本記事では、論文「Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond」をベースに大規模言語モデルの利用にフォーカスしてまとめます。変化の激しい領域ですが、基本的な考え方の整理としてご活用いただければ幸いです。
論文「Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond」
2023年4月にAmazonの自然言語処理(NLP)研究科学者などによって執筆された論文。
下流の自然言語処理(NLP)タスクで大規模言語モデル(LLM)を使用する際の実用的な側面に焦点をあて実用的なガイドラインを示したもの。
論文の構成:
1.現在のGPTおよびBERTスタイルのLLMの紹介と簡単な概要
2.事前学習データ、学習データ、テストデータの影響
3.自然言語タスクにおけるユースケースに関して
用語の定義:
LLMsとFine-tuned Modelsの定義は以下の通り(論文での定義)。
- LLM:(特定のタスクのデータを調整することなく)膨大な量のデータを用いて事前学習された巨大な言語モデル
- Fine-tuned Models:より小さな言語モデルで事前学習された後、より小さなタスクの固有のデータセットでさらにチューニングされ、そのタスクでの性能を最適化したモデル。
大きなモデルをファインチューニングすることも可能だが、多くの個人や組織にとって困難なため、実用的な観点から20B以下のモデルをファインチューニングモデルとして扱う(論文記載)。ファインチューニングに関する別記事の記載も大変興味深いのでぜひ参考にしてみてください。
主なLLMの一覧
下図は、論文関連のサイトから抜粋したものです。LLM の使用制限(商業目的や研究目的など)や、事前トレーニングデータの観点で情報がまとまっています。積極的に更新されているサイトですので参考にしてみてください。
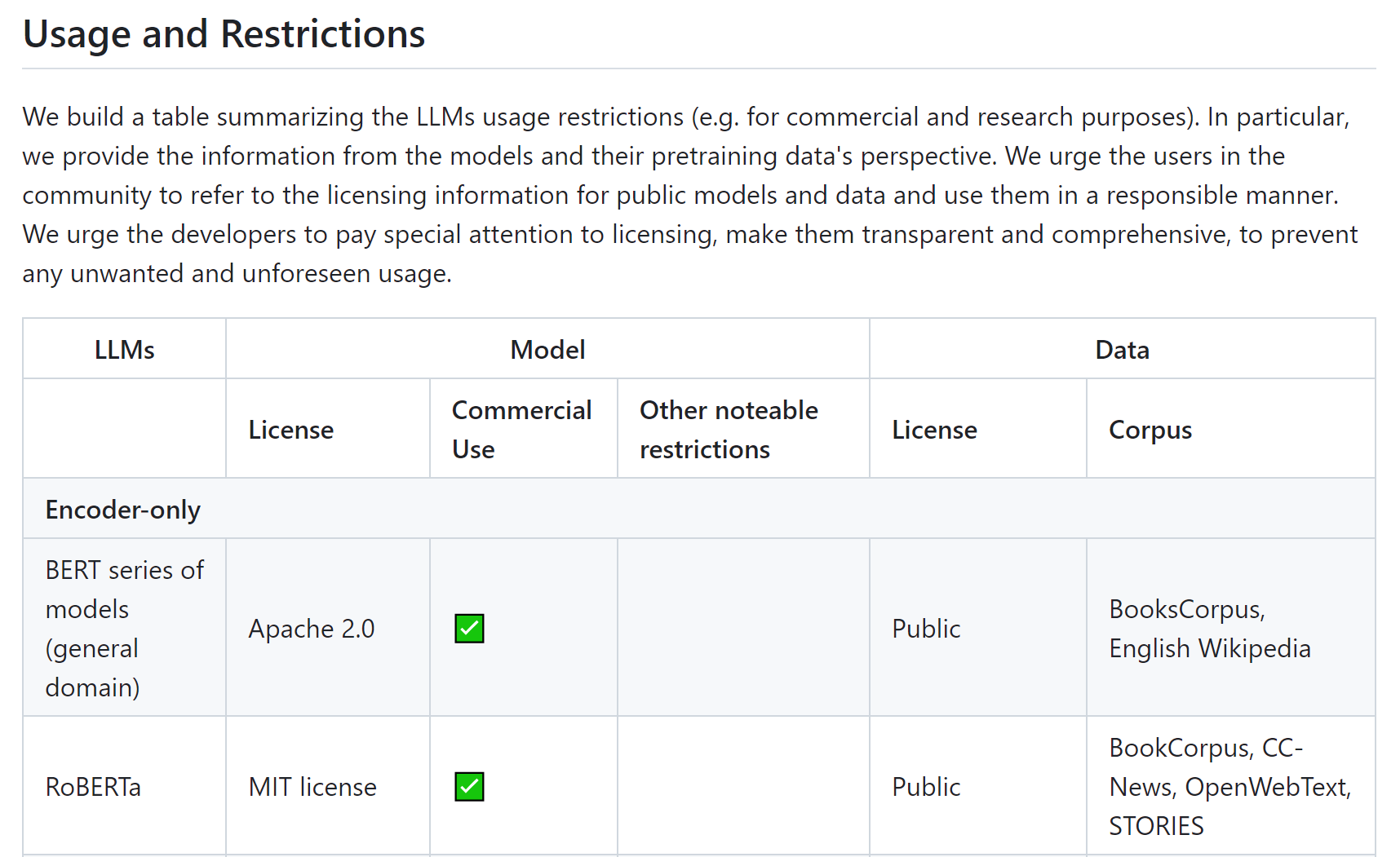
日本語LLMについてまとめられたページはこちらが参考になります。
どのタスクで使う?
LLMの活用における基本的な考え方は、以下の通り。
- 自然言語理解:分布外のデータに直面したときや、学習データが非常に少ないとき、LLMの優れた汎化能力を活用する。
- 自然言語生成:LLMの能力を活用し、さまざまなアプリケーションに対応した、首尾一貫した、文脈に即した、高品質なテキストを作成する。
- 知識集約型タスク:LLMに含まれる広範な知識を、ドメイン固有の専門知識や一般的な知識を必要とするタスクに活用する。
