本書は、numpyチュートリアル(ビギナーズ向け) を翻訳及び加筆(※)でしたものです。
※わかりにくいと思われる箇所の補足や、ipythonでコードが実行できるようにテストデータを作成するコードの追加等を実施しています
本コードを動かしながら学べるようにコードをGithubに公開しました(2022年1月)。
ご活用ください。
同様にPythonのチュートリアルを動かしながら学習できるようにGithubに公開しました。
https://qiita.com/DeepTama/items/4bf9e3139471918eb0fe

© Copyright 2008-2021, The NumPy community.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
筆者が所属するNPO法人の勉強用にメモしたものですので、誤りや不足、加筆修正すべきことろがありましたらご指摘ください。継続してブラッシュアップしていきます。
pandasのチュートリアルの翻訳も実施しています。合わせてご参照ください。
@2021 NPO法人AI開発推進協会
NumPyへようこそ!
NumPy (Numerical Python) は、科学や工学のほぼすべての分野で使用されているオープンソースの Python ライブラリです。これは Python で数値データを扱うための普遍的な標準であり、科学的な Python と PyData のエコシステムの中核をなしています。NumPyのユーザーは、初心者のコーダーから、最先端の科学や産業の研究開発を行っている経験豊富な研究者まで、誰もが参加しています。NumPy APIは
Pandas、SciPy、Matplotlib、scikit-learn、scikit-image、その他ほとんどのデータサイエンスや科学的Pythonパッケージで幅広く使用されています。
NumPyライブラリには多次元配列と行列データ構造が含まれています(これについては後のセクションで詳しく説明します)。均質な n 次元配列オブジェクトである ndarray と、その上で効率的に操作するためのメソッドを提供します。NumPy は配列に対する様々な数学的操作を行うために使用できます。 配列や行列を使った効率的な計算を保証する強力なデータ構造をPythonに追加し、これらの配列や行列を操作する高レベルの数学関数の膨大なライブラリを提供します。
NumPyについての詳細はこちら!
NumPyのインストール
NumPyをインストールするには、科学的向けPythonディストリビューションを使うことを強くお勧めします。お使いのオペレーティングシステムにNumPyをインストールするための完全な手順をお探しの場合は、ここですべての詳細を見つけることができます。
すでにPythonをお持ちの方は、下記のコマンドを使ってNumPyをインストールしておきましょう。
conda install numpy
or
pip install numpy
もしあなたがまだ Python を持っていないのであれば、Anaconda の使用を検討してみてはいかがでしょうか。これが一番簡単に始められる方法です。このディストリビューションの良いところは、NumPy や pandas, Scikit-Learn などのようなデータ解析に使用する主要なパッケージを別途インストールする必要がないことです。
インストールの詳細はSciPyのInstallationセクション
にあります。
NumPyのインポート方法
パッケージやライブラリをコードの中で使いたいときはいつでも、まずそれにアクセスできるようにする必要があります。
NumPy と NumPy で利用できるすべての関数を使い始めるには、NumPy をインポートする必要があります。これは、インポート文で簡単にできます。
import numpy as np
[補足] ipythonで学習する際の操作に対する補足
- ipythonで学習する際(途中からの再開を含む)は、以下のimport文を毎回実施してください。
- テキスト部分は「↓」ボタンでスクロール、各コマンドラインは「shift]+「retutn」キーで順番に実行してください。
- テキスト画面を編集で開いた場合は「shift]+「retutn」で閉じてください。
- 誤ってテキストを編集した場合は、「Ctrl」+「z」で取り消すことができます。
- 追加で動作確認したい場合は任意の場所でセル(メニューバーのInsert(挿入))を追加して試してください。
numpy を np と短縮することで時間を節約し、そしてまたコードを標準化しておくことで、あなたのコードを使って作業している誰もが簡単に理解して実行できるようにしています。
コード例の読みかた
多くのコードを含むチュートリアルを読むことにまだ慣れていない場合、このようなコードブロックをどのように解釈すればいいのかわからないかもしれません。
a = np.arange(6)
a2 = a[np.newaxis, :]
a2.shape
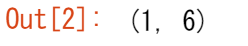
このスタイルに慣れていない人でも、とてもわかりやすいと思います。
もし >>> が見えていたら、あなたは入力、つまりあなたが入力するコードを見ていることになります。前に >>> がないものはすべて出力、つまりコードを実行した結果です。これはpythonをコマンドラインで実行しているときに表示されるスタイルですが、IPythonを使っている場合は違うスタイルが表示されるかもしれません。
[補足]IPythonを使う場合、入力欄には In [ ] または In[n] 、出力欄は Out[n] が左端に表示されます(nは実行順を示す数字です)。
PythonのリストとNumPyの配列の違いなんですか?
NumPyは、配列を作成したり、その中の数値データを操作したりするための高速かつ効率的な方法を提供してくれます。Pythonのリストは1つのリスト内に異なるデータ型を含むことができますが、NumPyの配列内のすべての要素は同種でなければなりません。もし配列が同種でなければ、配列上で実行されることを意図した数学的な操作は非常に非効率的です。
なぜNumPyを使うのか?
NumPyの配列はPythonのリストよりも高速でコンパクトです。配列はメモリ消費量が少なくて便利です。NumPyはデータを格納するのに使用するメモリがかなり少なく、データ型を指定する仕組みを提供しています。これにより、コードをさらに最適化することができます。
配列とは何ですか?
配列はNumPyライブラリの中心的なデータ構造です。配列は値のグリッドであり、生データに関する情報、要素の探し方、要素の解釈方法などが含まれています。要素のグリッドを持ち、様々な方法でインデックスを作成することができます。要素はすべて同じ型で、配列のdtypeと表されます。
配列は,非負の整数のタプル,ブーリアン,別の配列,または整数によってインデックスを作成することができます。配列のランク(rank)は,次元数です。配列の形状(shape)は,各次元に沿った配列のサイズを与える整数のタプルです。
NumPyの配列を初期化する方法の1つとしてPythonのリストを使います。2次元以上のデータは入れ子になったリストを使います。
例えば,以下のようになります。
a = np.array([1, 2, 3, 4, 5, 6])
or
a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
配列の要素には角括弧を使ってアクセスします。要素にアクセスするときは、NumPyのインデックスは0から始まることを覚えておいてください。 つまり、配列の最初の要素にアクセスしたい場合は、要素 "0 "にアクセスすることになります。
print(a[0])
配列の詳細情報
1次元配列、2次元配列、ndarray、ベクトル、行列について説明します。
たまに「NDARRAY」と呼ばれる配列を耳にすることがありますが、これは「N次元配列」の略語です。N次元配列とは、単純に任意の次元数の配列のことです。1-D、1次元配列, 2-D, 2次元配列などと呼ばれることもあります。NumPyのndarrayクラスは、行列とベクトルの両方を表現するのに使われます。ベクトルは1次元の配列(行ベクトルと列ベクトルの違いはありません)であり,行列は2次元の配列を指します。3次元またはそれ以上の次元の配列では,テンソルという用語もよく使われます。
[補足]ベクトル(1次元の配列)は1次元テンソル、行列(2次元の配列)は2次元テンソルとも表現されます。
配列の属性とは何ですか?
配列とは、通常、同じ種類&サイズの項目の固定サイズの容器です。配列の次元と項目の数は、その形状によって定義されます。配列の形状は、各次元のサイズを指定する非負の整数のタプルです。
NumPyでは、次元は軸(axis)と呼ばれます。つまり、次のような2次元配列があれば、以下のようになります。
[[0., 0., 0.],
[1., 1., 1.]]
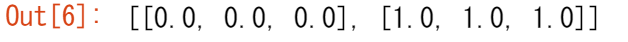
この配列には2つの軸があります。1つ目の軸の長さは2、2つ目の軸の長さは3です。
他のPythonコンテナオブジェクトと同様に、配列の内容はインデックスを作成したりスライスしたりすることでアクセスしたり変更したりすることができます。典型的なコンテナオブジェクトとは異なり、異なる配列は同じデータを共有することができるので、ある配列で行われた変更は別の配列でも見ることができます。
配列の属性は、配列自体に内在する情報を反映しています。新しい配列を作成せずに配列のプロパティを取得したり設定したりする必要がある場合は、その属性を使用して配列にアクセスすることができます。
配列の属性についての詳細はこちらを、配列オブジェクトについてはこちらをご覧ください。
基本的な配列の作り方
ここでは,np.array(),np.zeros(),np.ones(),np.empty(),np.arange(),np.linspace(),dtypeを扱います.
NumPy配列を作成するには、関数np.array()を使用します。
単純な配列を作成するために必要なのは、リストを渡すだけです。必要に応じて、リストに含まれるデータの型を指定することもできます。データ型についての詳細はこちらをご覧ください。
import numpy as np
a = np.array([1, 2, 3])
このようにして配列を可視化することができます。

これらの可視化は,概念を単純化し,NumPyの概念と力学の基本的な理解を得るためのものであることに注意してください.配列や配列操作はここで紹介したものよりもはるかに複雑です。
要素の並びから配列を作成する以外にも、0で埋め尽くされた配列を簡単に作成することができます。
np.zeros(2)
または、1を埋めた配列を作成することもできます。
np.ones(2)
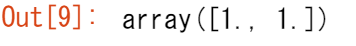
空の配列でも良いのです! 関数 empty は、最初の内容がランダムでメモリの状態に依存する配列を作成します。ゼロよりも空の配列を使う理由は、速度を上げるためです。
ただ、後ですべての要素を必ず埋めてください。
# Create an empty array with 2 elements
np.empty(2)

[補足]この出力はメモリの状態に依存するため一定ではありません
要素の範囲で配列を作成することができます。
np.arange(4)
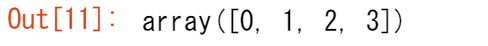
さらには、等間隔の範囲を含む配列も作成できます。これを行うには、最初の番号、最後の番号、間隔を指定します。
[補足]最後の番号(n)は含まず、n-1までになります
np.arange(2, 9, 2) #[補足]2から8(9-1)まで間隔2で作成
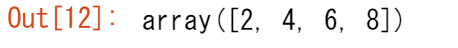
np.linspace() を使用して、指定した間隔で直線的に間隔を置いた値を持つ配列を作成することもできます。
[補足]linspace()では、最後の番号(n)を含みます
np.linspace(0, 10, num=5)

