こちらの記事に掲載した内容について、2021/8/19(木)にWebinarを開催いたします。Dataikuってどうだろうとご関心を持ってくださった方、ぜひご参加ください!
2021年の桜の開花日をDataiku DSSを使って予測してみました。大分県では3月22日、東京都では3月21日、青森県では4月21日に咲くらしいです。予測にはランダムフォレストを使ったので、モデルをRandom Sakura Forestと命名しました。
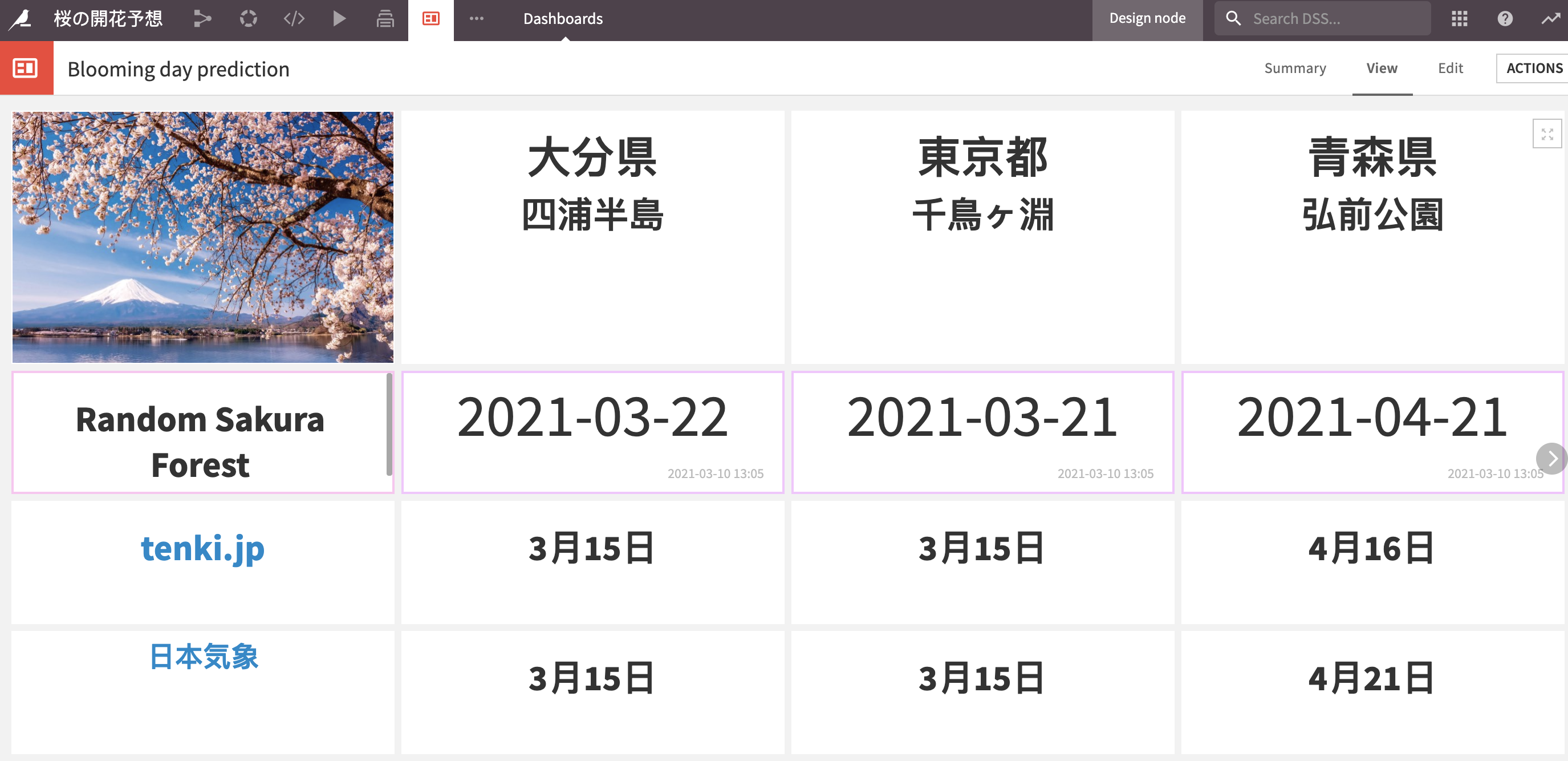
専門家の予測と比べると…
日本気象株式会社およびtenki.jp(日本気象協会)の予想と比べると、Random Sakura Forestは2社よりも0〜7日遅い予測を叩き出しています。
私の予測が正確かどうかの判断は花が開く日を待つとしましょう。それはさておき、Dataiku DSSを使う良さは毎日自動で予測を更新してくれる点にあります。これにはDataiku DSSの自動化ツールが役に立っています。
またRandom Sakura Forestは将来の天気予報を一切使わずに、過去の気象情報だけで予測するという荒業をやってのけました。というわけで、このブログではDataiku DSSでどう予測モデルを組み立てたかを説明します。
Dataiku DSSについて
Dataiku DSSはデータ分析プロジェクトを手助けするための企業向けツールです。フランスのDataiku社が開発し、データ収集から加工、分析、機械学習、モデルのデプロイメントまで一貫してひとつのプラットフォームで完結できるプラットフォーム型のツールになっています。
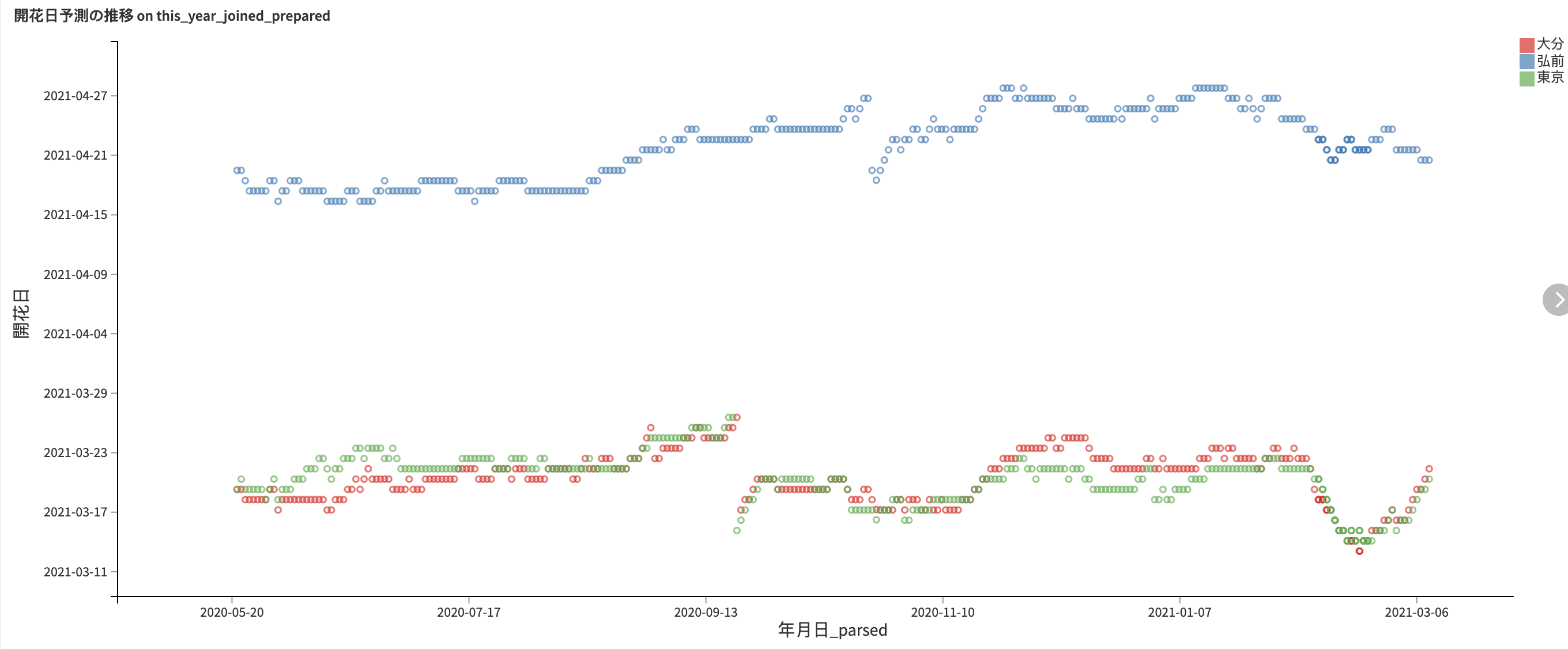
