Dataikuは9月14日(木)開催のDatabricks DATA+AI World Tourに出展します。Dataikuブースでお待ちしています!
技術革新のスピードが速い世界では、リーダーは組織全体でユーザーのニーズを満たす最適なテクノロジーを継続的に見つけなければなりません。高度なアナリティクスやAIが日常的なテクノロジーとなるにつれ、すべての人をサポートし、チーム間のコラボレーションを促進することが最重要課題となります。
DataikuとDatabricksがあれば、データ専門家からビジネス専門家まで、誰もがデータおよびAIプロジェクトを共同して開発し、大規模に成功させるために必要なものを手に入れることができます。このブログでは、DataikuとDatabricksの最新の統合について概説します。この統合では、データアナリストやドメインエキスパートはDataikuでSparkコードとビジュアルレシピをミックスし、Databricks上でそれらをすべて実行することが簡単にできます。
主な統合ポイントは以下の通りです。以降のセクションで詳細な例を挙げて概説します:
- Named Databricks Connection:Databricks Lakehouseに直接接続し、Dataikuのデルタテーブルを読み書きします。
- SQLプッシュダウン計算処理:DatabricksエンジンにビジュアルレシピおよびSQLレシピのプッシュダウンします。
- Databricks Connect:PythonレシピやコードノートブックにPySparkコードを記述し、Databricksクラスタ上で実行します。
- MLFlowモデルの交換:過去に学習したMLFlowモデルをDatabricksからDataikuにインポートし、Dataikuに保存したモデルとしてネイティブに評価・運用したり、Dataikuで学習したモデルをDatabricksにエクスポートしたりすることができます。
Named Databricks Connection
