はじめに
AIによる光学文字認識(OCR)は、単なる文字起こしから「文書理解」へと進化しています。中でもGoogle Gemini 2.5 Pro(05/06バージョン)は、これまでのOCRとは一線を画す高度な理解力と応用性を持つ次世代AIです。
本記事では、従来技術の壁を乗り越えたGemini 2.5 ProのOCR能力にフォーカスし、開発・業務にどう活用できるかを分かりやすく解説します。
1. Gemini 2.5 Proの特徴とOCR能力
Gemini 2.5 ProのOCR機能は、従来のOCRと異なり、単なる文字認識を超えて「文書全体の意味や構造を理解し、推論まで行える」ことが最大の強みです。
-
文書理解と推論力
抽出したテキストを表層的に並べるだけでなく、内容を読み取り、要約・分析・QAまで一気通貫で実現します。例えば契約書から特定条項を自動抽出したり、PDFの数百ページにわたる構造を踏まえて情報を要約することも可能です。 -
マルチモーダル処理
画像・PDFはもちろん、音声や動画など多様な形式のデータに対し、シームレスなOCR+AI処理ができます。
Google AI Studio上での実験では、YouTube動画の音声自動文字起こしや、映像のみのシーンから要点抽出も可能でした。 -
長大なコンテキスト対応
最大100万トークンという膨大な文脈を扱えるため、複雑で長大な文書も“全体を見渡した上で”一貫した情報抽出が可能です。
これらの特性により、Gemini 2.5 Proは「従来のOCRの限界」を大きく超えるAI文書活用基盤として注目されています。
2. Gemini 2.5 Pro OCRの使い方と実践例
(1)ノーコードで始めるならGoogle AI Studio
誰でもすぐ試せる最も手軽な方法は、Google AI Studio上で画像やPDFをアップロードし、プロンプトを入力するだけです。
- ステップ: AI Studioにアクセス → モデル選択 → ファイル添付 → 指示入力 → 実行
- ポイント: コーディング不要・試行錯誤がしやすい・一度に1000ページPDFも可