データタイプの指定
既定のデータ型は浮動小数点 (np.float64) ですが、dtype キーワードを使用して、どのデータ型を使用するかを明示的に指定できます。
x = np.ones(2, dtype=np.int64)
x
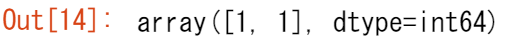
配列の作成についての詳細はこちらを参照してください。
要素の追加、削除、ソート
このセクションでは、np.sort()、np.concatenate()について説明します。
要素のソートはnp.sort()で簡単にできます。関数を呼び出すときに軸、種類、順序を指定できます。
下記の配列で始めると、
arr = np.array([2, 1, 5, 3, 7, 4, 6, 8])
こうして昇順に素早く並び替えることができます。
np.sort(arr)
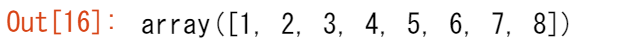
配列のソートされたコピーを返す sort に加えて、次のようなものが使えます。
-
argsort 、指定した軸に沿った間接的なソートです。
-
lexsort、複数のキーに対して間接的に安定したソートを行う 。
-
searchsorted 、ソートされた配列の要素を見つけます。
-
partition、これは部分的なソートです。
配列のソートについての詳細は、 sort を参照してください。
下記のこれらの配列から始めると、
a = np.array([1, 2, 3, 4])
b = np.array([5, 6, 7, 8])
np.concatenate()で連結することができます。
np.concatenate((a, b))
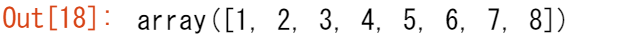
あるいは、これらの配列から始めると、
x = np.array([[1, 2], [3, 4]])
y = np.array([[5, 6]])
下記で連結ができます。
np.concatenate((x, y), axis=0)

配列から要素を削除するには、インデックスを使って保持したい要素を選択するのが簡単です。
連結についての詳細は concatenate を参照してください。
配列の形状やサイズを知るにはどうすればいいのでしょうか?
このセクションでは、ndarray.ndim、ndarray.size、ndarray.shapeを扱います。
ndarray.ndim は配列の軸数、つまり次元を教えてくれます。
ndarray.size は配列の要素の総数を示します。これは配列の形状の要素の積です。
ndarray.shape は、配列の各次元に沿って格納されている要素の数を示す整数のタプルを表示します。例えば、2行3列の2次元配列を作成した場合、配列の形状は(2, 3)となります。
例えば、以下のような配列を作成したとします。
array_example = np.array([[[0, 1, 2, 3],
[4, 5, 6, 7]],
[[0, 1, 2, 3],
[4, 5, 6, 7]],
[[0 ,1 ,2, 3],
[4, 5, 6, 7]]])
配列の次元数を調べるには、次のように実行します。
array_example.ndim

配列の総要素数を求めるには,次のように実行します。
array_example.size

そして,配列の形状を求めるには,次のように実行します。
array_example.shape
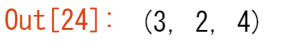
配列のリシェイプはできますか?
この節では arr.reshape() を扱います。
できます!
arr.reshape() を使用すると、データを変更することなく配列に新しい形を与えることができます。ただ、reshape メソッドを使用する際には、生成したい配列の要素数が元の配列と同じである必要があることを覚えておいてください。12 個の要素を持つ配列から始めた場合、新しい配列も合計 12 個の要素を持つようにしなければなりません。
以下の配列で始めた場合、
a = np.arange(6)
print(a)
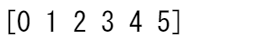
reshape() を使用して、配列の形状を変更することができます。たとえば、この配列を 3 行 2 列の配列にリシェイプすることができます。
b = a.reshape(3, 2)
print(b)

np.reshapeでは、いくつかのオプションのパラメータを指定することができます。
np.reshape(a, newshape=(1, 6), order='C')
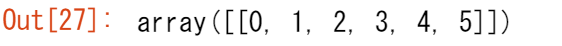
a はリシェイプされる配列です。
newshape:新しい形状を指定します。整数か整数のタプルを指定することができます。整数を指定した場合、結果はその長さの配列になります。形状は元の形状と互換性のあるものでなければなりません。
order:C は C ライクなインデックス順で要素を読み書きすることを意味し、F は Fortran ライクなインデックス順で要素を読み書きすることを意味し、A は a がメモリ内で Fortran が連続している場合は Fortran ライクなインデックス順で要素を読み書きすることを意味し、そうでない場合は C ライクなインデックス順で要素を読み書きすることを意味します。(これはオプションのパラメータであり、指定する必要はありません)。
CとFortranの順序についてもっと知りたい場合は、ここでNumPy配列の内部組織についての詳細を読むことができます。基本的に、CとFortranの順序は、配列がメモリに格納されている順序にインデックスがどのように対応するかに関係しています。Fortranでは、メモリに格納されている2次元配列の要素を移動するとき、最初のインデックスが最も急速に変化するインデックスです。最初のインデックスが変化しながら次の行に移動すると、行列は1列ずつ格納されます。これがFortranがカラムメジャー言語として考えられている理由です。一方、C言語では、最後のインデックスが最も早く変化します。行列は行単位で格納されるので、行メジャー言語になります。CとFortranのどちらをどうするかは、インデックスの規則を守ることと、データの並び替えをしないことのどちらが重要かにかかっています。
形状操作についてはこちらをご覧ください。
1次元配列を2次元配列に変換する方法(配列に新しい軸を追加する方法)
ここでは、np.newaxis、np.expand_dimsを扱います。
np.newaxis と np.expand_dims を使用して、既存の配列の寸法を増やすことができます。
np.newaxisを使用すると、1回使用すると配列の次元が1次元増加します。これは、1次元配列が2次元配列になり、2次元配列が3次元配列になることを意味します。
例えば、以下の配列から始めた場合、
a = np.array([1, 2, 3, 4, 5, 6])
a.shape

np.newaxisを使用して新しい軸を追加することができます。
a2 = a[np.newaxis, :]
a2.shape
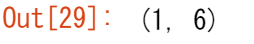
np.newaxis を使用して,明示的に 1 次元配列を行ベクトルまたは列ベクトルに変換することができます.例えば,1 次元に沿って軸を挿入することで,1 次元配列を行ベクトルに変換することができます。
row_vector = a[np.newaxis, :]
row_vector.shape
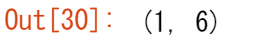
または、列ベクトルの場合は、2次元に沿って軸を挿入することができます。
col_vector = a[:, np.newaxis]
col_vector.shape
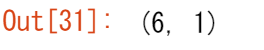
また、np.expand_dimsで指定した位置に新しい軸を挿入して配列を拡張することもできます。
例えば、以下ような配列から始めると、
a = np.array([1, 2, 3, 4, 5, 6])
a.shape

np.expand_dimsを使ってインデックス位置1に軸を追加することができます。
b = np.expand_dims(a, axis=1)
b.shape
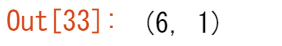
インデックス位置0に軸を追加することができます。
c = np.expand_dims(a, axis=0)
c.shape
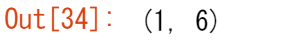
newaxisについての詳細はこちらを、expand_dimsについてはexpand_dimsを参照してください。
インデックスとスライス
Pythonのリストをスライスするのと同じように、NumPyの配列をインデックス化してスライスすることができます。
data = np.array([1, 2, 3])
data[1]

data[0:2]

data[1:]

data[-2:]

このように可視化することができます。

配列の一部や特定の配列要素を取り出して、さらなる分析や追加の操作に使用したい場合もあるでしょう。そのためには、配列のサブセット、スライス、インデックスを作成する必要があります。
配列から特定の条件を満たす値を選択したい場合は、NumPyを使えば簡単です。
例えば、次のような配列から始めると、
a = np.array([[1 , 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
配列内の5未満の値をすべて簡単に表示することができます。
print(a[a < 5])
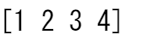
また、例えば5以上の数値を選択して、その条件を使って配列のインデックスを作成することもできます。
five_up = (a >= 5)
print(a[five_up])
# [補足] five_upはbooleanのインデックスになります
# [[False False False False]
# [ True True True True]
# [ True True True True]]
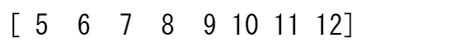
2で割り切れる要素を選択することができます。
divisible_by_2 = a[a%2==0]
print(divisible_by_2)
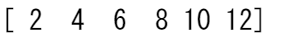
または、& 演算子と|演算子を使って2つの条件を満たす要素を選択することができます。
c = a[(a > 2) & (a < 11)]
print(c)
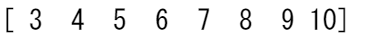
また、論理演算子 & や | を使用して、配列内の値が特定の条件を満たすかどうかを指定するブール値を返すこともできます。これは、名前やその他のカテゴリカルな値を含む配列で便利です。
five_up = (a > 5) | (a == 5)
print(five_up)

np.nonzero() を使用して、配列の要素やインデックスを選択することもできます。
下記の配列から始めて、
a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
np.nonzero()を使用して、例えば5未満の要素のインデックスを表示することができます。
b = np.nonzero(a < 5)
print(b)
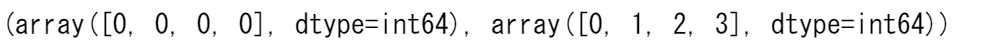
この例では、配列のタプルが返されました。
各次元に対して 1 つの配列が返されました。最初の配列は、これの値が見つかった行のインデックスを表し、2 番目の配列は、値が見つかった列のインデックスを表します。
要素が存在する座標のリストを生成したい場合は,zip関数を使用して配列のリストを繰り返し処理し,それを表示することができます。例えば、以下のようになります。
list_of_coordinates = list(zip(b[0], b[1]))
for coord in list_of_coordinates:
print(coord)
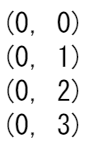
np.nonzero()を使用して、配列の要素が5未満のものを表示することもできます。
print(a[b])

探している要素が配列内に存在しない場合、返されるインデックスの配列は空となります。例えば、以下のようになります。
not_there = np.nonzero(a == 42)
print(not_there)
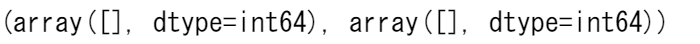
インデックス作成とスライスについては、こことここを参照してください。
nonzero 関数の使用についての詳細はnonzeroを参照してください。
既存のデータから配列を作成する方法
このセクションでは、スライスとインデックス作成、np.vstack()、np.hstack()、np.hsplit()、.view()、copy()を扱います。
既存の配列の一部から新しい配列を作成することが簡単にできます。
このような配列があるとしましょう。
a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
配列をスライスしたい場所を指定することで、いつでも配列の一部から新しい配列を作成することができます。
arr1 = a[3:8]
arr1
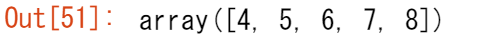
ここでは、インデックス位置3からインデックス位置8までの配列の部分を取得しています。
また、既存の2つの配列を縦にも横にも重ねることができます。2 つの配列 a1 と a2 があるとしましょう。
a1 = np.array([[1, 1],
[2, 2]])
a2 = np.array([[3, 3],
[4, 4]])
vstackで縦に積み上げることができます。
np.vstack((a1, a2))

