本書は物体検出の代表モデルであるSSDについて説明します。
(CNNの基礎を理解している前提で記載しています。まだ理解していない方は別冊のCNNの基礎を先に読んでください。)
【参考文献、サイト】
・ SSD原論文 、日本語翻訳サイト
・ ニューラルネットワーク/ ディープラーニング
SSDの実装コードの解説も記載しています。よろしかったら下記の記事もみてください。
1.物体検出(Object Detection)
はじめに、物体検出とは何かについて説明します。物体検出とは、画像内の物体領域の検出と、物体領域のクラス判定(Classification ex.猫、犬)を同時に行うものです。クラス判定をClassfication、物体領領域の検出をLocalizationと呼びます。

物体検出では主にバウンディングボックス(以降、BBoxと表記)と呼ばれる矩形で物体を検出します。具体的には、以下の5つの変数を予測します。
- class_name(クラス名)
- bounding_box_top_left_x_coordinate(矩形左上のX座標)
- bounding_box_top_left_y_coordinate(矩形左上のY座標)
- bounding_box_width(矩形の幅)
- bounding_box_height(矩形の高さ)
※SSDではX座標、Y座標は中心座標を用います
2.物体検出での評価指数
次に、物体検出を評価するための代表的な評価指数について説明します。物体検出では、検出精度の評価はAP/mAPやIoU、処理速度についてはfpsが主に使われます。
- AP(Average Precision) : クラスごとの平均適合率
- mAP(mean Average Precison) : 平均適合率APの全クラス平均
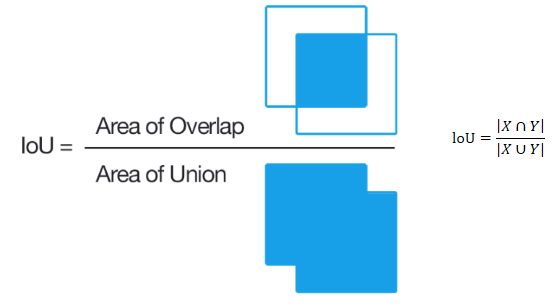
- IoU(Intersection over Union) : BBoxの一致度(オーバーラップ率、Jaccard係数とも呼ばれています)
- fps(frames per second) : 1秒間に何フレーム(画像)処理できるか
(1) 二値分類の評価指標について
物体検出の評価指標を説明する前に、基本の二値分類の評価指標について説明します。
