5年前まで機械学習におけるバイアスはほとんど語られなかったのが、最近では頻繁に見出しを飾るようになり、自動化プロセスが導入され望ましくないバイアスの新しいケースが頻繁に発見されています。しかし、このようなデータの偏りを防止し、評価するための「唯一無二」の標準的な機械学習ツールはまだありません。今回は、機械学習アルゴリズムの不公平さをどのように説明するかを扱います。
2014年、「Big Data: Seizing Opportunities and Preserving Values」という報告書の中で、オバマ大統領の執行部は、「ビッグデータ技術は、個人やグループに対する差別など、プライバシーへのダメージを超えた社会的な害を引き起こす可能性がある 」と指摘しました。これは、機械学習における不公平さが潜在的な害として公式に認識された初めての出来事でした。
それ以来、私たちは機械学習のユースケースにおける不公平な事例を数多く観察することができるようになりました。2015年、Amazonは機械学習を利用した求職者評価ツールが女性にバイアスがあることが判明したため、そのツールを停止しました。このモデルは、テクノロジー関連の仕事に就く女性が少ないことを学習し、このバイアスを否定的に解釈していたのです。2016年には、独立系雑誌「ProPublica」が、米司法省が裁判で受刑者を評価するために使用している再犯率予測モデルが、黒人に対してバイアスがあることを発見しました。
不公平さは、あらゆる機械学習プロジェクトの根幹であるデータで説明できます。というのも、データ自体に私たち自身のバイアスがかかっていることが多いからです。ここでは、「限定された属性」、「歪んだサンプル」、「汚染されたサンプル」、「サンプルサイズの格差」、「プロキシ」、「マスキング」という6つの不公平の原因に注目します。
語彙の整合性
この記事では、入力データと出力データの両方を修飾するために「データ」という言葉を使用します。入力データは、機械学習モデルが学習結果を出力するために必要なデータとなります。
限定された属性
機械学習は、与えられた課題について相当数の観測データを収集し、これらの例から学習することを基本としているため、代表性のないデータでモデルを学習した場合はどうなるでしょうか。
データ収集時にエラーが発生することはあっても、最適なデータ収集ワークフローでは、観測データ間のエラー分布はホワイトノイズに限りなく近く、つまり特定の観測データに関係なく均等に分布するはずです。実際には、ケイト・クロフォード教授が示したように、『すべてのデータが平等に作成されるわけでも、収集されるわけでもないため、大きなデータセットには「Signal Problems」があり、一部の市民やコミュニティが見落とされたり、十分に表現されない「ダークゾーン」が存在します』。
私たちのデータ収集は、設計上、洗練された現実の現象を部分的にしか捉えることができません。そのため、サブグループ間の差異を捉えるのに十分な粒度のデータが得られず、結果的にそのようなグループを観察する際のデータの質が低下してしまいます。このようなデータ品質の違いは、モデルの性能に直接影響を与えます。データ品質の低いモデルは、亜集団に偏ってしまう可能性が高いのです。