下はRandom Sakura Forestが毎日更新している予測開花日の推移をたどっている図です。あんまり落ち着いていませんね。ただ、このように毎日予測を更新している企業は多くありません。日本気象は2週間に1度、tenki.jpでは2月下旬から4月初旬まで週1度のペースです。
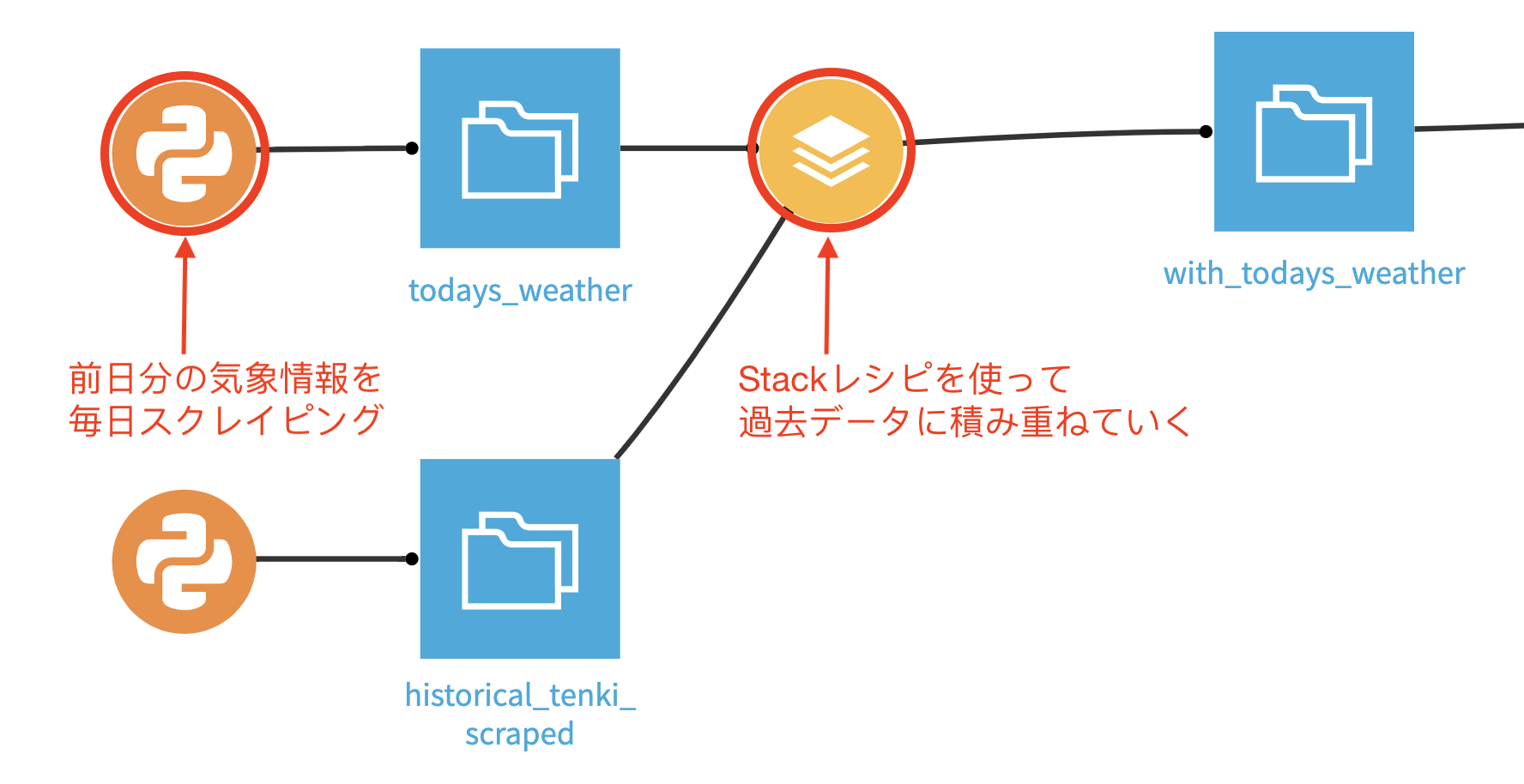
この予測モデルをつくるにあたり、生の気象データを集めて、加工し、モデルを学習させるといったステップを踏みました。しかし、私が書いたコードの行数はたった140行!Dataiku DSSにはコーディングなしでデータ解析ができるツールが豊富です。140行のコード以外はすべてクリック・ドラッグ&ドロップなどの簡単な作業だけでやり遂げました。
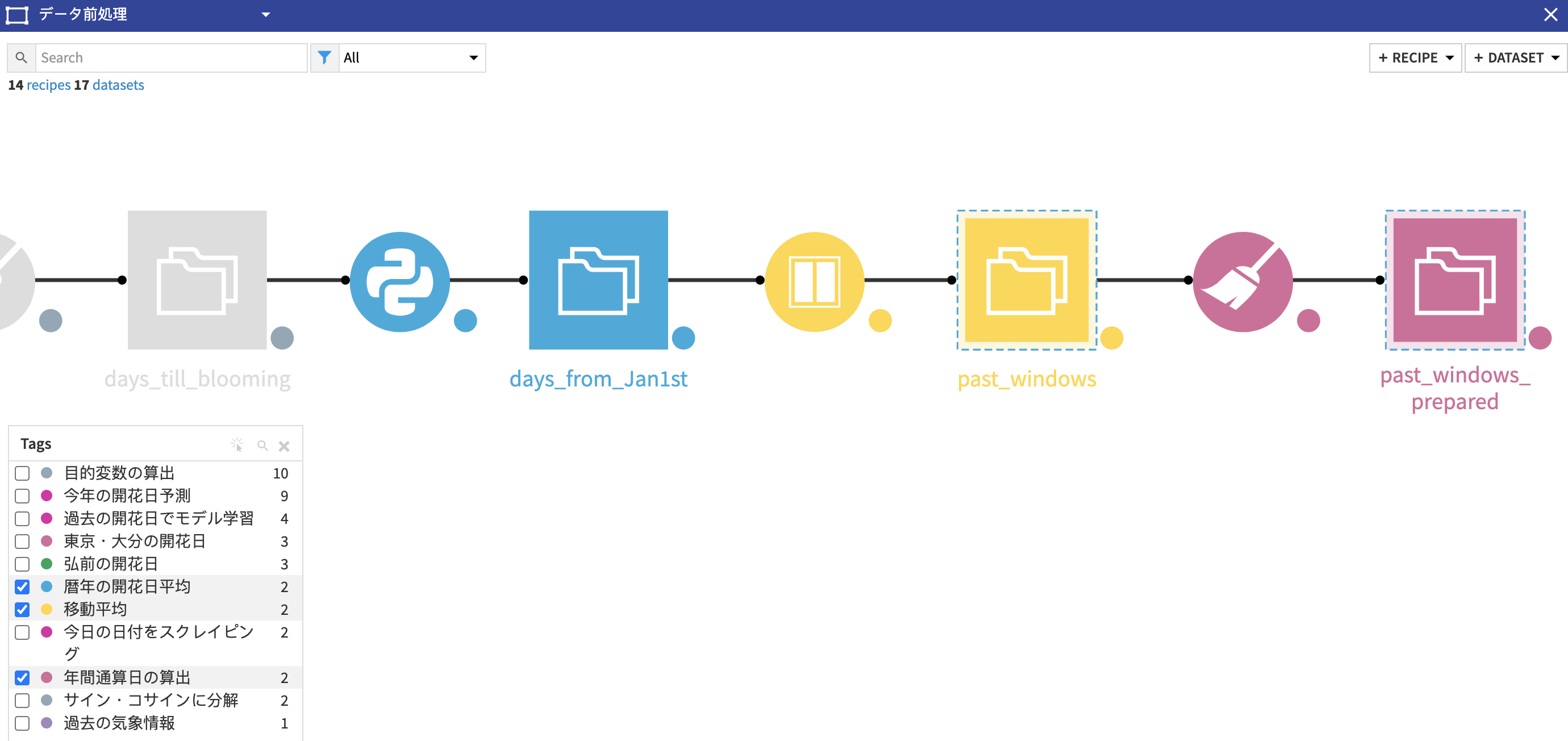
下はDataiku DSS上でつくったプロジェクトのフローチャートです。青く四角いアイコンはデータセット、黄色く丸いアイコンはコーディングなしのデータ加工、オレンジ色の丸いアイコンはPython、緑色のアイコンは機械学習を表しています。自分のやった作業がすぐにアイコン化されるので進捗状況をひと目で把握できます。
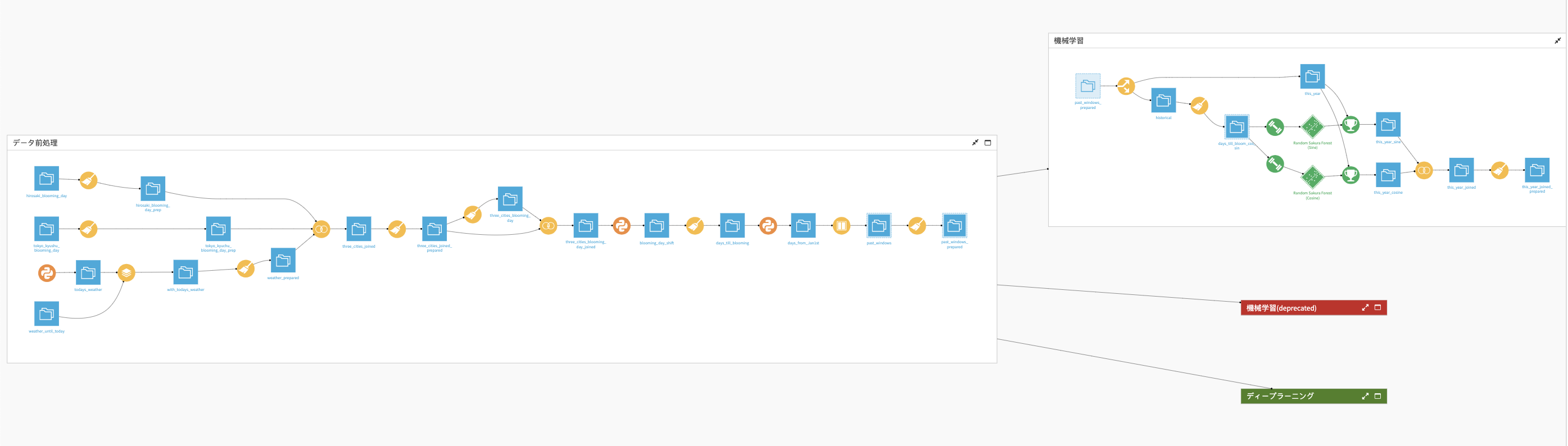
ではどのようにしてプロジェクトを完成させたのかを振り返ってみましょう。
データを集める
集めたデータは以下の2つです。
- 1991~2020年の大分県四浦海岸、東京都千鳥ヶ淵、青森県弘前公園における開花日
- 1991年から今日までの3地点の毎日の気象情報(最高・最低・平均気温、降水量、日照時間)