または hstack で水平にスタックします。
np.hstack((a1, a2))
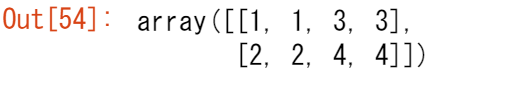
hsplit を使用して、配列をいくつかの小さな配列に分割することができます。返される配列の数や分割後の列を指定することができます。
次のような配列があるとしましょう。
x = np.arange(1, 25).reshape(2, 12)
x
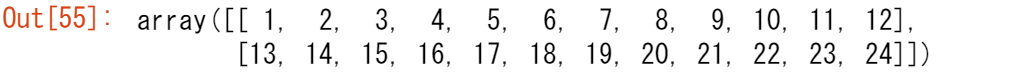
この配列を3つの均等な形の配列に分割したい場合は、以下のように実行します。
np.hsplit(x, 3)

3列目及び4列目で配列を分割する場合は、以下を実行します。
np.hsplit(x, (3, 4))

[補足]行方向に配列を分割するにはvsplit関数を使用します
配列のスタッキングと分割についてはこちらをご覧ください。
viewメソッドを使って、元の配列と同じデータを見る新しい配列オブジェクトを作成することができます(浅いコピー)。
[補足]浅いコピーではメモリ上は同一エリアを使います
ビューはNumPyの重要な概念です。 NumPyの関数は、インデックスやスライスなどの操作と同様に、可能な限りビューを返します。これはメモリの節約になり、そして高速です(データのコピーを作成する必要がありません)。しかし、注意しなければならないことがあります - ビュー内のデータを変更すると、元の配列も変更されてしまいます。
以下の配列を作成したとしましょう。
a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
ここで、aをスライスして配列b1を作成し、b1の最初の要素を修正します。これにより、aの対応する要素も変更されます!
b1 = a[0, :]
b1
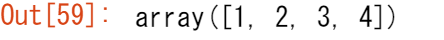
b1[0] = 99
b1
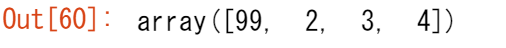
a

copy メソッドを使用すると、配列とそのデータの完全なコピーを作成します (深いコピー)。
[補足]深いコピーでは、(浅いコピーはメモリ上は同一であるのにくらべ)メモリ上も別エリアを確保してコピーします(=別エリア)
これを配列に使用するには、以下のように実行します。
b2 = a.copy()
コピーやビューについての詳細はこちらをご覧ください。
基本的な配列操作
足し算、引き算、掛け算、割り算などについて説明します。
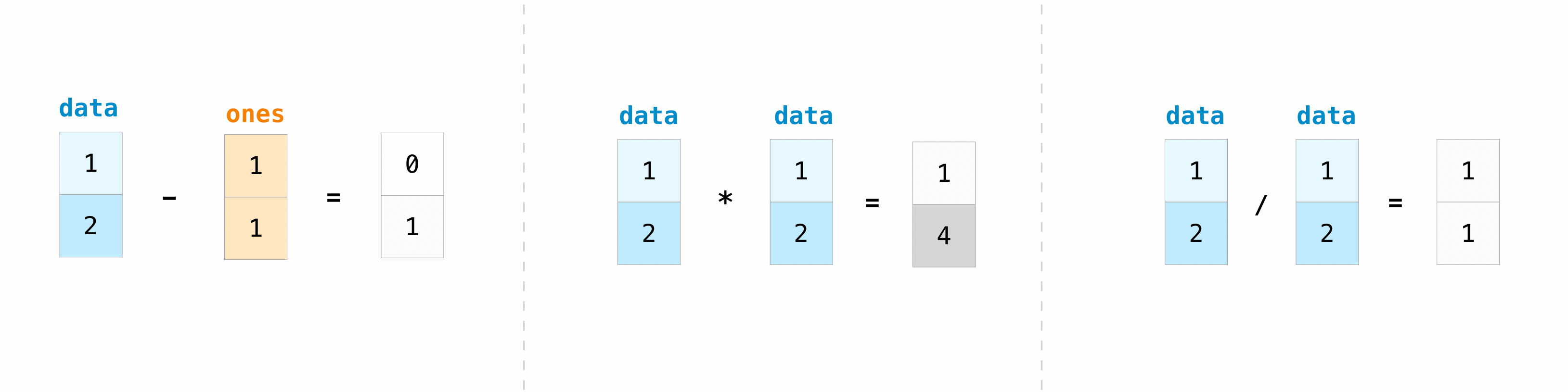
配列を作成したら、それを使って作業を始めることができます。例えば、"data" と "ones" という 2 つの配列を作成したとしましょう。
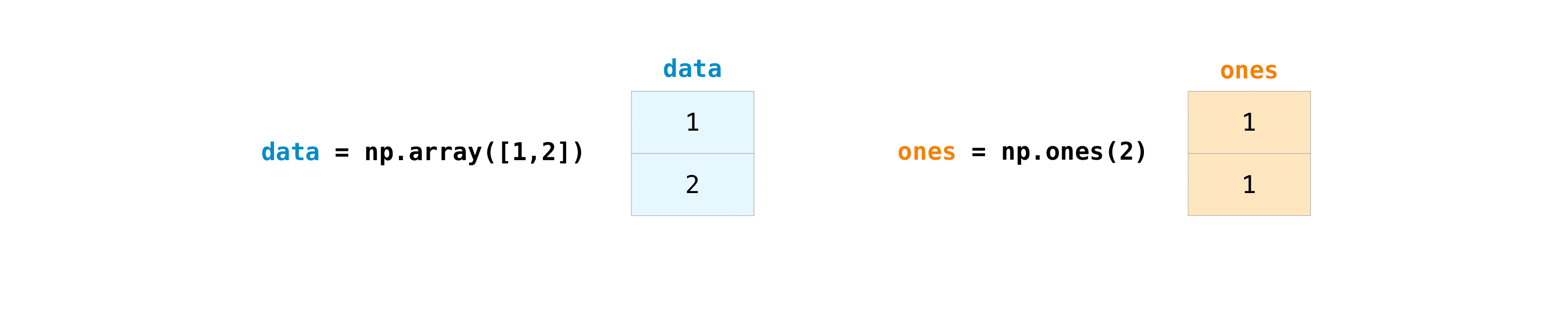
プラス記号と一緒に配列を追加することができます。
data = np.array([1, 2])
ones = np.ones(2, dtype=int)
data + ones

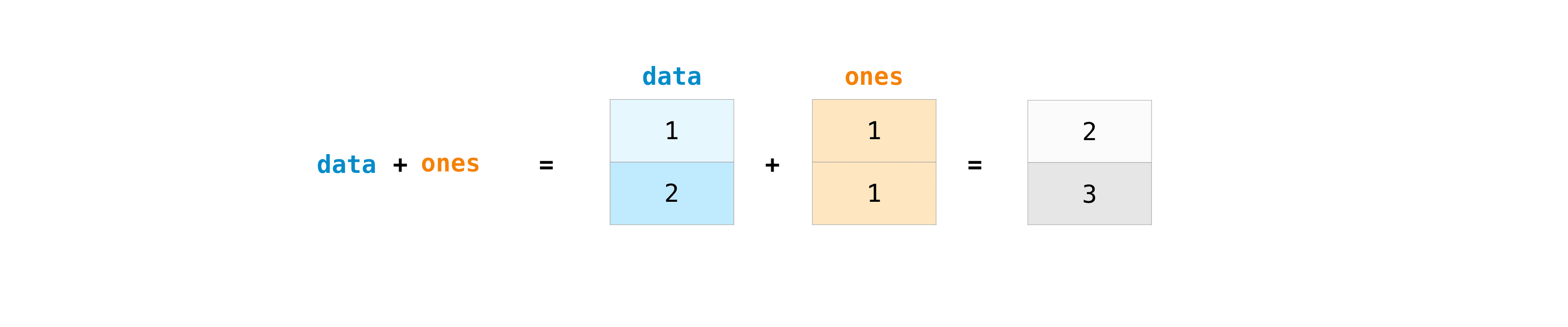
もちろん、足し算だけではありません!
data - ones

data * data

data / data

NumPyの基本的な操作は簡単です。配列の要素の和を求めるには,sum()を使います。これは,1次元配列,2次元配列,高次元の配列で動作します。
a = np.array([1, 2, 3, 4])
a.sum()

2次元配列の行や列を追加するには、軸を指定します。
以下の配列から始めると、
b = np.array([[1, 1], [2, 2]])
以下で行の合計ができます。
[補足]指定した軸(axis)に沿っていくので、指定された軸の要素が1になるイメージです
b.sum(axis=0) #[補足] 行単位なので1行になるように各列の要素を集計

