私たちの多くは、人間による偏見の結果としてデータに生じうる問題、すなわち、結果の格差、不公平な政策、機会損失などが、数え上げればきりがないことをよく理解しています。AIの力がセンシティブな状況に適用される際に、私たちは機械学習と偏り(バイアス)の混合が生み出す危険性が心配することになります。では、どうすればいいのでしょうか?
責任あるAIとは、意図しない結果の可能性に適切に対処しながら、組織がAIモデル開発のパイプラインを構築するためのフレームワークです。モデル構築に携わるデータサイエンティストは、結果が意図しないものになることをあまりコントロールできないように感じるかもしれませんが、そんなことはありません。
このブログは、Dataiku Product Daysのセッションをまとめたものです。当該セッションでは、DataikuのJacqueline Kuo(ソリューションエンジニア)、Sibongile Toure(データサイエンティスト)、Andy Samant(シニアデータサイエンティスト)が、責任あるAIにどう取り組むか、このようなプロジェクト目標のためにDataikuのさまざまな機能や技術をどう利用できるかについて、デモを交えて紹介しました。
AIパイプラインの構築とは
AIパイプラインの構築には多くの段階がありますが、まずはデータサイエンティストにとって最も不可欠な部分である「構築」について見てみましょう。
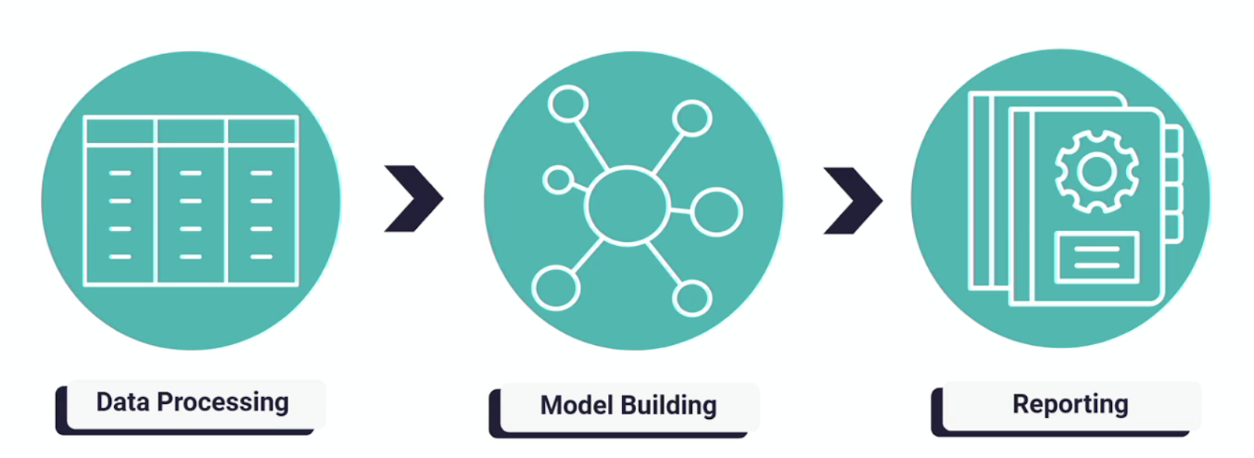
パイプラインの構築ステップの中には、主に3つのステージがあります。
- データ処理(クレンジングと特徴量の作り込み)
- モデル構築(モデルを作る)
- レポーティング(パフォーマンスを調べる)