二値分類では、予測結果と実際の値との間で以下の4つのパターン(①TP(真陽性)、②TN(真陰性)、③FP(偽陽性)、④FN(偽陰性))が存在し、混同行列として表現されます。
※ここで1文字目は予測が正解(True)か不正解(False)か、2文字目は予測が正(Positive)か予測が負(Negative)か、を表しています。
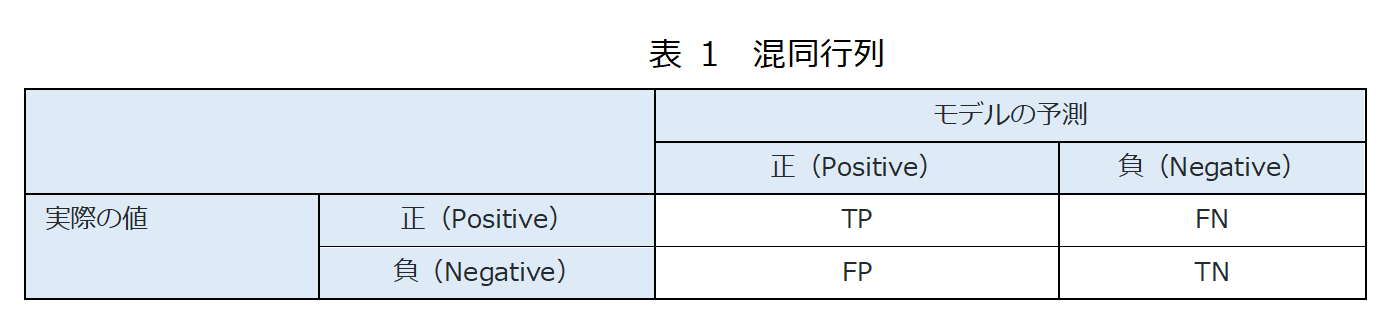
この混同行列を使って、以下のような指標を算出し、モデルを評価します。
- 正解率:すべての事象の中で予測が正解していた割合
正解率 = \frac {TP + TN}{TP + FP + FN + TN}
- 適合率(Precision):正と予測した中で実際に正であった割合(上記表の1列目)
Precision = \frac{TP}{TP + FP}
- 再現率(Recall): 実際に正であるものの中で、正と予測できた割合(上記表の1行目)
Recall = \frac{TP}{TP + FN}
- F値: 適合率と再現率を調和平均
F値 = \frac{2×(適合率×再現率)}{適合率\;\;\;\;+\;\;\;再現率\;\;}
(2) 物体検出の評価指標について
次に一般的な物体検出の評価指標について説明します。物体検出では、クラスの分類結果に加えて物体領域の検出結果を含めた評価を行う必要があります。
ⅰ) 検出したBBoxの評価
検出したBBoxと正解のBBoxとの一致度をIoU(Intersection over Union)と呼ばれる指標を用いて評価します。IoUは以下のように算出し、重なり度合いを0~1の間の数値で表現します。閾値を設定し、検出が有効か(TP)か、そうでないか(FP)を判断します(閾値以上が有効)。
ⅱ) AP・mAPの算出
APは、PR曲線で描かれた下側の面積として算出するのが一般的な方法です。PR曲線は、信頼度が高い順にサンプル数を増やしながら、複数の適合率と再現率を算出し、縦軸を適合率、横軸を再現率としてプロットすることで作成します。
また、mAPはAPの全クラス平均として算出します。
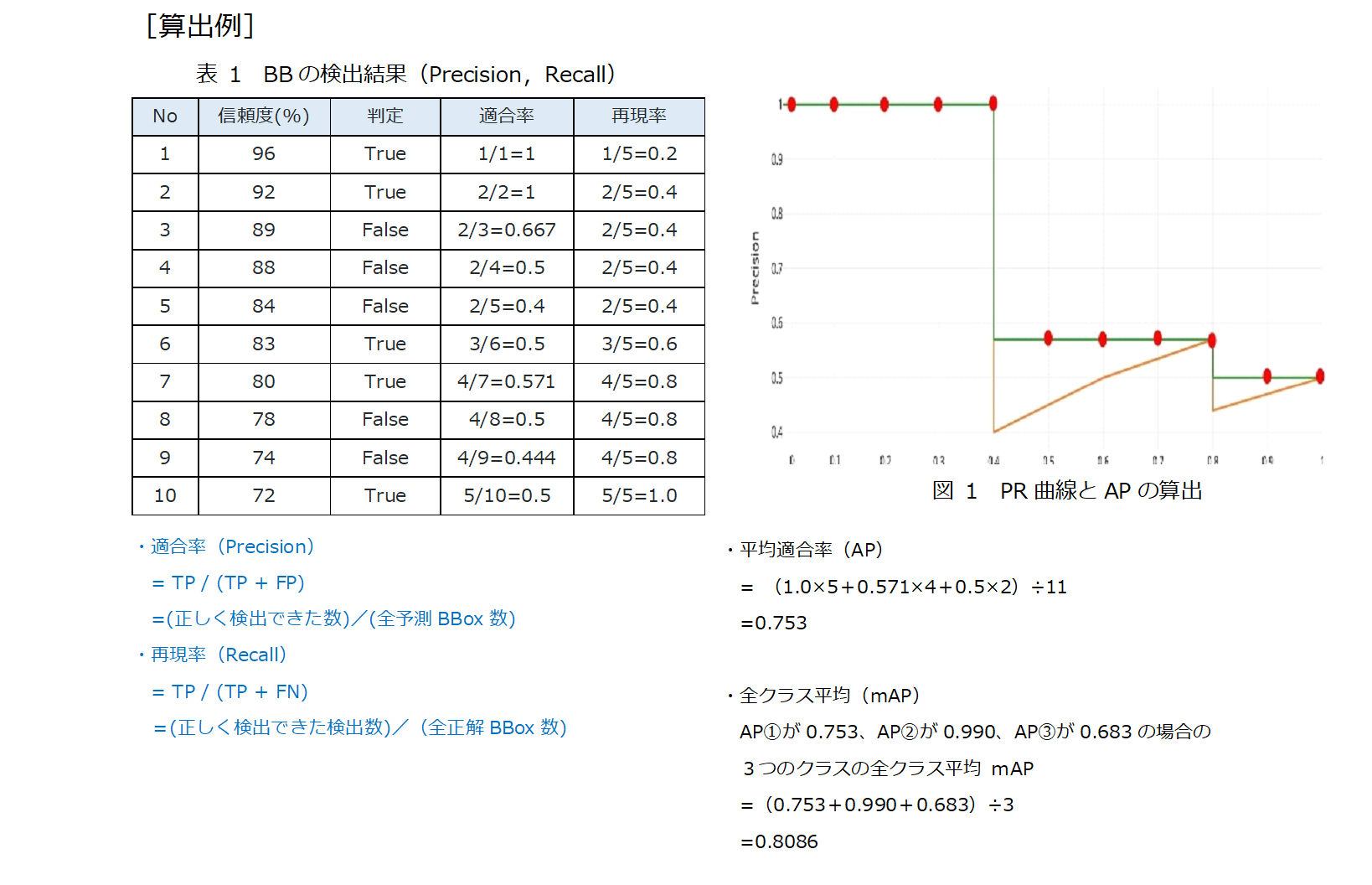
出展元)【物体検出】mAP ( mean Average Precision ) の算出方法
3.物体検出モデルの種類
