このブログは、2部構成のシリーズの第2部です。プロジェクト全体のゴール、データ準備のステップ、最初のモデル作成については、この記事を読む前にパート1をご覧ください。ブログの第2部(最終回)である本稿では、予測モデルの作成と、本番稼働しているデータプロジェクトの維持について述べています。とくにお伝えしたいのは、第1部でご説明したスコープと同様に第2部のこのスコープでも引き続き、コードを書かずにデータから洞察を得られるということです。

モデルのテスト
モデルをテストする前に、タスクを定義しましょう。特徴量抽出とクレンジングの後、60列と85,000行のデータを持っていたとします。最も重要な列は、ターゲット変数である "on-time-delivery"で、各行は "on-time"(定刻)か "missed delivery window"(配送遅延)のいずれかのデータを持ちます。このユースケースにおけるゴールは、偽陰性を最小にするモデル(またはモデルのアンサンブル)を見つけることです(つまり、配送要求が配送指定時間内に間に合う確率が50%より若干高いというようなケースでも、モデルは配送遅延と分類しても構わないということです)。
Dataikuには、機械学習(ML)モデルを視覚的に作成するための機能が驚くほど豊富に用意されています。もちろん、コードのためのオプションも備えています。DataikuでJupyter Notebooksを使うためのチュートリアルをご覧ください。
モデル設計
モデルテストは2段階に分けて実施します。まず、Dataiku AutoMLを使用して、ベースラインモデルを作成します。次に、ベースラインモデルを調べ、カスタマイズします。
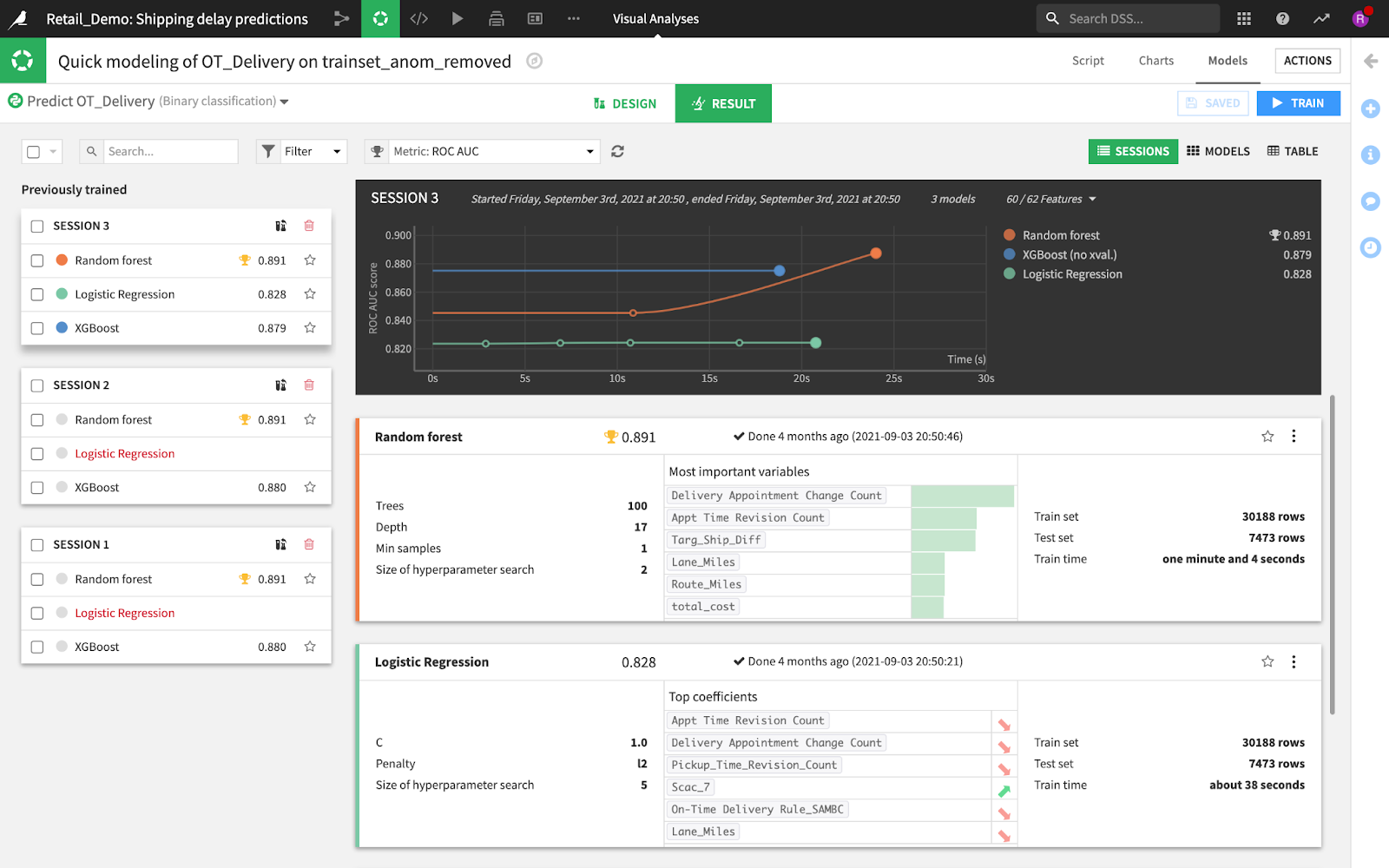
