はじめに
Xにある投稿が話題になった。
実際のツイート内容は下記となる。

カード会社のWebページで各月単位でしかダウンロードできず、複数月の一括ダウンロードができない仕様となっている。ユーザビリティが低いという問題である。
X上では様々な意見が飛び交い議論の対象となっていた。
- 技術的負債による改修できない理由がある
- レイテンシーが上がり、性能要件が満たせない
- 単純なエンジニアの技量不足
- そもそもの一括ダウロードの仕様の優先度が低い
実際にどういう実装になっているか、裏事情などを知らない1個人としては推測の域を超えない。まあどれも一理ある意見だなと思う。
改修コストについての考察
本記事では、「改修コストが高いため実現できない」という意見に焦点をあてて執筆しようと思う。

確かに各月のダウンロードが実現できているのであれば、裏側の処理を繰り返し呼び出すことで、バックエンド側の改修コストは直感的には高くならない気がする。帳票をマージする処理が入ると一気にメモリ消費コストが増加するが、単純にZipにまとめてレスポンスを返す程度であればすぐに実現できそう。以下、改修が発生する箇所を妄想してみる。
警告
筆者はユーザ数が多い大規模システムの経験が乏しく、金融系システムの取り扱い経験はありません。あくまでポエム記事である前提でお読みい頂ければ幸いです。
Fileダウンロードの処理を考察
Webサイトを触ってみる
まずは実際にWebページを触り、どういう処理がされてファイルダウンロードされているか考察しようと思う。
話題になった某金融機関のアカウントを持っていないため、別会社のWebサイト(楽天カード)を使わせていただく。

こちらのUIに関しても一括D/L処理が見当たらず、単月でファイルをダウンロードのみのため、こちらのサイトをベースに考える。
HTTPリクエストを確認
PDFボタンを押下した際のネットワークを見てみる。
<a href="/e-navi/members/statement/download-list.xhtml?downloadAsPdf=0" class="stmt-dw-btn type-pdf">PDF</a>
PDFボタンを押下した際のネットワークを見てみる。

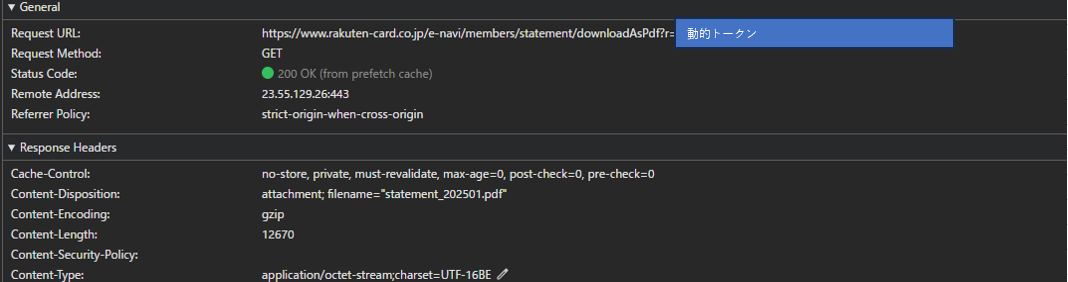
- GETリクエストを投げた後は、トークンを付与したURLにリダイレクトしている
- フロント側で特別にスクリプトが実行されていない
フロント側とバックエンド側の結合度が高いようには見えない。BFF等も大して絡んでいないであろうと推測。
また同月のPDF押下を1回目押下時、2回目押下時のレスポンスを計測したところどちらも200ms前後で変化は特にない。
オンデマンドでPDF作成処理をしていて2回目以降はキャッシュしているならレスポンスに変化が出るかと思ったがそうでもない。裏側でバッチ等による作成済みのファイルを返しているだけのロジックと想定。
シーケンス図の概略
以上より、シーケンス図の概略を考えてみた。

