仕事で Slack を使用していると、休日や稼働終了後もついつい Slack を見てしまいゆっくり休めない方が多いのではないでしょうか。
通知をオフにしたりアプリを削除するのもありですが、結局休日明けに自分で対応しないといけません。
私は働きたくありません。
そこで今回作成したボット「yattoite」の出番です。
前提
- 勤怠管理を freee 労務で行っていて、稼働開始・終了するタイミングで打刻を行っている
- 社内のコミュニケーションツールに Slack を使用している
やったこと
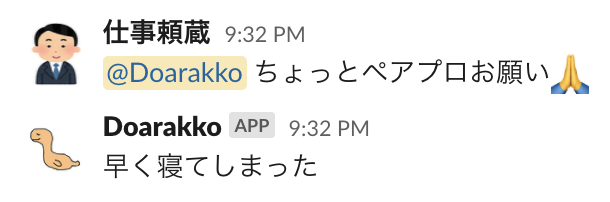
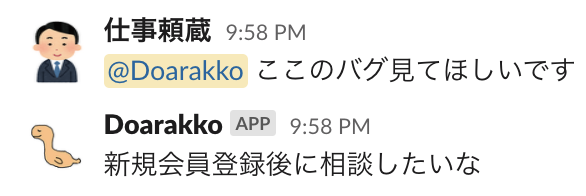
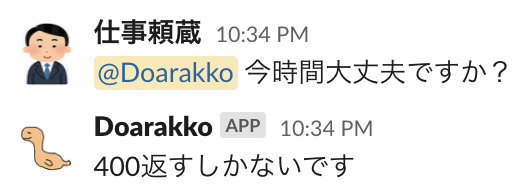
休日(or 稼働していない時間帯)に自分に Slack のメンションが飛んだときに、ボットに代わりに返答させるようにしました。
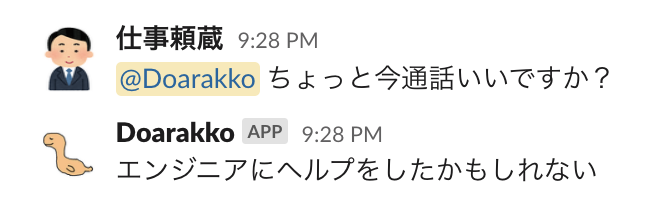
今回の目的は休日であることを相手に伝えることではありません。
ボットに代わりに対応させていることがバレたら...
そこで今回はボットだとバレないようにするためにいくつかの工夫を行いました。
1. メンション時に即返答させずにラグを作る
メンションと同時に返答してしまうと即ボットだと怪しまれてしまいます。
そこで乱数を使って 30 秒から 10 分の時間をおいてから返答させるようにしました。
time.sleep(
random.choice(
[10, 20, 20, 30, 30, 30, 60, 60, 60, 180, 240, 300, 360, 420, 480, 540, 600]
)
)
say(row.body)
本記事に添付しているものはテストのためこちらの処理を行っていません。
2. ボットのアイコンと名前を自分の Slack アカウントと同じものにする
自分の名前とアイコンではないアカウントが返答してしまったら即アウトです。
Slack App の設定から名前とアイコンを自分と同じものにしました。

よく見ると「App」の表示有無でボットだとバレてしまいますが、そこはなんとかなるでしょう。
3. 返答する文章を自分の過去のコメントを元にマルコフ連鎖で自動生成
返答する文章に全てが懸かっています。
ボットだとばれないようにするために、自分らしい文章を用意する必要があります。
自分で頑張って用意しても数十個が限界です。
また過去のコメントと同じものを使用すると怪しまれてしまいます。
今回は自分の過去の Slack でのコメントを元にマルコフ連鎖を使用して、1 万件(Heroku Postgres の無料枠での運用を想定)の文章を生成しました。
マルコフ連鎖についての説明は省きますが、「しゅうまい君」で使用されているものと言えばどんな文章が生成されるかだいたいのイメージはつくと思います。
マルコフ連鎖の性質上、文脈を考慮せずに支離滅裂な返答をしてしまう場合がほとんどですが、私は普段からよく支離滅裂なことを話しているので問題ないでしょう。
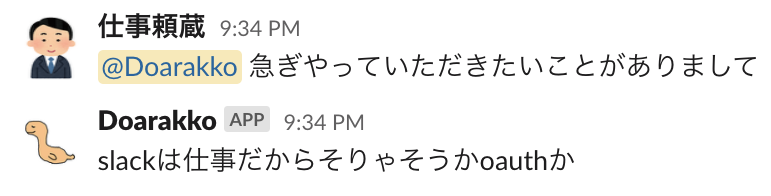
ここは今後強化したいところです。
全体の流れと構成
返答する文章は事前に生成し DB に格納しておきます。
ボット本体は Slack 公式が用意している Python 版 Bolt を用いて作りました。
- Slack でメンションが飛ぶ
- ボットがイベントをキャッチ
- freee人事労務 API を叩いて稼働中か確認
- 稼働していない場合は DB から事前に生成した文章をランダムに 1 件取得
- ランダムな時間待機
- Slack に投稿
freee人事労務 API で使用したものは以下になります。
ドキュメントがしっかりと用意されていて開発者サポートが手厚いです。
自分のユーザー ID を取得した後、そちらを使用してその日の勤怠情報を取得して稼働中か判定しています。
def is_working():
...
