前書き
この記事は下記記事の続きです。
超絶遅いクエリを直した後、謎のエラー地獄をどうやって解決するかを調べてみました。
実行環境
- サーバー
- Oracle Cloud Infrastructure
- Go/Gorm/OpenTelemetryを使ったとあるゲームAPI(Docker-compose)
- MySQL 8.1(Docker-compose)
- Oracle Cloud Infrastructure
- ログ基盤
- Uptrace(デプロイ環境)
- Jaeger(ローカル環境)
今回のトラブル
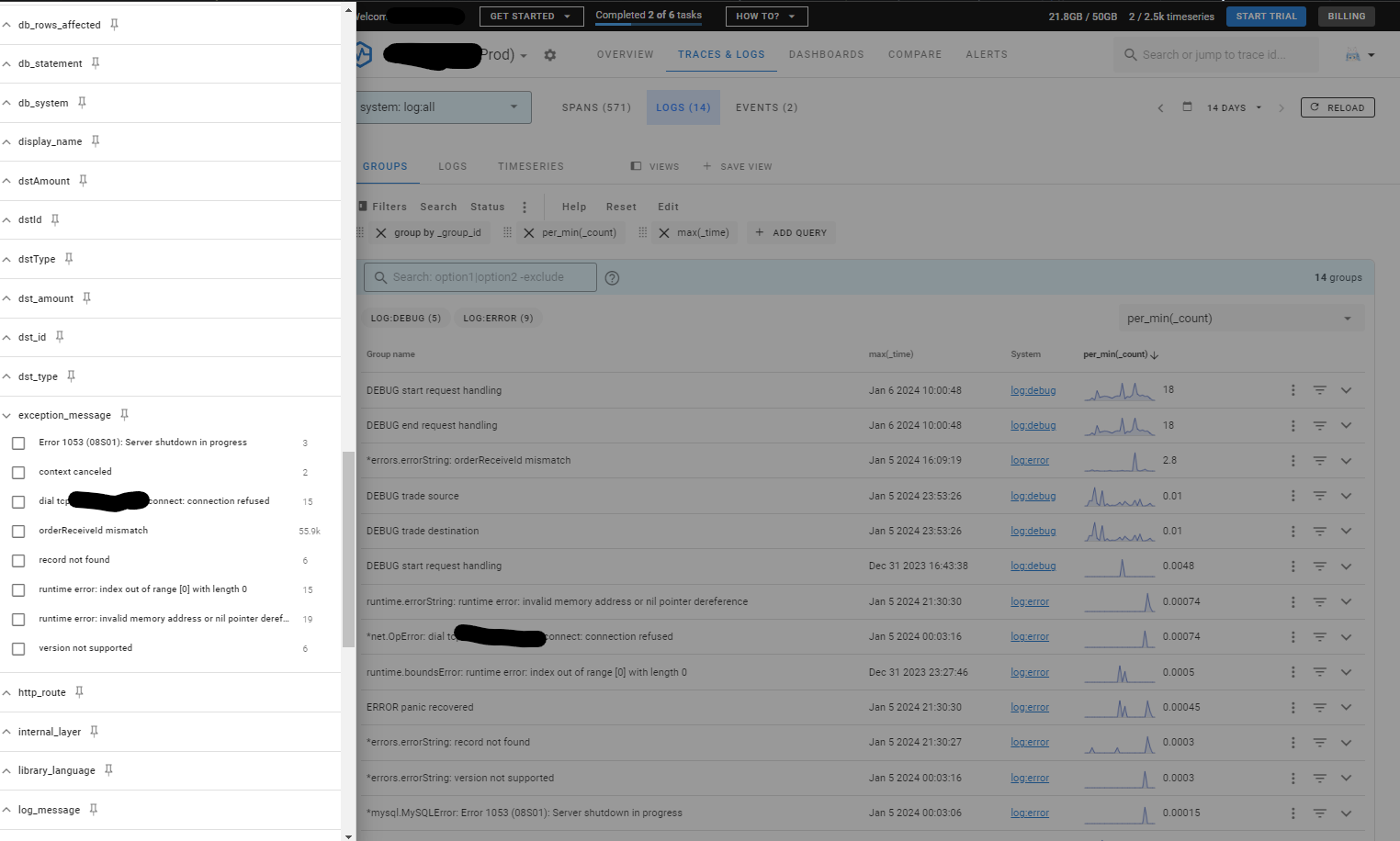
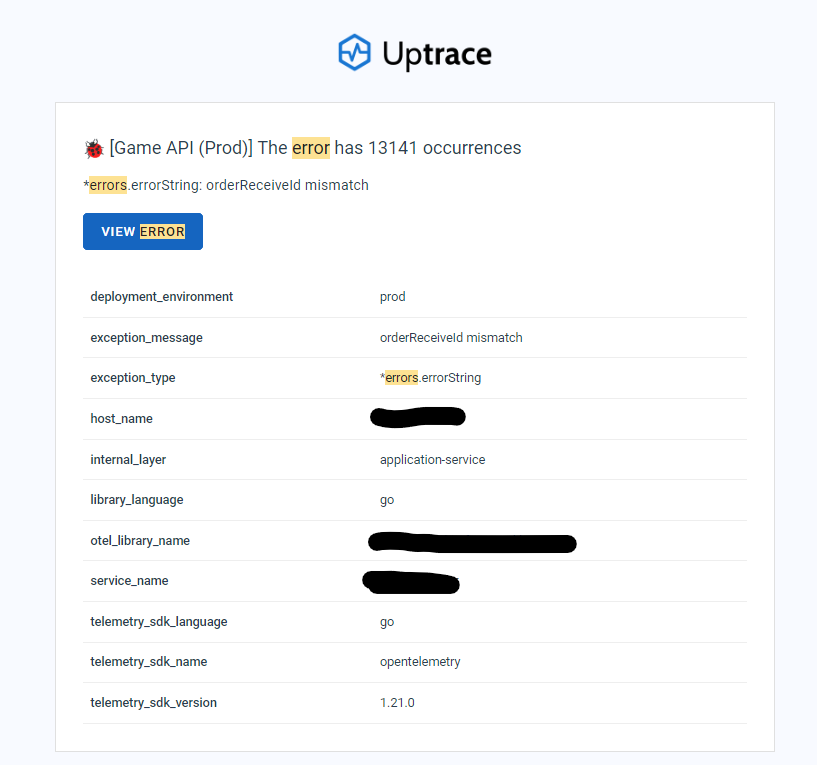
Uptraceでは、デフォルトでエラー発生時に(ある程度溜まったら?)ログをメールで送る機能が付いています。(無料で!) ある日エラーアラートメールが来たので見てみると1日で、orderReceiveId mismatch というエラーが13141回、2週間で55000回発生しているというとんでもないメールが送られてきたので原因を調査してみました。
トラブルの原因調査
手がかり1: エラーは普通のバリデーションで起こっている
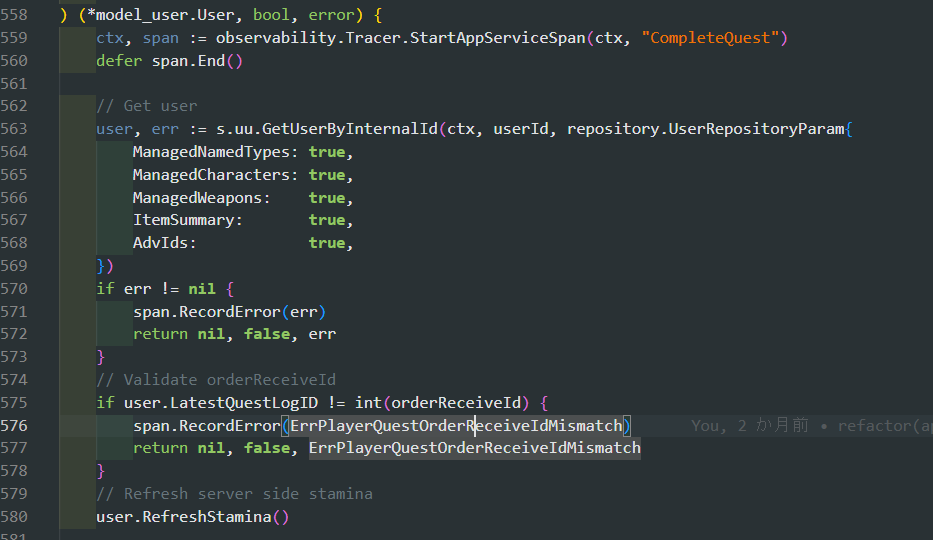
このエラーはサーバーがリクエストを受け取った際の一番初め、クライアントにリクエストされたパラメータの引数バリデーションで発生していました。つまり、サーバー側の処理上はこれで問題なさそうです。