データは気象庁のウェブサイトからDataiku DSS上でPythonを使ってスクレイピングして集めました。
予測スタイルを決め、目的変数をこしらえる
「開花日を予測する」とはどういうことなのか、より細かく決める必要があります。例えば次のような感じです。
- きょう時点で次の開花日までまだ残り何日あるか、を予測する
- 大分、東京、青森の3地点で別々の予測を出す
- 上記を毎日最新の天候情報を取り込んで更新する
例えば3月4日時点でモデルが「20」という値を返した場合、3月4日+20日で「3月24日」が予想開花日となります。このスタイルに合わせるべく、最後にはこんな見た目のデータになるようパイプラインを組み立てていきます。
| 今日の日付 | 場所 | 気温 | 花の状況 | 開花日 | 開花日までの日数 |
|---|---|---|---|---|---|
| 2020年4月1日 | 東京 | 16 | 開花 | 2020年4月1日 | 0 |
| 2020年3月31日 | 東京 | 18 | 未開花 | 2020年4月1日 | 1 |
| 2020年3月30日 | 東京 | 17 | 未開花 | 2020年4月1日 | 2 |
| 2020年3月29日 | 東京 | 15 | 未開花 | 2020年4月1日 | 3 |
| : | : | : | : | : | : |
| 2019年3月22日 | 東京 | 19 | 未開花 | 2020年4月1日 | 375 |
| 2019年3月21日 | 東京 | 16 | 未開花 | 2020年4月1日 | 376 |
| 2019年3月20日 | 東京 | 15 | 開花 | 2019年3月20日 | 0 |
