はじめに
Claude CodeをはじめとするCLI形式のAIエージェント型プログラミング支援ツールが、非常に注目を集めています。この流れを受けて、先月Googleも「Gemini CLI」をリリースしました。
Gemini CLIで特に注目すべきは、完全にオープンソースで公開されている点です。他の多くのAIツールがブラックボックス化されている中で、その設計思想や実装の詳細を直接確認できるのは極めて価値のある機会です。
本記事では、Gemini CLIのソースコードを詳細に分析し、最先端のAIエージェントがどのような技術的仕組みで「自律性」を実現しているのかを探っていきます。AIエージェントの開発や設計に関心のある方には、参考になる内容となるでしょう。
1. Turnベースアーキテクチャ
Gemini CLIのソースコードを読み進めていくと、まず目に留まったのが「Turn」という概念でした。調べてみると、これがGemini CLI全体の動作を制御する中核的なアーキテクチャだったのです。
Turnとは何か
従来のチャットボットは「ユーザーが質問→AIが回答」という単純なサイクルで動作していました。Gemini CLIの「Turn」は、それをはるかに超えた複雑な概念として実装されています。
この仕組みを図解すると、以下のような流れになります:
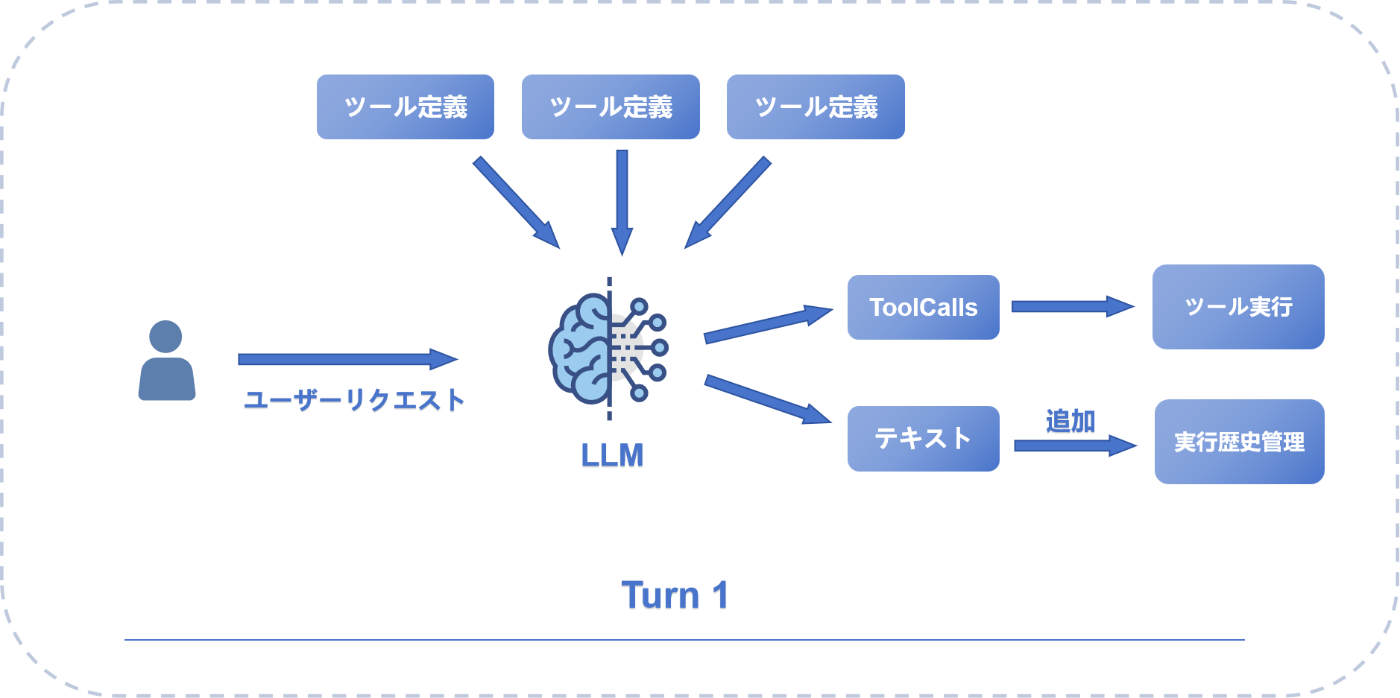
Turn 1の内部処理フロー図
図から分かるように、単一のTurnでも実際には複雑な処理が行われています。ユーザーからのリクエストがLLMに送られると、利用可能なツール定義を参照しながら、2つの異なる出力経路に分岐します。
一つはツール呼び出し(ToolCalls)として具体的なアクションを実行し、もう一つはテキスト応答として実行履歴に記録されます。この二重の出力構造により、AIは「考えながら行動する」ことが可能になっているのです。
実際のコードから、その本質を見てみましょう:
// packages/core/src/core/turn.ts より
export class Turn {
// 実行待ちのツール呼び出し一覧
readonly pendingToolCalls: ToolCallRequestInfo[];
// デバッグ用の応答履歴
private debugResponses: GenerateContentResponse[];
constructor(
private readonly chat: GeminiChat, // チャット管理インスタンス
private readonly prompt_id: string, // 現在のプロンプトID
) {
this.pendingToolCalls = [];
this.debugResponses = [];
}
// 単一ターンの実行メイン処理
async *run(
req: PartListUnion, // ユーザーからのリクエスト
signal: AbortSignal, // キャンセル用シグナル
): AsyncGenerator<ServerGeminiStreamEvent> {
try {
// Gemini APIからストリーミング応答を取得
const responseStream = await this.chat.sendMessageStream(
{
message: req,
config: {
abortSignal: signal,
},
},
this.prompt_id,
);
// 応答を順次処理
for await (const resp of responseStream) {
// Gemini 2.0の思考プロセス処理
const thoughtPart = resp.candidates?.[0]?.content?.parts?.[0];
if (thoughtPart?.thought) {
const rawText = thoughtPart.text ?? '';
// **主題**の抽出(アスタリスクで囲まれた部分)
const subjectStringMatches = rawText.match(/\*\*(.*?)\*\*/s);
const subject = subjectStringMatches
? subjectStringMatches[1].trim()
: '';
// 主題以外の部分を説明として抽出
const description = rawText.replace(/\*\*(.*?)\*\*/s, '').trim();
// 思考イベントを発行
yield {
type: GeminiEventType.Thought,
value: { subject, description },
};
continue;
}
// 通常のテキスト応答処理
const text = getResponseText(resp);
if (text) {
yield { type: GeminiEventType.Content, value: text };
}
// ツール呼び出し要求の処理