物体検出モデルは分類モデルとして検出を行うモデルと、回帰モデルとして検出を行うモデルとがあります。分類モデルとしては、R-CNN、SPP-net、FAST R-CNN、Faster R-CNNがありますが、これらの手法は「最初に物体候補が生成」され、次に「これらの候補を分類/回帰に送る」というパイプラインを構築することで分類問題として扱っています(詳細はそれぞれの論文や関連記事を参照ください)。
一方回帰問題として扱うモデルはいくつかありますが、最も代表的なものに「YOLO」と今回説明する「SSD」があります。
以降、SSD(Single Shot multibox Detector)について説明をします。
4.SSDについて
SSDは、様々な階層の出力層からマルチスケールな検出枠を出力できるよう設計されています。
モデルアーキテクチャは以下の通りです。
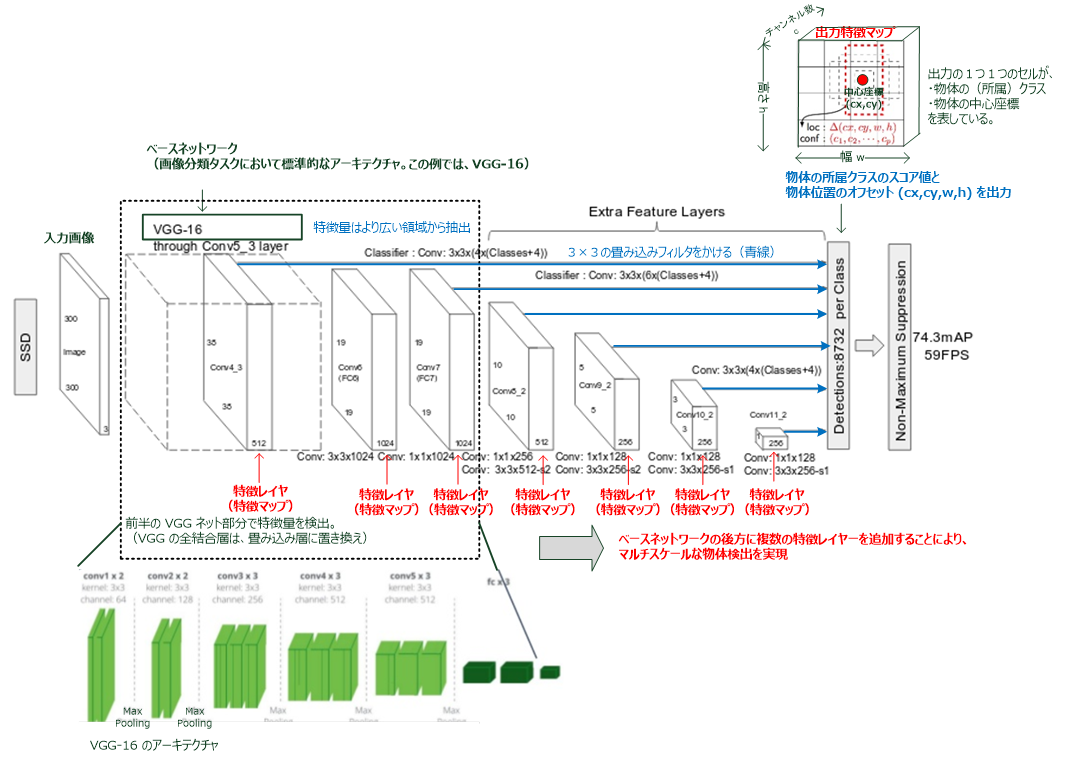
- SSD の基本的なアーキテクチャは、上図のように、フィードフォワード型(順方向)の多層 CNN をベースに構成されています。
- ネットワークの最初の部分のレイヤーは、画像分類に使用される標準的なアーキテクチャ(上図では VGG-16)に基づいて構成されており、これをベースネットワークといいます。
このベースネットワークで、特徴量を検出します(特徴量はより広い領域から抽出)。 - その後のレイヤーは、マルチスケール特徴マップによる多様な物体検出のための補助的な構造です。
[補足] 畳み込み層の出力「Detections 8732 per Class」について
「8732」はデフォルトモデルでのバウンディングボックスの数を示しています。上図の通り、300×300の元画像を38×38、19×19、10×10、5×5、3×3、1×1に均等に分け、それぞれ4個または6個のデフォルトボックスを生成します。具体的には以下の計算式で算出できます(’_’はその層で生成するバウンディングボックスの数)。1枚の画像から8,732のバウンディングボックスでクラス判定を行うことになります。
(38×38×4)+(19×19×6)+(10×10×6)+(5×5×6)+(3×3×4)+(1×1×4)= 8,732
5.SSDの物体検出の概要について
