1.はじめに
自然言語処理の文の類似度の算出をきっかけに、最適輸送処理を使ったWRDに興味をもち勉強してみました。
最適輸送理論は、その名の通り最適な輸送を考えるもので、最良の輸送プランと総輸送コストを求めるもののようです。ですが、確率分布を比較するものであることから、その応用分野は広く、自然言語をはじめ、画像処理、機械学習などいろいろな分野で使われているようです。
今回は、以下の論文で紹介されているWRD(Word Rotator’s Distance)について、ざっくり理解してみたいと思います。前半に文の類似度について、後半にWRDについて記載しました。導出や計算方法までの理解ではなく、あくまで自然言語処理でどんな使われ方をしているのかについての納得感を目指したいと思います。
参考文献:「超球面上での最適輸送に基づく文類似性尺度」
2.文の類似度の算出手法
まずは、文の類似度の算出について、以下3つのタイプにわけ、それぞれ代表的な手法を紹介します(詳細はリンクの※2のサイトを確認ください)。
①単語の出現回数を用いたもの
最初は、文書中の単語出現数をもとに文書ベクトルの類似度を算出する方法です。
-
BoW :文章をベクトル(数値)化する一番単純な手法が Bag of Words(BoW) です。BoWは、文章を形態素解析と呼ばれる処理で単語単位に分割し、各単語が何回出現したかを数え上げ文書ベクトルとします。この文章ベクトルをコサイン類似度などを用いて計算して文の類似度を算出します 。コサイン類似度は、ベクトルの向きがどの程度同じ方向を向いているか?という指標です。似た単語が多いと同じような向きになるので類似度が高い文となるイメージですね。このやり方だと、単語の並びを無視しているので重要な情報が飛んでしまいそうな気がしますが、類似文書検索タスクでは、十分精度がでるといわれています。
-
TF-IDF:TF-IDF は Term Frequency – Inverse Document Frequency の略で、文書中の単語の重要度を評価する手法です。具体的には、「文書に単語が何回出現したか」に「この文書特有の単語かどうか」を掛けて重要度を反映して文書ベクトル化するものです。
②単語の分散表現を用いたもの
次は、文章中の単語の分散表現をもとに文書ベクトルの類似度を算出する方法です。単語の分散表現は、単語を多次元空間上の座標にマッピングすることで、単語同士の類似度を比較したり、加減算したりすることができるようになるものです。単語の分散表現の代表的なものには、Word2VecやRetrofittingがあります。
-
WMD:単語を一対一で対応づけるのではなく、重み付きの対応関係を考える手法。単語に紐つく重みの和が頻度に等しくなるよう制約をかけ、重みと単語間距離の積の総和が最小となるように重みを調整します。調整済みの重みと単語間距離の積の総和が2文間の距離(=Word Mover’s Distance)となります。この手法の欠点は計算量が大きいことです(語数の3乗に比例)。類似文書検索のようにクエリと検索対象間で多数の類似度計算が必要な場面では現実的ではないと思われます。
