これは、Augusto González Bonorinoisによるゲスト記事です。Bonorinoisはクレアモント大学院大学の経済学、神経経済学の博士課程1年目に在籍しています。彼は学際性を熱心に提唱者しており、彼が自分の関心を他のさまざまな科学と融合させようという最近の取り組みには、高次元行列のリカッチ微分方程式を解くための量子コンピューティングの学習が含まれます。現在、彼は量子機械学習、計算論的神経科学、金融におけるAI、因果的機械学習、および行動経済学を研究しています。
データサイエンスとデータ分析関連の機会を得て、Pythonはあっという間にペースで人気を博しました。このプログラミング言語の単純な構文、さまざまなモジュール、マルチプロセッシングのサポート、そして活発なコミュニティにより、日々の科学、研究、またビジネス分析タスクにおいて、ユーザーに好まれています。
データサイエンスでは、Pythonは重要な役割を果たします。NumPy、pandas、scikit-learn、TensorFlow、PyTorchなどのライブラリにより、機械学習(ML)アルゴリズムの実装とプロトタイプ作成、プロセスパイプラインの作成、大規模なデータセットに対する統計分析の実行が容易になります。さらに、PythonはWebアプリケーションを構築するためのGUI(グラフィカルユーザーインターフェース)をサポートしており、調査結果をステークホルダーに伝えるのに役立ちます。Pythonの真の力は、ユーザーが同じ言語を用いて、一連の異なるタスクを実行できる柔軟性にあります。ただし、これらのパイプラインをコーディングするには、多くの場合、数行のコードとさまざまなライブラリが必要です。
データアナリストまたは機械学習実務担当者は主にデータ分析に関心があり、コーディングの必要性を最小限に抑えたいと考えています。この記事では、AIアプリケーションの設計、デプロイ、管理、および管理のための中心的なソリューションであるDataikuを使用して、これを実現する方法について説明します。この記事では、データラングリング、特徴量エンジニアリング、探索的データ分析(EDA)など、データサイエンスプロジェクトで最も時間のかかるタスクの中にいかに退屈で面倒なものがあるのか、そしてそれらをDataikuに置き換える方法について説明します。
Dataiku で時間を節約
このテストプロジェクトでは、さまざまなデータサイエンスのポジションの給与を調べてみましょう。Kaggleが提供する優れたデータセットを使用して、これらの手順を手動で実行するのにかかる時間とDataikuを使用して実行するのにかかる時間を比較します。
このお楽しみに参加するには、Python、scikit-learn、pandas、Matplotlibに精通している必要があります。さらに、このプロジェクトの第2部用のために、無料のDataikuアカウントを作成してください。
以下のセクションでは、PythonとDataikuのプラットフォームの両方を使用して、このデータサイエンスタスクを完了する手順について説明します。ただし、最も時間のかかるタスクのみに重点が置かれているため、完全なモデルを段階的に展開する方法については説明していません。
Pythonで機械学習モデルを作成する
ライブラリが環境に読み込まれたら、データセットのインポートに進みます。データセットはカンマ区切り値形式で、pandasで簡単に読み取ることができます。
ML モデルを作成するには、次のライブラリが必要です。
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
import plotly.express as px
import plotly.figure_factory as ff
import plotly.graph_objects as go
from wordcloud import WordCloud
import nltk
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import make_column_transformer
from sklearn.linear_model import LinearRegression, Ridge, Lasso
記述統計では.describeや.infoといったデータフレームメソッド使います。その場合、null値はありませんが、いくつかの特徴量ではデータ型が適切ではありません。
次のコードは、データセットから最も人気のある上位10の役職について棒グラフを生成します。
fig = px.bar(y=top10.values,
x=top10.index,
range_x = [-1, 11],
color = top10.index,
color_discrete_sequence=px.colors.sequential.PuBuGn,
text=top10.values,
title= 'Top 10 Most popular Job Titles in sample',
template= 'plotly_dark')
fig.update_layout(
xaxis_title="Job Titles",
yaxis_title="count",
font = dict(size=15,family="Franklin Gothic"))
fig.show()
これにより、plotlyパッケージの特徴である、美しくインタラクティブな棒グラフが生成されます。