この3つのカテゴリーにおいて、バイアスをキャッチするためには、モデルのセンシティブなカテゴリーや属性を意識することが重要です。このプロジェクトの例では、以下の3つの段階を通して、これらの要素を警戒する方法を見てみましょう。

クーポン交換プロジェクト
買い物をした後、メールや受信ボックスにクーポンが送られてくることがよくあります。このプロジェクトでは、クーポンが偏った形で送られていないか、データサイエンスチームがデータを調査してみました。
プロジェクトの目的
- 顧客がクーポンを利用するかどうかを予測する。
- 各年齢層で(モデルに基づいて)クーポンを受け取る機会が同じであることを確認する。
データ
- 顧客の特徴
- 顧客の売上
- クーポンの属性
- センシティブ属性(年齢層)
- ターゲット変数:クーポン引換状況
データのクリーニング
はじめのデータの確認後、チームは簡単なクレンジングとフィルタリングを行い、ひとつめのモデルを作成しました。バイアスを特定するための主な指標として、再現率(真陽性の数➗(真陽性の数+偽陰性の数で割ったもの))に焦点を当てることにしました。プロジェクトフローをゾーンに分割することで、プロジェクトをさまざまな部分に分けて整理することができます。
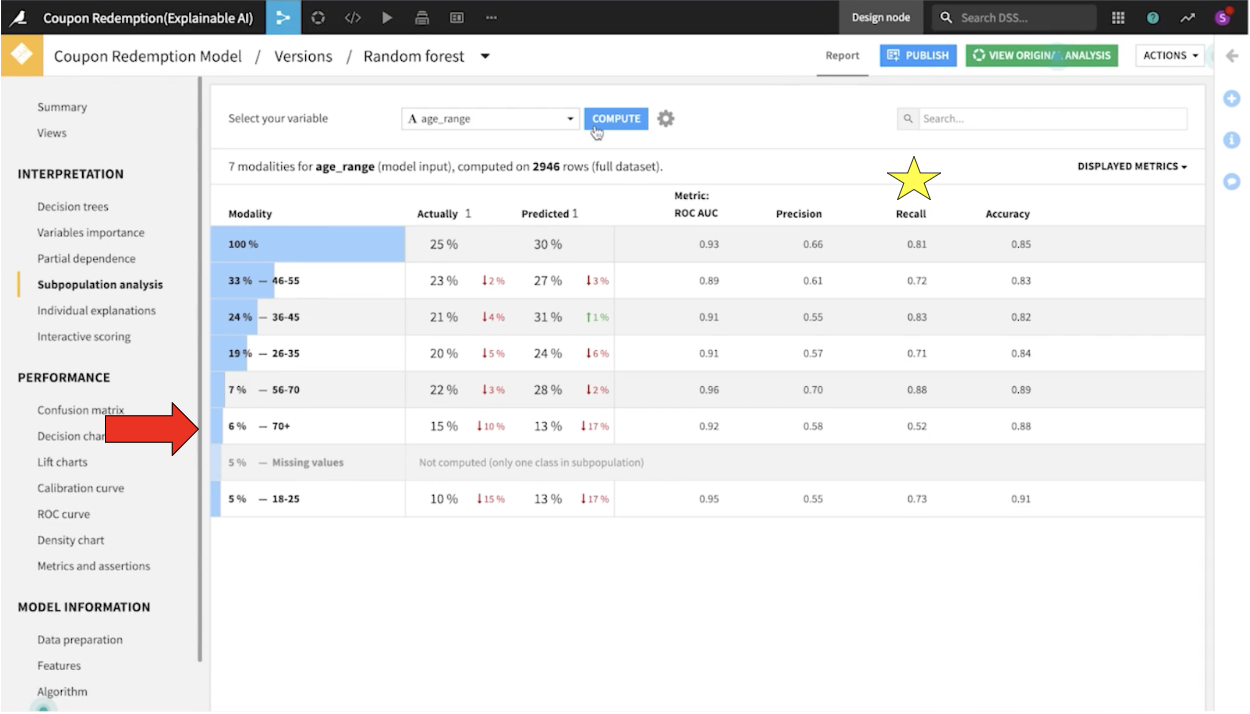
次に、混同行列をチェックして偽陰性の数を軽減することに焦点を当てました。サブポピュレーション分析をもとに、モデルが年齢層を超えて公平に機能しているかどうかを確認しました。

説明性について調べる
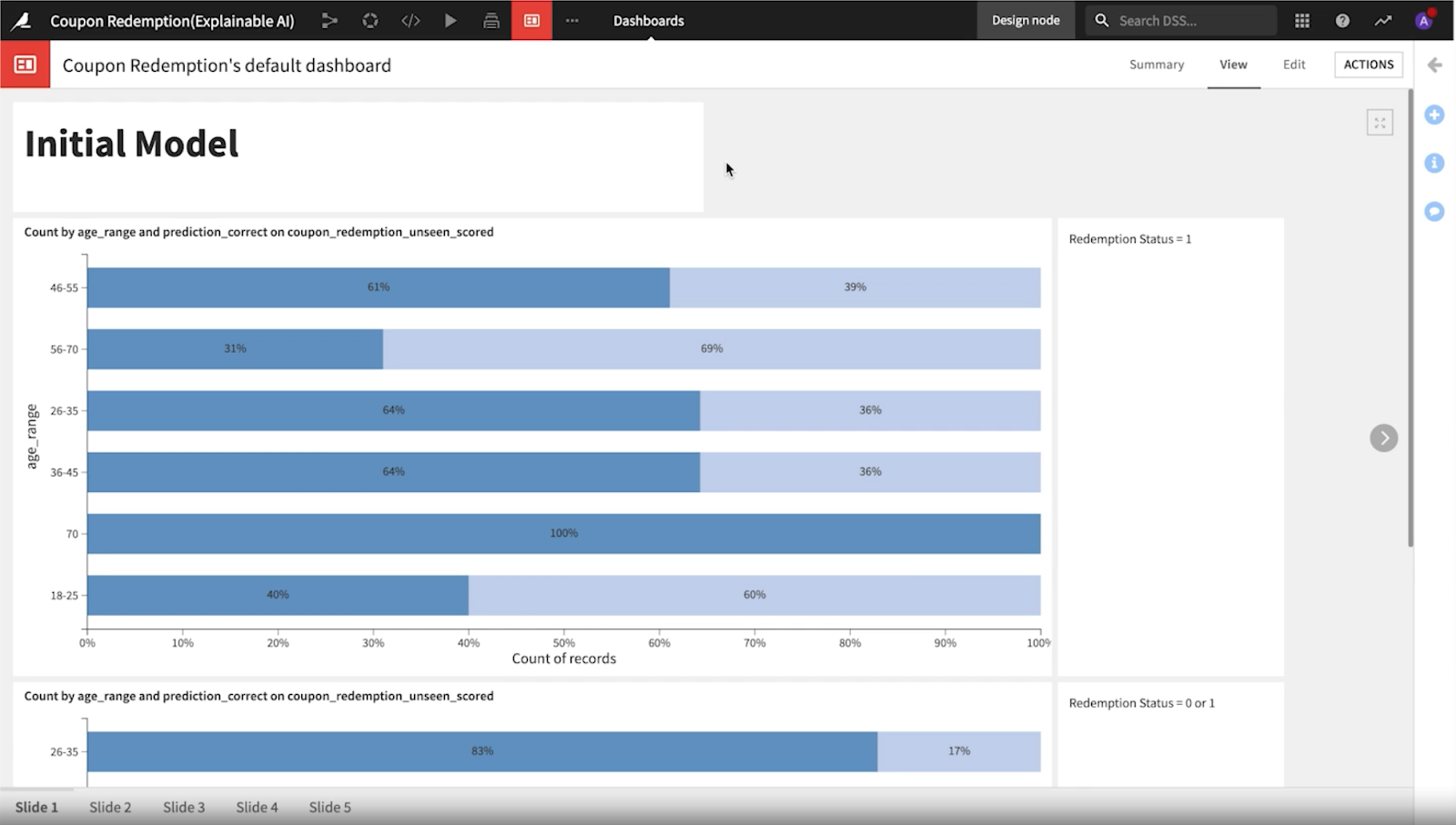
もし年齢層によって大きな差がある場合は、モデルに偏りがあるかも知れません。この例では、70歳以上の年齢層で再現率が低いことが極めて顕著でした。