Google AI Studioで「gemini-2.5-pro-preview-05-06」を選択してください。
(2)PythonによるOCR自動化(API/SKD活用例)
業務やアプリ開発では、Python SDK「google-generativeai」を利用したOCR自動化が便利です。
画像ファイルからテキスト抽出
import google.generativeai as genai
from google.generativeai import types
import os
# APIキー設定(事前にGOOGLE_API_KEY環境変数を用意)
model = genai.GenerativeModel('gemini-2.5-pro-preview-05-06')
image_path = "sample.png"
prompt = "この画像からテキストを元のフォーマットを維持しながら抽出してください。"
with open(image_path, 'rb') as f:
image_bytes = f.read()
image_part = types.Part.from_bytes(data=image_bytes, mime_type='image/png')
response = model.generate_content([image_part, prompt])
print(response.text) # 抽出されたテキストが出力される
※ mime_typeはファイル形式(png, jpeg等)に合わせて変更
PDFファイルからテキスト抽出
import google.generativeai as genai
model = genai.GenerativeModel('gemini-2.5-pro-preview-05-06')
pdf_path = "sample.pdf"
prompt = "このPDFからすべてのテキストを抽出してください。"
uploaded_file = genai.upload_file(path=pdf_path, display_name="sample")
file_part = {"file_data": {"mime_type": uploaded_file.mime_type, "file_uri": uploaded_file.uri}}
response = model.generate_content([file_part, prompt])
print(response.text) # 抽出結果
(3)実践Tips・プロンプト設計のコツ
-
精度を上げるには
抽出したい情報や出力形式(例:JSON形式)をプロンプトで具体的に指示しましょう。
例:「このレシート画像から日付、店舗名、合計金額をJSONで抽出してください」 -
画像/PDFの品質
できるだけ鮮明なデータを用意するのが理想です。 -
エラー時の対処
「思考プロセス」出力やエラーメッセージを確認・活用し、指示文や画像内容を工夫すると改善する場合があります。
(4)より高度な活用例
-
YouTube動画や音声ファイルの文字起こしにも対応
Google AI Studioでは、動画や音声の自動トランスクリプト作成・要点抽出・多言語翻訳も可能です。 -
API利用時のコスト・上限
大量のファイルを処理する際は、バッチ処理やファイル分割アップロードなどを活用し、API利用上限やコストも考慮しましょう。
3. 導入事例
(1) 青空文庫・古典文学OCRの実践例
-
使用データ・背景
出典:青空文庫に収録された著作権切れ(70年以上前)の日本近代文学作品(縦書き・旧字体・歴史的仮名遣い)。
難易度:極めて高い(縦書き・段組、旧字・変体仮名、文体の揺れなど)

出力結果比較
Gemini 2.5 Pro Preview 05/06
大筋の文意や段落構成は保たれるが、固有名詞・助詞・助動詞の一部に誤認や脱落あり。ただしAIが自動的に“創作”することはなく、機械的な誤字・抜けが中心。校正前提のテキスト化なら十分実用レベル。

GPT-4.1