①それぞれの層のデフォルトボックス(4~6個)ごとに、「Offset情報(自身が物体からどのくらい離れていてどのくらい大きさが異なるのか)、および、クラス情報」を予測します。
②①でクラス毎にスコアの高いデフォルトボックスを選択します。
③②で選択したデフォルトボックスを予測値をもとにバウンディングボックスを確定します。
④クラス毎に重なり率(IoU)を算出し、IoUが高い場合はスコアが低いデフォルトボックスを除します。
- top-k filtering:クラス所属の確信度が上位 k 個のもののみを抽出します。
- non-maximum suppression アルゴリズム:推論されたデータに対し、バウンディングボックスの重複防止のために non-maximum suppression アルゴリズムを適用します。

以降、特徴について詳細に説明します。
(A)基本コンセプト
「多層CNNでは、conv層やpooling層で、特徴マップがダウンサンプリングされて、後段に行くほど、特徴マップのグリッドサイズが小さくなります。これにより、各々の層の特徴マップで、色々なサイズの物体を検出出来る情報が含まれていることを意味しています。
従って、SSDモデルの後段の特徴マップ(特徴レイヤー)の各グリッドでは大きな物体の情報を、前段では、小さな物体の情報を取得することが出来ます。そして、各グリッドにおける特徴量を使用して、バウンディングボックス(BBox)のアスペクト比、所属クラス、座標のオフセットを学習させる。」というのが、基本的なコンセプトです。
(B)検出のためのマルチスケール特徴マップ
畳み込み特徴レイヤーを、(途中で打ち切られている)ベースネットワークの最後尾に追加しています。これらのレイヤーは、特徴マップのサイズを小さくさせ(上図5)、マルチスケールでの検出の予想を可能にします。(下図7)

(C)検出のための、畳み込み予想器
ベースネットワークの後尾に追加された各特徴レイヤーは、畳み込みフィルタ(フィルタ行列)の集合を使用して、固定の検出予想の集合を生成可能です。 p 個のチャンネルをもつサイズ m×n の特徴レイヤーに対しての、潜在的なパラメータ予想のための基本要素は、3×3×p の小さなカーネル(カーネル行列)であり、このカーネルは、予想カテゴリ(所属クラス)の 検出スコア(物体の中心座標が含まれているなら1となるようなスコア)、または、デフォルトボックスの座標に関してのオフセット値を生成(算出)します。