次に、通貨をインドルピー(INR)から米ドル(USD)に変換して、各ポジションの給与を確認します。現在の為替レートでは、1ドルは 81.2ルピーに相当します。これはPython関数を使い次のようにコーディングできます。
def to_usd(rupees):
return round(rupees / 81.2, 2)
これで、給与を米ドルで表す新しい列を作成できます。
data['Salary_In_Rupees'] = data['Salary_In_Rupees'].apply(
lambda x: float(x.split()[0].replace('.00', '').replace(',', '')
))
data['Salary_In_Dollars'] = to_usd(data['Salary_In_Rupees'])
同じデータセットを使用して、給与、職務内容、勤務地の関係を調べることもできます。たとえば、給与がリモート作業とオンプレミス作業にどのように関係しているかを調べることができます。
そのためには、データセットをDesignationとRemote_Working_Ratioの両方でグループ化します。このグループ化により、各行は、役職とそれぞれのリモート作業比率の一意の組み合わせを表します。以下のコードを実行して、職務内容ごとの平均給与とリモート勤務率を確認します。
remote_pos = data.groupby(['Designation','Remote_Working_Ratio']).mean()
remote_pos.head(6)
上記のコードスニペットは、下表のように最初の6行を出力します。

ここでの結果が示すように、リモートワークの比率が高い人は、リモートワーク比率が低い人よりも収入が大幅に少なくなります。
次に、結果をプロットし、視覚的に結果を確認します。ビジュアライゼーションのためのコーディングする前に、Working_Year列とSalary_in_Rupees列を削除して、米ドルでの分布に注目しましょう。これにより、プロットも容易になります。
remote_pos = remote_pos.drop(["Working_Year", "Salary_In_Rupees"], axis=1)
次に、以下のコードを使用して、今見たのとまったく同じ集計データをプロットします。
remote_pos.head(6).unstack().plot(kind='bar', rot=15, figsize=(7, 6))
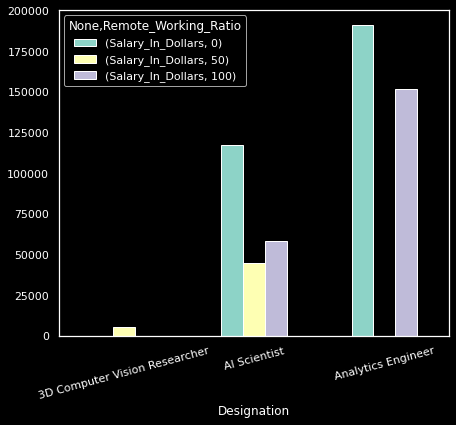
このプロットを作成するには、サンプル全体をサブセット化し、MultiIndex DataFrameをアンスタックし、最小限のパラメーターを設定して棒グラフをカスタマイズする必要がありました。