大規模な幻覚(Hallucination)現象。実際に画像に存在しない人名・情景・感情をAIが生成。原文の文学的雰囲気はあるが「創作」要素が多く、日本語OCR・書籍電子化には全く不向き。

| モデル | 文字・文意の再現率(目安) | コメント |
|---|---|---|
| Gemini 2.5 Pro-Preview 05/06 | 約85~90% | 校正前提で十分実用レベル。固有名詞や細部で若干の誤認・欠落があるが、全体の筋は正確に再現される。 |
| GPT-4.1 | 10%未満 | 原文から大幅に逸脱。存在しない人名や場面の“創作”が多数。業務用途・電子化用途では実用不可。 |
(2) 手書き文書OCR
-
例:日常の手書き日本語メモ
カタカナ・英語・記号・メールアドレス等が混在し、現代実用的な手書きOCR性能が問われるケース。

認識結果:

認識精度:100%(誤認なし)
原文と一字一句違いなく再現。日英混在、記号、メールアドレスも完全一致。
(3) PPT・レポート型ドキュメントOCR検証
-
例:企業サステナビリティに関するPPTスライド
レイアウトの複雑さ(段組、アイコン、表、グラフ、色付き背景等)を含む実務資料で性能検証。
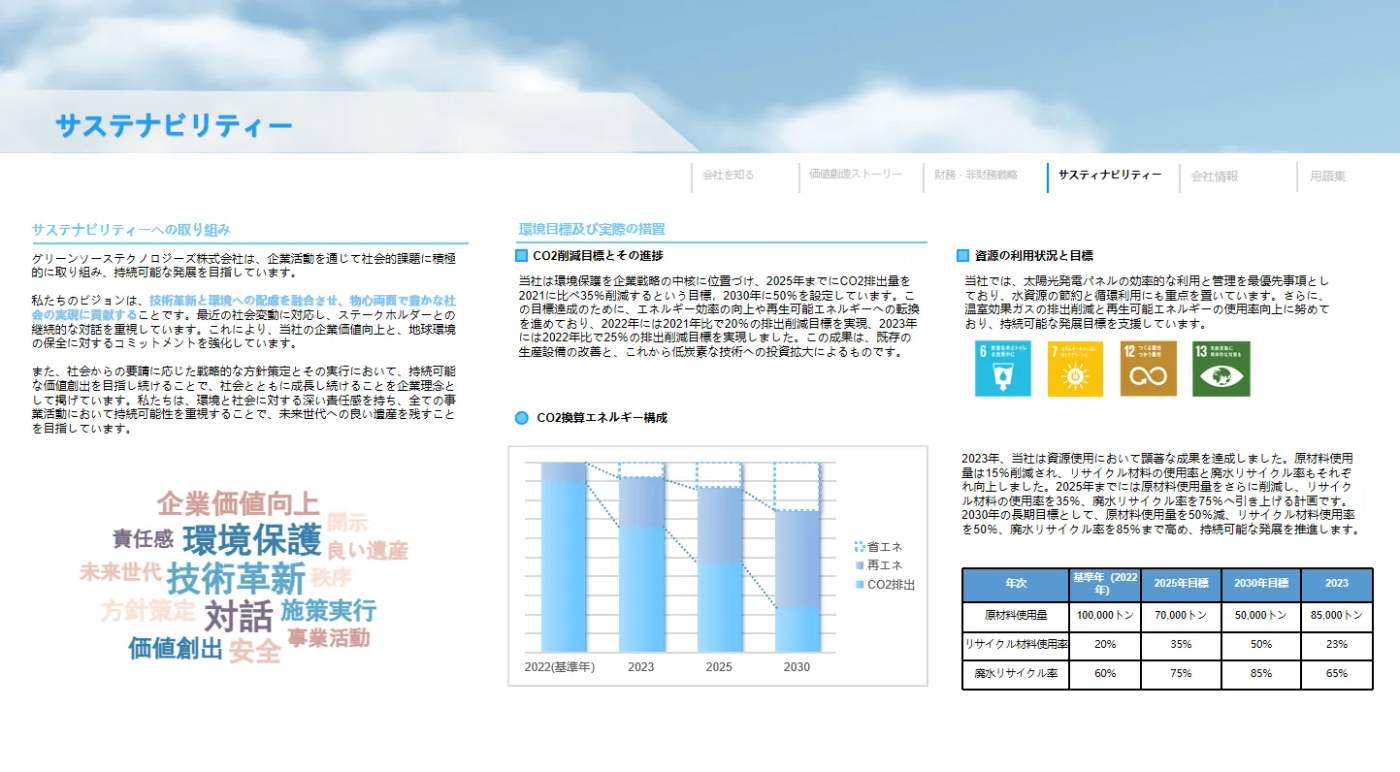
Gemini 2.5 Pro OCR出力例
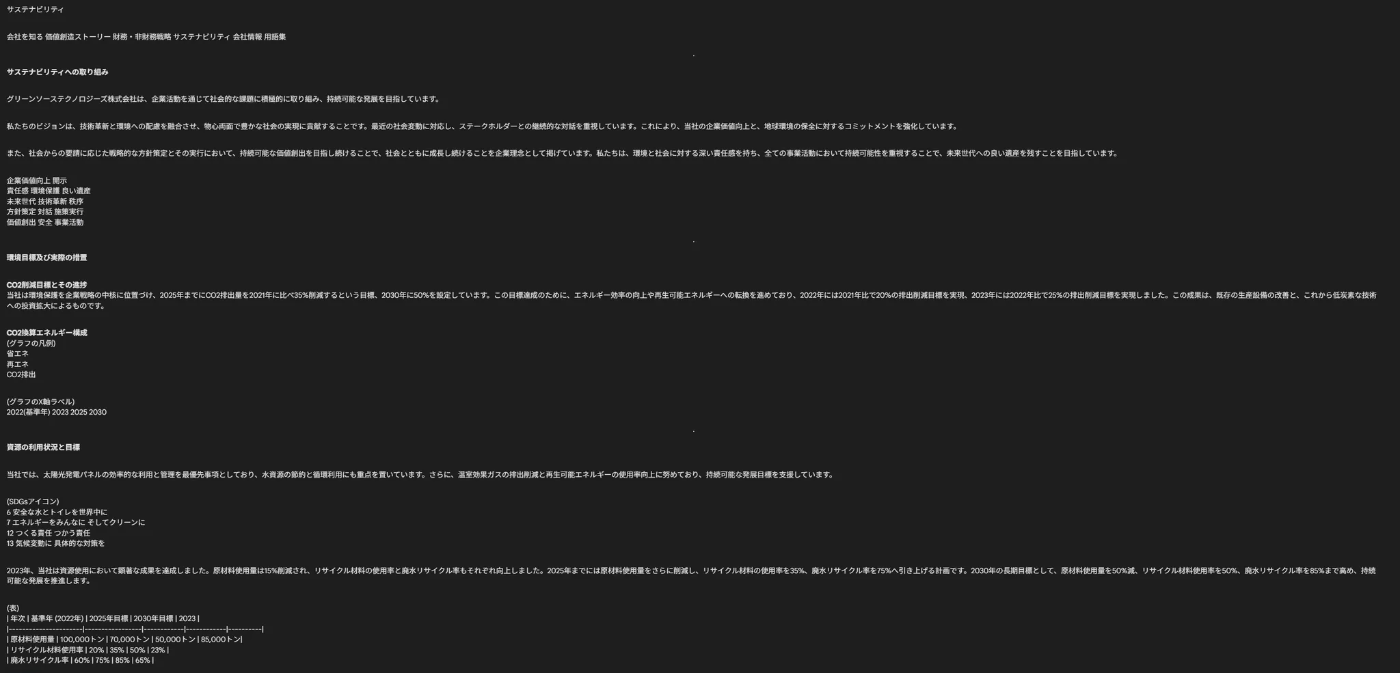
認識精度:ほぼ100%
本文、表、グラフ、SDGsアイコンの説明までほぼ誤字ゼロで自動認識。SDGsナンバーや説明も完全一致し、レイアウトもほぼ保持。
(4) 高度な数式画像OCR検証
検証対象:積分・Σ・ベクトル記号・多重積分などを含む複雑な数式画像
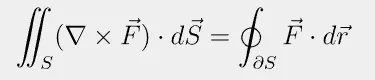
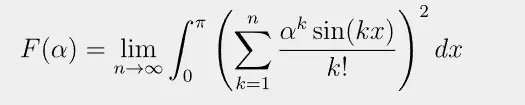
Gemini 2.5 Proによる認識結果(LaTeX形式出力):
1.
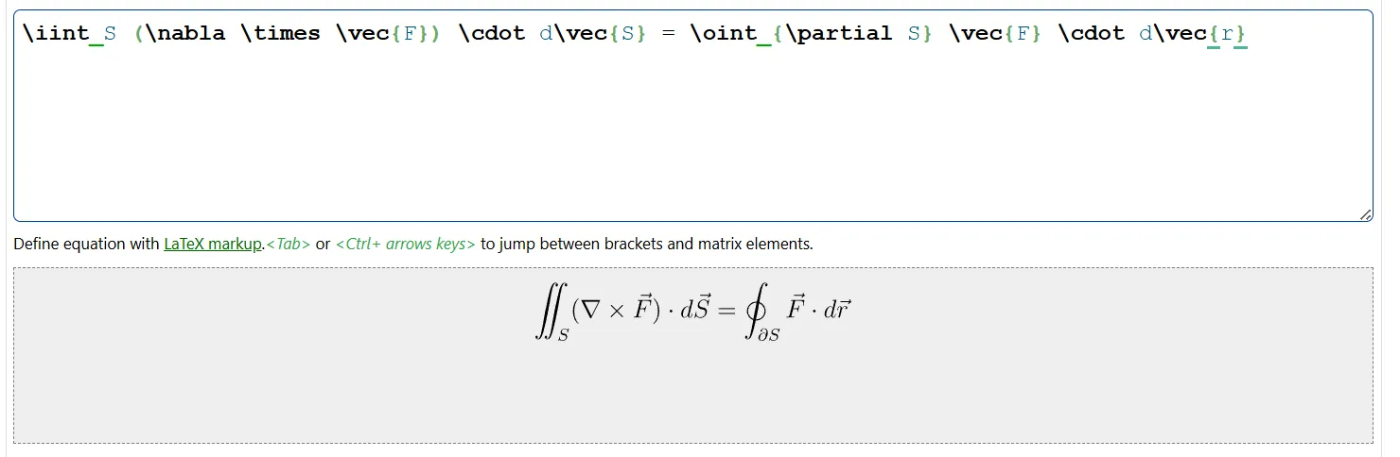
2.