AutoMLが作成したベースラインモデルを見て、まずは、自動的に選択されたモデルに対してデータがどのように反応するかを理解しましょう。Dataikuでは、各モデルの実行をセッションで区分しており、AutoMLが作成したモデルは常にセッション1です。セッション2と3は、モデルへのその後の変更を反映したものです。ランダムフォレストのROC AUCは0.891であることがわかりますが、これはどういう意味なのでしょうか? Dataikuでは、ユーザーは単にモデルを作成するだけでなく、モデルの説明性についても情報を得ることができます。
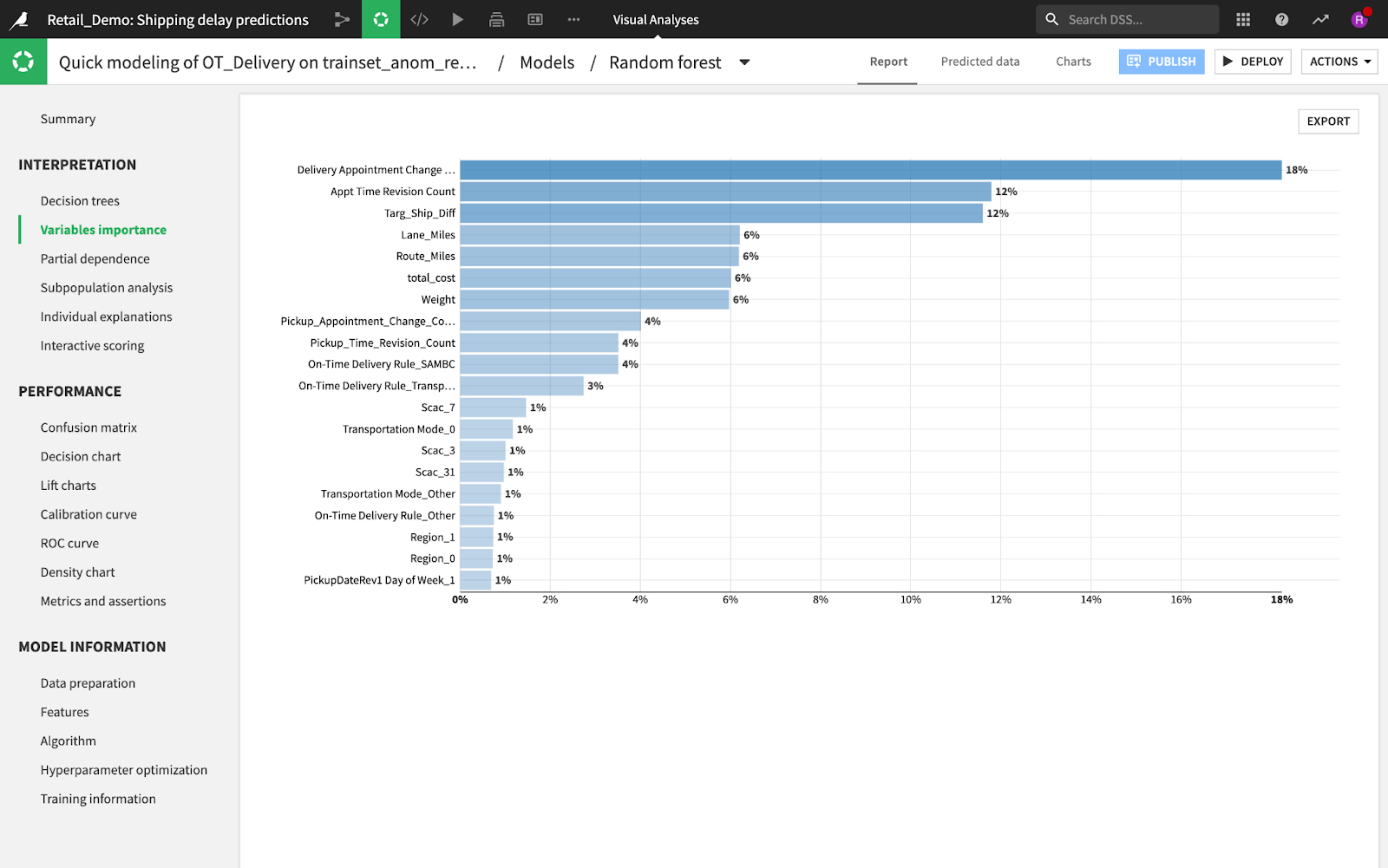
Dataikuは責任あるAIに広くコミットしているため、このブログではカバーしきれないほど素晴らしいモデルの説明性の機能がたくさんあります。これについて、ぜひモデルの説明性に関するこちらのページをブックマークください。
モデルの説明性は、新しいデータにうまく反応するモデルを作るのに役立ちます。たとえば、上記のスクリーンショットは、定刻通りの配送を予測する際に、最も重要な変数の上位のものを示しています。このケースの場合、配送予約が変更された回数が、指定時間内に配送が完了するかどうかに大きく影響していることがわかります。
モデルアンサンブル
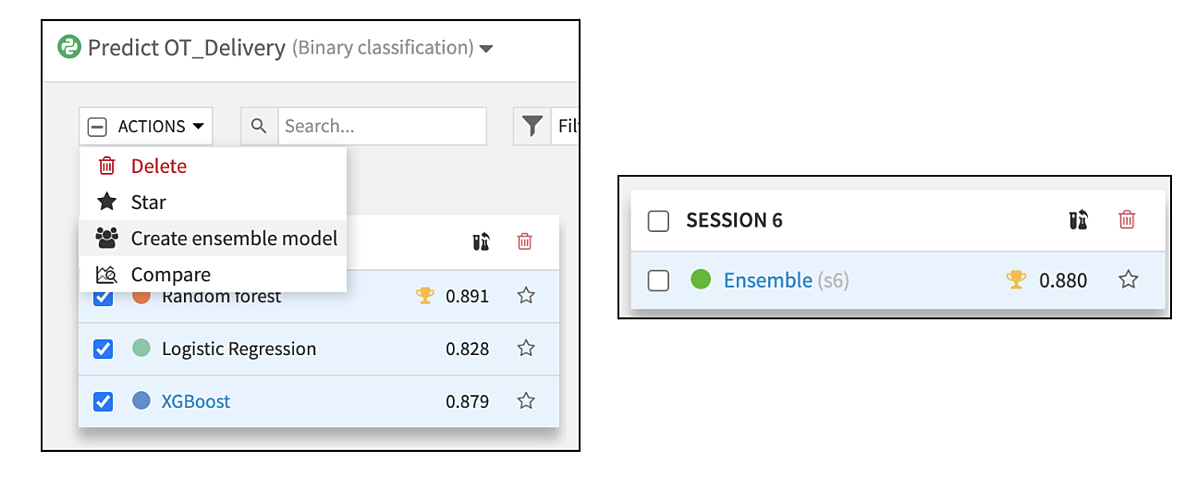
3つの分類モデル(ランダムフォレスト、ロジスティック回帰、XGBoost)が作成され、各モデルのROC AUCは妥当なものでした。3つのモデルから選択する代わりに、これらをアンサンブルすることができます。これは、"群衆の知恵"を利用するようなものです。優れたモデルの集合体から得られる予測は、単一のモデルよりも優れている可能性が高いのです。
一般に、アンサンブルモデリングは上級者向けです。しかしDataikuでは、モデルを選択し「アンサンブルモデルを作成」をクリックするだけで、新しいモデルを作成し学習パイプラインに展開することができます。
MLOps
満足のいくモデルができたら、次の論理的なステップはMLOpsです。MLOpsとは、モデルを本番環境にデプロイし、維持することです。データプロジェクトにおいては、MLOpsが、そのプロジェクトが行き詰まり学術的な探求のひとつで終わるのか、あるいはコスト削減、収益創出、またはそのどちらにも具体的に貢献するプロジェクトになるのか、の分かれ目となります。