- 推論能力:LLMの推論能力を理解し、活用することで、さまざまな文脈での意思決定や問題解決を向上させる。
どっちを使う?(LLMs or Fine-tuned Models?)
自然言語処理(NLP)アプリケーションにおいて、大規模言語モデル(LLMs)またはファインチューニングモデル(Fine-tuned Models)の選択のための意思決定フロー。
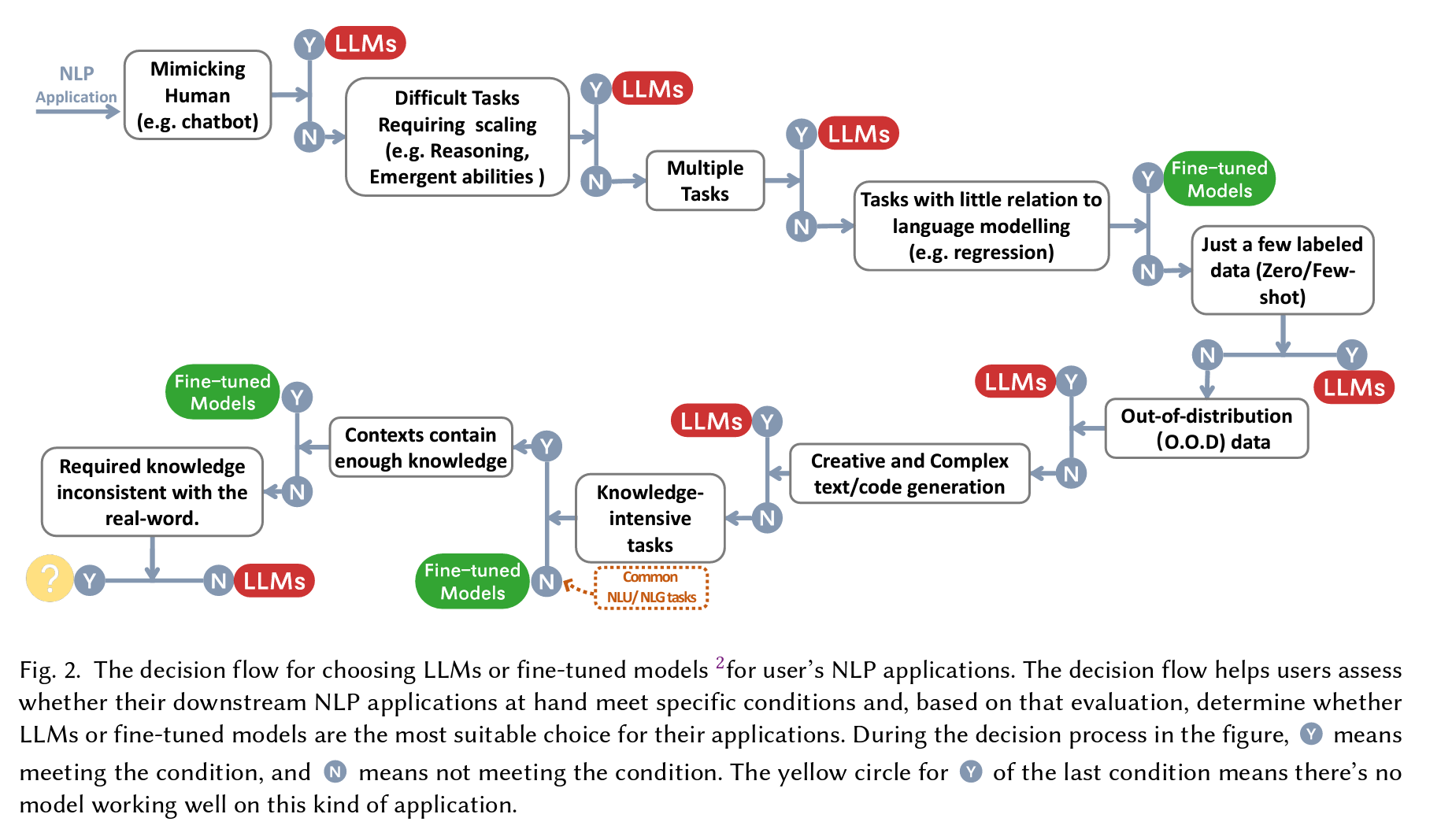
(出展元)「Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond」
| 条件 | モデル | |
|---|---|---|
| 1 | 人間の真似をする(例:チャットボット) | LLMs |
| 2 | スケーリングが必要な難しいタスク(例:推論、論理的能力) | LLMs |
| 3 | 複数のタスク | LLMs |
| 4 | 言語モデリングとあまり関係のないタスク(回帰など) | Fine-tuned Models |
| 5 | わずかなラベル付きデータ(ゼロショット/フューショット) | LLMs |
| 6 | 分布外(Out-of-Distribution, O.O.D)データ | LLMs |
| 7 | 創造的で複雑なテキスト/コード生成 | LLMs |
| 8 | 知識集約型タスク(文脈に十分な知識が含まれている) | Fine-tuned Models |
| 9 | 知識集約型タスク(文脈に十分な知識が含まれている かつ 必要な知識が現実世界と矛盾していない) | LLMs |
Fine-tuningについて上で紹介した別記事には、『The problems that this approach is effective at are usually those that involve learning the style or form of language rather than learning new concepts that do not exist in the base knowledge of the foundational model.』(DeepLで翻訳:このアプローチが効果的な問題は、通常、基礎モデルのベースとなる知識に存在しない新しい概念を学ぶのではなく、言語のスタイルや形式を学ぶものである。)と記載されています。
論文の各章における記載の抜粋 (GPT翻訳+α)
3 PRACTICAL GUIDE FOR DATA

