はじめに
Pandasで大量データを扱って処理時間にイライラしたことはないでしょうか?
なんと、Pandasを従来のコードを変えずに高速化するライブラリィが出たみたいです。
NEC研究所が出したFireDucks 🔥🐦 というライブラリィで、ベータ版が無償公開されています。
しかも CPU環境でも高速化されるみたいです。詳細は下記のサイトを参照してください。
ベーター版ですが無償とは素晴らしいですね!
早速検証してみましょう。
環境
FireDucksの利用方法には、「インポートフック」、「明示的なインポート」の2種類があります。
「インポートフック」の場合は、pythonの起動時にオプションを指定することでコードの書き換えなしに動かすことができます。一方、「明示的なインポート」の場合は、import文にfireducksを明示的に指定します。
python3 -m fireducks.imhook your_script.py
# import pandas as pd
import fireducks.pandas as pd
今回、Googleコラボで検証するため、「明示的なインポート」を使用します。
簡単な検証
定番の tatanicデータ を使って検証してみます。
groupby()メソッドでの効果を測定(してみますが、データ量が少ないので1万回ループして計測して見ます。
動作環境はGoogleコラボ上で、効果の違いが出そうなcpuリソースを使います。
通常のPandas環境
import pandas as pd
import time
# Githubに公開されているデータを直接読み込む
url = 'https://raw.githubusercontent.com/pandas-dev/pandas/master/doc/data/titanic.csv'
titanic = pd.read_csv(url)
start = time.time()
for i in range(10000):
titanic.groupby(["Sex", "Pclass"])["Fare"].mean()
elaps = time.time() - start
print(elaps)
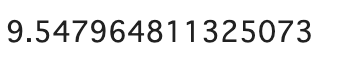
おおよそ9.5秒でした。
FireDucks環境
-
fireducksのインストールを行います
!pip install fireducks
- FireDucksでの処理時間の検証
import fireducks.pandas as pd2
url = 'https://raw.githubusercontent.com/pandas-dev/pandas/master/doc/data/titanic.csv'
titanic2 = pd2.read_csv(url)
import time
start = time.time()
for i in range(10000):
titanic2.groupby(["Sex", "Pclass"])["Fare"].mean()
elaps = time.time() - start
print(elaps)
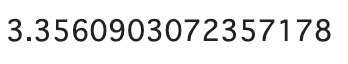
約3.4秒で おおよそ3倍 もの高速化がされています。
これはすごい!。
大量データを扱う場合にはかなり効果が発揮されそうです。
おわりに
無償かつコードの変更なしに手軽るに使えるとなれば、使わない手はないと思います。
公式ホームページによると、全てのpandasのメソッドが高速化されている訳ではなく、順次対応メソッドを増やしていくとのことみたいです(FireDucksに対応されていないメソッドは、内部で通常のpandasのメソッドを呼び出しているので、使えないわけではなく高速化されないだけみたいです)。
今後とも応援していきたいですね(今後とも無償での継続提供を期待しています!)。
[補足]
Pandasをはじめ、Pythonやmatplotlib等のチュートリアルをオンラインで自己学習できるコンテンツを公開しています。よろしかったらこちらもご参照ください。