上記の例に見られるように、データをしっかりと理解したら、より高度な方法を使用してその品質を向上させることができます。これらには、サンプリング(一般的にRandomパッケージで行われる)と、相関行列や関連する統計検定をプロットするような、さらなる分析が含まれます。
プロジェクトの最後のステップは、モデルトレーニング用のデータを分割して処理することです。scikit-learnのコンピューターとエンコーダーを使用して、数値とカテゴリ値を処理するパイプラインを作成します。
num_xformer=make_pipeline(SimpleImputer(strategy="median"),StandardScaler())
cat_xformer=make_pipeline(SimpleImputer(strategy="most_frequent"),
OneHotEncoder(handle_unknown='ignore'))
numeric_features=X_train.select_dtypes(include=['int64','float64']).columns
categorical_features=X_train.select_dtypes(include=['object','category']).columns
preprocessor = make_column_transformer((num_xformer, numeric_features), (cat_xformer, categorical_features))`
最後に、このパイプラインを使用して線形回帰モデルを学習させます。
pipe = make_pipeline(preprocessor, LinearRegression())
pipe.fit(X_train, y_train)
完璧なモデルをすぐに入手できる可能性はほとんどありません。したがって、モデルの学習プロセスを最適化するには、ハイパーパラメーターの調整と学習後の更新が重要です。
scikit-learnから、GridSearchCVオブジェクトをインポートします。次に、調整するパラメーターを選択します。このデモンストレーションでは、調整可能なアルファパラメーターを持つリッジ回帰を使用します。実験したいアルファのさまざまな値で辞書を指定します。
最後に、新しいパイプラインにグリッド検索を適用します。試行するパラメーターと値、評価メトリクス、交差検証の回数などの引数を指定します。
コードは次のようになります。
from sklearn.model_selection import GridSearchCV`