さらに調査するために、データサイエンティストは個々の説明性のレコードを調べ、ICE法を用いて、極端な確率に最も影響する特徴量の説明性を計算しました。
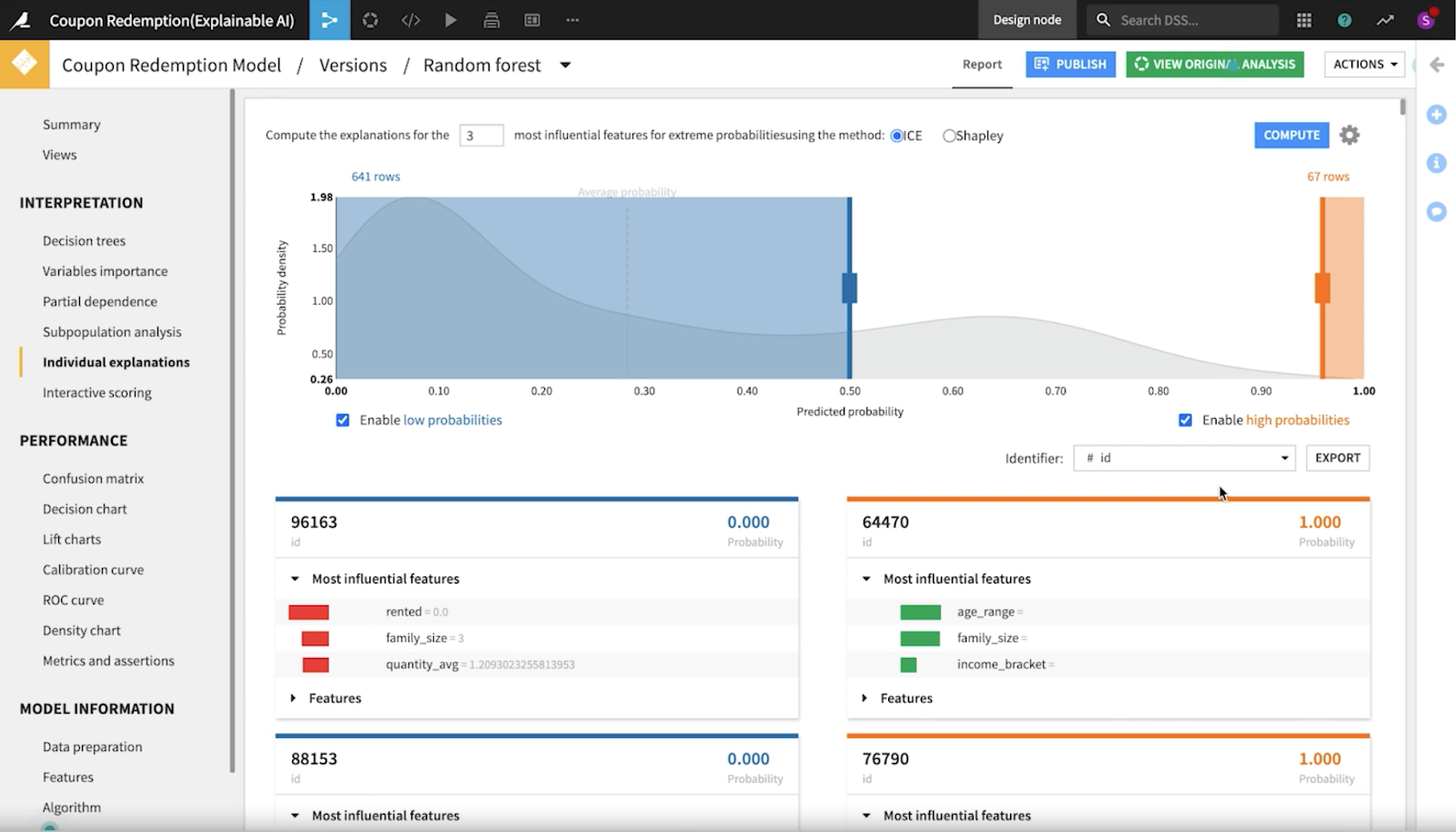
モデルの公平性の評価
モデルの公平性を数学的、社会的の2つの角度から評価する必要があります。
- 数学的な公平さ: 公平な予測は、センシティブ属性に依存しない
- 社会的な公平性: 公平なモデルのパフォーマンスは、さまざまなグループ間でも一貫しており、その結果は望ましい意図と一致する
この観点から、チームはDataikuのモデル公平レポートを使って、4つの異なる主要な指標をチェックしました:人口統計学的パリティ、均等化オッズ、機会均等、予測率パリティです。
