この3回シリーズの最初のブログ記事では、機械学習(ML)のためにデータ準備について取り上げました。このデータ準備には、データのクリーニング、特徴の選択、特徴の取り扱いとエンジニアリングが含まれます。準備作業は一段落したので、次は実際にモデルを構築し、評価する作業に入リます。モデル解釈については、次回の連載で取り上げます。
モデルを構築する
最初に作るモデルは、ベースライン、つまり、単純だが、きちんとした結果が得られる可能性の高いモデルであるべきだ。ベースラインモデルの構築は迅速であり、多くの場合、必要な場所への道のりの90%を得ることができます。実際、ベースラインモデルがあれば、目の前の問題を解決するのに十分かもしれないです。精度が90%なら、精度を95%にすることに集中すべきでしょうか?それとも、より多くの問題を90%の精度で解決する方が時間を有効に使えるでしょうか?答えは、ユースケースとビジネスの文脈に大きく依存します。

AutoMLは、機械学習を適用するプロセスを自動化するツールであり、迅速に基本的なモデリングを簡単に行うことができます。経験豊富なデータサイエンティストでさえ、AutoMLを活用して作業を効率化しています。例えば、Dataikuでは、ツールがあなたに代わって多くの最適化された選択を行うAutoMLモードによって、モデルの詳細を制御したり、独自のアルゴリズムを書いたり、ディープラーニングモデルを使用したエキスパートモードのいずれかを選択することができます。AutoMLモードでは、Dataikuが学習するアルゴリズムの種類を定義することができます。これらにより、高速なプロトタイプ、解釈可能なモデル、または解釈可能性が低い高性能モデルのいずれかを選択できるようになります。
モデルをデザインする
DataikuのAutoMLでは、(クイックプロトタイプであっても)モデルを作成する際にいくつかの決定を下す必要があります:
1.目的変数の選択します。教師あり学習モデルを使用するので、目的変数、つまり他の変数を使用してモデルによって値が予測される変数を指定する必要があります。言い換えれば、それは我々が予測したいものです。我々の俳句Tシャツプロジェクトの場合、予測したい変数は、来月に新規顧客によって生み出されるであろう期待収益です。

2.予測タイプを選択する。ターゲット変数を識別した後、次のステップは予測タイプを選択することです。リマインダとして、予測の主なタイプそして、我々の例でそれらをどのように使用するかどうかは以下のとおりです:
-
回帰、つまり数値を予測する。我々の目的は、新規顧客へのTシャツの販売によって生み出される収益額を予測することなので、我々のサンプルモデルにとって、予測タイプとして回帰を選択することが最も理にかなっています。あるいは、同じ俳句Tシャツのデータで、少し異なる問題とターゲット変数を定式化するとしたら、代わりに分類を選ぶこともできます
-
分類とは、いくつかの可能な選択肢の中から「クラス」、つまり結果を予測することを意味します。例えば、新規顧客が "高額消費者"(例えば、1ヶ月に50ドル以上商品を購入した人と定義できる)である可能性が高いかどうかを判断したい場合、2クラス分類を使って顧客が高額消費者(クラス1)か非高額消費者(クラス2)かを予測することができます。この場合、可能性のある結果が2つあるので、これは2クラス分類になりますが、別の問題では2つ以上の結果を持つことが理にかなっているかもしれません
データのサブセットでのトレーニング
機械学習モデルを開発する際、入力と出力をどの程度対応付け、正確な予測を行うことができるかを評価できることが重要である。しかし、(例えばトレーニング中に)モデルが既に見たデータを使って性能を評価すると、オーバーフィッティングのような問題を検出することができない。