以下で例の合計ができます。
b.sum(axis=1) #[補足] 列単位なので1列になるように各行の要素を集計
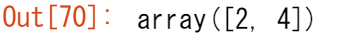
基本的な操作の詳細ついてはこちらをご覧ください。
ブロードキャスティング
配列と単一の数値(ベクトルとスカラの間の演算とも呼ばれます)や、2つの異なるサイズの配列の間で演算を行いたい場合があるでしょう。例えば、ある配列(ここでは「data」と呼ぶことにします)にはマイル単位の距離の情報が含まれているかもしれませんが、その情報をキロメートルに変換したいとします。この操作は次のようにして行うことができます。
data = np.array([1.0, 2.0])
data * 1.6
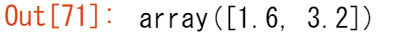
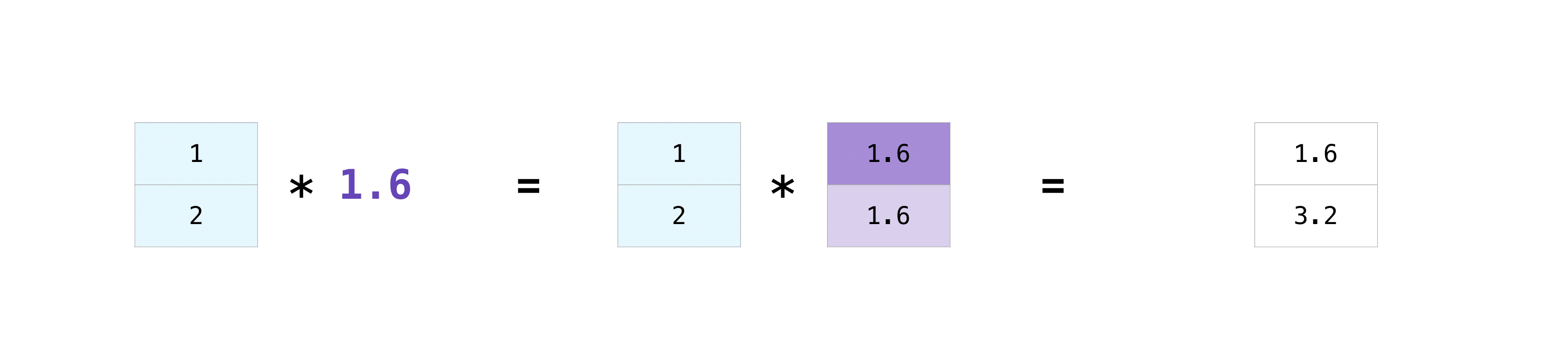
NumPyは、乗算はそれぞれのセルで行われる必要を理解しています。この概念はブロードキャストと呼ばれています。ブロードキャスティングは、NumPyが異なる形状の配列に対して演算を実行できるようにするメカニズムです。配列の次元は互換性がなければなりません。例えば、両方の配列の次元が等しい場合や、片方が1の場合などです。 次元に互換性がない場合は、ValueErrorが発生します。
ブロードキャストについての詳細はこちらをご覧ください。
より便利な配列操作
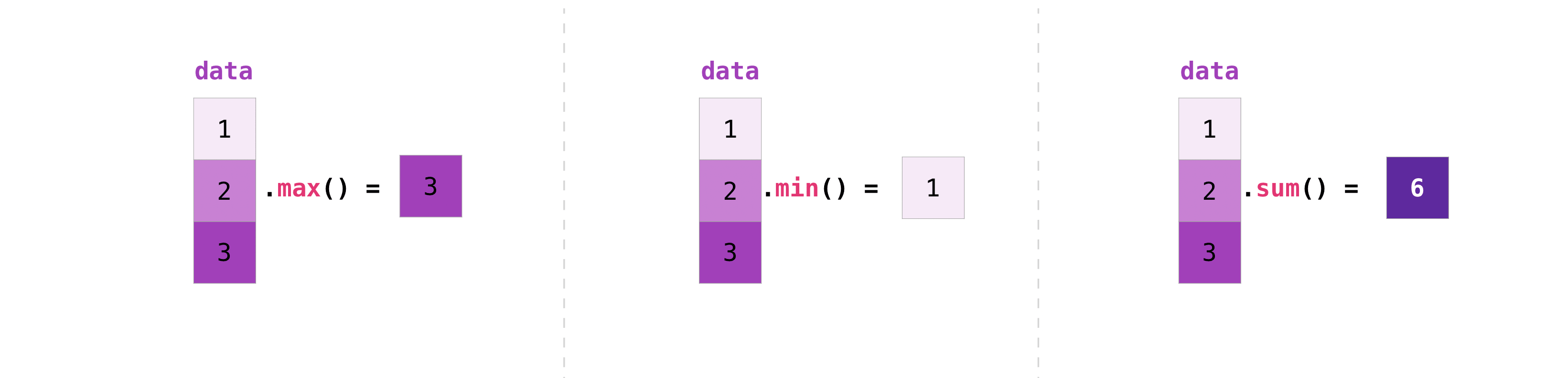
このセクションでは、最大、最小、合計、平均、積、標準偏差などを扱います。
NumPyは集計関数も実行します。min, max, sumに加えて、平均を得るためのmean、要素を掛け合わせた結果を得るためのprod、標準偏差を得るためのstdなどを簡単に実行することができます。
data.max()

data.min()

data.sum()

まずは以下の配列、"a "から始めましょう。
a = np.array([[0.45053314, 0.17296777, 0.34376245, 0.5510652],
[0.54627315, 0.05093587, 0.40067661, 0.55645993],
[0.12697628, 0.82485143, 0.26590556, 0.56917101]])
行や列に沿って集計したいというのは非常によくあることです。デフォルトでは、すべてのNumPy集約関数は配列全体の総和を返します。配列の要素の合計または最小値を求めるには、以下のように実行します。
a.sum() #合計
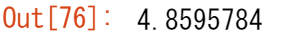
あるいは
a.min() #最小値
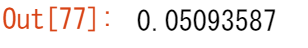
集約関数を計算させたい軸を指定できます。例えば、axis=0 を指定することで、各列内の最小値を見つけることができます。
a.min(axis=0)
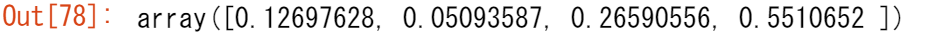
上記の4つの値は、配列の列数に対応しています。4列の配列の場合、結果として 4 つの値が得られます。
配列のメソッドについての詳細はこちらをご覧ください。
行列の作成
Pythonのリストを渡して、NumPy向けの2次元配列(または「行列」)を作ることができます。
data = np.array([[1, 2], [3, 4], [5, 6]])
data


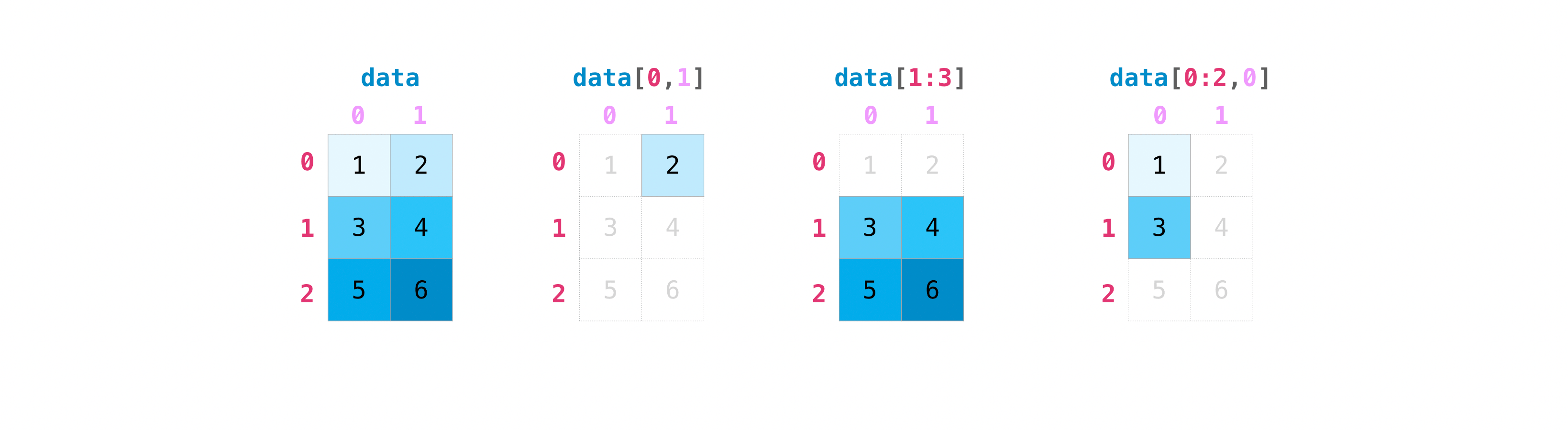
行列を操作する際には、インデックスやスライス操作が便利です。
data[0, 1]

data[1:3]
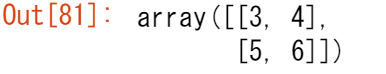
data[0:2, 0]

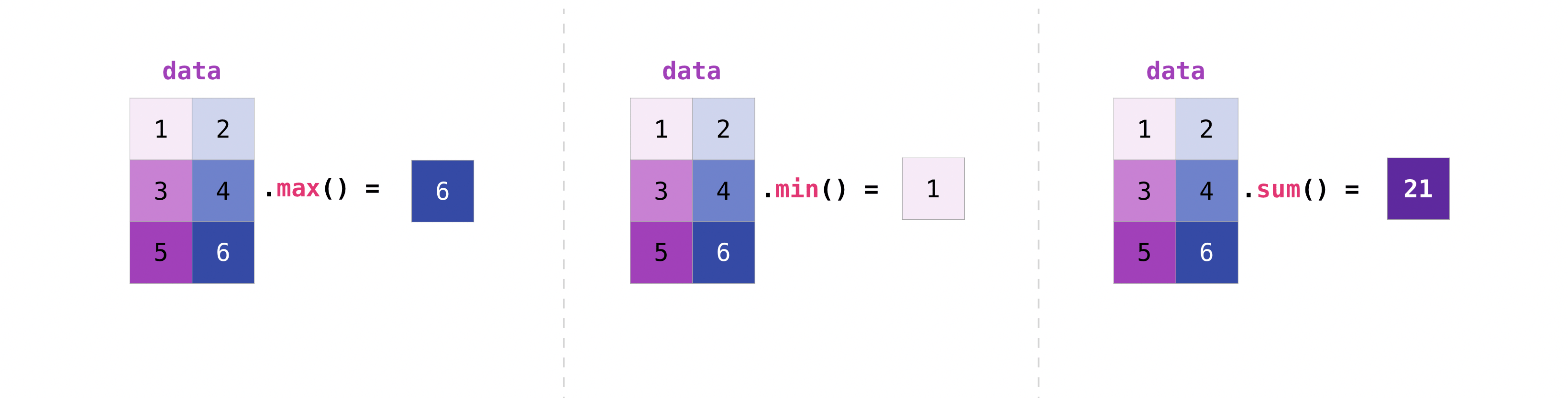
ベクトルを集約するのと同じように行列を集約することができます。
data.max()

data.min()

data.sum()

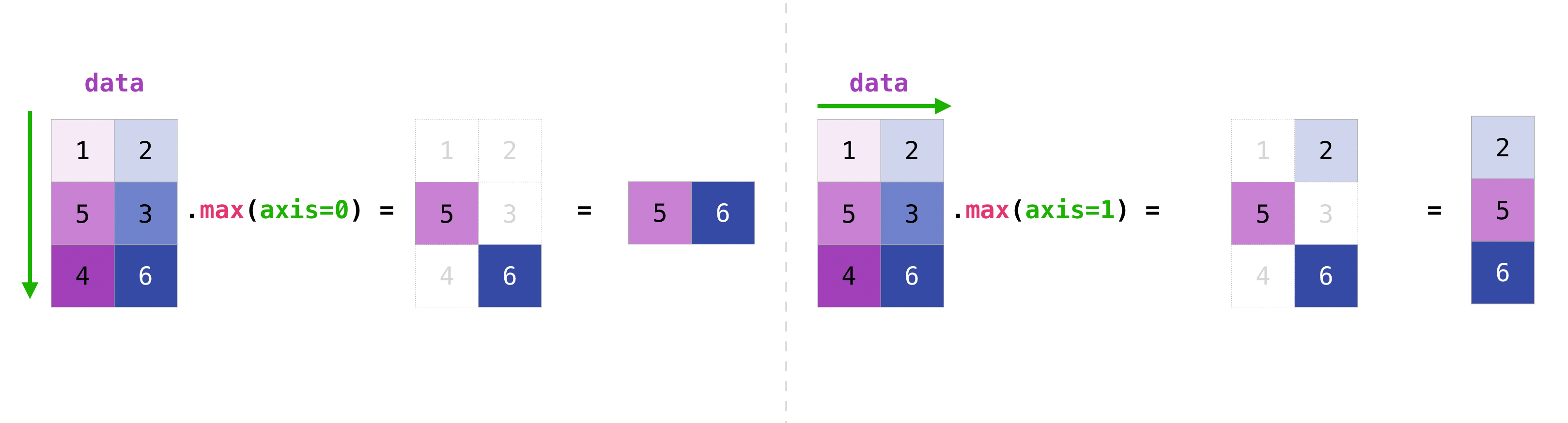
行列内のすべての値を集約することができ、軸パラメータを使用して列または行にまたがって集約することができます。
data.max(axis=0)

data.max(axis=1)