| 2019年3月19日 | 東京 | 12 | 未開花 | 2019年3月20日 | 1 |
| : | : | : | : | : | : |
目的変数である「開花日までの日数」は0~365の値を取りますが、これだとたった1日予測がずれただけでも誤差が非常に大きくなってしまいます。下の例の1行目を見てください。モデルは2019年3月21日を開花日だと予測しているのに対して、実際の開花日は前日の2019年3月20日と既に過ぎてしまっています。そのため、この行の目的変数は翌年の2020年4月1日になっています。事実上の誤差は1日なのにも関わらず、翌年の開花日までの375日を誤差と認識してしまいます。
| 今日の日付 | 場所 | 気温 | 花の状況 | 開花日 | 開花日までの日数 | 予測 | 誤差 |
|---|---|---|---|---|---|---|---|
| 2019年3月21日 | 東京 | 16 | 未開花 | 2020年4月1日 | 375 | 0 | 375 |
| 2019年3月20日 | 東京 | 15 | 開花 | 2019年3月20日 | 0 | : | : |
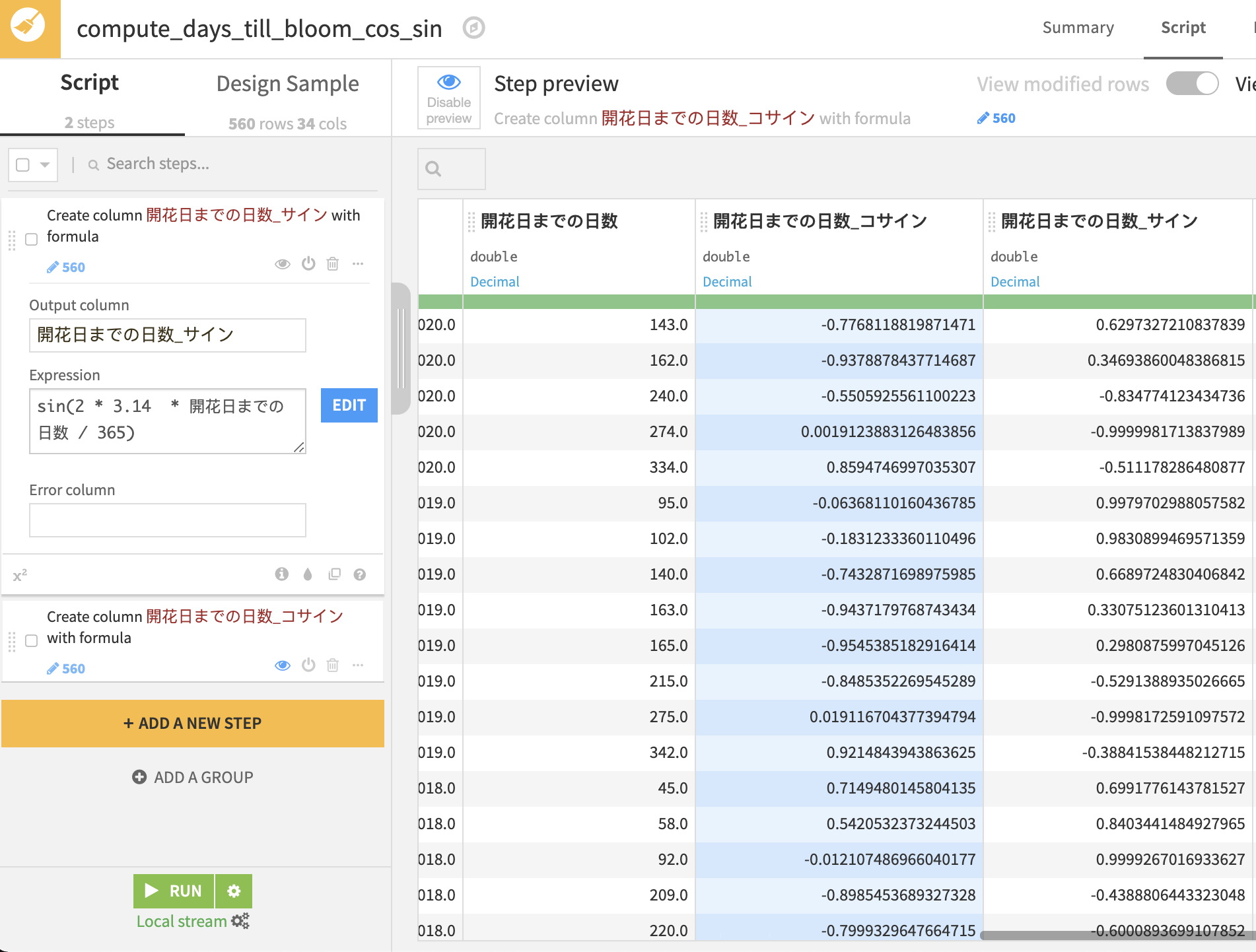
そこで解決策として、切れ目のない滑らかな変数を導入することにします。開花日までの日数をシクリカル変数とみて、0~2πのレンジにスケーリングし、それをサインとコサインに分解します。Prepareレシピを使えばEXCELとほぼ同じ数式の書き方で計算できるので便利です。
特徴量を加える
ここからは予想に役立ちそうな特徴量を加えていきます。
気象情報の移動平均