このブログはビジネスアナリストを対象としているため、ピンとこない方もいらっしゃるかもしれませんが、DataikuはMLOpsのための機能をフルセットで提供しています。各企業のMLOps戦略は、全社的なITポリシーや企業のインフラ戦略、プロジェクト自体の特定のゴールによって異なります。本番環境にプロジェクトをデプロイし維持するためには、自動化とAPIエンドポイントという2つの重要なコンポーネントが存在します。自動化とは、データパイプラインのスケジューリングとデータのドリフトを監視することを指します。APIエンドポイントとは、その名が示すように、予測モデル(複数のモデルの場合もあり)をREST APIエンドポイントとしてデプロイするプロセスです。DataikuによるMLOpsの詳細について関心のある方は、こちらのビデオやDataikuアカデミーのMLOpsプラクティショナーコースをご覧ください。
まとめ
2つのブログを通して多くのことをご紹介しましたが、Dataikuでできることのごく一部に過ぎません。最後に、重要なステップとゴールについてまとめます。重要なステップとは、広範なデータの探索と準備、モデルのテスト、そして最後に、トレーニングパイプラインにアンサンブルモデルをデプロイすることです。ゴールは明確で、配送遅延の数を減らすのに役立つ機械学習モデルを作成することでした。最後になりますが、説明したすべてのステップで、コードの経験がまったく必要なかったことに留意ください。データの探索から高度なモデルの作成まで、反復的で協力し合える作業だったといえるでしょう。
Dataiku + サプライチェーンについてさらに興味のある方
サプライチェーンやロジスティクスにおけるAIアプリケーションとユースケース(そしてDataikuがどのように役立つか)について、こちら(英語)をご覧ください。
原文:Empowering Supply Chain Analysts With No-Code Machine Learning