→ バリデーションエラーである
手がかり2: 1ユーザーからしか起こっていない
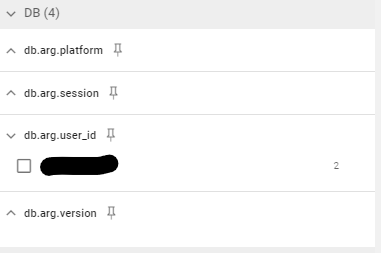
絞り込みの結果大量のエラーはすべて同一ユーザーのリクエストから発生していました。
→ 特定のケースのみで起こっている
手がかり3: クライアントはマクロ操作で自動的に連打されている
エラーを起こしているクライアントを使っているユーザーさんに事情聴取した協力頂いたところ、クライアントをマクロを使って自動操作しており、クライアントにエラーが発生したら勝手に再試行が行われていることがわかりました。そのため、つい最近まで気づいていなかったようです。尋常じゃない回数のエラーは、マクロが引き起こしていたものでした。
→ 最初の1回だけがエラーで、残りはすべて再試行であるため、エラーが起こっているのは実質1度だけ。
手がかり4: リクエストを23秒かけて完了させたログが残っている
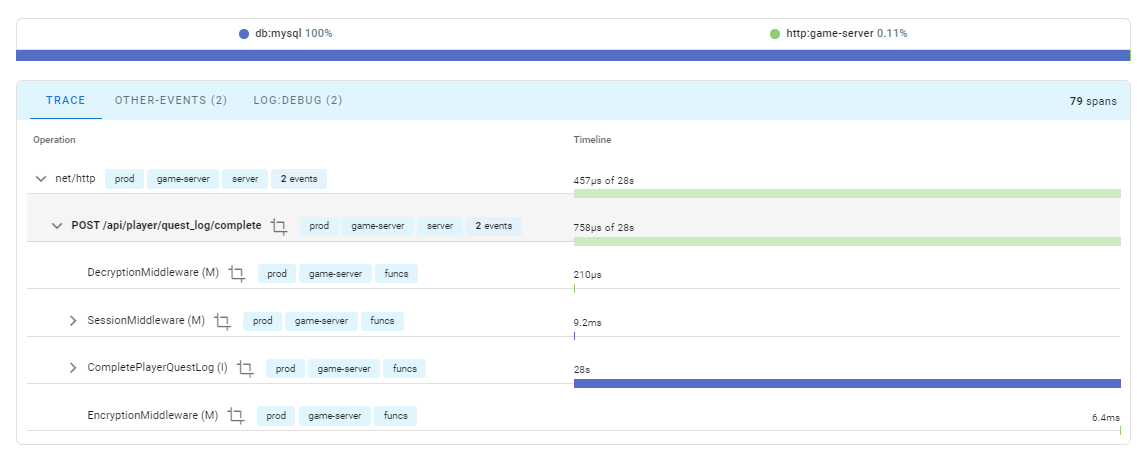
以前の記事によると、DBの処理に23秒という極端に長い時間かけて処理を完了させる場合があるとわかりました。
→ サーバーにタイムアウトがない
トラブルの原因
つまり原因は "クライアントだけのタイムアウト" です。
具体的には下記の図のようになっていました。