なんとなくですが、「直近何日間かの気温や日照時間の変動によって、開花日も変わるんだろうな」と想像します(実際はちゃんとリサーチして見当をつけましょう笑)。そこで、気温・降水量・日照時間それぞれで直近1ヶ月、3ヶ月、半年の移動平均を計算しました。
一見難しそうですが、Dataiku DSSのWindowレシピを使えば、コーディングなしの4ステップで終わります。
- 1. 行をグループごとにまとめるかを決める
- 2. 行の並び順を決める
- 3. 窓枠の大きさを定義する
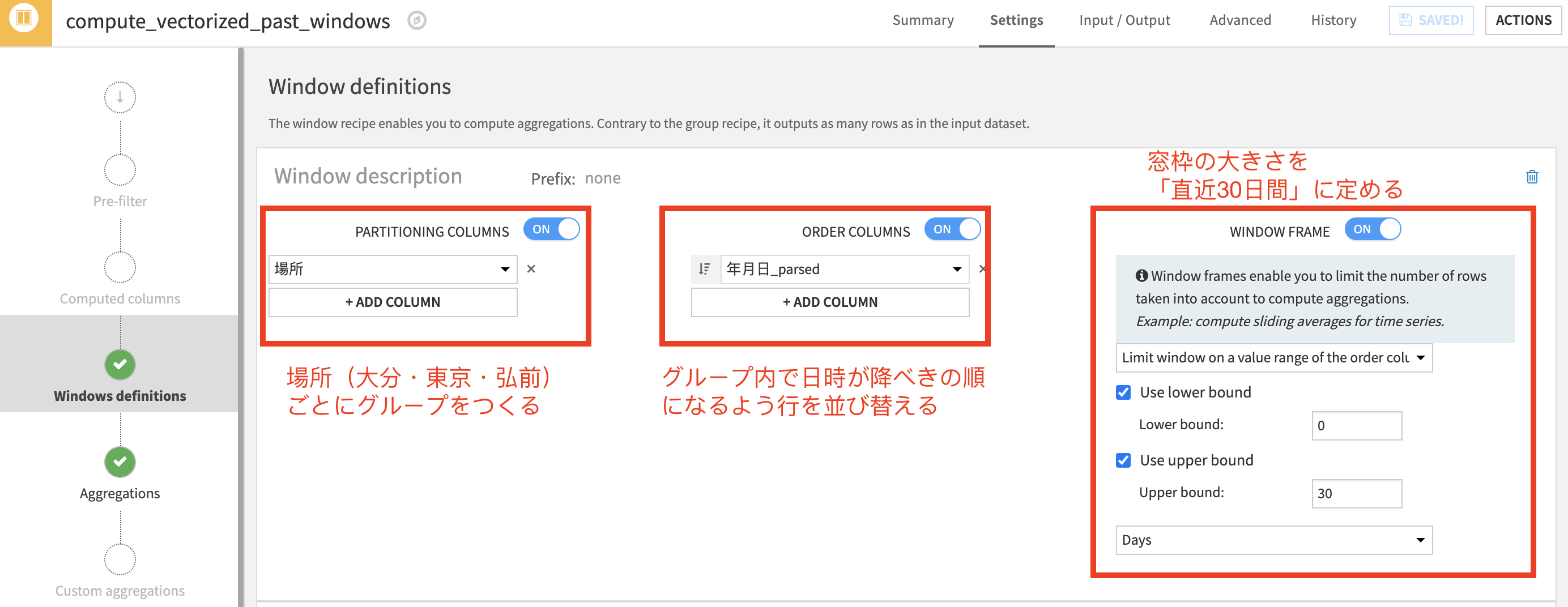
- 4. 窓枠の中でどんな計算をしたいか指定する
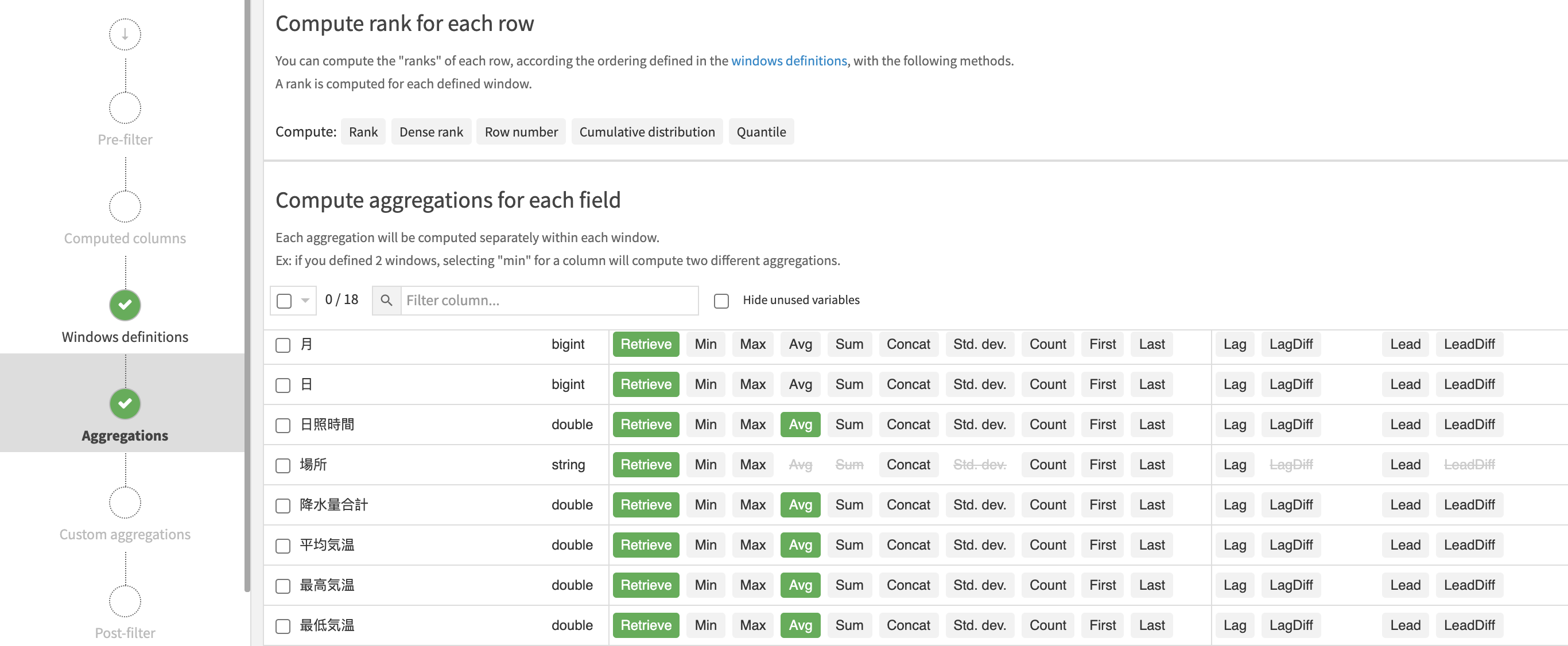
ここでは平均気温、最高気温、最低気温、降水量、日照時間の5項目でそれぞれ平均値をとります。
暦年の平均開花日
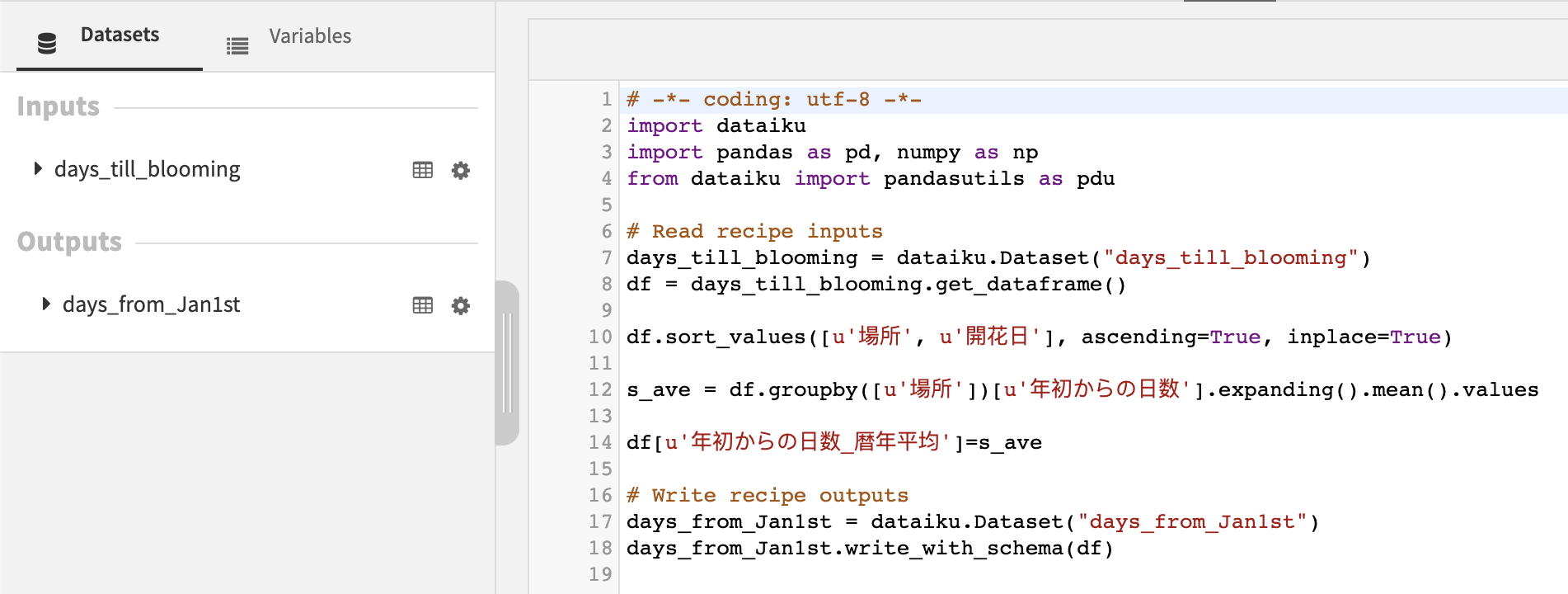
桜の開花日は毎年それほど大きく変わることはないでしょう。そのため、「これまで平年では平均していつ頃が開花日なのか」を特徴量とすれば力強い予測屋さんになってくれそうです。ここではPythonレシピを使ってコーディングしました。
最終的に特徴量の追加はフロー上だとこんな感じに見えます。ひとつひとつのオブジェクトにタグ付けすることでチームメイトと共同作業がさらにしやすくなります。
モデルを学習させる
さて、いよいよ機械学習モデルを組み立てます。開花日までの日数をサイン・コサインに分解したので、それぞれを別々に予測するモデルを2個つくって、予測結果を組み合わせて開花日に戻す、という作業をします。
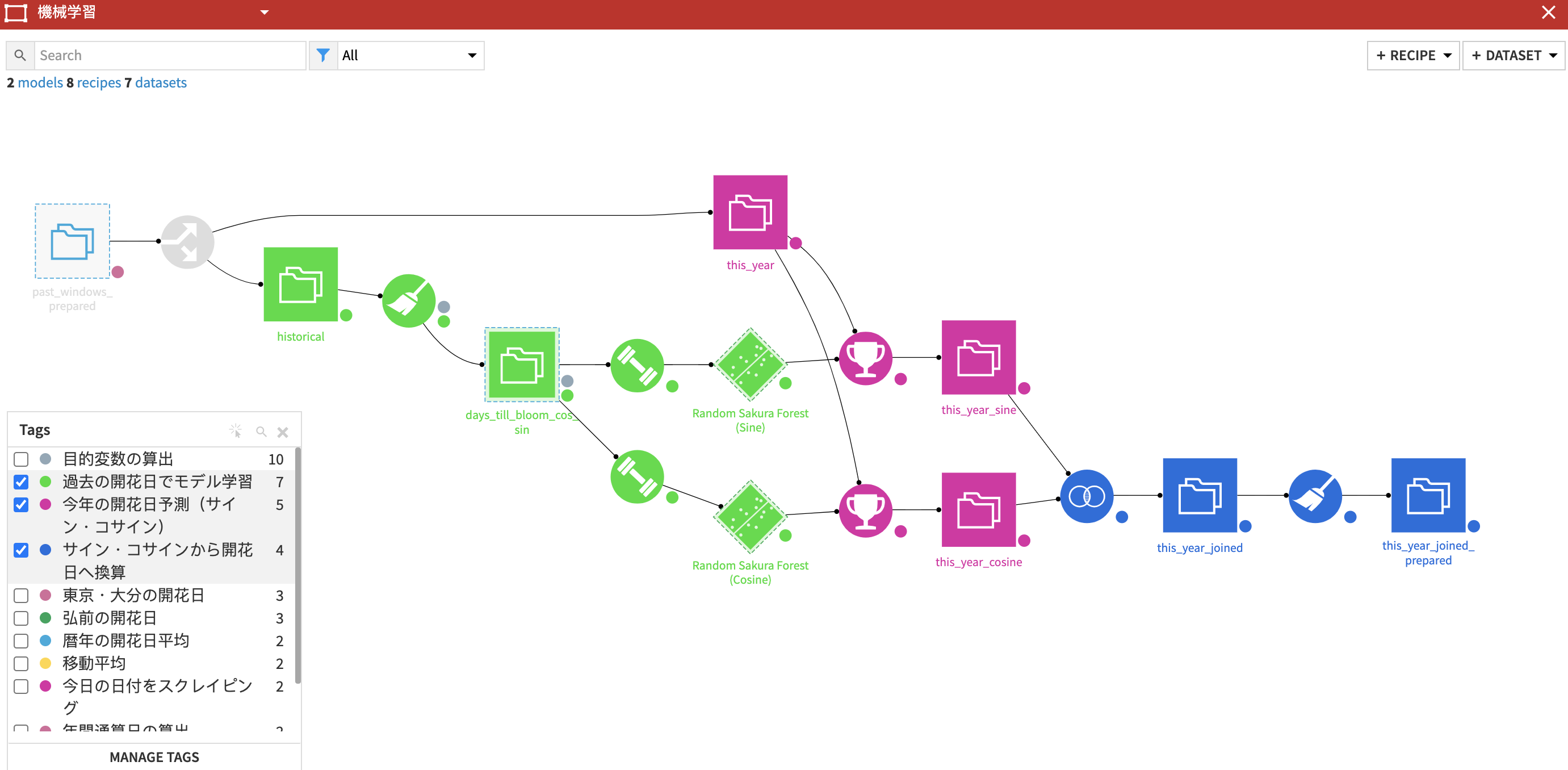