if clock_in_at is None:
return False
if clock_out_at is None:
return True
clock_in_at = datetime.datetime.strptime(j["clock_in_at"], "%Y-%m-%dT%H:%M:%S.%f%z")
clock_out_at = datetime.datetime.strptime(
j["clock_out_at"], "%Y-%m-%dT%H:%M:%S.%f%z"
)
now = datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9)))
return now >= clock_in_at and now <= clock_out_at
これでゆっくりと年末年始を過ごせそうです。

使用方法
ここからは手元でボットを動かすための説明になります。
不要な方は飛ばしてください。
後でHeroku で運用する手順を追記します。
必要なもの
- Slack
- freee API
- Docker
- docker-compose
手順
1. コード準備
git clone https://github.com/Doarakko/yattoite
cd yattoite
cp .env.example .env
2. Slack App を作成してトークンを取得
こちらからボット用の Slack App を作成します。
今までは必要な権限をブラウザ上でポチポチしていましたが、YAML ファイルから設定をインポートできるようになりました。
こちらのファイルをインポートしてください。
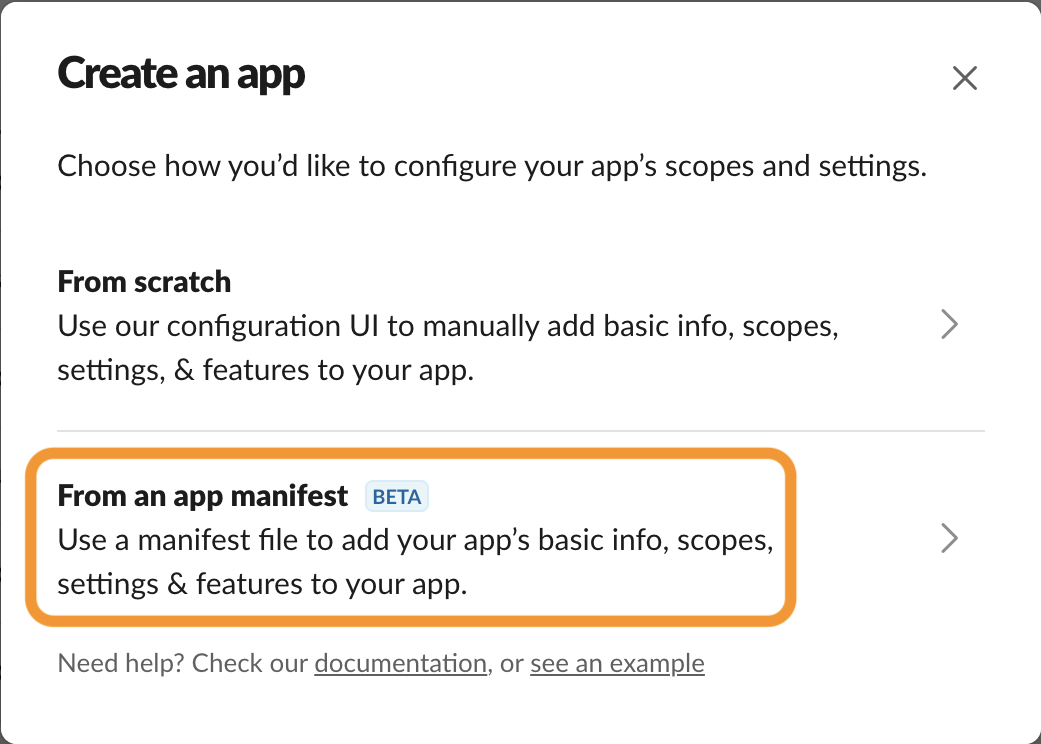
残念ながらトークンを取得するためには、ブラウザ上で追加で 2 つ作業を行う必要あります。
- 「Basic Inormation」から「App-Level Tokens」を
connections:writeで作成 - 「OAuth & Permissions」から Workspace にアプリをインストール
取得した 「App-Level Tokens」(xapp-aaaa)と「Bot User OAuth Token」(xoxb-bbbb)を .env ファイルに入力します。
...