Named Databricks Connectionにより、DatabricksからDataikuデータセットに直接データをロードすることができます。これにより、ビジネスユーザーはLakehouseのデータにアクセスできるようになります。この直接接続では、データがDatabricksから離れることがなく、ユーザーはLakehouseのセキュリティーとガバナンス機能を活用することができます。また、Databricksと他のデータソース間のデータのロード/アンロードには、Syncレシピを使用することができます。
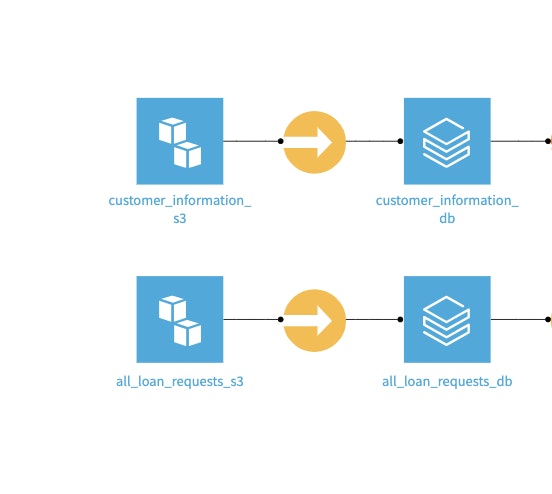
S3バケットからDatabricksへのロード/アンロード例
SQLプッシュダウン計算処理
Databricksへの読み書き機能を使い、DataikuのビジュアルレシピやSQLレシピのすべての計算処理をDatabricksクラスタにプッシュダウンできるようになりました。つまり、ビジュアルレシピやコードレシピを使用してDataikuで開発された高度な分析パイプラインをDatabricksで処理できるようになります。この機能は、Dataikuがすべての人のためのプラットフォームであることを特徴付けています。開発者は、Dataikuのビジュアルレシピを活用して同僚と協働でき、またそのためにコードを書くことができます。いずれにせよ、Databricksの計算能力を活用することで、パイプライン全体が最適化されます。
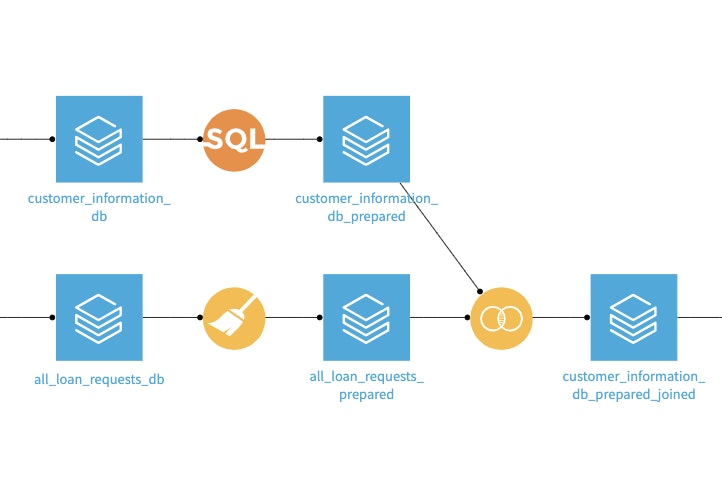
Dataikuのビジュアルレシピもコードレシピも、Databricksのコンピュート機能を活用
Databricks Connect
Databricksが発表したDatabricks Connectにより、開発者はリモート環境(Dataikuのコードレシピやノートブック)でPySparkコードを記述し、Databricks上で実行できるようになります。我々のPython APIを通じてシームレスに統合されたDataikuは、既に確立されたDataiku接続を参照することで、Databricksクラスタに接続することができ、毎回クレデンシャル情報を入力する必要がなくなります。データセットをデータフレームとして読み込んだ後、使い慣れたPySparkコードを記述してデータ処理を実行します。