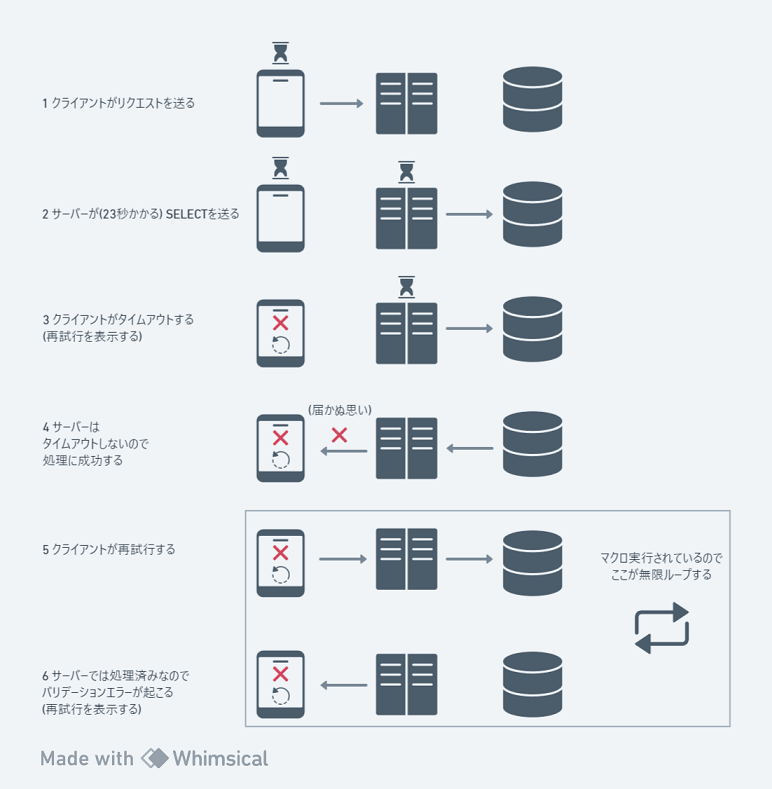
トラブルの解決
解決策1 タイムアウトするクエリを修正する
明らかにこれは常人が耐えられる待ち時間ではないため解決する必要がありました。
(前回の記事で行いました)
解決策2 サーバーにタイムアウトを設定する
クライアントがタイムアウトエラー(再試行)を持っているため、サーバーはそのタイムアウトまでに処理を終える必要があります。今回のパターンでは無限秒待って処理を完了させるのではなく、クライアントが汎用エラーを返す前にタイムアウトエラーを返すべきでした。
(そもそもの23秒かかろうが処理を完了させていたのはDDoSがとてもしやすそうという点で不味かったように感じます。)
解決策3 バリデーションエラーの発生時、クライアントに再試行ではなく再起動を要求するエラーを返す
"サーバーにとって処理済み"であることをクライアントに返すことができていなかったため、再試行が表示されていました。このケースでは、再試行を表示させず、ゲームをログインからやり直すのが理想の流れでした。
タイムアウトの実装
クエリの修正とエラーの変更は省略するとして、タイムアウトを起こせるような、ミドルウェアを実装してみた例を紹介します。
今回のAPIはOpenAPI Generatorを使い生成したため、EchoやGin等を使わず 素のnet/httpで実装しています。下記記事の要領でミドルウェアをルーターに挿入し、無事15秒でタイムアウトするようになりました。(コンテキスト処理がややこしいことになっているのは見逃してください)