行列を作成したら、同じ大きさの行列が2つあれば、算術演算子を使って足し算や掛け算をすることができます。
data = np.array([[1, 2], [3, 4]])
ones = np.array([[1, 1], [1, 1]])
data + ones
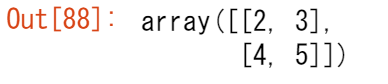
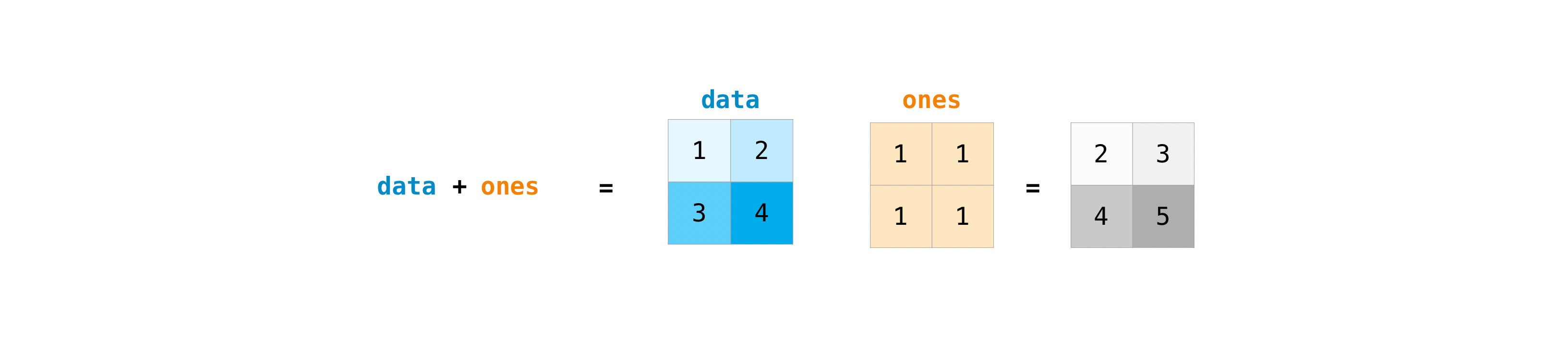
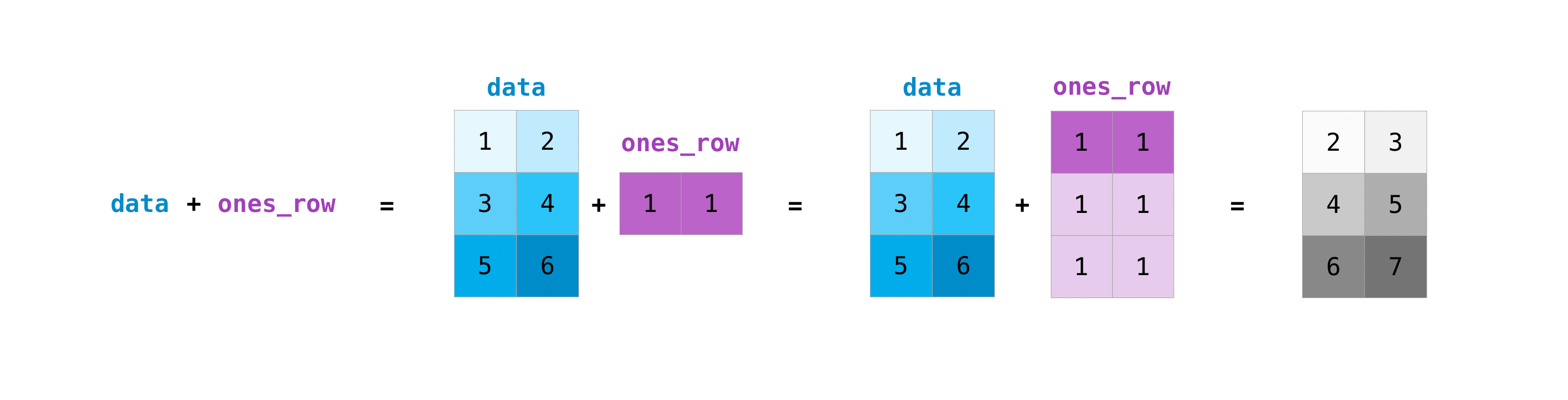
異なるサイズの行列に対してこれらの算術演算を行うことができますが、1つの行列が1列または1行しかない場合に限ります。この場合、NumPyはブロードキャスト規則を使って演算を行います。
data = np.array([[1, 2], [3, 4], [5, 6]])
ones_row = np.array([[1, 1]])
data + ones_row

NumPyがN次元配列を表示するとき,最後の軸は最も速く,最初の軸は最も遅くループされることに注意してください。
例えば、
np.ones((4, 3, 2))

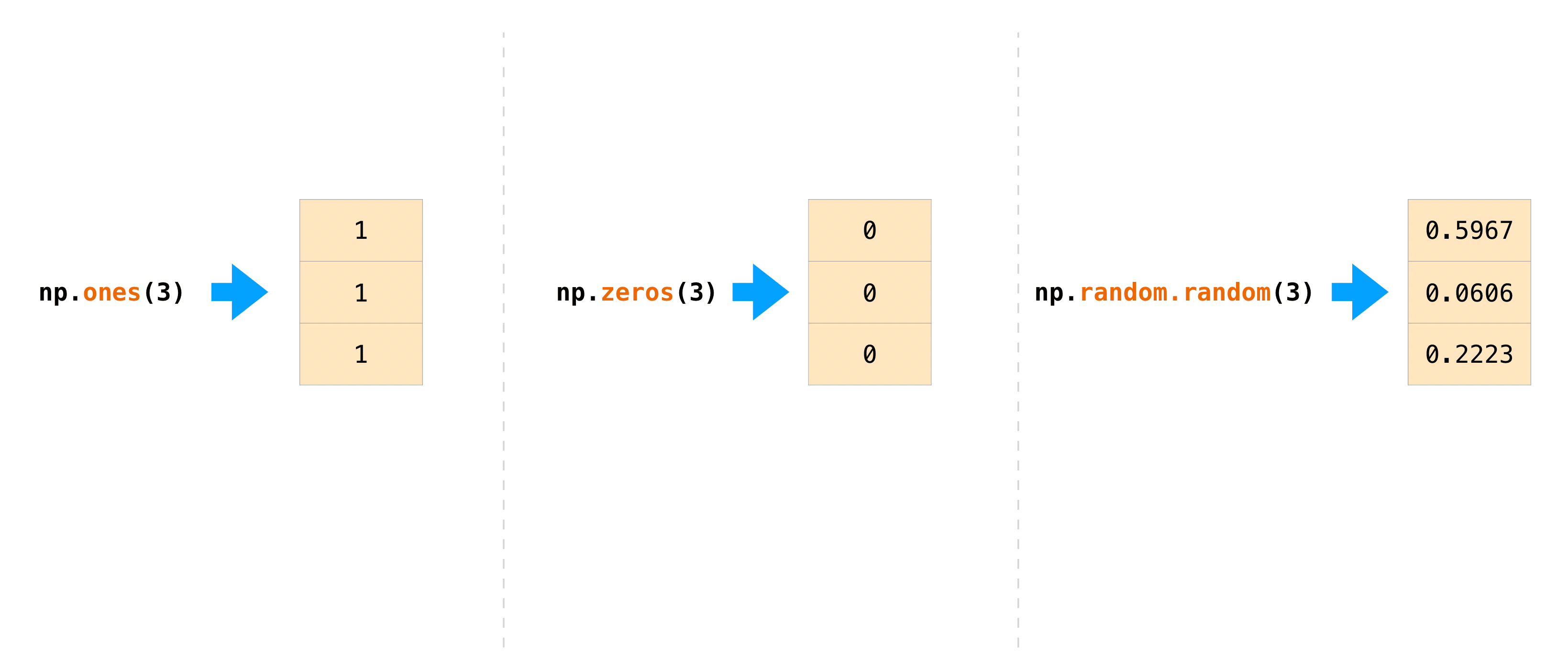
NumPyで配列の値を初期化したい場合がよくあります。NumPy には ones() や zeros() のような関数や、乱数を生成する random.Generator クラスがあります。必要なのは、生成してほしい要素数を渡すだけです。
np.ones(3)
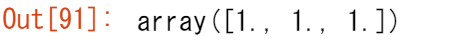
np.zeros(3)
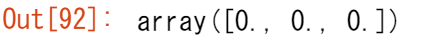
rng = np.random.default_rng(0)
rng.random(3)
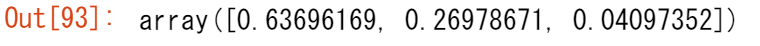
また,行列の次元を記述するタプルを与えれば, ones(),zeros(),random() を用いて 2 次元配列を作成することもできます。
np.ones((3, 2))

np.zeros((3, 2))
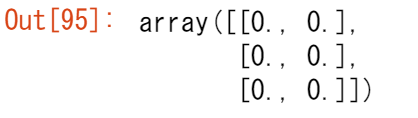
rng.random((3, 2))