param_grid = {'ridge__alpha': [0,0.001,0.01,0.1,1,10,100,1000]}
grid = GridSearchCV(make_pipeline(preprocessor, Ridge(alpha=0.07)),
param_grid,
scoring= 'neg_mean_absolute_error',
cv=5, n_jobs = -1, verbose = 5)
grid.fit(X_train, y_train);
> Fitting 5 folds for each of 8 candidates, totalling 40 fits
Dataiku で機械学習モデルを作成する
上記の例では、データサイエンスプロジェクトの主要な段階をハイライトしています。これから、同様の手順を少々異なるやり方で繰り返すことになります。上記の例は非常に単純な機械学習プロジェクトですが、簡単というわけではありません。クレンジングするデータが最小限であっても、このような複数ステップのプロセスは、規模が大きくなればいかに負担が大きいものになるかということを示しています。さらに、上記のプロセスでは、ビジュアライゼーションや特徴量エンジニアリング、モデル設定について、それらが適切であることを確認するために必要な何回にもわたる繰り返しや微調整が省略されています。
あなたが律儀なコーダーであれば、パイプラインの開発時間を短縮するために適応できる一連のコードサンプルをすぐ利用できるように用意しているかもしれません。それでも、少なくとも、コピーと貼り付けを何度も行う必要があります。
さらに、コーディングできるチャートの数とテストできるモデルの数には合理的な制限があります。レポートを送信したり、ダッシュボードを作成したりする必要がある場合はどうすればよいでしょうか。Dataikuのプラットフォームでは、最小限のコーディングでこの分析を実行することができます。
まず、 Datasetタブに移動してデータセットをインポートします。あるいは、これが新しいプロジェクトの場合は、自動的にプロンプトが表示されます。Datasetタブは、プロジェクト名の右側にある、ネットワークアイコンのラベルが付いたドロップダウンメニューの下にあります。インターフェースは次のようなものです。
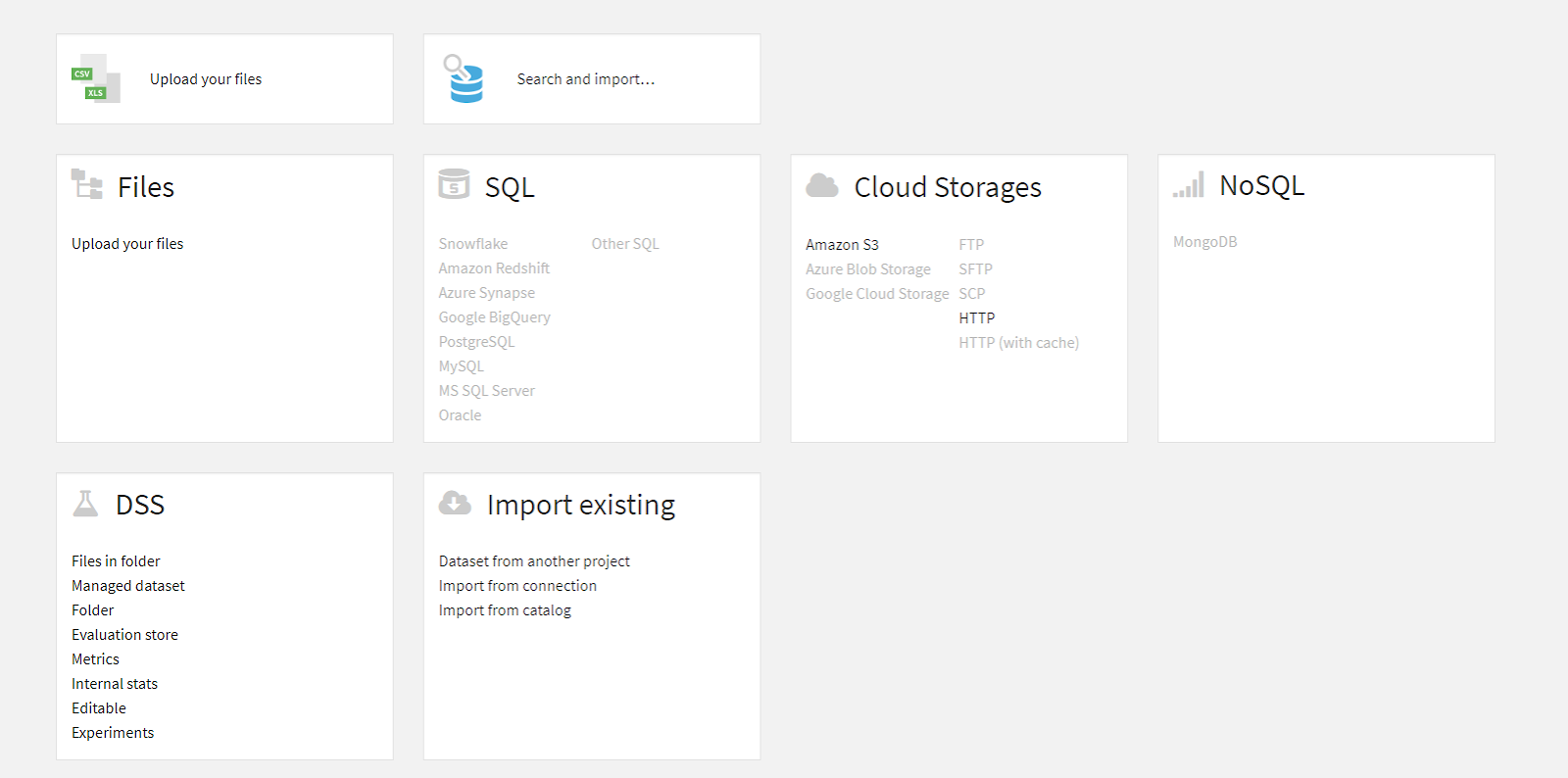
データ準備
Dataikuプラットフォームでは、ほぼすべての形式またはデータソースが入力データセットとして取り扱えます。SQLデータベース、クラウドストレージ、特殊なファイル形式などのソースに接続することもできます。アップロードが完了すると、Dataikuはデータセットを作成するように促し、Exploreビューに移動します。