このような属性が限定されたデータとその影響の例として、自動車保険の価格設定が挙げられます。ある人の自動車保険の契約価格は、その人と似たような人たちの事故のリスクに基づいています。このようなクラスタリング・アプローチによって生じる公平性の問題は、もしその人が自分のクラスタの平均的な人々よりも良い運転をしたとしても、その人の保険料は他のグループと同じになってしまうということです。

属性が限定された状態を表す図。形状は類似した人々のグループを定義し、赤と緑はそれぞれ運転が不得手と得意の人を表しています。実線は「不公平」なバイアスのかかったクラスタを、破線は「公正」なクラスタを定義しています。
歪んだサンプル
第二の不公平性の原因はサンプルの偏りです。属性の限定など他の不公平感の原因により既に偏っているデータ収集プロセスを使用することによる結果です。このような偏ったデータ収集プロセスは、偏ったモデルにつながる可能性があり、そのようなモデルに基づいてビジネス上の意思決定を行った場合、その結果が悪影響を及ぼし、このデータの偏りを強化することになります。これは、偏ったフィードバックループと呼ぶことができます。
実際、偏った分布からのサンプリングが、頻度の低い観測値を除外することで偏りを強化するのと同じように、偏ったモデルは比較的富裕層に対してのみ最高のパフォーマンスを発揮し、その出力は富裕層以外を除外する傾向があります。このような偏ったモデルに基づくビジネス上の意思決定がデータ収集プロセスに影響を与えると、収集された情報はますます富裕層に集中することになります。その結果、不公平感が増大し続けるという悪循環に陥ってしまいます。
このような偏ったフィードバックループを実際に説明するために、「Google Flu Trends」の失敗を例に挙げることができます。Google Flu Trendsは、Googleが開発した機械学習モデルで、検索データを利用してインフルエンザの発生の強さを測定するものです。しかし、このモデルは2009年のA/H1N1インフルエンザのパンデミックの検出に失敗し、その後、2011年から2014年にかけてインフルエンザの発生を過大評価し続けていました。
この研究の筆頭著者であるDavid Lazerらは、この過大評価は、Googleの検索提案サービスの内部変化によって引き起こされたと示唆しています。このサービスでは、健康な人にインフルエンザ関連の検索を提案するようになりました。その結果、インフルエンザ関連の検索数が大幅に増加し、検索サジェストサービスの変化が結果的に2011年から2014年の間のインフルエンザ発生検出の偏りを大きくしたと考えられます。
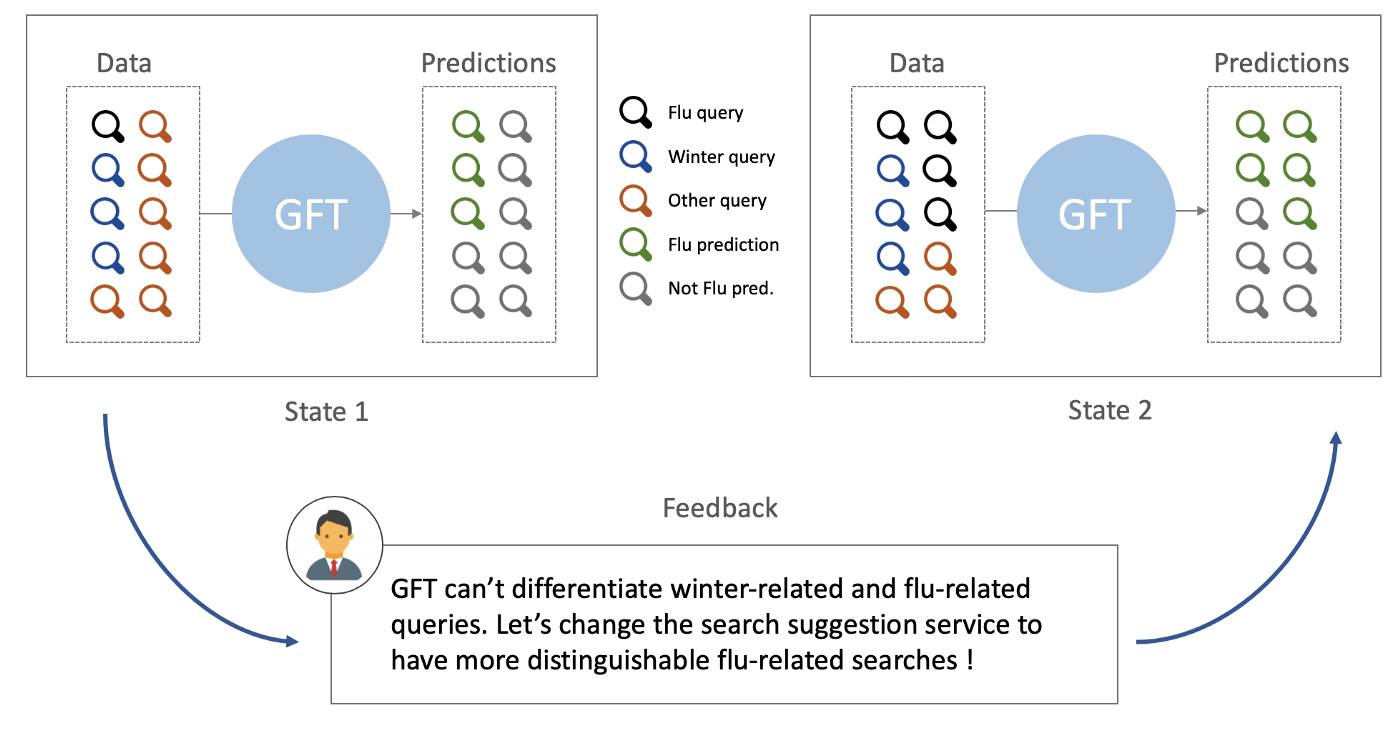
Google Flu Trendのフィードバックループの説明図です。
汚染されたサンプル
教師あり学習タスクでは、分類タスクのターゲットが正しいことはもちろん重要です。しかし、ターゲットが十分に定義されていなかったり、特徴が偏っていたりするとどうなるでしょうか?