人口統計学的パリティは、センシティブなグループと有利なグループの間の陽性予測の割合(陽性率)を測定します。この指標では、陽性予測が真か偽かは考慮されず、各グループの陽性予測率のみが考慮されます。
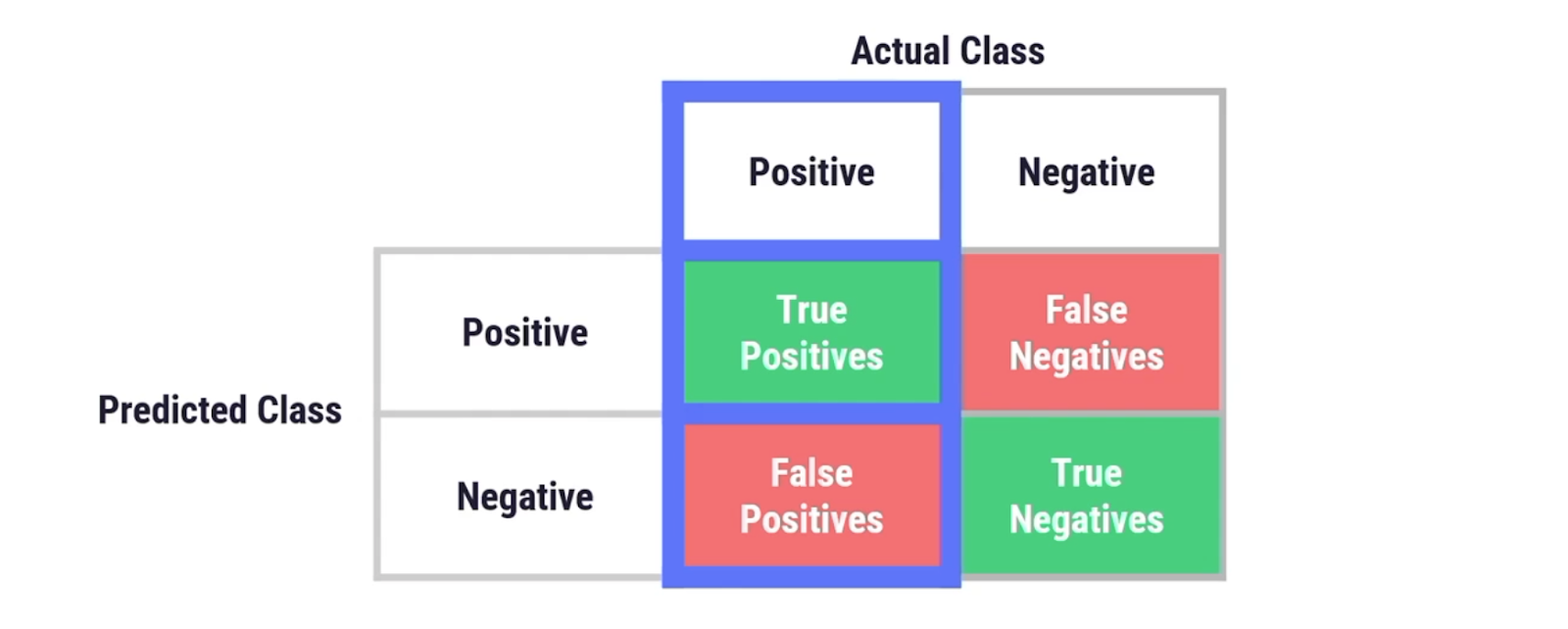
ある年齢層が優先されていないことを確認するために、各年齢層で陽性率(分配されるクーポン)が等しいことを確認したいと思います。
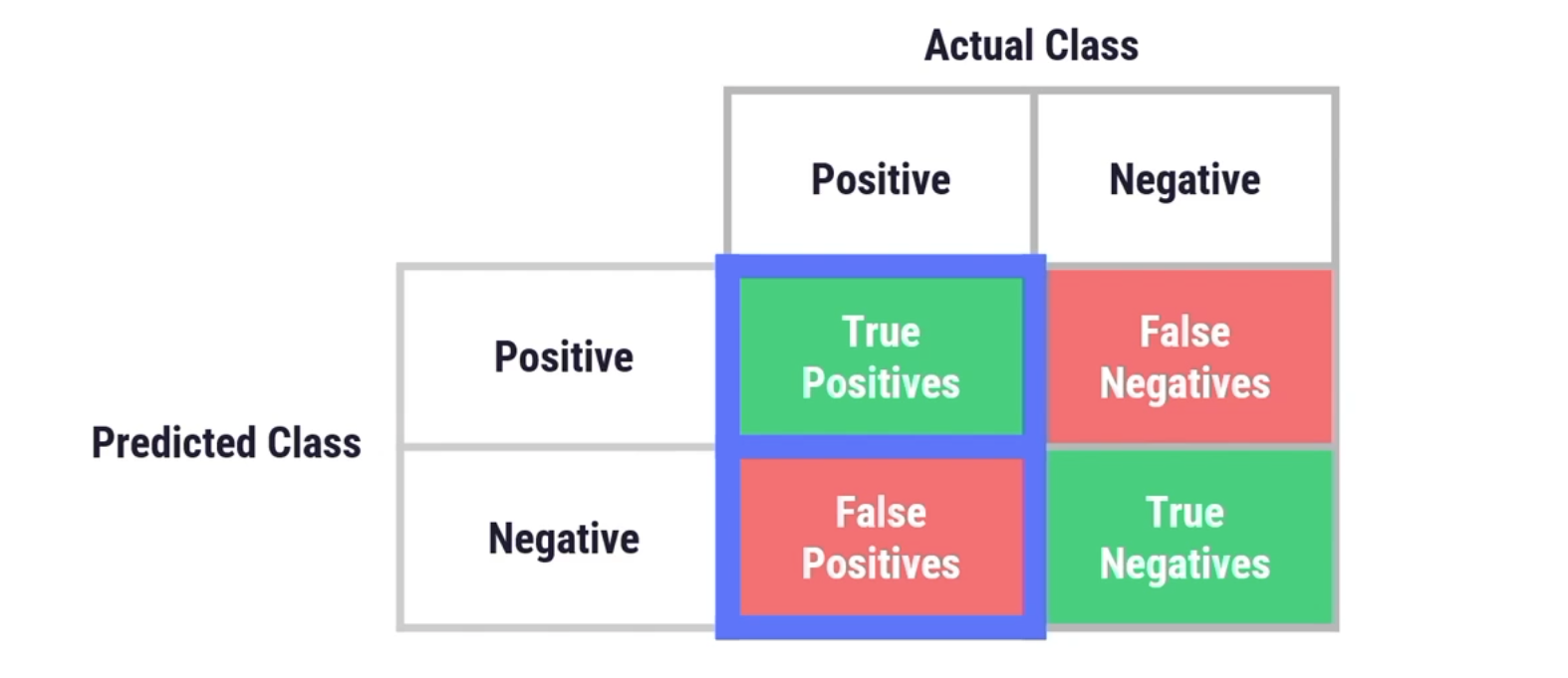
均等化オッズは、真陽性率と偽陽性率がすべてのグループ間で等しいかどうかを測定します。これは、分類器が陽性を正しく予測する能力と、陽性を誤って予測する可能性について評価するものです。この2つの率を比較し、グループ間で等しいかどうかを確認します。実際にビジネス用途に適用する場合、これは、マーケティングがあまりにも多くの費用を費やし、クーポンを利用していない人々にクーポンを送っている可能性があるかどうかを判断するのに役立ちます。