認識精度:100%
画像のレイアウトや記号の細部まで100%一致。人手修正不要レベル。正答率実質100%。
4. 将来展望とエンタープライズ応用のヒント
1. 主要ユースケースと活用ヒント
-
契約書・技術文書の一括分析
Gemini 2.5 Proは、数百ページに及ぶ契約書や技術文書、財務レポート等から重要な条項や異常リスクを自動抽出・要約・比較できます。医療・法務・金融分野での複雑なPDFや非構造化データの自動仕分け・横断検索にも強みを発揮します。
-
業務帳票・紙ベースデータのDX(デジタル変革)
手書き伝票、請求書、レシート等の紙資料もOCRで正確にデータベース化し、CSVやJSONで即出力。入力ミス削減と事務作業の効率化を大幅に推進します。
-
マルチメディア連携型ワークフロー
動画・音声からの文字起こしや要約、YouTubeや会議録音からの自動議事録化・翻訳なども実用レベルに。今後は画像・音声・動画・テキストを統合した「マルチモーダル知識基盤」の実現が見込まれます。
-
品質・現場データのリアルタイム連携
工場・現場での部品番号・検査記録のOCR結果を、生産管理システム等に即時連携。不良品トレースやアラートの自動化などIoT/スマートファクトリーにも対応可能。
-
アクセシビリティ・バリアフリー
ポスター・看板・紙書類などの画像を即座にテキスト化し、音声で読み上げ。視覚障害者の情報アクセスや、多言語自動翻訳にも応用できます。
2. 今後の進化と企業現場への提案
-
レイアウト理解・長大文書対応の深化
複雑なPDFや帳票でもセクション・表・図解・キャプションまで構造的に理解し、整理されたデータとして一括出力。200万トークン級の巨大文書対応も視野に入っています。
-
AIエージェント連携による業務自動化
OCR→要約→判断→外部API(Docling, AutoAgent等)連携による「分析・報告・通知・登録」までを一気通貫で自動化。現場の知的ワークフローそのものを変革します。
-
プロンプト最適化とユーザーフィードバック
Gemini独自の「思考プロセス」可視化や、インタラクティブな誤認修正機能を活用し、AI×人間の協働で継続的な精度改善サイクルが構築可能です。
-
Docling+Gemini 2.5 Pro連携による企業知識インフラ
今後はDocling等の企業向け文書基盤とGemini 2.5 Pro OCRを統合し、「OCR抽出→構造化→全文検索→社内Q&A自動化」までをワンストップで実現。
既存のBox, Google Drive等クラウドSaaSとの連携も容易で、大規模・多拠点企業におけるナレッジDXの中核技術となる見込みです。
5. まとめ
本記事では、Google Gemini 2.5 Pro Preview(05/06バージョン)が持つ先進的なOCR機能に着目し、その技術的特長、活用方法、実践事例、そしてエンタープライズ現場における将来展望について解説しました。
Gemini 2.5 Proは、従来のOCRを大きく超える高精度な文字認識と文書構造の理解力、さらに画像・音声・動画を統合的に扱うマルチモーダル処理能力を備えています。
実際のテストでも、古典文学の縦書き、手書きメモ、複雑なPPTや高度な数式画像まで業務実用レベル〜100%に近い精度を達成。従来のAIモデルでは困難だったタスクにも、今や「AI OCRによる全自動化」が現実になりつつあります。
今後は、長大な契約書・技術文書の一括分析や、マルチメディアワークフローの全自動化、現場データのIoT連携、アクセシビリティ向上など、幅広いビジネスシーンでの活用が拡大する見通しです。
さらに、Docling等の知識基盤と組み合わせることで、社内外の膨大な非構造化データを自動で構造化・ナレッジ化し、「人とAIの協働による知的生産性革命」を後押しします。
Gemini 2.5 Pro OCRは、単なる文字起こしを超え、企業知識と業務自動化の中核インフラへと進化しつつあります。
本記事が、読者の皆様の業務変革や新規サービス開発の一助となれば幸いです。