また、バウンディングボックスの座標オフセットの出力値は、各特徴マップの位置に対するデフォルトボックスの位置に対して測定されます。
SSD モデルは、(前述のように)いくつかの特徴レイヤーを、ベースネットワークの最後に追加しますが、これらの特徴レイヤーは、異なるスケールとアスペクト比のデフォルトボックスに対するオフセット値と、それに付随する確信度を予測します。
(D)デフォルトボックスとアスペクト比(デフォルトボックスと回帰によるオフセット予想)
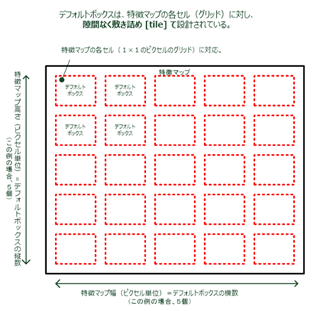
ネットワークのトップで、複数の特徴マップに関して、各特徴マップのセル(グリッド)とデフォルトボックスの集合を関連付けています。
その対応するセル(グリッド)に対して、各デフォルトボックスの位置が固定されるように、デフォルトボックスは、畳み込みのやり方で、特徴マップを隙間なく敷き詰め [tile] ています。(下図8参照)
その結果、特徴マップに適用されるフィルタは、合計 (c + 4)×k 個となり、m × n の特徴マップに対して、(c + 4)×k×mn 個の出力が生成されることになります。
幾つかの特徴マップで、異なるデフォルトボックスの形状を利用することにより、出力されるボックス(出力特徴マップ)の形状を、効率よく離散化 [discretize] することが出来ます。
(E)デフォルトボックスとアスペクト比の選択(デフォルトボックスと回帰によるオフセット予想)の詳細
異なるスケールの物体検出を取り扱うために、元画像を異なるサイズで処理し、それらの結果を結合する手法を提案している研究も存在します。
しかしながら、このSSDのように、単一のネットワークの中の幾つかの異なるレイヤーの特徴マップを利用することで、全ての物体のスケールについて、同じパラメータを共有しながら、同様の効果を得ることが出来ます。(更に、こちらの手法では同一の単一のネットワークの使用するため、処理が軽くなるメリットがあります。)
また、先述のように特定の特徴マップが、特定のスケールの物体に対応するように学習させるために、デフォルトボックスを“敷き詰めて”設計されています。デフォルトボックスを中心とする提案領域は、物体のスケール値、中心座標、高さ、幅が合っていないことがあるため、スケール値、幅、高さ、中心座標に回帰する畳み込み層を追加しています(BBoxの形状回帰)。具体的には、今、m 個の特徴マップを予想に使用するケースにおいて、各特徴マップ k についてのデフォルトボックスのスケール は、以下のようにして計算されます。