実業務でターゲットを定義することは、猫と犬の間に線を引くように簡単なことではありません。
「実際のユースケースでは、人々はしばしば恣意的な判断に基づいてターゲットを作らなければなりません。」
これを説明するために、アマゾンのような多くの企業が、膨大な数の候補者がいる中で、求職者を自動的に選別する必要があることを考慮します。モデル作成プロセスでは、各候補者の特徴(最高学歴、出身校、経験年数など)をまとめて計算し、その候補者が良いかどうかを記述したターゲットを使用します。しかし、この基準は絶対的なものではないため、モデル設計の担当者がこのターゲットを作成する必要があります。
ターゲットの例としては、候補者が採用されたかどうか(二元分類の場合)、また採用後の実務での評価(連続予測の場合)などが考えられます。どちらのターゲットも候補者の選別に使用でき、2つ目のターゲットは採用担当者が候補者をランク付けすることさえ可能です。しかし、どちらのターゲットも人間の評価に基づいており、人種に偏りがある可能性があります。このことは、Stauffer & Buckleyが、仕事の評価で黒人に対してバイアスがあることを実証しました。この例では、モデルがこのバイアスを学習し、それを再現することで、黒人を差別した採用活動を行うことになります。
モデルで使用される特徴についても、同様の挙動を示すことができます。このようなバイアスの伝達の証拠は、w2vNEWS自然言語処理モデルに見られます。Bolukbasiらは、Google Newsで学習したw2vNEWSが生成した単語埋め込みが「女性/男性のジェンダー・ステレオタイプを気になるほど示す」ことを証明しました。これは、モデルがコラムニストが男性と女性について書く際のジャンル・バイアスを捉えていたためです。下の図は、「彼女」と「彼」にそれぞれ最も近い職業を表示しています。公正なモデルでは、ほとんどの職業が両方の性別代名詞に同じように近いはずです。
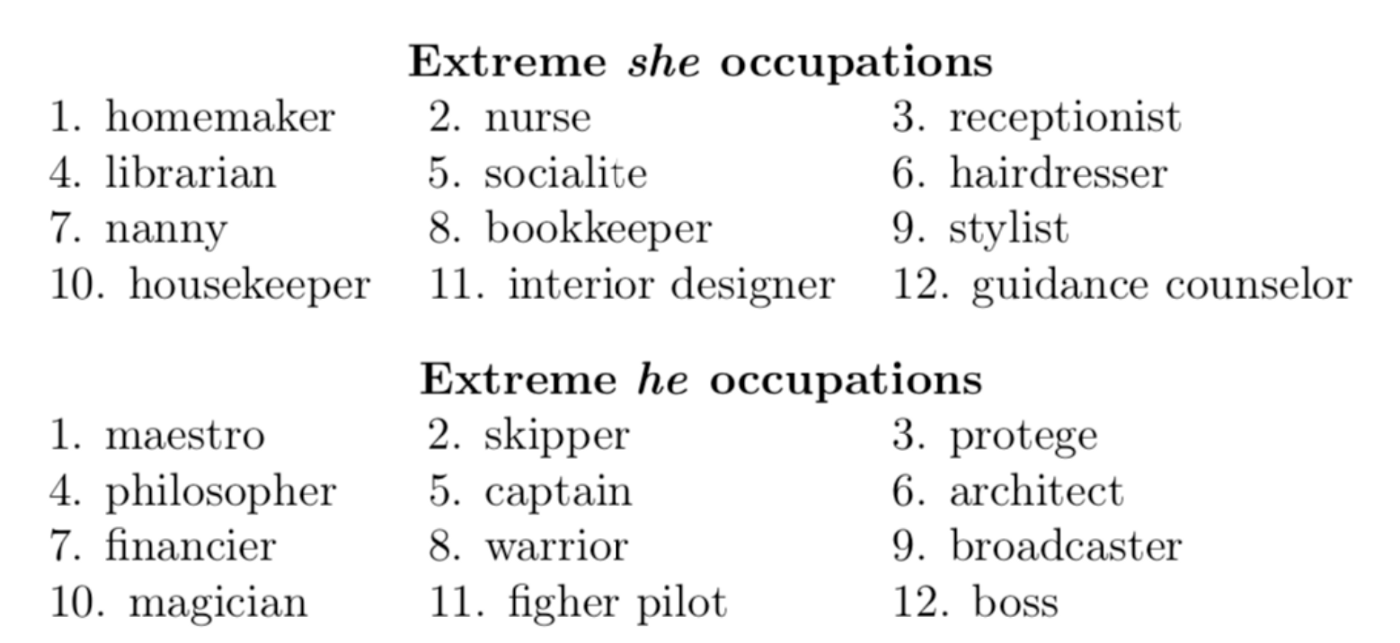
女性に対するw2vNEWSの単語埋め込みデータの偏りの図解(2016年)。
サンプルサイズの格差
これまでの例がすべて偏ったトレーニングデータに基づいていたことを考えると、すべての公平性の問題は、モデルに取り込まれた固有のデータの不公平さに帰着するということでしょうか?
