はじめに
NII(国立情報学研究所)が開発した130億パラメータの日本語LLMをGoogleコラボ上でRAG(LlamaIndex)が使えるのか、検証してみました。
LLM-jpは、1750億の完全オープンで商用利用可能な日本語LLMのリリースも予定されており、今後の動向に注目です。
LLM-jp趣旨(興奮しますね😋)
検証環境
130億パラメータのモデルを動かすため、Googleコラボ Pro+ で A100 環境を使用しました。
検証手順
以下に順を追って説明します。
パッケージのインストールとログレベルの設定
# パッケージのインストール
!pip install transformers sentencepiece accelerate
!pip install llama-index==0.8.0
!pip install transformers accelerate bitsandbytes
!pip install sentence_transformers
!pip install langchain
# ログレベルの設定
import logging
import sys
# ログレベルの設定 デバック時は level=logging.DEBUG に設定する
logging.basicConfig(stream=sys.stdout, level=logging.INFO, force=True)
パッケージのインストールとログレベルの設定
# ログレベルの設定
import logging
import sys
# ログレベルの設定 デバック時は level=logging.DEBUG に設定する
logging.basicConfig(stream=sys.stdout, level=logging.INFO, force=True)
トークナイザーとモデルの準備
今回は、llm-jp-13b-instruct-full-jaster-v1.0 を使用します.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
#
tokenizer = AutoTokenizer.from_pretrained(
"llm-jp/llm-jp-13b-instruct-full-jaster-v1.0",
)
model = AutoModelForCausalLM.from_pretrained(
"llm-jp/llm-jp-13b-instruct-full-jaster-v1.0",
torch_dtype=torch.float16,
device_map="auto",
)
パイプラインとLLMの準備
from transformers import pipeline
from langchain.llms import HuggingFacePipeline
# パイプラインの準備
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=256
)
埋め込みモデルの準備
# 埋め込みモデルの準備
from langchain.embeddings import HuggingFaceEmbeddings
from llama_index import LangchainEmbedding
from typing import Any, List
# 埋め込みクラスにqueryを付加
class HuggingFaceQueryEmbeddings(HuggingFaceEmbeddings):
def __init__(self, **kwargs: Any):
super().__init__(**kwargs)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return super().embed_documents(["query: " + text for text in texts])
def embed_query(self, text: str) -> List[float]:
return super().embed_query("query: " + text)
# 埋め込みモデルの準備
embed_model = LangchainEmbedding(
HuggingFaceQueryEmbeddings(model_name="intfloat/multilingual-e5-large")
)
サービスコンテキストの準備
# サービスコンテキストの準備
# チャンクサイズを512、段落セパレータを"。"
from llama_index import ServiceContext
from llama_index.text_splitter import SentenceSplitter, TokenTextSplitter
from llama_index.node_parser import SimpleNodeParser
import tiktoken
# ノードパーサーの準備
text_splitter = TokenTextSplitter(separator="。 ", chunk_size=512
, chunk_overlap=100
, tokenizer=tiktoken.get_encoding("cl100k_base").encode)
node_parser = SimpleNodeParser(text_splitter=text_splitter)
# サービスコンテキストの準備
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
node_parser=node_parser,
)
RAG(LlamaIndex)にデータを読ませる
今回は、ポケモンwikiのポケモン一覧をテキスト化して、DataSourceとして与えてみます。
作成したテキストをGoogleコラボに適当なフォルダを作ってアップロードします。
(例 /content/sample_data/data)
ドキュメントの読み込みとインデックスの作成

from llama_index import SimpleDirectoryReader
# ドキュメントの読み込み
# それぞれの環境に応じてディレクトリを設定、今回は /content/sample_data/data にDataSoutceを配置
documents = SimpleDirectoryReader(
input_dir="/content/sample_data/data"
).load_data()
from llama_index import VectorStoreIndex
# インデックスの作成
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context,
)
クエリーテンプレートの準備
from llama_index.prompts.prompts import QuestionAnswerPrompt
# QAテンプレートの準備
qa_template = QuestionAnswerPrompt("""以下の文脈を使って、最後にある質問に答えてください。もし答えがわからない場合は、答えがわからないと言ってください。答えをでっちあげようとしないでください。
{context_str}
質問: {query_str}
お役立ち回答:""")
これで、準備完了です。
下記がクエリー実行のイメージです。
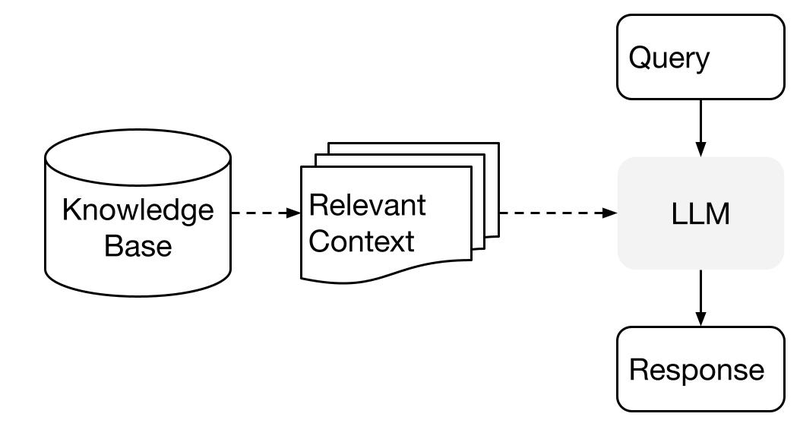
では、早速RAGを使わない場合と、RAGを使った場合の回答結果を見比べてみましょう。
RAGを使わない場合
text = "ポケモンのピカチュウはどんなタイプのポケモンですか?"
text = text + "### 回答:"
tokenized_input = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(
tokenized_input,
max_new_tokens=100,
do_sample=True,
top_p=0.95,
temperature=0.7,
)[0]
print(tokenizer.decode(output))
[結果]
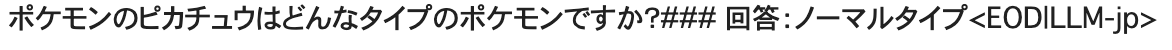
あら、、、「 ノーマルタイプ 」?
RAG(LlamaIndex)を使った場合
# LLMへの問い合わせ
# この時indexを参照し、問い合わせに近い情報(チャンク)を取得し、それをプロンプトに組み込む
# 幾つのチャンクを組み込むのかをtop_kで指定する(今回は1)
query_engine = index.as_query_engine(
similarity_top_k=1,
text_qa_template=qa_template,
)
query = "ポケモンのピカチュウはどんなタイプのポケモンですか?"
response = query_engine.query(query)
print(response)
[結果]

正しく、「でんき」と返せました!😄
(参考)リソース表示
参考までにGoogleコラボのリソース使用状況を添付します。
13Bモデルといえどもローカルで動かすとなるとA100でないと厳しそうですね。

おわりに
LLM-jpの175BがリリースされRAGと組み合わせることで、どこまでGPT-4に近づけることができるのか楽しみです。
LLM-jpは出力からコーパス検索し、回答の元となった文章も表示できるみたいです。
この辺りの機能も追々検証してみたいと思います。