s_k=s_{min}+\frac{s_{max}-s_{min}}{m-1}\times (k-1), \hspace{20pt}(k \in [1,m])
- k:各特長マップのインデックス(k=1:最下位のレイヤー。k=m:最上位のレイヤー)
- $ s_{min}=0.2,s_{max}=0.9 $ ⇒最下位のレイヤー(k=1)は0.2のスケール。最上位のレイヤー(k=m)は0.9のスケール
この式より、最下位のレイヤーのスケール 0.2 と最上位のレイヤーのスケールは 0.9 となり、中間レイヤーのスケールは、上式に従って規則的な間隔で設定されます。
また、デフォルトボックスのアスペクト比に関しては、ar = {1, 2, 3, 1/2, 1/3 } の異なるアスペクト比を設定します。
このスケールとアスペクト比により、各デフォルトボックスに対して、幅 Wk(a) = sk√arと、高さ hk(a) = sk / √ar が設定されます。
(F)特徴マップとデフォルトボックスについて
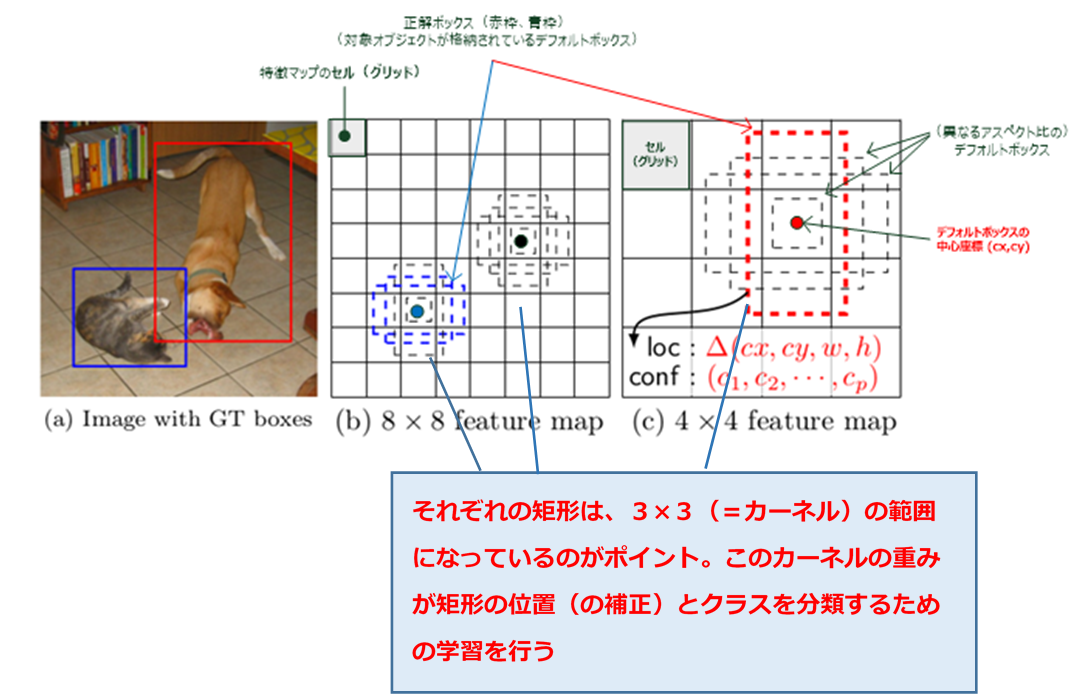
- SSD が訓練中に必要とするのは、入力画像(図5の(a))と、各物体それぞれの正解ボックス(デフォルトボックスの内、各物体が収まるボックス。上図の赤枠と青枠)のみです。
- 各層での畳み込み処理のやり方 [in a convolutional fashion] において、いくつかの特徴マップでの各位置(中心座標)において、異なるアスペクト比デフォルトボックスの少数の集合(上記例では4個)を、異なるスケールの特徴マップ内(例えば、上記の (b) の 8×8 の特徴マップ内、(c) の4×4の特徴マップ内)で評価します。
- そして、これらのデフォルトボックスそれぞれにおいて、形状のオフセットloc :(cx, cy, w, h) と、全ての物体カテゴリー (c1, c2, ..., cp) に関する確信度 confを予測します。
