深層学習における物体検出の分野もLLMの波
近年、自然言語処理の分野で大きな注目を集めている大規模言語モデル(Large Language Models: LLMs)の急速な進歩は、他の AI 分野にも大きな影響を与えています。特に、コンピュータビジョンの重要なタスクの一つである物体検出においても、LLM の技術が活用され始めています。
従来の物体検出は、畳み込みニューラルネットワーク(CNN)を中心とした深層学習アーキテクチャに大きく依存してきました。しかし、LLM の登場により、テキストプロンプトを用いて画像内のオブジェクトを特定し、ラベル付けを行うことが可能になりつつあります。この新しいアプローチは、データアノテーションの効率化や、少量のデータでの学習(few-shot learning)への応用が期待されています。
LLM を活用した物体検出の代表的な例として、Grounding DINO や GroundingSAM などのモデルが挙げられます。これらのモデルは、自然言語の理解力を画像理解に応用することで、物体検出のパフォーマンスを向上させています。さらに、LLM の強力な言語理解力を活かすことで、従来の手法では困難だった、より抽象的で高度な概念のラベル付けも可能になると期待されています。
この新しい潮流は、物体検出のみならず、セグメンテーションやトラッキングなどの関連タスクにも波及しつつあります。LLM の進化が深層学習におけるコンピュータビジョンの分野にもたらす変革は、まだ始まったばかりです。今後、さらなる研究開発が進むことで、より効率的で高性能な物体検出システムが実現されるでしょう。
そんな中、コンピュータビジョンプロジェクトの効率化を支援するプラットフォームである Roboflow が、LLM を活用した自動ラベル付け機能 "Auto Label" のベータ版を公開しました。この新機能は、物体検出におけるデータアノテーションの負担を大幅に軽減し、プロジェクトの加速に大きく貢献することが期待されています。
Roboflowで自動ラベル画像を起動
コンピュータビジョンプロジェクトを進める上で、データアノテーションは非常に時間がかかり、フラストレーションを感じやすい作業の一つです。Roboflowはこの問題に対処するため、Auto Label(ベータ版)の提供を開始しました。このテキストプロンプトベースの手法は、オープンソースリポジトリのAutodistillを活用し、一度に数千枚の画像をラベル付けできるように設計されています。
Auto Labelの特徴
- Grounding DINOやGroundingSAMなどの基礎モデルを使用して、通常は本番環境での使用には遅すぎるものの、画像を自動的にラベル付けします。
- ゼロショットモデルであり、カスタムデータに対して微調整することなく動作します。