機械学習では、まず学習データをトレーニング用とテスト用に分けるのが標準的だ。分割の正確なサイズに関するルールはありませんが、トレーニング用に大きめのサンプルを確保するのが賢明です - 典型的な分割は、80%のトレーニングと20%のテストデータです。両方のデータセットに存在するパターンをうまく表現できるように、データもランダムに分割することが重要です。
アルゴリズムとハイパーパラメータの選択
異なるアルゴリズムには異なる長所と短所があるため、どのモデルを使用するかは、ビジネスの目標と優先順位に大きく依存します。そのため、どのアルゴリズムをモデルに使うかは、ビジネスの目標と優先順位に大きく依存します:
モデルの精度はどの程度必要か?不正検知のようなユースケースでは、精度が重要です。また、例えば推薦エンジンのように、成功しビジネス価値を提供するためには、それほど正確である必要はない。
解釈可能性は重要か?もし人々が個々の予測因子がどのようにレスポンスと関連しているかを理解する必要がある場合、より解釈しやすいアルゴリズム(例えば線形回帰)を選択することは理にかなっているかもしれない。
スピードはどの程度重要か?異なるアルゴリズムは、データをスコアリングするのに異なる時間を要しますが、ビジネスの文脈によっては、時間は本質的なものです(たとえ数分の1秒でも-自動車保険の見積もりを取ることを考えてください)。決定木は通常、高速かつ正確であるため、基本的な選択肢として適しています。
また、ライブラリーの概念を理解することも重要です。ライブラリーとは、特定の言語で記述されたルーチンや関数のセットであり、何行ものコードを書き換えることなく、複雑なMLタスクを簡単に実行できるようにするものです。例えば、Dataiku AutoMLは4つの異なる機械学習エンジンをサポートしています:
- In-memory Python (Scikit-learn / XGBoost)
- MLLib (Spark) engine
- H2O (Sparkling Water) engine
- Vertica
アルゴリズムを選択するだけでなく、MLモデルを構築するもう一つの側面は、ハイパーパラメータのチューニングである。ハイパーパラメータは、学習プロセスを制御するために使われるパラメータで、機械学習モデルの設定だと思ってください。ハイパーパラメータは、MLモデルの全体的な振る舞いを制御するので重要であり、ハイパーパラメータをチューニングまたは最適化することで、モデルのパフォーマンスを向上させることができます。
ハイパーパラメータの最適化を行うことは、時間の制約の中で可能な限り最良のモデルを探索することです。探索空間を絞り込む1つの方法は、どのハイパーパラメータが最も重要かを研究し、それに集中することです。与えられた機械学習タスクでは、いくつかのハイパーパラメータの値を変更することで、他のハイパーパラメータよりも性能に大きな違いが出る可能性が高いです。したがって、これらのハイパーパラメータの値を調整することが、最大の利益をもたらします。
ハイパーパラメータの最適な組み合わせを見つけるのは本当に難しく、その方法を明らかにすること自体がトピックになり得るので、このガイドの範囲外です。ベースラインモデルの場合、AutoMLは最も有望なハイパーパラメータ最適化の可能性に素早く焦点を当てることで、限られた時間でより良いモデルを構築するのに役立ちます。
モデルの評価
データに接続し、それを探索し、クリーニングし、簡単なモデルを作成した。さて続いてどうすれば良いでしょうか?そのモデルが良いものかどうか、どのように判断すれば良いでしょうか?そこで、異なるアルゴリズム間でモデルのパフォーマンスを追跡・比較する必要があります。
指標の評価と最適化
機械学習モデルを評価するための指標は、回帰モデルか分類モデルかによっていくつかあります。また、ほとんどのアルゴリズムでは、モデル学習中に最適化する特定のメトリックを選択することも注目に値します。しかし、その評価指標は、モデルがどの程度うまく機能するかを実際に判断するための他の評価指標ほど解釈しやすいものではないかもしれません。