このタブでは、型キャスト、ソートなど、EDA(探索的データ分析)の一般的な前処理を実行できます。タイプの変更は非常に簡単です。列のデータ型を表示するセルをクリックし、ドロップダウンメニューから正しい形式を選択するだけです。分析エンジンを開くと、ルピー列の給与を簡単に詳しく調べることができます。関心のある列(この場合はSalary_In_Rupees)をクリックし、Analyzeボタンを選択します。

これにより、以下に示すように、この特定の列に関する有用な記述統計を含む画面が表示されます。

Pythonを使用しても、これを作成するには数行のコードが必要でした。
次に、Pythonで行ったように、ドルでSalary列を作成します。これを行うには、Dataikuのレシピ機能を使用できます。レシピとは、Pythonコードを使用して、または組み込みのレシピを活用して視覚的に、既存のデータセットに対して実行されるカスタム変換です。
現在表示されている Analyzeポップアップ画面から、メインインターフェースの右上隅に移動し、Actionボタンをクリックします。これらの手順に従うと、次の画面が表示されます。
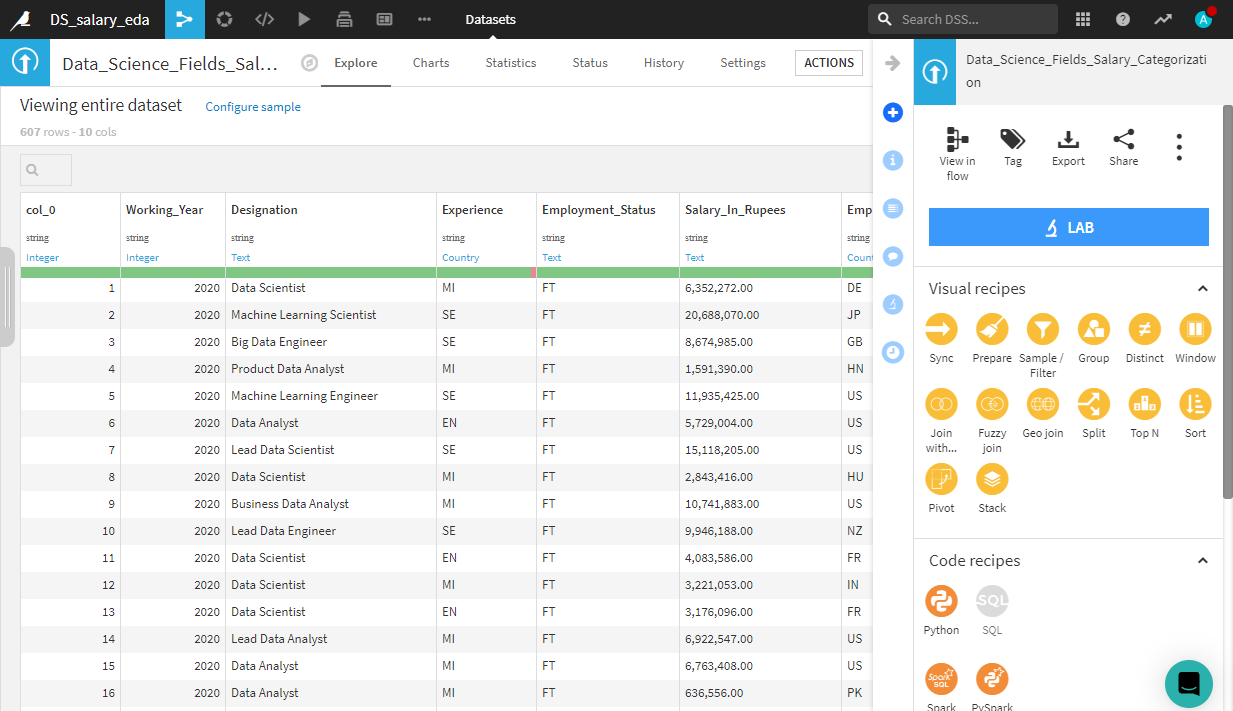
コードを書かずに通貨を変換する関数を再作成してみましょう。Viaual Recipeの下にあるオレンジ色のPrepareボタンを見つけてクリックします。画面は次のようになります。

次に、Addをクリックし(フィールドが自動入力されていない場合)、出力に名前を付けて、CREATE RECIPEをクリックします。さあ、調理が始まります!
レシピは変換であることを思い出してください。列名がInputsとOutputsになっているのはそのためです。入力はデータセットの現在の状態であり、出力は変換後の結果のデータセットです。
レシピを作成すると、次の画面に移動します。ここで、Add A NEW STEPボタンをクリックして、新しいビジュアルレシピを作成できます。