- LLMは、逆例やドメインシフトなどの分布外データを扱う下流タスクにおいて、ファインチューニングされたモデルよりも一般化能力が高い。
- 注釈付きデータが限られている場合、LLMはファインチューニングされたモデルよりも好ましい選択肢となる。豊富な注釈付きデータが利用可能な場合、特定のタスク要件に応じて、どちらも合理的な選択肢となり得る。
- 下流タスクに類似したデータ分野で事前学習されたモデルを選択することが望ましい。
Adversarial examples:逆例や敵対的例と訳されることが多く、モデルが誤った予測や判断を行うように意図的に設計されたデータ。モデルの堅牢性テストに使用。
4.1 Traditional NLU tasks

伝統的な自然言語理解(NLU)タスクにおいては、一般的にファインチューニングされたモデルがLLMよりも良い選択であるが、強力な一般化能力を要求される場合にはLLMが助けとなることがある(一般化能力が必要な場合は、LLMが強い?)。
4.2 Generation tasks
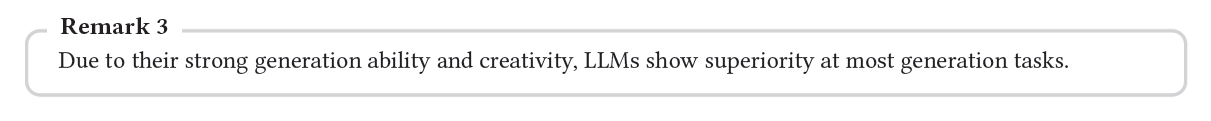
その強力な生成能力と創造性により、LLMはほとんどの生成タスクで優位性を示す。
4.3 Knowledge-intensive tasks