回帰モデルについては、平均2乗誤差とR2乗(R2)に注目したい
- 平均2乗誤差は、すべての誤差の2乗を計算し、すべてのオブザベーションにわたって平均することによって計算される。この数値が小さいほど、予測がより正確であることを意味します
- R2(R-Squared と発音)は、モデルによって説明される(つまり予測される)平均からの観察された分散のパーセンテージです。R2は常に0と1の間にあり、数値が高いほど良いといえます
分類モデルの場合:
- モデルを評価するための最もシンプルな指標は精度である。精度は一般的な言葉ですが、この場合、我々はそれを計算する非常に特殊な方法を持っています。精度は、モデルによって正しく予測されたオブザベーションのパーセンテージです。精度は理解しやすいですが、特に予測するさまざまなクラスがアンバランスな場合は、注意して解釈すべきです
- もう1つの指標は,ROC AUCで,これは正確さと安定性の尺度である.一般的にROC AUCが高いほど、より良いモデルであることを意味する
- 対数損失(log loss)は、Kaggleが運営するようなコンペティションでよく使われる指標で、分類モデルが厳密な分類(例えば、真と偽)ではなく、クラスメンバーシップ確率(例えば、真である確率が10%、真である確率が75%など)を出力する場合に適用されます。対数損失は、モデルが高い信頼性で行った間違った予測により重いペナルティを適用します
オーバーフィットと正則化
オーバーフィッティングについては前のセクションでも触れましたが、予測モデルを構築する際の最大の課題の1つになる可能性があるため、ここでもう一度詳しく説明します。一言で言えば、トレーニングセットを使ってモデルをトレーニングするとき、モデルは予測を行うためにトレーニングセットの基本パターンを学習します。
しかし、モデルはまた、予測価値を持たないデータの特異性も学習します。そして、その特異性が予測に影響を及ぼし始めると、トレーニングセットの説明がうまくなりすぎて、テストセットでの(そして新しいデータでの)パフォーマンスが低下する。正則化とは、基本的にモデルを単純化し、より専門的でないものにすることです。
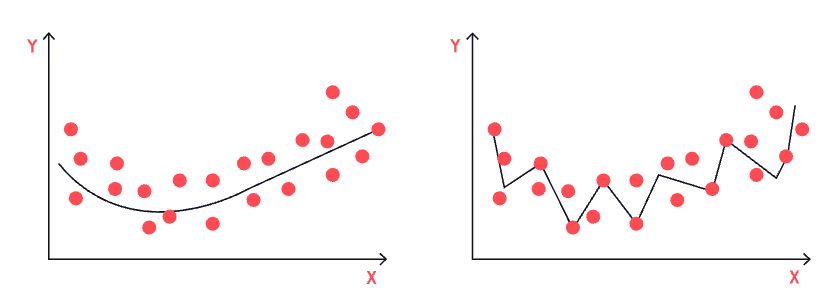
右側は、オーバーフィッティング、つまりモデルがうまく訓練されすぎている場合の視覚的表現である(左側のモデルはロバストでフィットしている、つまりちょうどいい!)。
線形回帰では、正則化はL2正則化とL1正則化の形をとります。これらのアプローチの数学は、このガイドの範囲外ですが、概念的にはかなり簡単です。y = C1a + C2b + C3c...というモデルで、たくさんの変数とたくさんの係数を持つ回帰モデルがあるとします。L2正則化が行うのは、係数の大きさを小さくすることで、個々の変数の影響をいくらか弱めることです。
ここで、小さいけれどもゼロではない係数を持つ変数が、何十個、何百個、あるいはそれ以上とたくさんあるとします。L1正則化は、これらの変数の多くが単なるノイズであるという仮定のもとで、これらの変数の多くを排除します。
決定木モデルの場合、正則化は木の深さを設定することで達成できる。深い木、つまり多くの決定ノードを持つ木は複雑になり、深ければ深いほど複雑になる。ツリーの深さを制限し、浅くすることで、精度は多少落ちますが、より一般的になります。
次回はモデルの解釈について説明します!
Dataikuをさらに使いこなす準備はできましたか?
DataikuでビジュアルMLを始めたい人のために設計された、機械学習の基礎に関するDataikuアカデミーのコースはこちらから受講できます。
原文:Data Basics, Use Cases & Projects, Dataiku Product, Featured