モデル組み立てはとっても簡単です。入れたい特徴量のスイッチをオンにして、特徴量のスケーリングや欠損値の処理をして…
試したいアルゴリズムのスイッチをオンにして、ハイパーパラメータを入力して…
TRAIN!

結果の分析
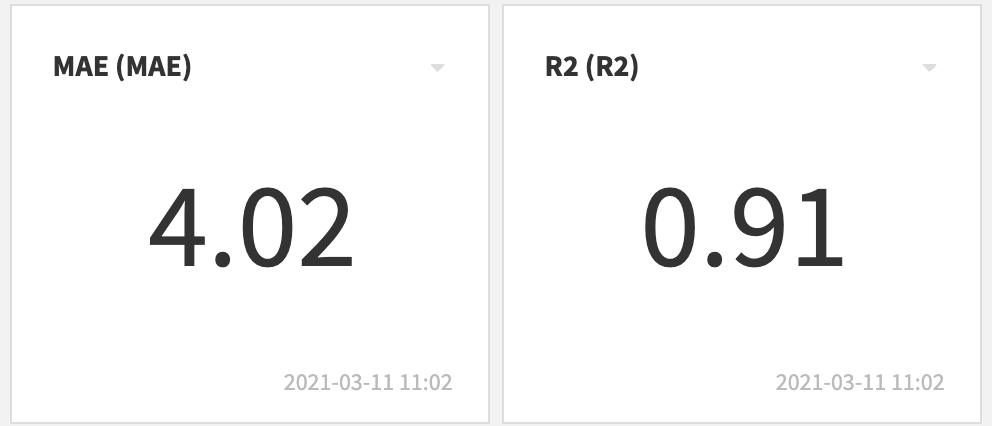
モデル学習の結果、500本の決定木でつくったランダムフォレストが最も良いパフォーマンスを出しました。MAEは4.0となり、予測には約4日の誤差があることがわかりました。R2スコアは0.91でした。
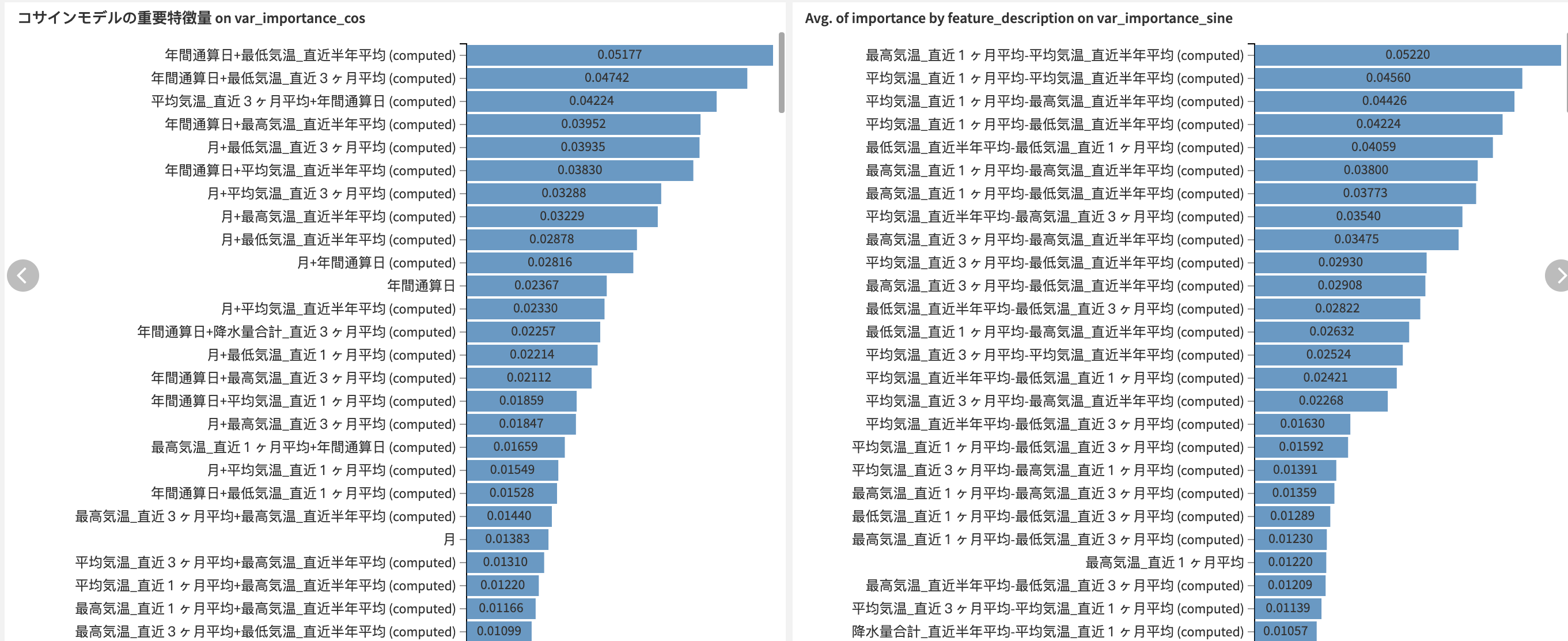
どの特徴量が予測に貢献したかを示すグラフを見てみると、1ヶ月〜半年の気温の移動平均の組み合わせが上位に来ています。その一方で、降水量や日照時間の移動平均や、頼みにしていた「平年の開花日平均」は役に立ちませんでした。この原因は後ほど分析します。
予測結果はダッシュボードにまとめて、チームメイトやステークホルダーと共有できます。
自動化
一通り予測のためのパイプラインを作り終えたら、今度は毎日自動的に予測を更新するための仕組みをつくります。Dataiku DSSではシナリオと呼んでいます。
シナリオの作り方も簡単で、たった2ステップで済みます。
- 1. 組み立てるデータセットや実行するレシピを順番に指定する
- 2. シナリオを実行するタイミングを決める(毎日深夜0時、毎月第2土曜日…など)
今回は毎日深夜2時に前日分の気象情報をスクレイピングして、予測を更新するシナリオを設定しました。毎日少しずつ予測が揺れ動いている様子がわかります。
なぜ降水量や日照時間は役立たずだったのか?
桜の開花日を予測するには、花の生態をよく知ることが重要です。