ビジュアルレシピを使用して、Salary_In_Rupees列のデータ型を数学演算に使用できる数値に変換してみてください。(ヒント: Data Cleansingプロセッサーを参照してください。) 最後に、米ドルに変換するには、Math > Numbersライブラリをクリックして、オプションを調べます。Convert currencyプロセッサーを使用する方法と、シンプルにカスタムFormulaを適用する方法の2つが考えられます。この例では後者を使用しました。結果を次のスクリーンショットに示します。
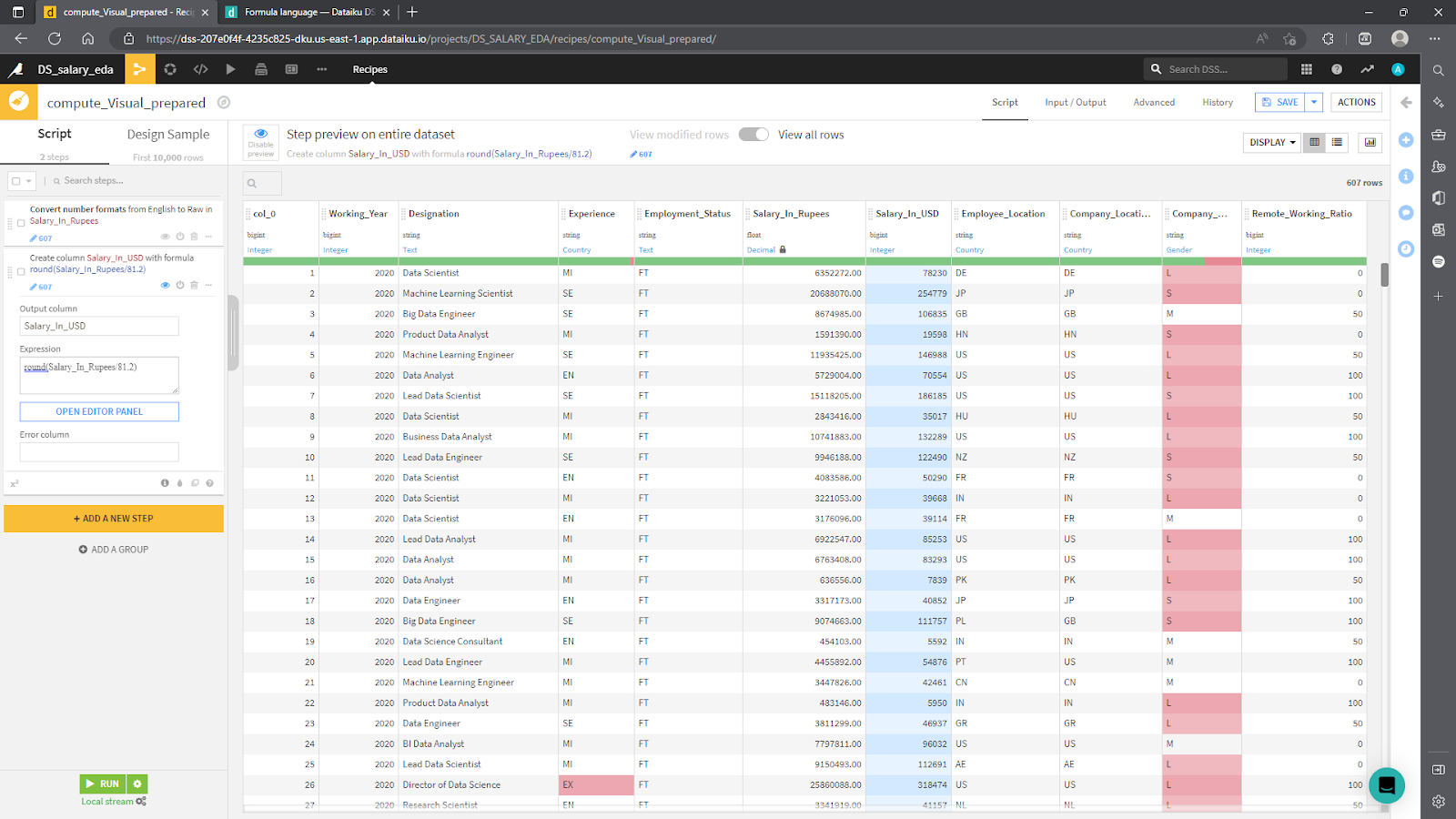
完了したら、Runをクリックして、変換されたデータセットを自動的に生成します。Flowに戻ると、左上隅に、処理されたデータセット (exampleと呼ばれます) を示す新しい青い四角形が表示されます。ここまでの例では、次のようになります。自分でさらに実験した場合、画面が異なって見える可能性があります。

上の画像では、オレンジ色の円が追加されていることに注目してください。これは、データセットの準備に使用されるコードレシピに対応しています。最後に、小さなチャレンジとして、Dataikuが提供するビジュアルレシピまたはコードレシピを使用して、給与をルピーで表示する列を削除します。
データ分析と可視化
次のステップは、統計分析とデータの視覚化です。Dataikuを使用すると、Satisticsタブで数十の異なる統計テストと分析をシームレスに実行できます。
データを分析して視覚化するには、Flowのメイン画面に移動し、左上のメニューに移動して、一番左のアイコンをクリックし、ドロップダウンメニューからDatasetsを選択します。これにより、以下に示す画面が表示され、利用可能なすべてのデータセットが表示されます。インポートした元のデータセットと変換されたデータセットが表示されます。

この演習用に変換されたデータセット (ここではArticle_exampleという名前) を選択します。これにより、最初にデータをロードしたときと同じメニューが返されます。
インターフェースの上部にメニューがあることに注目してください。この時点でExplorerタブが表示されているはずです。Statisticsタブが見つかるまで右に移動し、それをクリックします。これにより、以下のようなメニューでワークシートを作成するように求められます。