※w : デフォルトボックスの幅、h : デフォルトの高さ、cx,cy : デフォルトボックスの中心座標 - 訓練時には、最初にこれらのデフォルトボックスと正解 [ground truth] ボックスのマッチ度を図ります。上図の例では、2つのデフォルトボックスの内、1つ目はネコ、2つ目はイヌとマッチさせていますが、この組み合わせは正 [positive] として扱われ、残りは負 [negative] として扱われます。
- モデルの誤差(損失関数)は、
位置特定誤差 [localization loss] (例えば、Smooth L1)と、確信度誤差 [confidence loss] (例えば、softmax)との間の重み付き和 [weighted sum] です。
6.訓練(学習)アルゴリズム
(a)マッチング戦略
訓練では、どのデフォルトボックスが正解ボックスとなるのか決定する必要があり、その結果を元にネットワークを学習させます。
各正解ボックスは、座標位置、アスペクト比、スケール値が異なる幾つかのデフォルトボックスから選択しますが、これらデフォルトボックスに対して、jaccard overlap の最良値(最もエリアが正解と重複している)で、各正解ボックスのマッチ度(エリアの重複度)を算出することになります。
この際、ベストマッチした(最もエリアが重複している)デフォルトボックスだけでなく、jaccard overlap が 0.5 の値よりも大きいデフォルトボックスを正解ボックスと判定させ、学習させます。
これにより、正解ボックスに複数に重なり合っているデフォルトボックスについて、高いスコア予想が可能になります。
(b)「損失関数」
SSD の損失関数は、位置特定誤差(loc)と確信度誤差(conf)の重み付き和であり、(SSD の学習は、複数の物体カテゴリーを扱うことを考慮して行われるため2つの線形和をとる。)以下の式で与えられます。

ただし、N = 0 の場合(一致するデフォルト)は、loss値を0とする
・l:予想あれたボックス
・g:正解ボックス
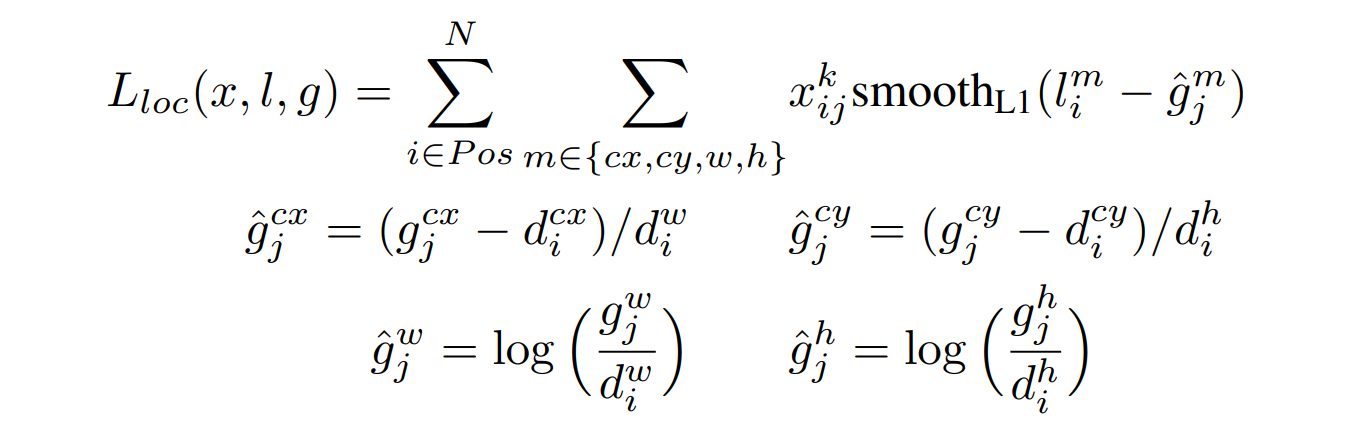
※Smooth L1 誤差(関数)
smooth_{L1}(x) =\left\{
\begin{array}{ll}
0.5x^2 & if \; |x| < 1 \\
|x|-0.5 & otherwise,
\end{array}
\right.