桜の花そのものは前年の夏にはすでに成形されています。桜の木は秋から冬にかけて休眠状態に入り、冬の間に一定期間低温にさらされると春が近づいていることを感じ取って目が醒めます。そのあとは春先の気温の上昇に伴い開花へ向かって生長していきます。
開花予測には大阪府立大学の青野靖之准教授が開発した手法がよく用いられています。眠りから目覚める日(起算日)を各地点で別々に計算し、起算日から温度変換日数を一日ずつ積み重ねていくやり方です。その積算値が23.8を超える日を開花日と予想します。
起算日は
D_2=136.765-7.689\Psi+0.133\Psi^2-1.307\ln L+0.144T_F+0.285T_F^2
$\Psi$ : 緯度 ($^{\circ}N$)
$L$ : 海岸からの距離 ($km$)
$T_F$ : 1~3月の平均気温の平年値 ($^{\circ}C$)
温度変換日数は
(t_s)_{ij}=\exp \left( \frac{E_a(T_{ij}-T_s)}{RT_{ij}T_s} \right)
$E_a$ : 生育の温度に対する応答の特性を代表する温度特性値 ($70KJmol^{-1}$)
$T_{ij}$ : $i$年の年間通算日$j$における平均気温 ($K$)
$T_S$ : 標準温度 ($288.2K$)
$R$ : 普遍気体定数 ($8.314Jmol^{-1}K^{-1}$)
です。この$T_{ij}$の未来の値を天気予報から引っ張ってきて、積算値を計算します。
青野氏の手法と比べた結果の解釈
