度を求められる際には不向きであるのかなと思ってしまう。
ただしここでいうクオリティーとは何を持って言っているのかは不明である。