- 新しいプロンプティングインターフェイスにより、様々なプロンプトとクラスレベルの信頼度閾値を迅速にテストできます。
Auto Labelの使用方法
- 画像をRoboflowにアップロードします。
- Auto Labelに画像を割り当てます。
- モデルにラベルを付けるオブジェクトを指示するテキストプロンプトをテストします。
- プレビューモードで満足するまでプロンプトを調整し、画像を一括ラベル付けします。
- トレーニングを開始する前に最終レビューを実施します。
Auto Labelベータアクセス
- 全てのRoboflowユーザーがベータ版の一環として無料でAuto Labelを使用できます。
- 1つのラベリングジョブあたり最大1,000枚の画像が設定されています。
- ベータ期間後の価格、制限、および利用可能性は変更される場合があります。
Auto Labelは、次のコンピュータビジョンプロジェクトのラベリング時間を数週間短縮する可能性を秘めた、革新的なバッチラベリング機能です。この新機能により、開発者はより迅速かつ効率的にプロジェクトを進められるようになるでしょう。
Auto Labelで実際にラベリングしてみた
まず、Roboflowにサインインして下さい。そこで、画像データをアップロードして下さい。
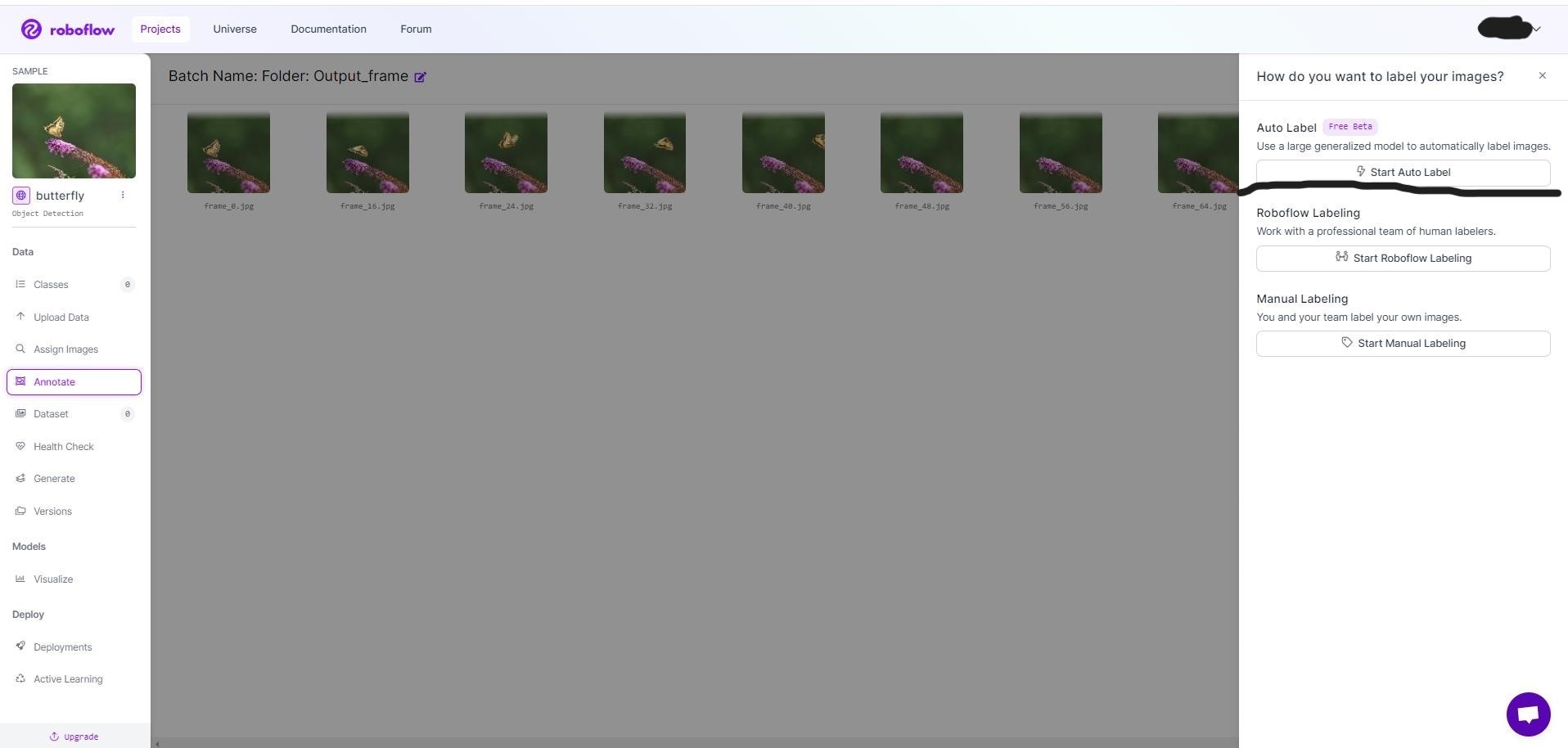
Start Auto Labelで自動ラベリング開始です!
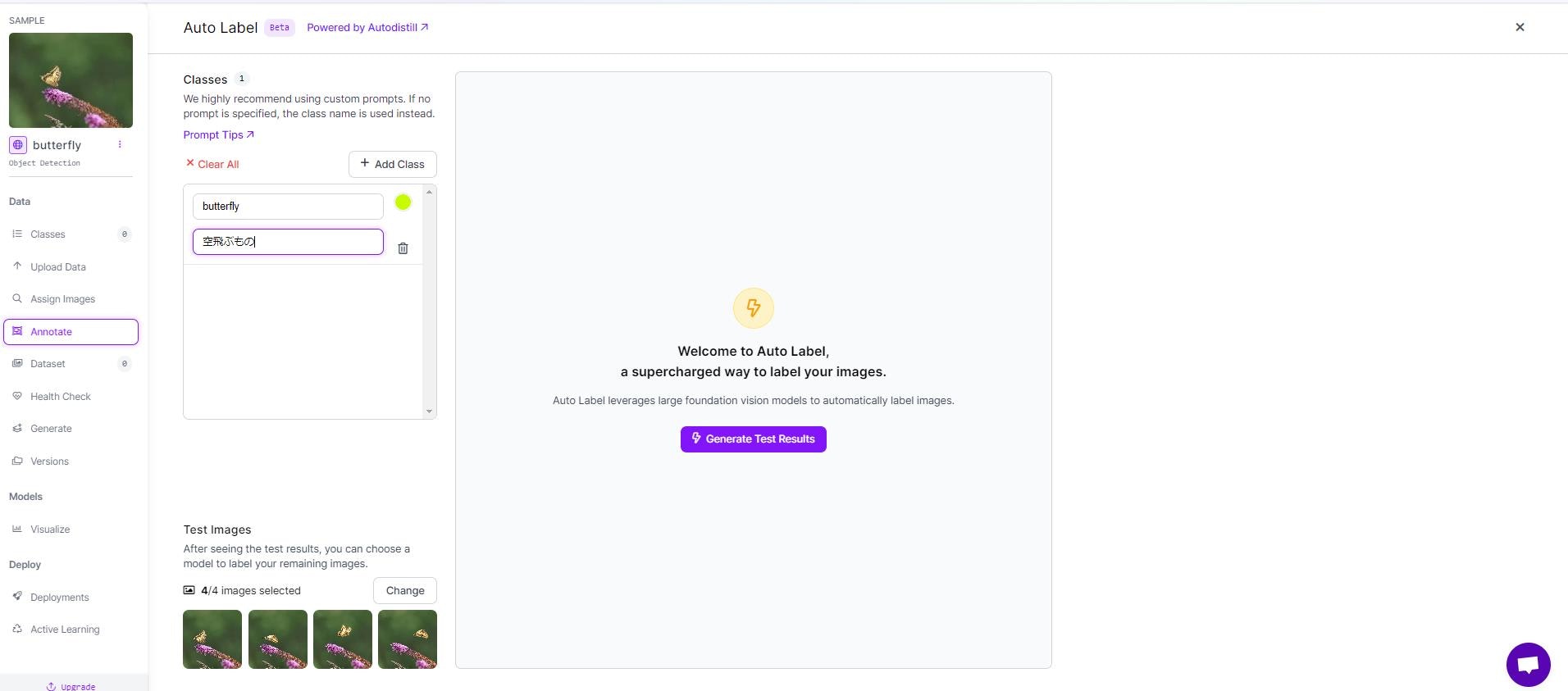
今回、物体検出するのは、蝶です。なので、ラベリングを「蝶」にし、promptを「空飛ぶもの」に設定しました。プロンプトが日本語対応しているかはわかりませんが、今回はエラーなく、上手くいきました。
これで、ラベリングほぼ終わりです!あとは、ラベリングが上手くいっているか確認して下さい。私の場合は、全て、上手くいってました!
以下のColabのリンクで、カスタムデータセットの学習が出来ます。
YOLOで距離を算出してみよう
上のYOLOを用いた距離算出のコード(参照から引用)
import cv2
import math
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
model = YOLO("yolov8s.pt")
cap = cv2.VideoCapture("Path/to/video/file.mp4")
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
out = cv2.VideoWriter('visioneye-distance-calculation.avi', cv2.VideoWriter_fourcc(*'MJPG'), fps, (w, h))
center_point = (0, h)