func NewTimeoutMiddleware() func(next http.HandlerFunc) http.HandlerFunc {
return func(next http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
requestCtx := r.Context()
timeoutCtx, cancel := context.WithTimeout(requestCtx, 15*time.Second)
defer cancel()
processDone := make(chan bool)
go func() {
next(w, r)
processDone <- true
}()
select {
case <-timeoutCtx.Done():
err := timeoutCtx.Err()
if err == context.DeadlineExceeded {
logger := logger.FromContext(requestCtx)
logger.Ctx(requestCtx).Error("process timeout")
body := response.NewServerTimeoutResponse()
bufw := &responseBuffer{ResponseWriter: w}
json.NewEncoder(bufw).Encode(body)
rawResp := bufw.Buffer().Bytes()
w.Write(rawResp)
}
case <-processDone:
}
}
}
}
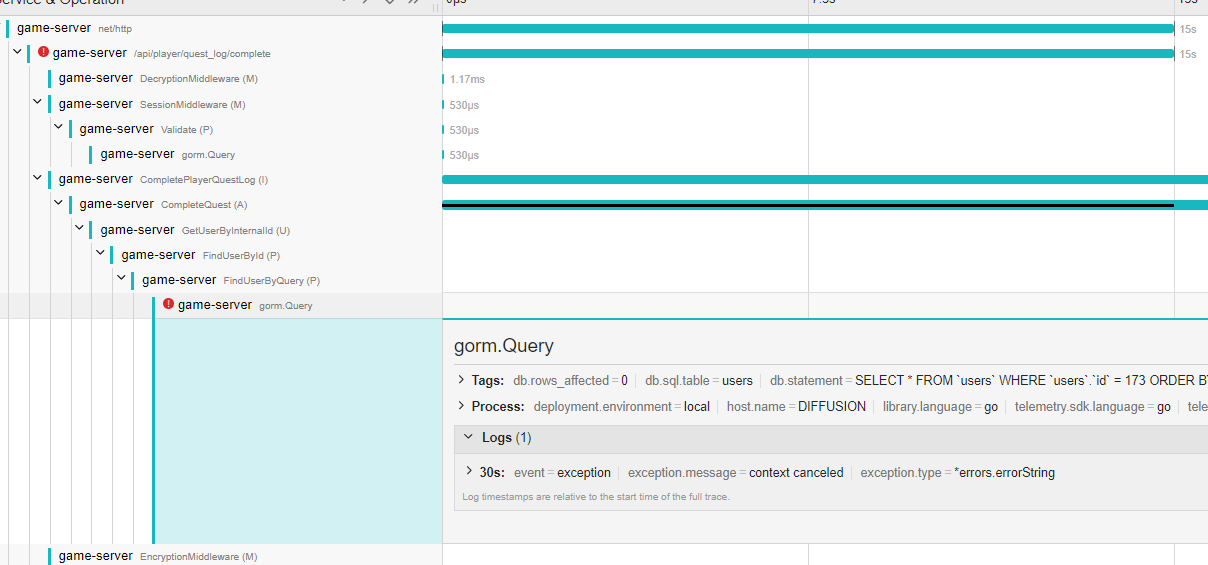
ミドルウェアでタイムアウトが発生した場合、どうなるのか?
今回のコードでは、そもそもミドルウェアで作ったコンテキストをnext()に渡していません。
この場合どうなるかというと、コンテキストタイムアウトを知らない無垢な関数群は忠実に処理を実行してしまいます。
このように思いましたが、実際には gormにコンテキストを渡して実行している場合、gormがそのタイムアウトを検出してくれるため、途中でエラーを発生させてくれます。これにより正しくエラー処理が終了しました。どこでタイムアウトしたのかを知るためにOpenTelemetryのログが最後まで送られるのを待ってから終了する必要があり、これは非常に好都合でした。
感想
何が原因なのかさっぱりわからず、かなり時間がかかってしまっていましたが、タイムアウトが原因とわかりスッキリしました。クライアントがマクロを使い操作されているとは聞いてみないとわからなかったので、関係者に話を聞いて情報を集めることも原因追求には大事だなぁ~と感じました。
備考
- コンテキスト周りの処理はまだ理解が浅く、今回のミドルウェアに何か問題があるように思うので十分ご注意の上参考にしてください