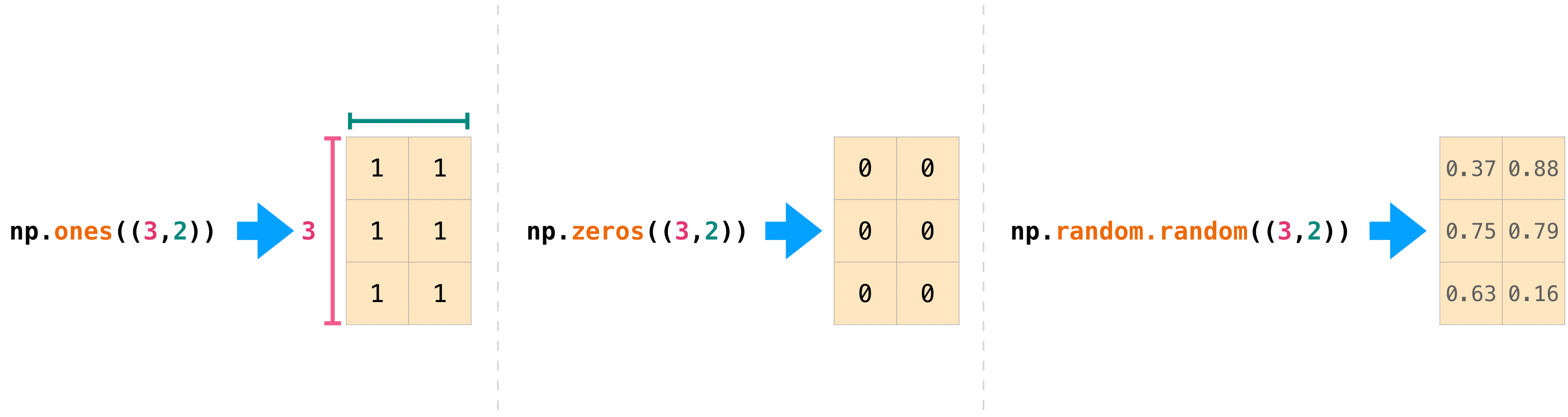
0、1、その他の値や初期化されていない値で埋められた配列を作成することについての詳細は、array creation routines参照してください。
乱数の生成
乱数生成の使用は、多くの数値計算や機械学習アルゴリズムの構成や評価の重要な部分です。人工ニューラルネットワークで重みをランダムに初期化する場合でも、データをランダムなセットに分割する場合でも、データセットをランダムにシャッフルする場合でも、乱数(実際には再現性のある擬似乱数)を生成できることは不可欠です。
Generator.integersを使えば、低位(NumPyに含まれることを忘れないようにしてください)から高位(排他的)までの乱数を生成することができます。endpoint=Trueを設定することで、高位の数値を含むようにすることができます。
以下で、0から4までの乱数の2×4配列を生成することができます。
rng.integers(5, size=(2, 4))
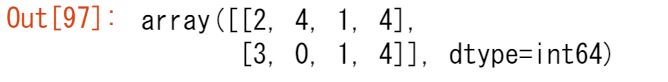
乱数の生成についてはこちらをご覧ください。
ユニークアイテムとカウント数の取得方法
このセクションでは、np.unique()を扱います。
配列のユニークな要素はnp.uniqueを使えば簡単に見つけることができます。
例えば、次のような配列で始まるとします。
a = np.array([11, 11, 12, 13, 14, 15, 16, 17, 12, 13, 11, 14, 18, 19, 20])
配列内の一意な値を表示するには np.unique を使用します。
unique_values = np.unique(a)
print(unique_values)
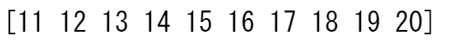
NumPy配列(配列内のユニークな値の最初のインデックス位置の配列)でユニークな値のインデックスを取得するには、np.unique()に、配列と同様にreturn_index引数を渡すだけです。
unique_values, indices_list = np.unique(a, return_index=True)
print(indices_list)
配列と一緒にnp.unique()のreturn_counts引数を渡すことで、NumPy配列内のユニークな値の頻度カウントを取得することができます。
unique_values, occurrence_count = np.unique(a, return_counts=True)
print(occurrence_count)
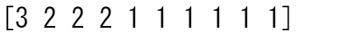
これは2次元配列でも動作します! 以下の配列から始めると、
a_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [1, 2, 3, 4]])
以下で、ユニークな値を見つけることができます。
unique_values = np.unique(a_2d)
print(unique_values)
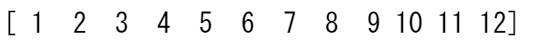
axis 引数が渡されていない場合、2D 配列は平坦化(1次元化)されます。
ユニークな行や列を取得したい場合は、必ず axis 引数を渡してください。ユニークな行を取得するには axis=0 を、列を取得するには axis=1 を指定します。
unique_rows = np.unique(a_2d, axis=0)
print(unique_rows)

ユニークな行、インデックスの位置、出現数を取得するには、以下が使えます。
unique_rows, indices, occurrence_count = np.unique(
a_2d, axis=0, return_counts=True, return_index=True)
print(unique_rows)
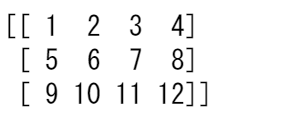
print(indices)

print(occurrence_count)
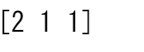
配列の中から一意な要素を見つける方法の詳細については、 unique を参照してください。
行列の転置とリシェイプ
このセクションでは, arr.reshape(), arr.transpose(), arr.Tを扱います。
行列を転置する必要があることはよくあることです。NumPy配列には、行列の転置を可能にするTというプロパティがあります。
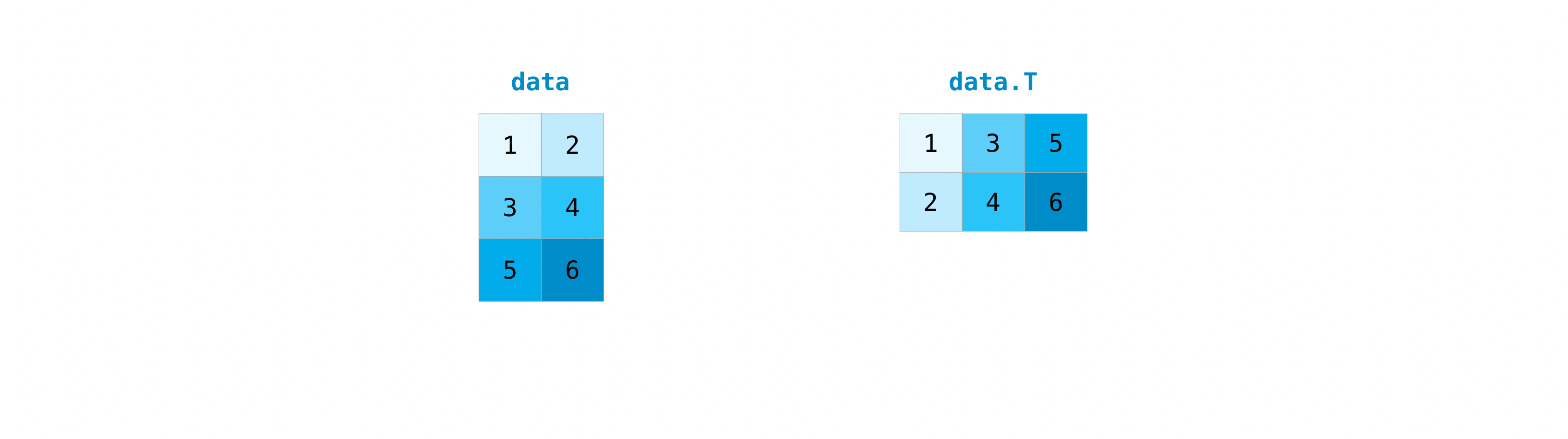
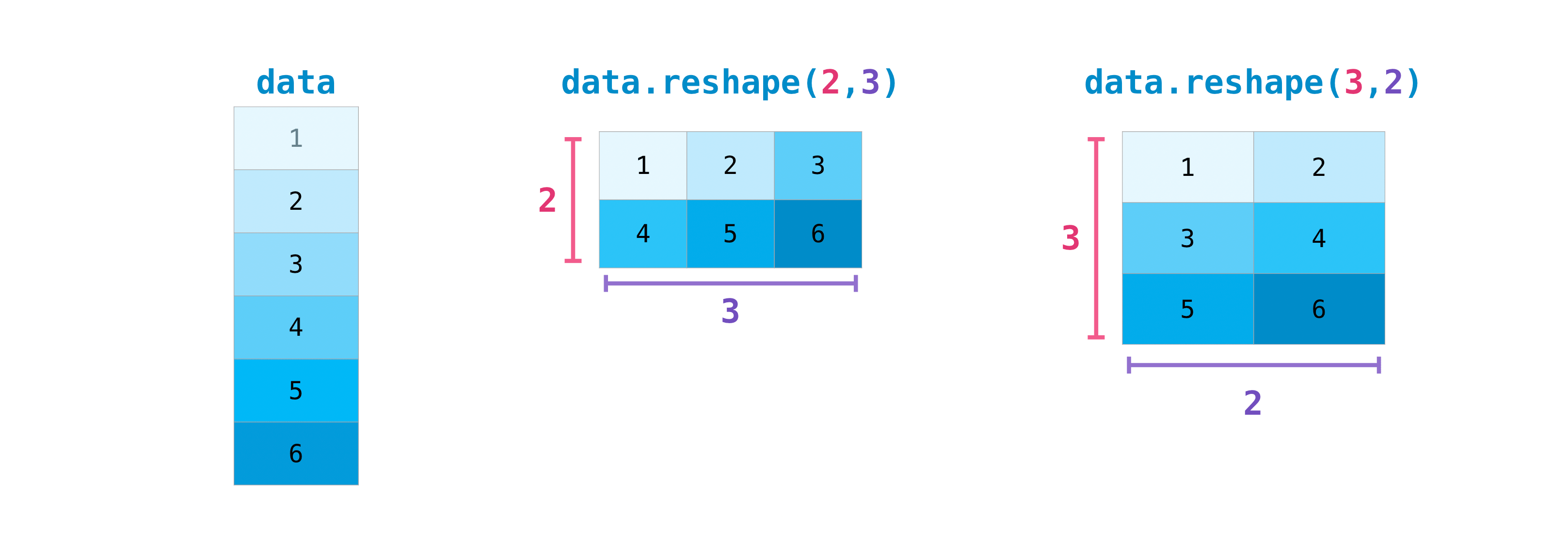
また、行列の次元を切り替える必要があるかもしれません。これは、例えば、データセットとは異なる特定の入力形状を想定したモデルがある場合などに起こります。このような場合に reshape メソッドが役立ちます。単に,行列に必要な新しい次元を渡す必要があるだけです。
data.reshape(2, 3)
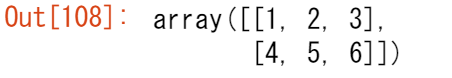
data.reshape(3, 2)

また、.transpose() を使用して、指定した値に応じて配列の軸を反転させたり変更したりすることもできます。
以下の配列で開始した場合、
arr = np.arange(6).reshape((2, 3))
arr
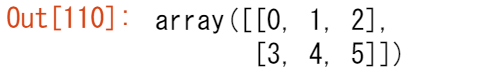
arr.transpose() を使用して配列を転置することができます。
arr.transpose()

arr.T.を使用することもできます。
arr.T
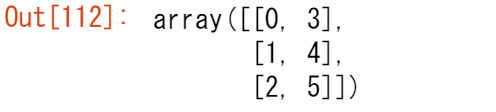
配列の転置とリシェイプの詳細については、 transpose と reshapeを参照してください。
配列を反転させる方法
このセクションでは、np.flip()を扱います。
NumPyのnp.flip()関数では、配列の内容を軸に沿って反転させたり、反転させたりすることができます。np.flip()を使用する際には、反転させたい配列と軸を指定します。軸を指定しなかった場合、NumPyは入力配列のすべての軸に沿って内容を反転します。
1次元配列の反転
以下のような1次元配列から始めると、
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
以下で反転させることができます。
reversed_arr = np.flip(arr)
逆さにした配列を表示したい場合は、以下を実行します。
print('Reversed Array: ', reversed_arr)
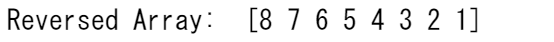
2次元配列の反転
2次元配列も同じように動作します。
以下の配列から始めると、
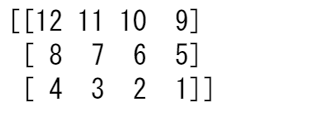
arr_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
以下で、すべての行とすべての列の内容を反転させることができます。
reversed_arr = np.flip(arr_2d)
print(reversed_arr)
以下で、行だけを簡単に反転させることができます。
reversed_arr_rows = np.flip(arr_2d, axis=0)
print(reversed_arr_rows)