pixel_per_meter = 10
txt_color, txt_background, bbox_clr = ((0, 0, 0), (255, 255, 255), (255, 0, 255))
while True:
ret, im0 = cap.read()
if not ret:
print("Video frame is empty or video processing has been successfully completed.")
break
annotator = Annotator(im0, line_width=2)
results = model.track(im0, persist=True)
boxes = results[0].boxes.xyxy.cpu()
if results[0].boxes.id is not None:
track_ids = results[0].boxes.id.int().cpu().tolist()
for box, track_id in zip(boxes, track_ids):
annotator.box_label(box, label=str(track_id), color=bbox_clr)
annotator.visioneye(box, center_point)
x1, y1 = int((box[0] + box[2]) // 2), int((box[1] + box[3]) // 2) # Bounding box centroid
distance = (math.sqrt((x1 - center_point[0]) ** 2 + (y1 - center_point[1]) ** 2))/pixel_per_meter
text_size, _ = cv2.getTextSize(f"Distance: {distance:.2f} m", cv2.FONT_HERSHEY_SIMPLEX,1.2, 3)
cv2.rectangle(im0, (x1, y1 - text_size[1] - 10),(x1 + text_size[0] + 10, y1), txt_background, -1)
cv2.putText(im0, f"Distance: {distance:.2f} m",(x1, y1 - 5), cv2.FONT_HERSHEY_SIMPLEX, 1.2,txt_color, 3)
out.write(im0)
cv2.imshow("visioneye-distance-calculation", im0)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
out.release()
cap.release()
cv2.destroyAllWindows()
参照