-
LC-RWMD:WMD と比較して精度と引き換えに計算量を大幅に削減する手法です。計算量は語数に比例します。
③文章の分散表現を用いた手法
最後は、文章の分散表現を用いた手法です。単語の分散表現を使ったやり方では文の類似度を得るためにひと手間必要でしたが、こちらは文書自体を固定長のベクトルに変換し、コサイン類似度等で評価するという手法です。
-
Dec2Vec:Word2Vec を文章に適用できるようにアレンジした手法です。 Doc2Vec には PV-DM、PV-DBoW の二つの手法があり。
-
Sent2Vec:こちらも Word2Vec のアレンジといってよいでしょう。こちらの学習では単語とNグラムの分散表現が得られます。
3.最適輸送を使った EMD → WMD → WRD を理解する
ここからは、これら文書の類似度の算出方法の中で、最も良好な精度がでていると論文で紹介されているWRDについて紹介したいと思います。最適輸送のEMDから、WMD、WRDと順を追って紹介していきたいと思います。
3.1 EMD(Earth Mover’s Distance)
EMDを使って最適輸送コストを算出する方法についてまずは考えます。EMDは与えられた2つの分布間の輸送コストを最小化する最適化問題です。最適化問題を解く過程で得られる2点間のアライメント(対応関係)が単語ベクトルのアライメントとして利用されます。

3.2 WMD(Word Mover’s Distance)
WMDは、EMDを利用した文の意味的な類似性(semantictextual similarity; STS) 計算手法の草分け的存在です。WMDでは各文を「単語ベクトルの集合(離散分布)」とみなし、その間のEMD(最適輸送コスト)を測り、単語ベクトルのアライメントとして利用します。

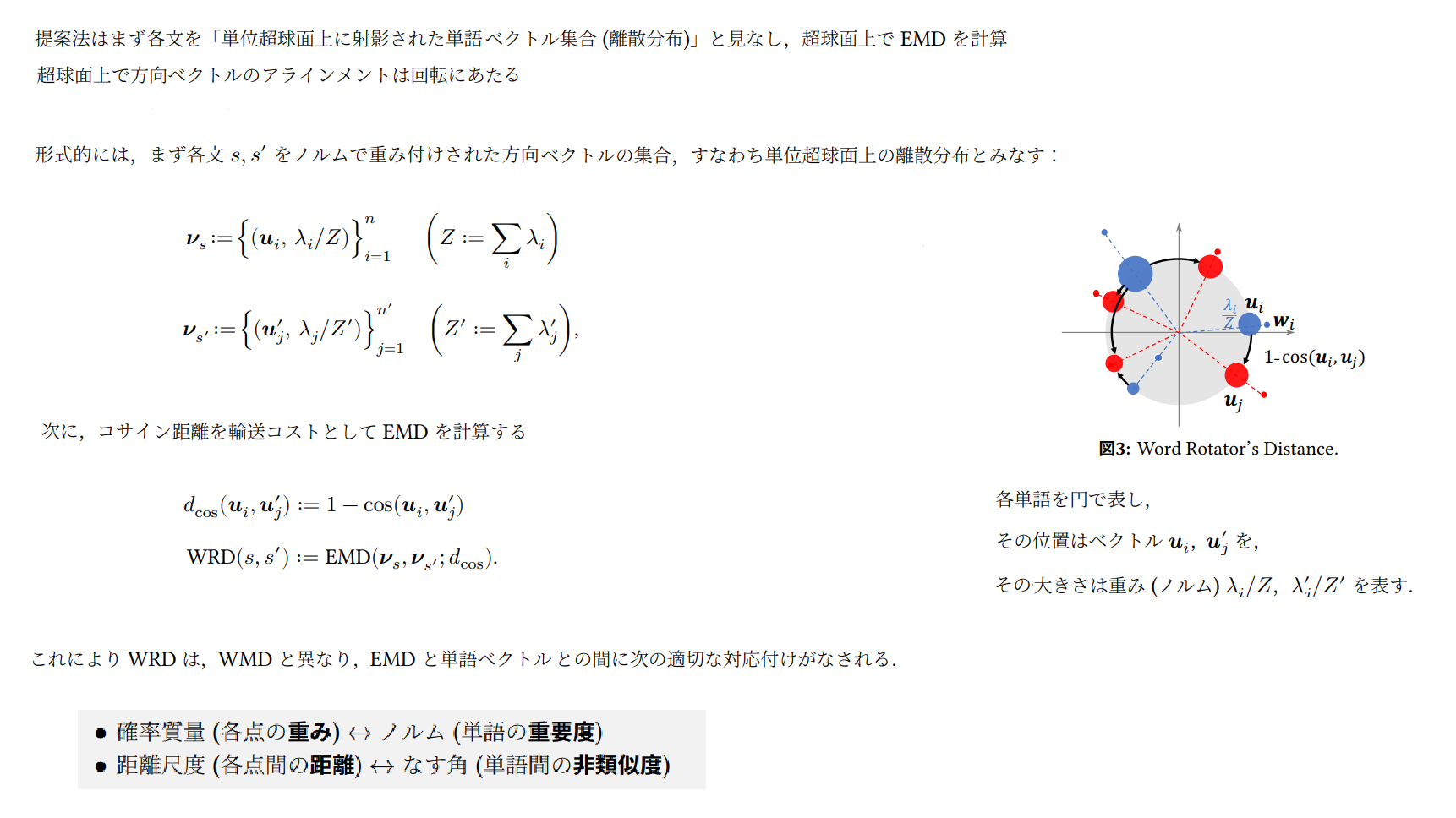
3.3 WRD(Word Rotator’s Distance)を理解する
WRDはWMDにおいて問題とされている以下2点の考察から、単語ベクトルのノルムと方向ベクトルを分けて活用する新しい分類類似尺度として提案されています。
[ WMDの問題点 ]
・各単語ベクトルの重要度(ノルム)を無視して一様に重みづけをしている
・重要度と意味が混ざったユークリッド距離を使っている
※単語ベクトルのノルム(長さ)には単語の重要度が、
単語ベクトルの方向ベクトル(向き)には単語の意味がエンコードされている
まとめ
最適輸送ベースのWRDを使うと単語のベクトル表現で獲得した単語の重要度と意味あいを良い感じに扱って良い結果がでるということですね。最適輸送については、2023年1月に新しく (機械学習プロフェッショナルシリーズ)から「最適輸送の理論とアルゴリズム」が発売されるようなので、もう少し掘り下げてみたいと思います。
参考サイト
※1:超球面上での最適輸送に基づく文類似性尺度
※2はじめての自然言語処理
※3:深層学習による自然言語処理入門: word2vecからBERT, GPT-3まで
※4:輸送問題を近似的に行列計算で解く(機械学習への応用つき)