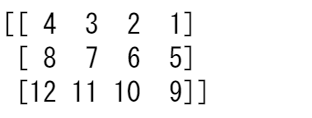
または、以下で列だけを反転させることもできます。
reversed_arr_columns = np.flip(arr_2d, axis=1)
print(reversed_arr_columns)
また、1つの列または行だけの内容を反転させることもできます。例えば、インデックス位置1(2行目)の行の内容を反転させることができます。
arr_2d[1] = np.flip(arr_2d[1])
print(arr_2d)

インデックス位置1(2列目)の列を反転させることもできます。
arr_2d[:,1] = np.flip(arr_2d[:,1])
print(arr_2d)
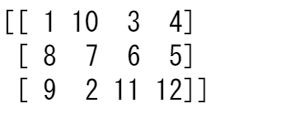
配列の反転についての詳細はflipを参照してください。
多次元配列のリシェイプと平坦化
このセクションでは、.flatten()、ravel()を扱います。
配列を平坦化するには、.flatten() と .ravel() の 2 つの一般的な方法があります。この二つの主な違いは、ravel() で作成される新しい配列は実際には親配列への参照 (つまり "ビュー" です) であるということです。つまり、新しい配列への変更は親配列にも影響するということです。ravel はコピーを作成しないので、メモリ効率が良いです。
以下の配列から始めた場合、
x = np.array([[1 , 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
配列を1次元配列に平坦化するには、flattenを使用することができます。
x.flatten()

flatten を使用した場合、新しい配列を変更しても親配列は変更されません。
例えば、
a1 = x.flatten()
a1[0] = 99
print(x) # Original array
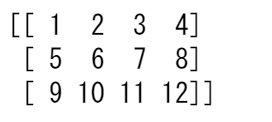
print(a1) # New array
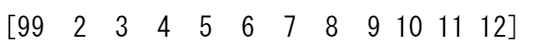
しかし、ravel を使用した場合、新しい配列に加えた変更は親配列に影響を与えます。
例えば、
a2 = x.ravel()
a2[0] = 98
print(x) # Original array
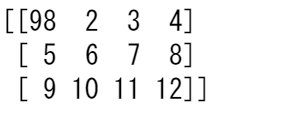
print(a2) # New array
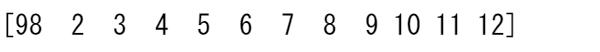
flattenについてはの詳細はndarray.flatten、ravelの詳細はravel を参照してください。
詳細を知るためにdocstringにアクセスする方法
このセクションでは、help(), ?, ??について扱います。
データサイエンスのエコシステムといえば、PythonとNumPyはユーザーのことを考えて構築されています。その最良の例の一つが、組み込みのドキュメントへのアクセスです。すべてのオブジェクトは文字列への参照を含んでおり、これはdocstringとして知られています。ほとんどの場合、このdocstringにはオブジェクトとその使い方の簡単で簡潔な要約が含まれています。Pythonには、この情報にアクセスするのに役立つ help() 関数が組み込まれています。つまり、より多くの情報が必要になったときにはほぼいつでも、 help() を使って必要な情報を素早く見つけることができます。
例えば、
help(max)
Help on built-in function max in module builtins:
max(...)
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> valueWith a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
追加情報へのアクセスは非常に便利なので、IPythonでは'?'という文字を使ってこのドキュメントにアクセスし、他の関連情報にもアクセスできるようにしています。
IPythonは複数の言語でインタラクティブな計算を行うためのコマンドシェルです。IPythonについての詳しい情報はこちらをご覧ください。
例えば、
max?
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> valueWith a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
Type: builtin_function_or_method
この表記法は、オブジェクトメソッドやオブジェクトそのものにも使えます。
以下のような配列を作成したとしましょう。
a = np.array([1, 2, 3, 4, 5, 6])
すると、多くの有用な情報を得ることができます(最初にa自身の詳細、次にaがインスタンスであるndarrayのdocstringが続きます)。
a?
Type: ndarray
String form: [1 2 3 4 5 6]
Length: 6
File: ~/anaconda3/lib/python3.7/site-packages/numpy/init.py
Docstring:
Class docstring:
ndarray(shape, dtype=float, buffer=None, offset=0,
strides=None, order=None)An array object represents a multidimensional, homogeneous array
of fixed-size items. An associated data-type object describes the
format of each element in the array (its byte-order, how many bytes it
occupies in memory, whether it is an integer, a floating point number,
or something else, etc.)Arrays should be constructed using
array,zerosorempty(refer
to the See Also section below). The parameters given here refer to
a low-level method (ndarray(...)) for instantiating an array.For more information, refer to the
numpymodule and examine the
methods and attributes of an array.Parameters
------
(for the new method; see Notes below)shape : tuple of ints
Shape of created array.
...
これは、関数やその他のオブジェクトを作成した場合にも動作します。ただ、文字列リテラルを使用して関数に docstring を含めることを忘れないでください (""" """ またはドキュメントの周りに '''
''' を使用してください)。
例えば、次のような関数を作成したとします。
def double(a):
'''Return a * 2'''
return a * 2
この関数に関する情報を得ることができます。
double?
Signature: double(a)
Docstring: Return a * 2
File: ~/Desktop/~
Type: function
興味のあるオブジェクトのソースコードを読むことで、別のレベルの情報にリーチすることができます。二重のクエスチョンマーク(??)を使うと、ソースコードにアクセスできます。
例えば、
double??
Signature: double(a)
Source:
def double(a):
'''Return a * 2'''
return a * 2
File: ~/Desktop/~
Type: function
知りたいオブジェクトがPython以外の言語でコンパイルされている場合、'??'を使用すると'?'と同じ情報が返されます。これは、例えば組み込みのオブジェクトや型の多くで見られるでしょう。
len?
Signature: len(obj, /)
Docstring: Return the number of items in a container.
Type: builtin_function_or_method
そして、
len??
Signature: len(obj, /)
Docstring: Return the number of items in a container.
Type: builtin_function_or_method
lenは、Python以外のプログラミング言語でコンパイルされているため、同じ出力を持っています。
数式を使った作業
配列上で動作する数式の実装の容易さは、NumPyが科学的なPythonコミュニティでこれほどまでに広く使われている理由の一つです。
例えば、これは平均二乗誤差の公式(回帰を扱う教師付き機械学習モデルで使われる中心的な公式)です。
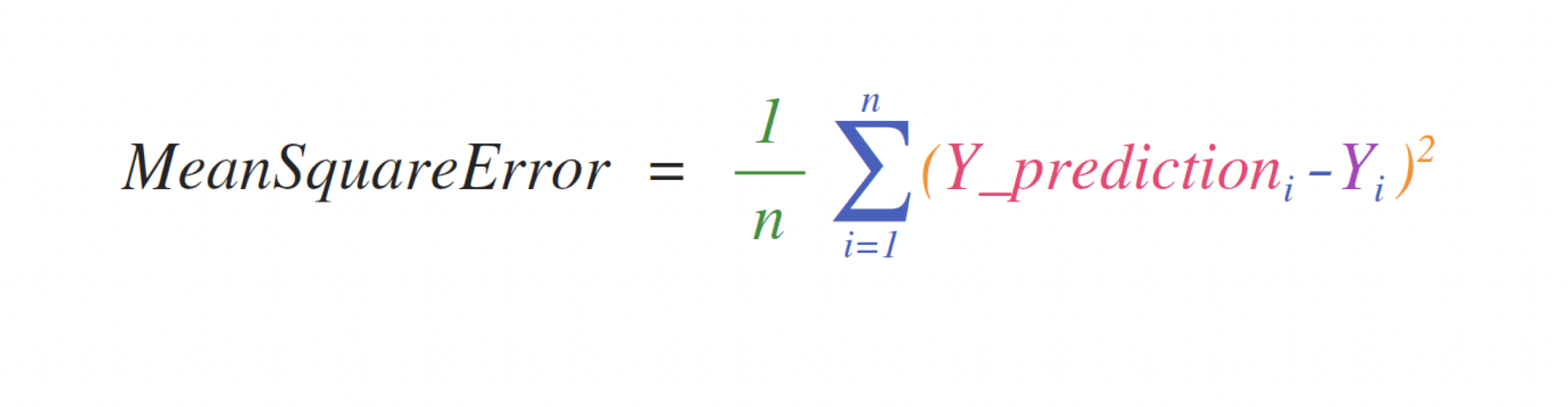
この式の実装は、NumPyではシンプルで簡単です。

これが非常にうまく機能するのは、予測値とラベルが1つまたは1000個の値を含むことができるからです。これらは同じサイズである必要があります。
このように可視化することができます。

この例では、予測ベクトルとラベルベクトルの両方に3つの値が含まれており、nには3つの値があることを意味します。減算を行った後、ベクトル内の値は2乗されます。NumPyが値を合計し、その結果が予測値の誤差値とモデルの品質のスコアとなります。