const functionCalls = resp.functionCalls ?? [];
for (const fnCall of functionCalls) {
// ツール呼び出しイベントを生成
const event = this.handlePendingFunctionCall(fnCall);
if (event) {
yield event;
}
}
}
} catch (e) {
// エラー発生時の処理とイベント発行
}
}
}
3層アーキテクチャ:GeminiClient、Turn、GeminiChatの連携
Turnは単独で動作するものではありません。実際にコードを追っていくと、Gemini CLIの綺麗な3層アーキテクチャの一部として機能していることが分かります:
GeminiClient(セッション全体の管理)
↓ sendMessageStream()でTurnを開始
Turn(単一ターンの実行)
↓ chat.sendMessageStream()を呼び出し
GeminiChat(会話履歴とコンテキスト管理)
各層が明確な役割を担っているのが、この設計の特徴です。GeminiClientがマルチターンの流れを制御し、Turnが個々の実行を管理し、GeminiChatが履歴を保持する。
マルチターン処理 (AIが「自分で考えて」作業を続ける仕組み)
Gemini CLIは、このマルチターン処理でAIが自律的に作業を続ける仕組みを実現しています。
実際のコードを見てみましょう:
// packages/core/src/core/client.ts より
async *sendMessageStream(
request: PartListUnion, // ユーザーリクエスト
signal: AbortSignal, // キャンセル制御
prompt_id: string, // プロンプトID
turns: number = this.MAX_TURNS, // 残りターン数(デフォルト100)
originalModel?: string, // 元のモデル名
): AsyncGenerator<ServerGeminiStreamEvent, Turn> {
// 無限ループ防止:最大ターン数で制限
const boundedTurns = Math.min(turns, this.MAX_TURNS);
if (!boundedTurns) {
return new Turn(this.getChat(), prompt_id);
}
// 新しいTurnインスタンスを作成して実行
const turn = new Turn(this.getChat(), prompt_id);
const resultStream = turn.run(request, signal);
// Turnからのイベントを上位に転送
for await (const event of resultStream) {
yield event;
}
// ツール実行完了後:次に誰が話すかを判断
if (!turn.pendingToolCalls.length && signal && !signal.aborted) {
// LLMに継続の必要性を判断させる
const nextSpeakerCheck = await checkNextSpeaker(
this.getChat(),
this,
signal,
);
// モデルが「まだ作業が必要」と判断した場合
if (nextSpeakerCheck?.next_speaker === 'model') {
const nextRequest = [{ text: 'Please continue.' }];
// 自分自身を再帰呼び出しして次のTurnへ
yield* this.sendMessageStream(
nextRequest,
signal,
prompt_id,
boundedTurns - 1, // ターン数をデクリメント
originalModel,
);
}
}
return turn;
}
再帰的な構造により連続的なタスク実行を実現し、boundedTurnsというカウンターで無限ループを防いでいます。シンプルでありながら実用的な解決策と言えるでしょう。
実際のマルチターン処理の流れを可視化すると、以下のようになります:
各Turnは独立しているように見えて、実際には「Execution History Manager」を通じて前のTurnの結果を次のTurnに継承している。Tool Executorは全Turnで共有され、一貫した作業環境を提供します。
特に注目すべきは、Turn 2以降で「Render History」というプロセスが挿入されている点です。これにより、AIは常に最新の作業文脈を把握しながら、次の行動を決定できるのです。最終的にTurn 3で作業が完了すると判断されれば、ユーザーに最終的な応答が返される。
2. 継続判断メカニズム:AIが「次に何をすべきか」を決める仕組み
Turnアーキテクチャの全体像を理解したところで、次に調べたくなったのはAIが「続けるか止めるか」をどのように判断しているかでした。
checkNextSpeaker