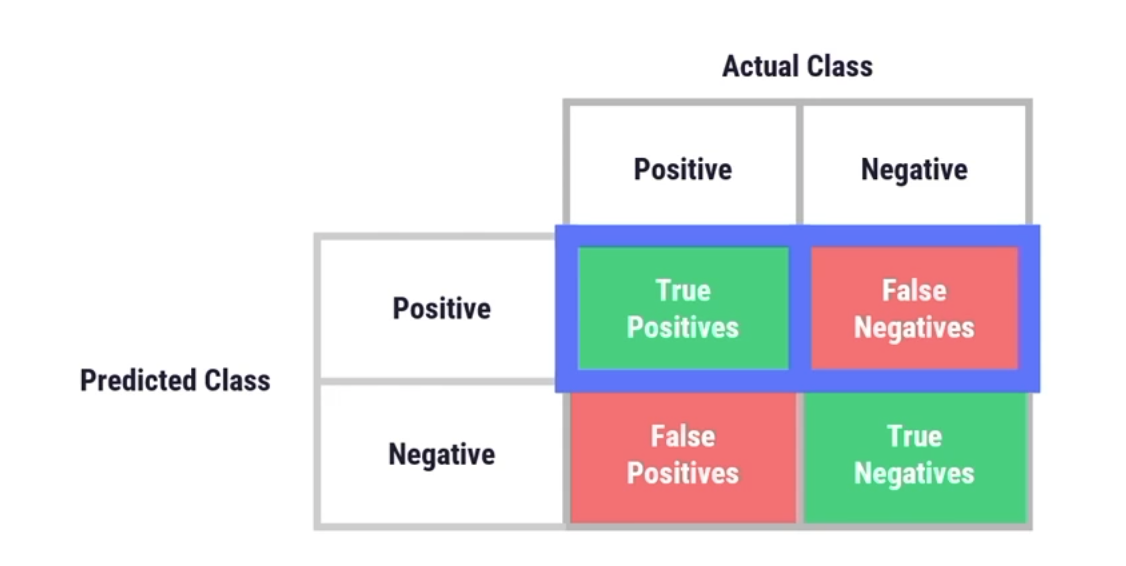
機会均等は、すべてのグループにわたる真の陽性率(または再現性)を測定します。これは、モデルが、グループ間で等しくクーポンを利用する顧客を正しく分類し、すべての顧客にクーポンを受け取る機会(すなわち、このプロジェクトで最も重要なメトリック)を等しく与えることを意味します。
最後に、予測率パリティは、全グループの適合率を測定します。
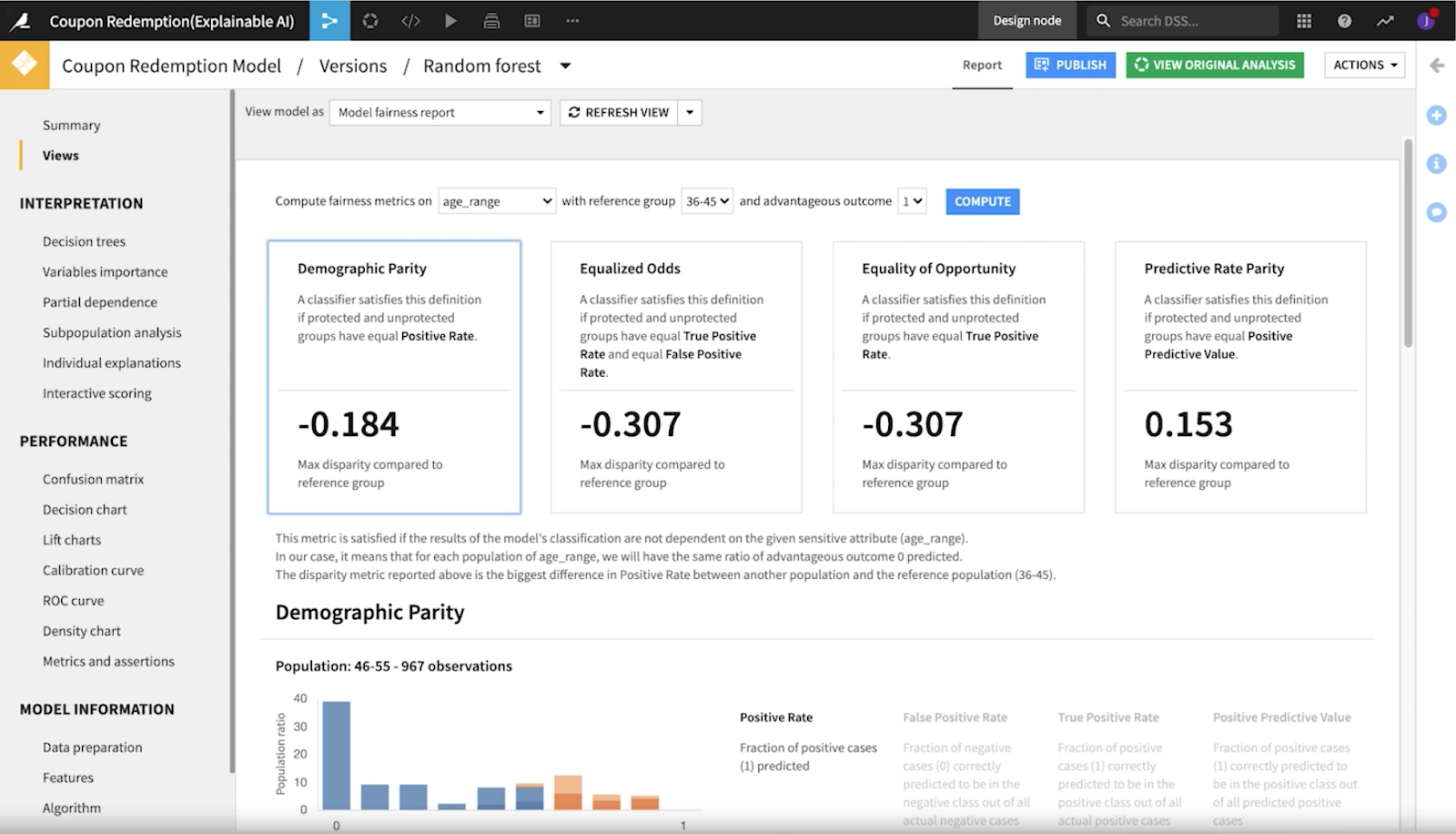
では、社会的な公平性を重視する視点で見てみましょう。Dataikuのwhat-if分析ツールを使うと、モデルのさまざまな値を切り替えることができ、個々の変更がモデル全体の予測にどのような影響を与えるかを簡単に確認することができます。