これは必ずしもそうではありません。例えば、完全に偏っていないデータにアクセスできたとして、そのデータが不均衡であると仮定すると、データセットの中にサイズの違う部分集団があることになります。
Moritz Hardt氏は、ある特徴量のセットに対して、「分類の誤差は、サンプルサイズの逆平方根として減少することが多い。4倍のサンプル数があれば、エラーレートは半分になる」としています。
「パフォーマンスの問題は、公平性と関連しています。なぜなら、実際には、マイノリティグループで利用できるデータは一般的に少ないからです。その結果、モデルは、マイノリティグループで一般化できない場合、全体の人口よりもパフォーマンスが悪くなる傾向があります。」

異質な集団をガウス混合物としてモデル化し,EMアルゴリズムを用いてそのパラメータを学習させる。すると予想通り,小さいグループの推定値は,大きいグループの推定値よりも大幅に悪くなっています.赤い破線の楕円は,推定された共分散行列を表している.緑の実線は,正しい共分散行列を示している.緑と赤の十字は,それぞれ正しい平均値と推定された平均値を示す(Moritz Hardt).
実際には,分類に用いた特徴が,多数派グループと少数派グループで異なる動作をしたり,逆の動作をしたりする場合には,サンプルサイズの格差が悪化する可能性があります.
同じ特徴のグループ間の相関関係が逆転していることを示す例として,2011年のGoogle Nymwarsスキャンダルが挙げられます.GoogleはGoogle+で実名制を導入しようとしましたが、アルゴリズムは白人系アメリカ人の名前と構造が異なるため、少数派の名前を偽名と予測する傾向がありました。この違いは、白人の名前は名字と名前で構成されたごく標準的なものであるのに対し、少数派民族系の名前ははるかに多様で、単音の場合もあることから説明できます。
プロキシ
これまで述べてきた不公平感の原因は、人に影響を与える可能性のある機械学習モデルをトレーニングする前に、データを慎重に選択する必要があることを強調しています。しかし、保護されているセンシティブな属性(性別、人種など)を取り除いたとしても、機械学習モデルは、マイノリティのクラスでは、全体の人口に比べてパフォーマンスが低下することがあります。このようなパフォーマンスの違いは、残った特徴が保護された属性の代理として機能する場合に説明できるかもしれません。
この現象は「冗長エンコーディング」と呼ばれ、保護された属性がデータセット内の1つまたは複数の特徴にまたがって埋め込まれているため、保護された属性の除去が無意味になることを意味します。この場合、汚染された例が起こるのと同じように、モデルは既に存在する不平等を捉え、それを再現するように学習します。このようなエンコーディングの例として、ニューヨーク市では、世帯収入が人種の強力なプロキシとして使用できることが挙げられます。
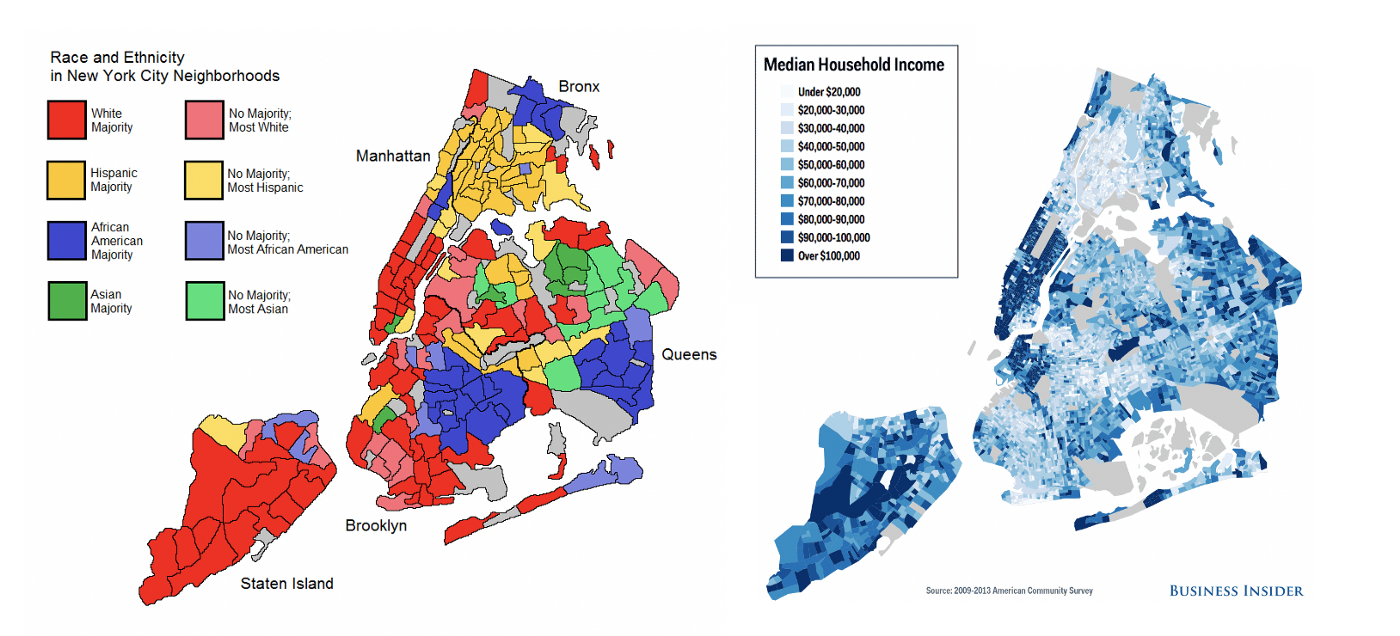
ニューヨーク市における人種・民族と世帯収入(中央値)の比較。