SLACK_APP_TOKEN=xapp-aaaa
SLACK_BOT_TOKEN=xoxb-bbbb
SLACK_USER_ID=ABCD01234
...
自分の Slack のユーザー ID はアカウントを右クリックして「Copy link」で取得できます。
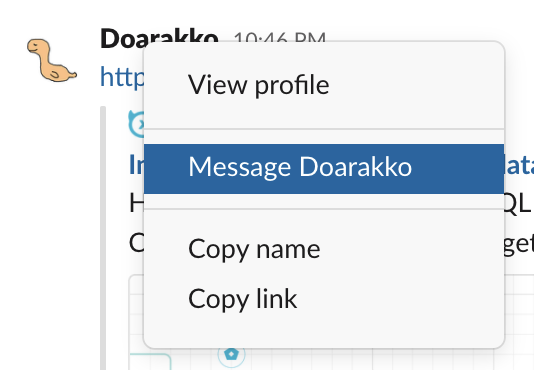
ボットはここで入力したユーザー ID のメンションにのみ反応します。
@app.message("^.*<@{}>.*$".format(os.environ["SLACK_USER_ID"]))
def message(say):
...
3. freee アプリを作成
こちらから作成します。
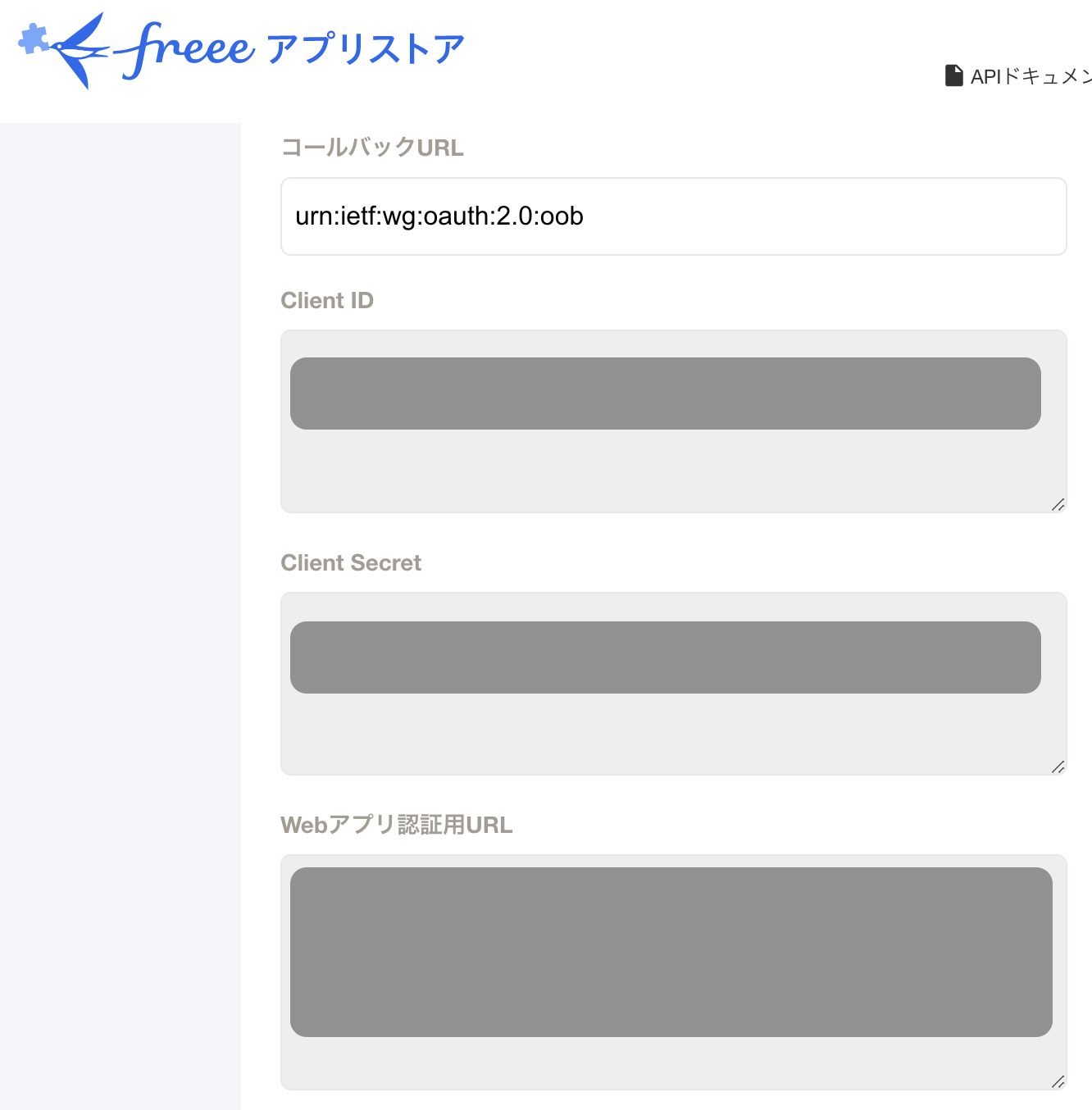
FREEE_CODE は「Web アプリ認証用 URL」にブラウザ上でアクセスして取得した「認可コード」を入れてください。
...