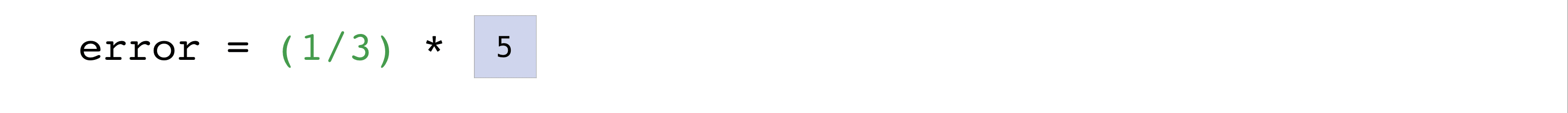
NumPyオブジェクトの保存と読み込み方法
ここでは、np.save、np.savez、np.savetxt、np.load、np.loadtxtを扱います。
ある時点での、配列をディスクに保存して、コードを再実行することなくロードしたいと思うことがあるでしょう。幸いなことに,NumPyではオブジェクトを保存したりロードしたりする方法がいくつかあります.ndarrayオブジェクトは、通常のテキストファイルを扱うloadtxtとsavetxt関数、NumPyバイナリファイルを扱うloadとsave関数、NumPyファイルを扱うsavez関数を使ってディスクファイルに保存したり、ディスクファイルからロードしたりすることができます(拡張子は.npyです)。
.npyと.npzファイルは、ファイルが異なるアーキテクチャの別のマシン上にある場合でも、配列を正しく取得できるように、データ、形状、dtype、およびNDアレイを再構築するために必要なその他の情報を格納します。
1つのndarrayオブジェクトを保存したい場合は、np.saveを使用して.npyファイルとして保存します。複数のndarrayオブジェクトを1つのファイルに保存したい場合は、np.savezを使用して.npzファイルとして保存します。また、複数の配列を1つのファイルに保存するには、savez_compressedを使用して圧縮されたnpz形式で保存することもできます。
np.save()を使えば、簡単に保存して読み込んで配列にすることができます。保存したい配列とファイル名を指定するだけです。例えば、このような配列を作成した場合、
a = np.array([1, 2, 3, 4, 5, 6])
以下で、これを「filename.npy」として保存することができます。
[補足]下記をiPythonで実行した場合、カレントフォルダに「filename.npy」が作られますので後で削除してください
np.save('filename', a)
np.load() を使用して配列を再構築することができます。
b = np.load('filename.npy')
配列をチェックしたい場合は、以下を実行します。
print(b)
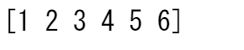
NumPy配列は,np.savetxtで.csvや.txtファイルのようなプレーンテキストファイルとして保存することができます。
例えば、以下のような配列を作成した場合、
csv_arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
以下のように「new_file.csv」という名前の.csvファイルとして簡単に保存することができます。
[補足]下記をiPythonで実行した場合、カレントフォルダに「new_file.npy」が作られますので後で削除してください
np.savetxt('new_file.csv', csv_arr)
loadtxt() を使用して、保存したテキストファイルを素早く簡単に読み込むことができます。
np.loadtxt('new_file.csv')
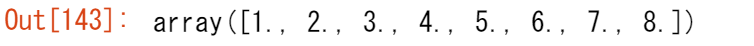
savetxt()とloadtxt()関数は、ヘッダ、フッタ、デリミタなどの追加のオプションパラメータを受け付けます。テキストファイルは共有しやすくなりますが、.npyや.npzファイルはより小さく、より速く読むことができます。テキストファイルをより高度に扱う必要がある場合(例えば、欠落した値を含む行を扱う必要がある場合など)、genfromtxt関数を使用することになります。
savetxtを使用すると、ヘッダ、フッタ、コメントなどを指定することができます。
入力および出力ルーチンの詳細については、こちらを参照してください。
CSVのインポートとエクスポート
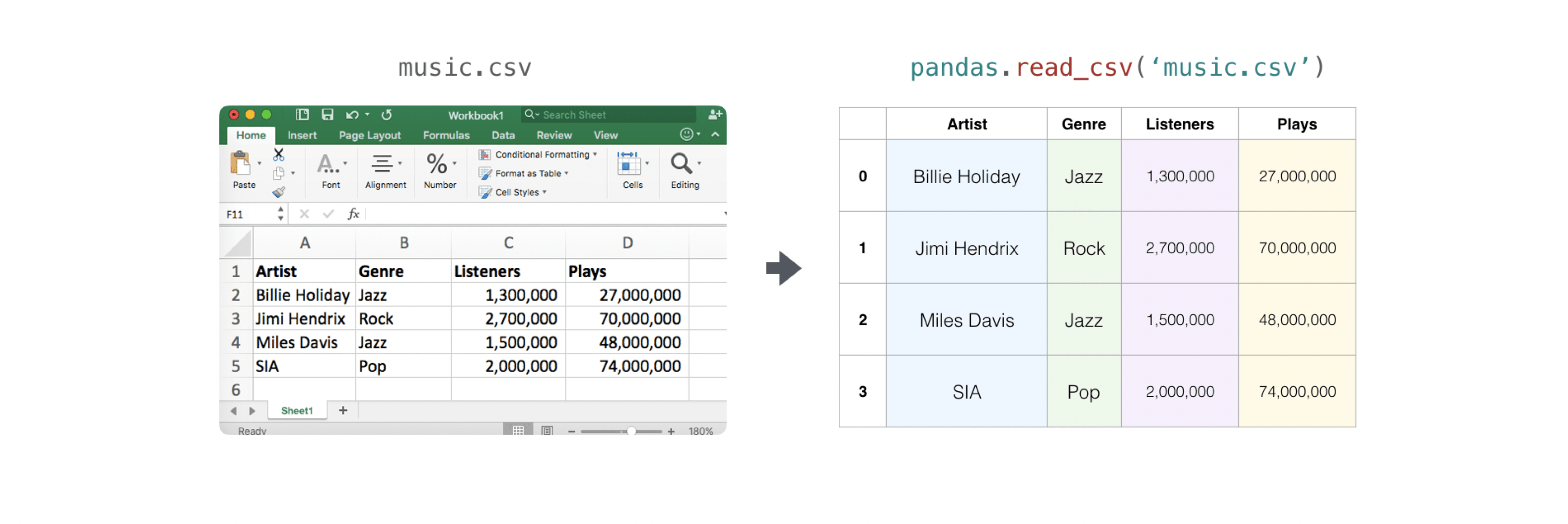
既存の情報を含んだCSVで読み込むのが簡単です。一番簡単で良いのはPandasを使うことです。
[補足]以降のコマンドを実行するためにカレントフォルダに「music.csv」を作成します。
データは下記です
Artist,Genru,Listener,Plays
Billie Holiday,Jazz,1300000,27000000
Jimmie Hendrix,Rock,2700000,70000000
Miles Davis,Jazz,150000,48000000
SIA,Pops,2000000,74000000
# テストファイルを作成します
with open('music.csv', 'w') as f:
f.write("Artist,Genru,Listener,Plays\n")
f.write("Billie Holiday,Jazz,1300000,27000000\n")
f.write("Jimmie Hendrix,Rock,2700000,70000000\n")
f.write("Miles Davis,Jazz,150000,48000000\n")
f.write("SIA,Pops,2000000,74000000\n")
f.close
import pandas as pd
# If all of your columns are the same type:
x = pd.read_csv('music.csv', header=0).values
print(x)

# You can also simply select the columns you need:
x = pd.read_csv('music.csv', usecols=['Artist', 'Plays']).values
print(x)

配列のエクスポートもPandasを使えば簡単です。NumPyに慣れていない方は、配列の値からPandasのデータフレームを作成して、PandasでCSVファイルに書き出してみるのもいいかもしれません。
以下の配列 "a "を作成した場合、
a = np.array([[-2.58289208, 0.43014843, -1.24082018, 1.59572603],
[ 0.99027828, 1.17150989, 0.94125714, -0.14692469],
[ 0.76989341, 0.81299683, -0.95068423, 0.11769564],
[ 0.20484034, 0.34784527, 1.96979195, 0.51992837]])
Pandsのデータフレームを作成することができます。
df = pd.DataFrame(a)
print(df)

以下で、簡単にデータフレームを保存することができます。
df.to_csv('pd.csv')
そして、以下でCSVを読み込み、
data = pd.read_csv('pd.csv')
data

NumPyのsavetxtメソッドを使って配列を保存することもできます。
np.savetxt('np.csv', a, fmt='%.2f', delimiter=',', header='1, 2, 3, 4')
コマンドラインを使っている場合は、次のようなコマンドでいつでも保存したCSVを読み込むことができます。
[補足]Windows学習環境でcatコマンドの代わりにWindowsのtypeコマンドで確認します
# cat np.csv オリジナルコード
!type np.csv

または、テキストエディタでいつでも開くことができます!
Pandasについて詳しく知りたい方は、Pandasの公式ドキュメントをご覧ください。Pandasの公式インストール情報でPandasのインストール方法をご紹介します。
Matplotlibによる配列のプロット
値のプロットを作成する必要がある場合,Matplotlibを使用すると非常に簡単です.
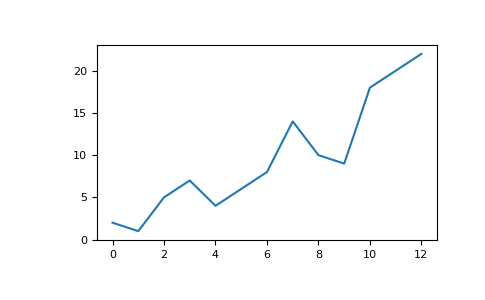
例えば、以下のような配列があれば、
a = np.array([2, 1, 5, 7, 4, 6, 8, 14, 10, 9, 18, 20, 22])
すでにMatplotlibがインストールされている場合は、それを使ってインポートすることができます。
import matplotlib.pyplot as plt
# If you're using Jupyter Notebook, you may also want to run the following
# line of code to display your code in the notebook:
%matplotlib inline
値をプロットするために必要なのは、実行することだけです。
plt.plot(a)
コマンドラインから実行している場合は、以下の操作が必要になります。
>>>plt.show()
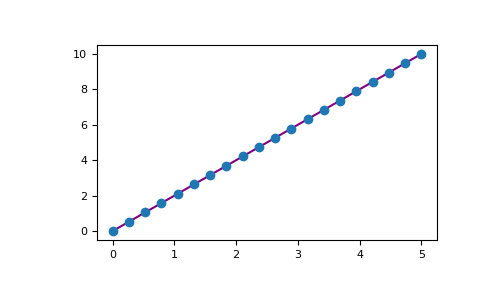
例えば、1次元配列をこのようにプロットすることができます。
x = np.linspace(0, 5, 20)
y = np.linspace(0, 10, 20)
plt.plot(x, y, 'purple') # line
plt.plot(x, y, 'o') # dots
Matplotlibを使用すると、膨大な数の可視化オプションにアクセスすることができます。
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)
X = np.arange(-5, 5, 0.15)
Y = np.arange(-5, 5, 0.15)
X, Y = np.meshgrid(X, Y)
R = np.sqrt(X**2 + Y**2)
Z = np.sin(R)
ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='viridis')
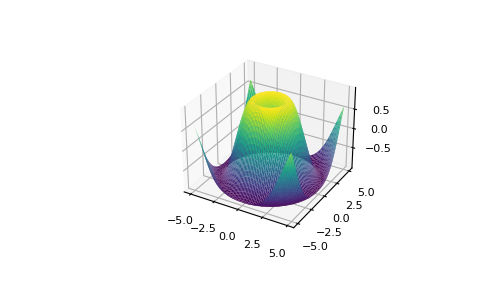
Matplotlibとそれができることについての詳細を読むには、公式ドキュメントを見てください。Matplotlibのインストール方法については、公式のインストールセクションを参照してください。
Image credits: Jay Alammar http://jalammar.github.io/
おわりに
NPO法人AI開発推進協会では、本チュートリアルをiPythonやGoogleコラボ上で動かしながら学習するオンランセミナーや、さまざまなAIモデルをボタンを押すだけでAIを体験できるGUIツールを用いたセミナーも定期的に開催しています。 また、各種AIのモデルの解説も掲載しております。興味がありましたら当法人のホームページをご覧ください。