青野式の計算方法を見ると分かるとおり、桜の開花日は地理的な条件と気温だけでほぼ説明できてしまいます。もちろん、降水量や日照時間も気温との因果・相関関係はあり、開花日に間接的な影響は及ぼしているに違いありません。しかし開花により大きく影響する気温を特徴量としてたくさん用意したため、結果として降水量や日照時間の優先順位が下がったのだと考えられます。
青野式とRandom Sakura Forestとの大きな違いは、気温情報の使い方です。青野式は天気予報から将来の気温情報を持ってくることで予測する一方、Random Sakura Forestは過去の気温情報だけに頼っています。予報の不確かさに左右されないという点では良いかもしれませんが、Random Sakura Forestも予報を取り込んだモデルに変えるとより正確さが増すのかもしれません。
ソメイヨシノはDNAが同じ
桜並木が一斉に花開く理由を皆さんご存知でしょうか?実は遺伝子研究の結果、ソメイヨシノはエドヒガンとオオシマザクラの雑種が交雑してできた単一の木を始源とするクローンであることが明らかになっています。この一本の木を接ぎ木や挿し木で増やしていったため、日本のソメイヨシノの桜並木はすべてDNAが同じらしいです。だから花が咲くときはほぼタイミングが同じなんですね。
ってことは…
Random Sakura Forestって名付けたけど、ぜんぜんランダムじゃねーじゃん!

追記 (2021年4月27日)
3地点の実際の開花日が出揃いました!結果は…
大分県:3月18日 ハズレ!予想より4日早い
東京都:3月14日 ハズレ!予想より1週間早い
青森県:4月14日 ハズレ!予想より1週間早い
ことしは全国で記録的に早い開花だったようです。弘前公園によると「平年より9日早く、昭和22年からの記録上2位の早咲き」とのことでした。
それにしても悔しい…
一年間腕を磨いて、リベンジは来年果たします!