Gemini CLIの継続判断メカニズムの中心にあるのがcheckNextSpeaker関数です。この関数は、AI自身の最後の応答を分析して、次に誰が話すべきかを判断します。
実際のcheckNextSpeaker関数の実装を見てみると、巧妙な仕組みが見えてきます:
// packages/core/src/utils/nextSpeakerChecker.ts より
export async function checkNextSpeaker(
chat: GeminiChat,
geminiClient: GeminiClient,
abortSignal: AbortSignal,
): Promise<NextSpeakerResponse | null> {
// まず特殊なケースをチェック
if (lastComprehensiveMessage && isFunctionResponse(lastComprehensiveMessage)) {
return {
reasoning: 'The last message was a function response, so the model should speak next.',
next_speaker: 'model',
};
}
// LLMに次の話者を判断させる
const contents: Content[] = [
...curatedHistory,
{ role: 'user', parts: [{ text: CHECK_PROMPT }] },
];
const parsedResponse = await geminiClient.generateJson(
contents,
RESPONSE_SCHEMA,
abortSignal,
);
}
面白いのは、単純なキーワードマッチングではなく、LLM自身に「次に誰が話すべきか」を判断させている点です。これにより、文脈に応じた柔軟な判断が可能になっています。
コンテキスト管理
長時間の作業では、コンテキストウィンドウの制限が問題になります。実際に2時間以上の作業セッションでは、以下のような圧縮処理が動作します:
// packages/core/src/chat-compressor.ts より
class ChatCompressor {
private readonly compressionThreshold = 0.7;
async compressIfNeeded(chat: Message[]): Promise<Message[]> {
const tokenCount = await this.countTokens(chat);
const threshold = this.maxTokens * this.compressionThreshold;
if (tokenCount > threshold) {
const recentCount = Math.floor(chat.length * 0.3);
const oldMessages = chat.slice(0, -recentCount);
const recentMessages = chat.slice(-recentCount);
const summary = await this.summarizeMessages(oldMessages);
return [
{ role: 'system', content: `Previous conversation summary:\n${summary}` },
...recentMessages
];
}
return chat;
}
}
長時間の作業セッションでAIがどのようにコンテキストを管理しているかは重要な課題です。このChatCompressorクラスの実装を見ると、人間の記憶システムと同様に、古い情報は要約して「長期記憶」として保存し、最近の情報は詳細なまま「短期記憶」として保持するという設計になっています。
実践での比較:3つのツールのアプローチ
同じ「React コンポーネントのリファクタリング」タスクを3つのツールで実行してみた結果:
| 特徴 | Gemini CLI | Claude Code | Cursor |
|---|---|---|---|
| タスク分解 | 暗黙的(Turnで自然に分割) | 明示的(TodoList作成) | 一括提案 |
| 進捗の可視性 | 低(何をしているか不明瞭) | 高(チェックリスト表示) | 中(差分表示) |
| 柔軟性 | 高(状況に応じて変更) | 中(計画の修正が必要) | 低(承認か拒否のみ) |
| 実行時間 | 長い(段階的実行) | 中程度 | 短い(即座に提案) |
実際に同じタスクを3つのツールで試してみると、それぞれの特徴が明確に現れました。Gemini CLIの継続判断は自律的なエージェントに委任する感覚に近く、途中経過の可視性は低いものの、複雑なタスクを最後まで自律的に完遂してくれるという強みがあります。
3. ツールシステム
AIエージェントが実際の作業を行うためには、ファイル操作やコマンド実行などの「手足」が必要です。Gemini CLIでは、これらの機能を「ツール」という統一されたインターフェースで抽象化しています。