- LLMは膨大な実世界知識を持っているため、知識集約的な仕事を得意とする。
- 知識要件がLLMが学習した知識と一致しない場合、または文脈的な知識のみが必要なタスクに直面した場合、LLMは苦戦することがある。このような場合、ファインチューニングされたモデルはLLMと同じくらいうまく機能することがある。
4.4 Abilities Regarding Scaling

- モデル規模の指数関数的増加に伴い、LLMは算術推論や常識的推論のような推論能力に特に長けるようになる。
- 大規模化するにつれて現れるLLMの突発的な能力、例えば言葉の操作や論理的な能力は、新たな使用法にとって幸運な偶然となる(予期せず能力が向上する?)。
- 大規模言語モデルの能力が拡大するにつれてどのように変化するかの理解が限られているため、多くの場合、性能はスケーリングに伴って一様に向上するわけではない(実態がわからない?理由がわかっていない?)。
4.5 Miscellaneous tasks

- ファインチューニングされたモデルや特定のモデルは、LLMの事前学習目的やデータとはかけ離れたタスクにおいて、まだその余地を残している(活躍の場がある?)。
- LLMは人間の行動を模倣し、データの注釈付けや生成に優れている。また、自然言語処理(NLP)タスクの品質評価にも使用され、解釈可能性のような追加的な利点を提供する。
4.6 Real world "tasks"

LLMは、ファインチューニングされたモデルに比べて、実世界のシナリオを扱うのに適している。しかし 実世界におけるモデルの有効性を評価することは、まだ未解決の問題である。
5 OTHER CONSIDERATIONS

- 特にコストに敏感である場合や厳しいレイテンシー要件を持つ場合は、LLMではなく、軽量でローカルなファインチューニングされたモデルを検討すべき。パラメータ効率の良いチューニングは、モデルの展開や提供において実現可能な選択肢となり得る。
- 大規模言語モデル(LLM)のゼロショットアプローチでは、タスク固有のデータセットからのショートカットの学習が行われないようにしているが、これはファインチューニングされたモデルでは一般的なこと。しかしながら、LLMもショートカット学習に関してはいくらかの課題を持っている(特定の状況やタスクで依然として簡易な解決策やパターンに頼る傾向がある?)。
- LLMに関連する安全性の懸念は最大限に重視されるべき。LLMからの潜在的に有害または偏見のある出力やハルシネーションは重大な結果を引き起こす可能性がある。人間のフィードバックなどの方法は、これらの問題を軽減することにおいて有望であると示されている。
おわりに
本記事では、LLM?Fine-tuning?という視点を中心にまとめてきました。より細かなユースケースや安全性、コストに関する記載など興味深い内容が論文には多数ありますので、別記事にまとめていければと思っています。
【出展元・参考サイト】
◆ The Practical Guides for Large Language Models
◆ Jingfeng Yang Blog
◆ Fine tuning is for form, not facts