Dataikuでは、実行したい統計の種類を選択するよう求められます。または、データの特性に基づいてプラットフォームにレコメンドを提示させることもできます。相関行列、要約統計量、密度分布図や、Pythonで作成するには多数のコード行を必要とするその他の値から選択できます。
この例では、ドルでの給与への影響を理解しようとしています。したがって、適合分布をプロットし、Salary_In_Dollarsの単変量分析をCompany_Sizeごとに実行して、3つの規模の企業間で給与がどのように異なるかを調べます。すべての情報が1つの画面に表示され、インタラクティブなプロットが特徴です。そして、それにはほんの数分しかかかりません。
さらに、さらに実験を行い、モデルをトレーニングする前にデータセットをサンプリングする必要がある場合は、ドロップダウンメニューのSampling and filteringとConfidence levelに、これらのパラメーターを操作するための多くのオプションが用意されていることに注目してください。

機械学習
あとは、線形回帰モデルをトレーニングしてテストするだけです。よく使用するコードブロックがある場合は、新しいコードレシピを作成して、モデルのトレーニングに使用するデータフレームとカスタマイズされたモデルを生成できます。そうでない場合は、データを迅速に処理し提案されたモデルをトレーニングする、自動レコメンデーションに頼ることができます。
Flowタブで、機械学習モデルに使用するデータセットのアイコンをクリックします。次に、Labをクリックします。オプションのセットが右側のメニューに表示されます。Dataikuが提供するAutoMLを利用することで、データの処理、トレーニング、テスト、デプロイ、およびモデルの保守のプロセスを合理化します。

この場合、Dataiku はランダムフォレストとリッジ回帰をレコメンドします。Pythonでは、ハイパーパラメーターの検証、データセットの変換、トレーニング、さまざまなモデルの評価を行うためのインフラストラクチャーをセットアップするには、大量のコードとscikit-learnの機能に関する知識が必要になります。しかし、コードを1行も書く必要はありませんでした。Dataikuがすべてを自動的に行ってくれました。
さらに、Designタブで、すべての特徴量やハイパーパラメーター、トレーニング戦略、モデルにアクセスできます。

これで、完全なデータセット分析とベンチマークモデルが完成しました。任意のデータセットのフローを複製し、必要に応じて更新できるようになりました。
この記事を締めくくる前に、機械学習の実験に対するDataikuの機能の関連性をより徹底的に見てみる必要があります。現在の画面から、主要な記述統計に加えて、メインチャートの真上にあるドロップダウンメニューからさまざまな評価指標を設定できることに注目してください。

Dataikuのプラットフォームのこの機能により、さまざまなメトリックで横断的にモデルのパフォーマンスをすばやく評価できます。しかし、真のイノベーションはDesignタブにあります。メトリクスドロップダウンメニューの上部にあるDesignをクリックします。Basicというタイトルのメニューの下にあるMetricsタブをクリックします。

Metricsでは、トレーニングパラメーターの変更、特徴量エンジニアリング、データ分割方法のカスタマイズ、説明可能性レポートの作成、実験の自動追跡を行うことができます。これはPythonで実行するのは非常に重いタスクであるため、ここでDataikuを使用すると、時間を大幅に節約できます。
Dataikuを使いデータにフォーカスし続ける
Pythonは、データサイエンティストのツールキットに欠かせないものになりました。これにより、迅速なプロトタイピングが可能になり、迅速な分析が容易になります。それでも、データサイエンスプロジェクトワークフローの各コンポーネントを実装するには、多くのコーディングと外部ライブラリの知識が必要です。Dataikuのプラットフォームは、研究プロジェクトの実験的側面とパイプラインの作成を容易にすることで、時間を節約します。
Dataikuを使用すると、機械学習モデルの変化を自動的に監視し、コラボレーションを促進し、モデルを微調整できます。一元化されたインフラストラクチャーですべてを実行し、モデルの最適化を簡素化し、セキュリティーを向上させ、データ分析の促進をサポートします。
PythonタスクをDataikuに置き換える
PythonタスクをDataikuに置き換えることで、機械学習モデルを次の段階へと導く方法を見つけてください。
→Dataikuの無料オンライントライアルはこちら