FREEE_CLIENT_ID=cccc
FREEE_CLIENT_SECRET=dddd
FREEE_CODE=eeee
...
4. Slack API を用いて自分の過去のコメントを収集
マルコフ連鎖で文章生成するために、Slack の過去の自分のコメントを収集します。
docker-compose up
docker exec -it app python scripts/create_table.py
<query> には取得したいチャネル名を入力します。
docker exec -it app python scripts/1_save_slack_comments.py <query>
times_ にすると times_ が含まれるチャネルを全て対象にできます。
チャネル・コメント数によっては数時間かかるのでご注意ください。
下記で収集したデータから自分のコメントのみを抽出して CSV ファイルに保存します。
docker exec -it app python scripts/2_select_slack_user.py <user id>
5. 収集したコメントに前処理をかける
マルコフ連鎖に投げるために文章を形態素に分解する必要があります。
形態素解析にはインストールが簡単な GINZA を使用しました。
docker exec -it app python scripts/3_preprocessing.py -i data/<user id>_comments.csv
こちらで記号の削除や特定文字列(URL、メンション、コードブロック、etc)が含まれるコメントの除外などの前処理を行っているので、各自カスタマイズしてください。
comments = comments[
(comments["body"].str.contains("<@.*>") == False)
& (comments["body"].str.contains("```") == False)
& (comments["body"].str.contains("<#.*>") == False)
& (comments["body"].str.contains("<!subteam.*>") == False)
& (comments["body"].str.contains("http") == False)
& (comments["body"].str.contains("`.+`") == False)
& (comments["body"].str.contains(">") == False)
& (comments["body"].str.contains("todo") == False)
& (comments["body"].str.contains("done") == False)
]
6. 文章生成
まずは短すぎる(長過ぎる)文章を除外します。
docker exec -it app python scripts/4_make_sentences.py -min <minimum word count> -max <max word count>
-min と -max オプションで、使用するコメントの長さ(形態素の数)を制御できます。
-min を 6 に設定すると 我々 4 歳 くらい です(5 個) は除外されます。
以下で文章の生成を行います。
docker exec -it app python scripts/5_generate.py -n <count of generate sentences> -s <state size>
-n で生成する文章の数、-s で元の文章で使用する形態素の数を指定できます。
-s を小さくしすぎるとと訳の分からない文章が、大きくしすぎると元の文章と近い文章が生成されます。
ここは実際に生成される文章(app/data/output.txt)を見ながら調整してみてください。
7. DB にデータを投入
docker exec -it app python scripts/6_insert.py
8. 動作確認
自動返答させたいチャネルにボットを招待する必要があります。
自分と同じ名前のボットを招待していることがバレたら怪しまれるのでうまいこと誤魔化してください。
おわりに
今回は個人利用を想定していますが、freee API を真面目に使えば全社員を対象に、休日の人にメンションが飛んだら「xx さんは休暇をとっているか稼働開始前です」と返すようなボットも作れると思います。
休日の人に間違えてメンションを飛ばしてしまった方もすぐわかりますし、休日の人も心理的に楽になるのではないでしょうか。
ふざけたことをしていないでそっちに時間を使っていれば良かったです。
おまけ:Heroku にデプロイ
低コストで実運用するために Heroku へのデプロイ方法を記載します。
以下のボタンを押して環境変数を入力すると Heroku にデプロイできます。

DB は Heroku Postgres を使用していますが、そちらへのデータ投入はローカル環境で行う必要があります。
Heroku ダッシュボードの「Settings/Config Vars」から DATABASE_URL を取得して、.env ファイルを編集、コンテナを再起動してください。
後は上記手順のテーブルの作成とデータの投入のみ行えば動きます。