又、確信度誤差 Lconf は、所属クラスのカテゴリ(c)に対する softmax cross entropy 誤差(関数)であり、以下の式で与えられます。
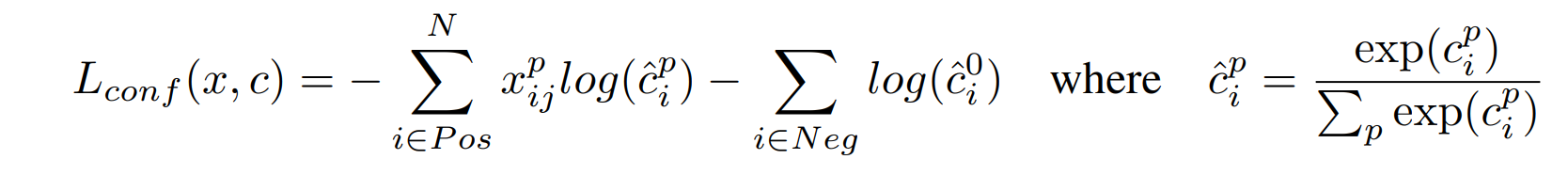
(c)ハードネガティブマイニング [hard negative mining]
マッチング工程の後、有効なデフォルトボックスの数が多い場合多くのデフォルトボックスは、負 [negative] に判定され、正と負の訓練データの比率が不均衡になってしまいます。
(=典型的な画像の多くの面積は、背景によって占められますが、これを有効なデフォルトボックスとして採用すると、背景しか出力しないネットワークでも、ある程度 loss 値を下げることが出来てしまい、結果として検出能力の低いモデルになってしまいます。)
この問題に対する対策として、負に判定される全訓練データを使用する代わりに、これらの(訓練データとしての) デフォルトボックスに対しての誤差関数が高い順(降順)にソートし、負と正の比率が、最大でも3:1になるように、誤差関数の値が上位のもののみを選択します。
これにより、より速くモデルが最適化され、又、安定した学習に繋がります。
(d)データ拡張 [data augumentation]
モデルを様々な物体の大きさと形状に対して、よりロバスト(堅牢)にするために、各訓練画像は、以下のオプションをランダムに選択し、(画像中の領域の)サンプリングを行います。
- 元の入力画像全体を使用する。
- 物体画像との最小の jaccard overlap が、0.1 , 0.3 , 0.5 , 0.7 , 0.9 となるように、画像中の領域(サンプルパッチ)をサンプリングする。
- 画像中の領域(サンプルパッチ)をランダムにサンプリングする。
この各画像中の領域(サンプルパッチ)のサイズは、元の画像サイズの 0.1倍 ~ 1.0倍で、アスペクト比は 1/2 ~ 1.0 倍です。
但し、サンプルパッチの中に正解ボックスの中心座標が存在する場合は、正解ボックスの重複部分はそのままにします(サイズやアスペクト比を元の画像から変更しない)。
7.おわりに
以上が物体検出・SSDの基礎になります。
更に詳しく知りたい方に向けてSSDのコードの解説記事を掲載していますので興味があればご覧ください。
関連する物体検出モデルとして、分類モデルとして物体検出を行うFaster R-CNNや、最近話題になっているTransformerを使った物体検出モデルであるDETR(DEtection TRnsformer)についても執筆しておりますのでよろしかったら参考にしてください。