統一されたツールインターフェース
全てのツールは共通のインターフェースを実装しています:
// packages/core/src/tools/tools.ts より(実際のTool interface)
export interface Tool {
name: string; // ツールの内部識別名
displayName: string; // ユーザー向け表示名(必須)
description: string; // ツールの機能説明(必須)
schema: FunctionDeclaration; // API仕様定義
isOutputMarkdown: boolean; // 出力形式がMarkdownか
canUpdateOutput: boolean; // リアルタイム出力更新可能か
// パラメータの妥当性検証
validateToolParams(params: unknown): string | null;
// ユーザー確認が必要かどうか判定
shouldConfirmExecute(
params: unknown, // 実行パラメータ
abortSignal: AbortSignal, // キャンセル制御
): Promise<ToolCallConfirmationDetails | false>;
// ツールの実際の実行処理
execute(
params: unknown, // 実行パラメータ
signal: AbortSignal, // キャンセル制御(必須)
updateOutput?: (output: string) => void, // リアルタイム出力更新
): Promise<ToolResult>;
// 実行前の説明文生成
getDescription(params: unknown): string;
}
このシンプルなインターフェース設計により、Gemini CLIは高い拡張性を実現しています。新しいツールを追加する際も、このインターフェースを実装するだけで既存のシステムに統合できます。実際にカスタムツールを作成してみると、その簡潔さが実感できます。
安全性を考慮した実行フロー
興味深いのは、ツールの実行が複数の段階を経ることです:
実際のGemini CLIでは、ツール実行に複雑な状態管理システムが採用されています。CoreToolSchedulerクラスは以下のような状態遷移を管理します:
- validating: パラメータ検証中
- awaiting_approval: ユーザー確認待ち
- scheduled: 実行予定
- executing: 実行中
- success/error/cancelled: 完了状態
この状態ベースの設計により、複数のツール呼び出しを安全かつ効率的に管理できるのです。特に注目すべきは、各ツールのshouldConfirmExecuteメソッドが返すToolCallConfirmationDetailsに基づいて、ユーザーに適切な確認ダイアログを表示する仕組みです。
実際の開発作業中に、AIが意図しない危険なコマンドを実行しようとした際、この安全機構の重要性を実感しました。AIエージェントの便利さと安全性のバランスを取ることの重要性が、改めて明確になりました。
実際のツール実装例:ShellTool
シェルコマンド実行ツールには、高度なセキュリティ機構が組み込まれています:
// packages/core/src/tools/shell.ts の概念的な簡化版
export class ShellTool extends BaseTool {
private whitelist = new Set<string>(); // 承認済みコマンドのホワイトリスト
// コマンドの安全性を検証
isCommandAllowed(command: string): { allowed: boolean; reason?: string } {
// 1. コマンド代替 $() の禁止
if (command.includes('$(')) {
return { allowed: false, reason: 'Command substitution not allowed' };
}
// 2. 設定ベースの許可/ブロックリストシステム
// 3. コマンドチェーン解析 (&&, ||, |, ;)
// 4. 厳密な前置マッチング検証
return { allowed: true };
}
async shouldConfirmExecute(params: ShellToolParams): Promise<ToolCallConfirmationDetails | false> {
const rootCommand = this.getCommandRoot(params.command);
// 既にホワイトリストに登録済みの場合は確認不要
if (this.whitelist.has(rootCommand)) {
return false;
}
return {
type: 'exec',