難しいのは、プロキシが1つの特徴だけで構成されているのではなく、複数の特徴の組み合わせで構成されている可能性があり、それによって検出が難しくなっていることです。例として、Yeom、Datta、Fredriksonは、C&Cデータセット(米国の国勢調査とFBIの犯罪報告データから構成される)に基づいて、コミュニティごとの犯罪率を予測しようとしました。彼らは、全122件のうち人種との関連が明示されている32件の特徴を削除しても、残り90件のうち58件の特徴の組み合わせからなる人種のプロキシーになる属性を見つけることができました。
このプロキシの人種との関連性は0.85であったのに対し、データセットの中で最も強い関連性を持つ1つの特徴は0.73の関連性しかありませんでした。何十もの特徴の組み合わせをチェックしなければならないため、実際にプロキシを特定するのは非常に難しいです。
プロキシに関する2つ目の問題は、限定された属性を扱う場合に発生します。これまで説明してきたように、限られた機能では、マイノリティグループに関連する特定の行動を明確に説明できるだけの粒度がデータにないため、バイアスが生じます。しかし、マイノリティクラスのデータの粒度を上げることで、モデルは既に存在する差別の望ましくないパターンを発見し、それを悪影響として学習する可能性があります。
マスキング
先に挙げたデータバイアスの原因は、いずれもデータ収集時に意図せずにバイアスが入ってしまったことを想定していました。しかし、BarocasらとDworkらは意図的なバイアスの原因を強調することに注力しています。この最後のバイアスの原因はマスキングと呼ばれ、ある特定の集団を自発的に差別するために、事前に挙げたバイアスの原因のすべてを意図的に使用することで構成されます。
悪意のある人にとって、マスキングは様々な方法で実施できるという利点がありますが、そのすべてが発見されにくいものです。彼らは、データ収集プロセスに偏りを持たせて、結果として得られるモデルが望ましい偏りを示すようにすることもできるし(歪んだサンプルを使用)、また、既に存在するプロセスの結果を、本来ならば公正で公平な特徴として使用することで、不公平さを維持することもできる(汚染された例を使用)。
また、マイノリティグループの特定の行動を識別できないような一般的な機能を使用して、結果的にマジョリティグループにのみ有効なモデルを作成することもできます(限定的な機能を使用)。
結論
ここでは、機械学習における不公平感の原因として、6つの可能性を紹介してきましたが、いずれも後続モデルの学習に使用されるデータに根ざしています。もちろん、このようなデータの偏りは、そのモデルが何を学習するかにとどまらず、より深い社会的な影響を及ぼします。
機械学習アルゴリズムは、例えば求職者の順位付けなど、人間の手動プロセスを自動化するためのバイアスのない正当な方法と考えられがちです。人間のプロセスに潜むバイアスを学習することで、モデルはこのデータのバイアスを検出されることなく再現することができます。
しかし......私たちは、どのような状況においても、不公平さを明示的に定義したことはありません。これは、機械学習アルゴリズムで不公平さを検出するために必要なことで、次回のブログ記事「公平さとデータ」のテーマになります。