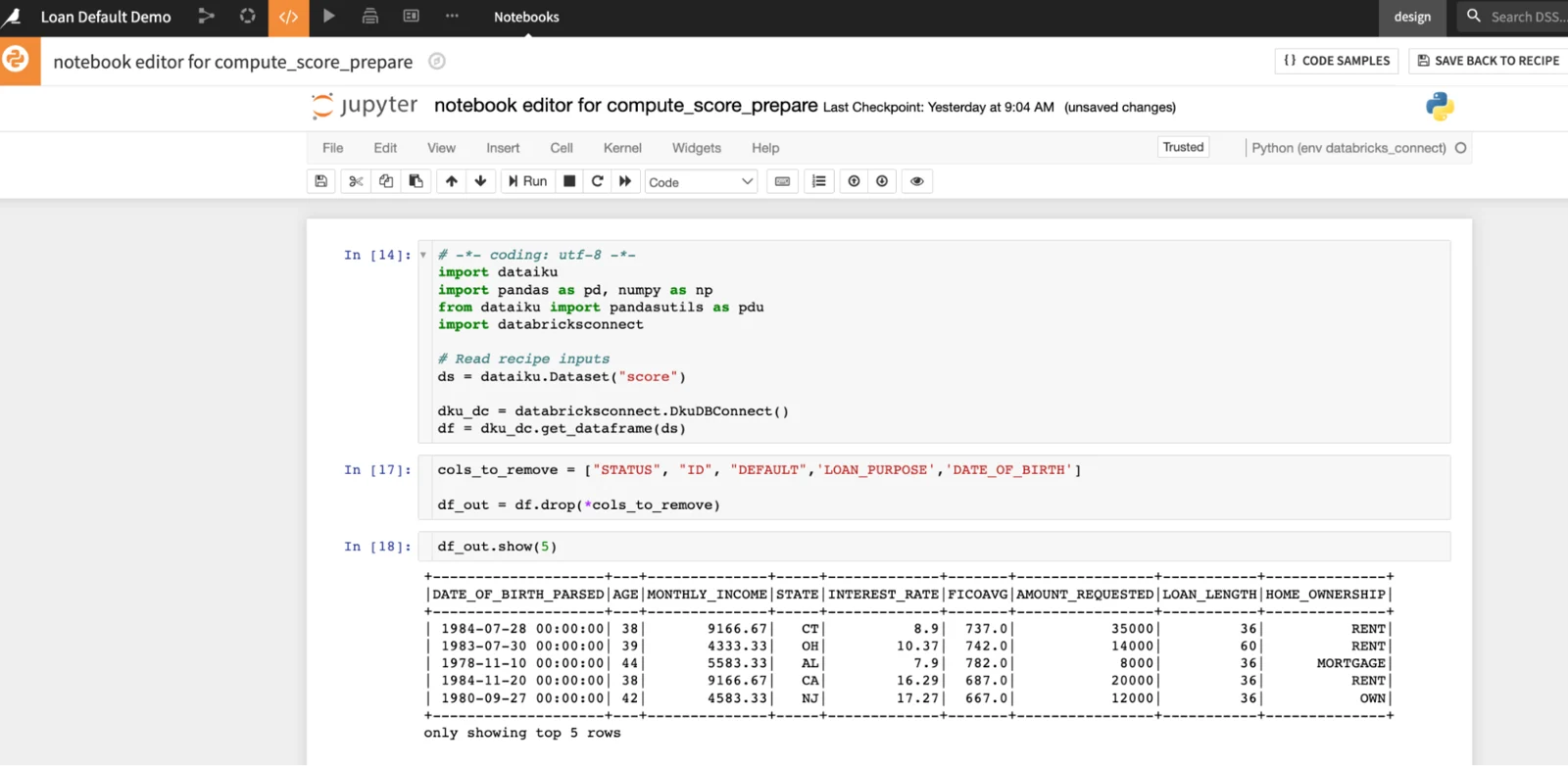
JupyterノートブックにPySparkコードを書きDatabricksで実行
MLFlowモデルの交換
MLFlowで学習したモデルをDataikuにインポートすることで、DataikuのすべてのML管理機能を利用することができます。ワークフローとしては、Databricksでモデルをトレーニングし、APIコールで登録されたモデルを取得し、Dataikuの保存モデルとしてMLFlowをインポートします。
保存されたモデルとして、新しいデータをスコアレシピでスコアリングしたり、モデルのパフォーマンスを評価したり、複数のモデルや複数のバージョンのモデルを比較したり、データやパフォーマンスのドリフトを分析したりすることができます。双方向のデプロイメントパターンは、Visual MLでDataikuモデルをトレーニングし、MLFlowモデルとしてエクスポートしてLakehouse環境にデプロイすることもできます。
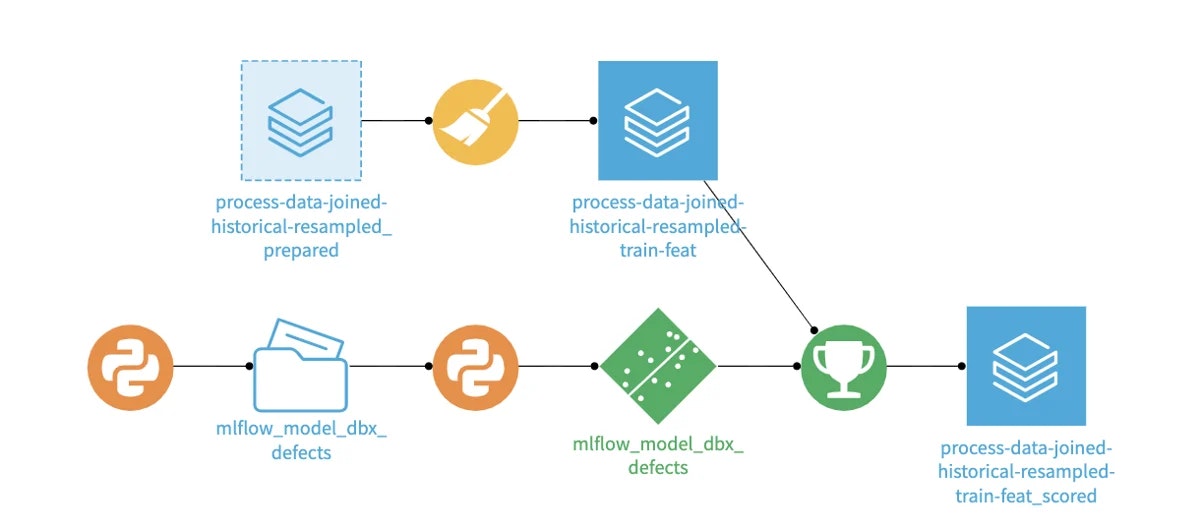
Databricksから以前に学習させたモデルをインポートし、Dataikuの新しいデータでスコアリング
すべてをひとつに
このハウツーガイドでは、DataikuとDatabricksの補完しあうテクノロジーが、いかにデータエキスパートとドメインエキスパートを統合するためのベストインブリードスタックを提供するかをお話ししました。Dataikuのコラボレーションを促進するインターフェースとDatabricksの強力な計算処理およびストレージ機能を組み合わせることで、実用的なビジネス成果がすぐそこまで来ています。ユーザーや彼らの知識やスキル、データを活用しないままに置き去りにするようなことはありません。
さらに詳しく知りたい方へ
このビデオ(英語)では、Dataiku + Databricksを使用したアナリティクスライフサイクルの各パートを紹介します。また、シンプルなデータ準備から高度な開発パイプラインまで、あらゆる場面でLLMを使用しています。