title: 'Confirm Shell Command',
command: params.command,
rootCommand,
onConfirm: async (outcome) => {
// "常に許可"の場合はホワイトリストに追加
if (outcome === ToolConfirmationOutcome.ProceedAlways) {
this.whitelist.add(rootCommand);
}
}
};
}
}
注:上記は理解しやすさのために簡略化された概念コードです。実際のGemini CLI ShellToolはより複雑なセキュリティモデルを採用しています。
実際のShellToolは、単純な危険コマンドリストではなく、設定ファイルによる柔軟な許可/ブロック機構を採用しています。コマンドチェーン(&&、||など)の解析や、コマンド代替の検出など、高度なセキュリティ機能が実装されています。
拡張性:MCPによる外部ツール統合
Model Context Protocol (MCP)により、外部ツールも統合できます:
// settings.json の例
{
"mcpServers": {
"database": {
"command": "python",
"args": ["-m", "mcp_server_postgres"],
"env": {
"DATABASE_URL": "postgresql://localhost/mydb"
}
}
}
}
MCPを使った外部ツール統合にも対応しており、データベース操作やAPI連携など、様々なサービスとの統合が可能です。
4. ストリーミングアーキテクチャ:リアルタイム性の実現
Gemini CLIを使っていて特に印象的なのは、AIの思考過程までもがリアルタイムで表示される点です。この体験を実現しているのが、洗練されたストリーミングアーキテクチャです。
リアルタイム性を支える技術
Gemini CLIのストリーミング処理は、複数のコンポーネントが連携して実現されています:
主要なイベント類型(GeminiEventType):
-
Content: テキストコンテンツの段階的配信 -
Thought: Gemini 2.5の思考過程の可視化 -
ToolCallRequest: ツール呼び出しリクエスト -
ToolCallConfirmation: ツール実行確認 -
ToolCallResponse: ツール実行結果 -
UserCancelled: ユーザーによる操作中断 -
ChatCompressed: 長対話時のコンテキスト圧縮通知 -
MaxSessionTurns: セッション最大ターン数到達 -
Error: エラー情報の即座な伝達
思考内容の処理:
実際のコードでは、思考コンテンツ(Thinking)の処理において、以下のような構造化が行われています:
// Gemini 2.0の思考内容解析処理
// **主題**の部分を正規表現で抽出(**で囲まれた部分)
const subjectStringMatches = rawText.match(/\*\*(.*?)\*\*/s);
const subject = subjectStringMatches ? subjectStringMatches[1].trim() : '';
// 主題以外の部分を説明文として抽出
const description = rawText.replace(/\*\*(.*?)\*\*/s, '').trim();
// 構造化された思考オブジェクトを作成
const thought: ThoughtSummary = { subject, description };
ストリーミング状態管理:
StreamingContextにより、以下の状態が管理されています:
-
Idle: 待機状態 -
Responding: 応答中 -
WaitingForConfirmation: ツール実行確認待ち
この設計により、AIの思考プロセスから具体的なアクション実行まで、すべてをリアルタイムで追跡できる体験が実現されています。特にGemini 2.0の思考機能との組み合わせにより、従来のブラックボックス的なAI体験から、透明性の高い協働体験へと進化していると言えるでしょう。
まとめ
Gemini CLIのソースコードを詳細に分析することで、現代のAIエージェントがどのように「自律的」な振る舞いを実現しているか、その技術的な仕組みが明らかになりました。
発見:
- 継続判断は文脈を考慮したヒューリスティクスで実現
- Turnベースアーキテクチャにより段階的な問題解決が可能
- ツールシステムによる安全な外部操作の実現
- ストリーミング処理によるリアルタイム性の確保
これらの仕組みは完璧ではありませんが、現時点での技術的制約の中で、実用的なソリューションを提供していると評価できます。
AIエージェント開発に興味のある方は、ぜひGemini CLIのソースコードを読んでみることをお勧めします。実装に触れることで、ドキュメントだけでは分からない多くの知見が得られるはずです。
本記事はソースコードの分析に基づく解釈であり、開発者の意図とは異なる場合があります。