オンデマンドによるリアルタイムの帳票作成を行っていないことを考えると、処理自体かなりシンプルで改修コストもそこまでかからない可能性が高そう。
性能考慮した改修すべき事項
求められるレスポンス指標について
まず業務システムとは異なりBtoCのWebサービスのSLAはかなり高い水準を求められるはず。以下引用。
1秒(1,000ミリ秒)を超えると、ユーザーは自身が実行したタスクへの関心を失い始めています。
単純にクエリパラメータで複数月を渡して、バックエンドのループ処理を回すだけでは性能問題に直結する可能性も高い。バックエンド側の改修としては性能を担保できるような改修をしなければならない。
並行処理や非同期処理の導入
まず考えられるのはマルチスレッドで並行処理の実現だろう。
既存の処理が下記のようにシングルファイルの取得前提のメソッドしか設けられていない場合は、マルチスレッドで取得できるようにメソッドを新設する必要がある。
public void downloadStatement(HttpServletResponse response, int year, int month) {
try {
// S3からファイルを取得する例
s3object = s3Client.getObject(new GetObjectRequest(bucketName, key));
try (InputStream is = s3object.getObjectContent()) {
is.transferTo(response.getOutputStream());
}
}
public void streamDirectlyFromS3(HttpServletResponse response, LocalDate startDate, LocalDate endDate) {
try {
// 対象期間の明細書ファイルキーを取得
List<String> fileKeys = getFilesToDownload(startDate, endDate);
// ZIPストリームの作成とファイル書き込み
try (ZipOutputStream zipOut = new ZipOutputStream(response.getOutputStream())) {
// 非同期でS3からファイルを取得しZIPに追加
List<CompletableFuture<Void>> futures = fileKeys.stream()
.map(key -> CompletableFuture.runAsync(() -> {
S3Object s3object = null;
try {
s3object = s3Client.getObject(new GetObjectRequest(bucketName, key));
// ZIPファイルへの書き込み(同期化して順序を保証)
synchronized (zipOut) {
zipOut.putNextEntry(new ZipEntry(getFileName(key)));
s3object.getObjectContent().transferTo(zipOut);
zipOut.closeEntry();
}
}, executorService))
.collect(Collectors.toList());
// 全ての非同期処理の完了を待機
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
}
}
サンプルソースは、生成AIでS3からのダウンロードを非同期処理で指示して適当に書かせた。リトライ処理やエラーハンドリングを実装する必要も出てくるが、サービス層にビジネスロジックをしっかり分離できているシステムでは非同期に改修するコストもさほど高くないだろう。肥大化したコントローラーやロジック分離がめちゃくちゃ場合はおそらくこの分離作業だけでも相当なコストがかかるとは思うが。
備考:
zipファイルの生成のAWSをフル駆使したアーキテクチャのテックブログを見つけたので、参考までにリンク張っておきます。
https://developers.prtimes.jp/2023/12/25/use_go_and_aws_to_build_press_kit_batch_download/
キューイングシステムの導入
アクセス処理が一時的に普段より爆発的に多くなるタイミングがあるかもしれない。
一度に大量の処理が来た場合でも、キューに溜めて順次処理することで、システムがダウンするのを防ぐことが可能となる。
本件の場合は月末、年度末などがピークになるかもしれない。
ZOZOが公開している下記の記事が面白いのでこれもリンク張っておく。
データベースの修正
DBの修正が必要か考えてみる。
裏で帳票を作成した際にレコードを生成して、そこからパスを取得する実装である場合を検討する。テーブル定義は下記のようなイメージ
CREATE TABLE statement_files (
id BIGINT PRIMARY KEY,
user_id VARCHAR(50),
statement_date DATE,
file_path VARCHAR(255),
created_at TIMESTAMP,
status VARCHAR(20)
);
インデックスが存在しない場合に追加、それに伴い一括でパスを取得できるようにロジック側のクエリ修正くらいしか思いつかない。月次単位にテーブルがパーティション分割されている場合は考慮する必要もなし。
CREATE INDEX idx_statement_files_user_date
ON statement_files (user_id, statement_date);
結論
技術的負債で何か難しいことがあるのでは?と思い書いたものの全く思いつかず。
オンデマンドで帳票を作成していない限り改修コストは大したことないんじゃ?
誰か技術的負債による改修コストが高くなる具体的な事象を思い付いた方がいれば教えてください。
追記
前提として金融系システムの改修は絶対に落ちない、止まらないよう、金・時間かけるのが基本。単純に改修するプログラムのステップ数が少ないからと言ってコストが低いという記載は語弊を生みますね。追記として補足まで。