この例では、年齢層を操作すると、すぐに予測値が変化することに気づきました。大きなバイアスがかかっているようですね。
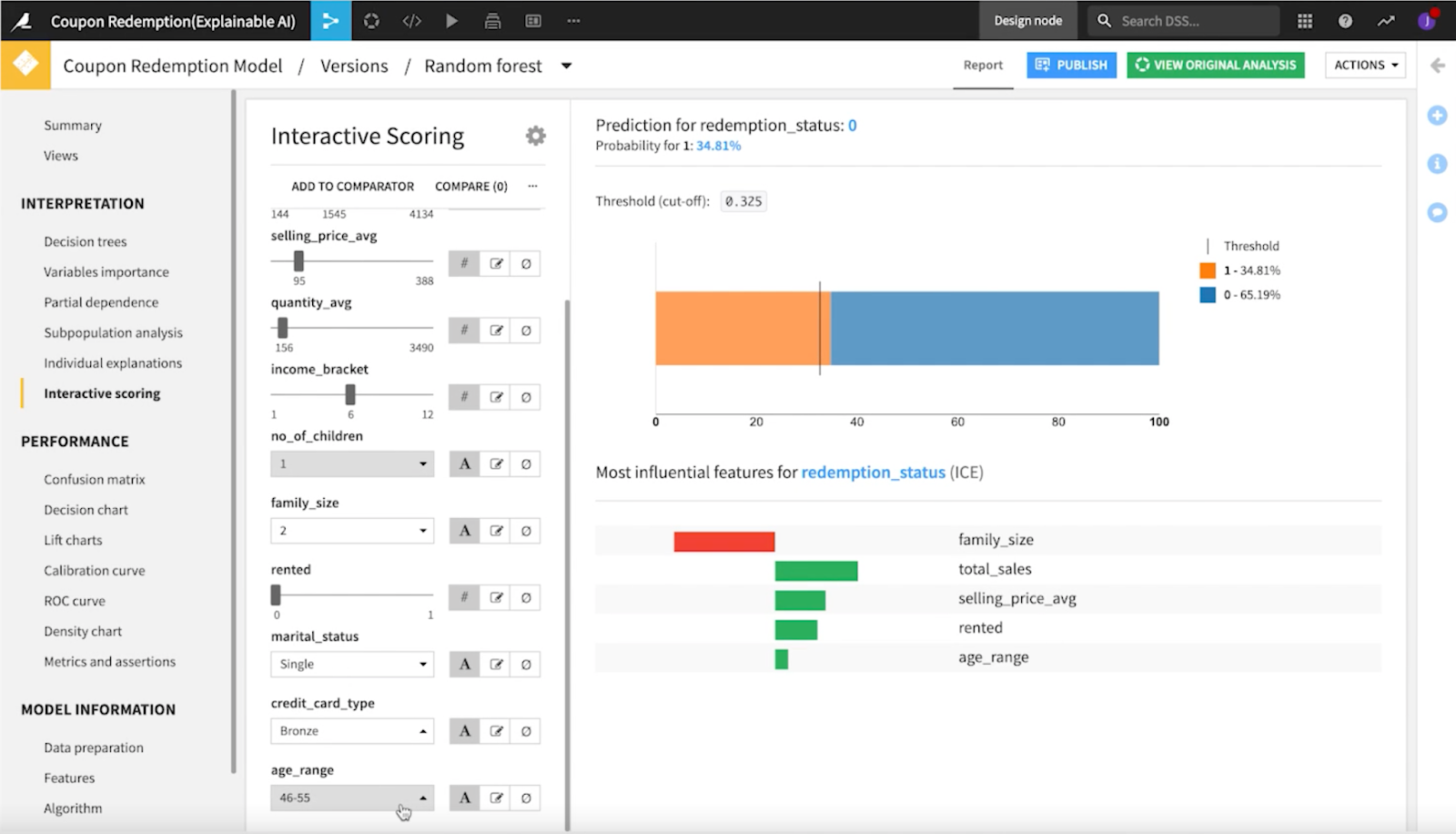
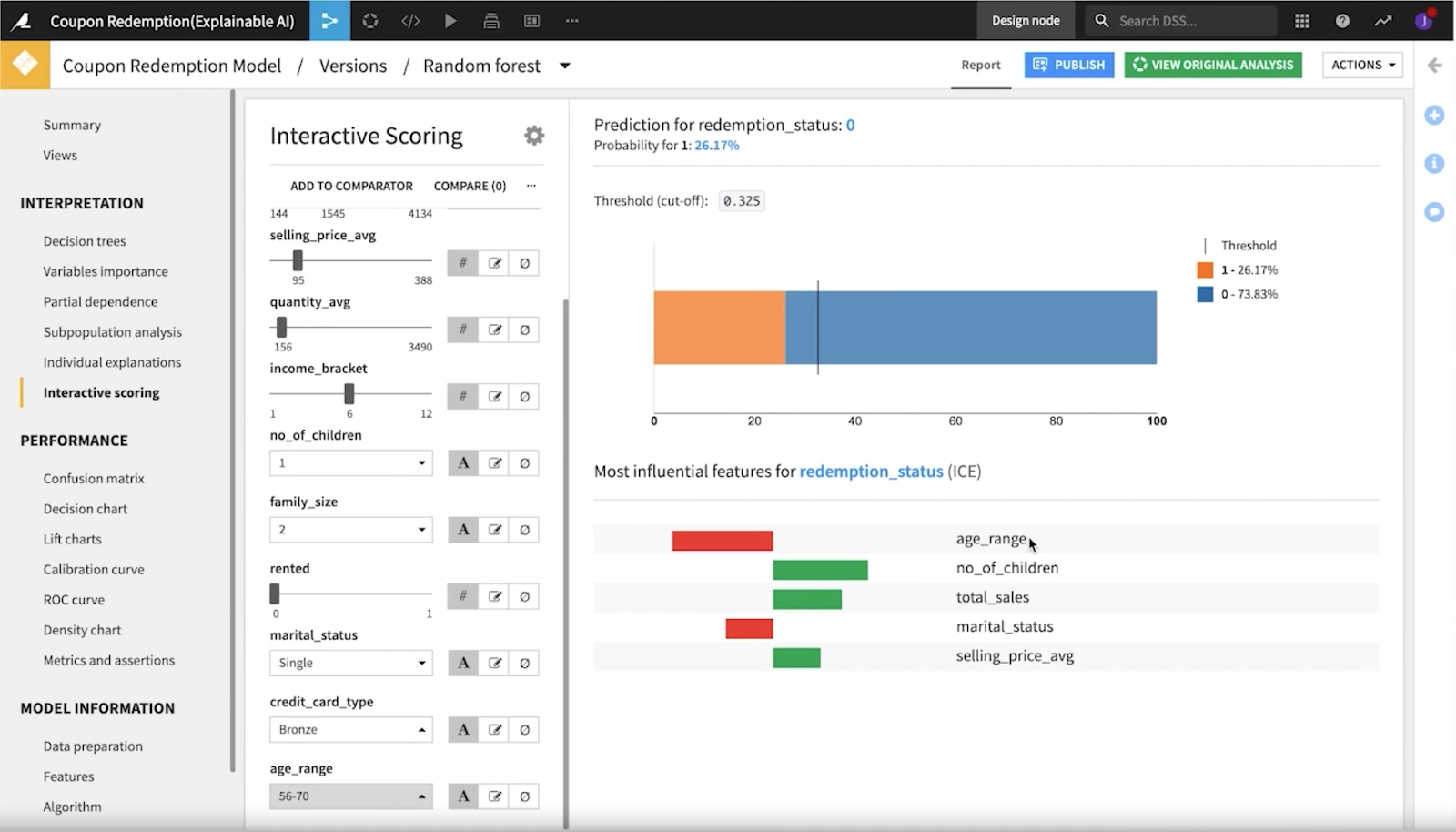
テイク2:どう改善するか?

バイアスの少ない新しいモデルを作るために、データサイエンティストはプロジェクトの原点に立ち返り、バイアスの原因となる問題点をデータセットから取り除くことを考えました。これには、年齢をモードの特徴量から削除することも含まれますが、測定目的のためにデータセットの列として含めることは変わりません。ここはダッシュボードを検討すべきタイミングと言えるでしょう。ダッシュボードは、あらゆる種類のユーザーペルソナやエンドユーザーにデータを提できる、アクセスしやすい方法です。
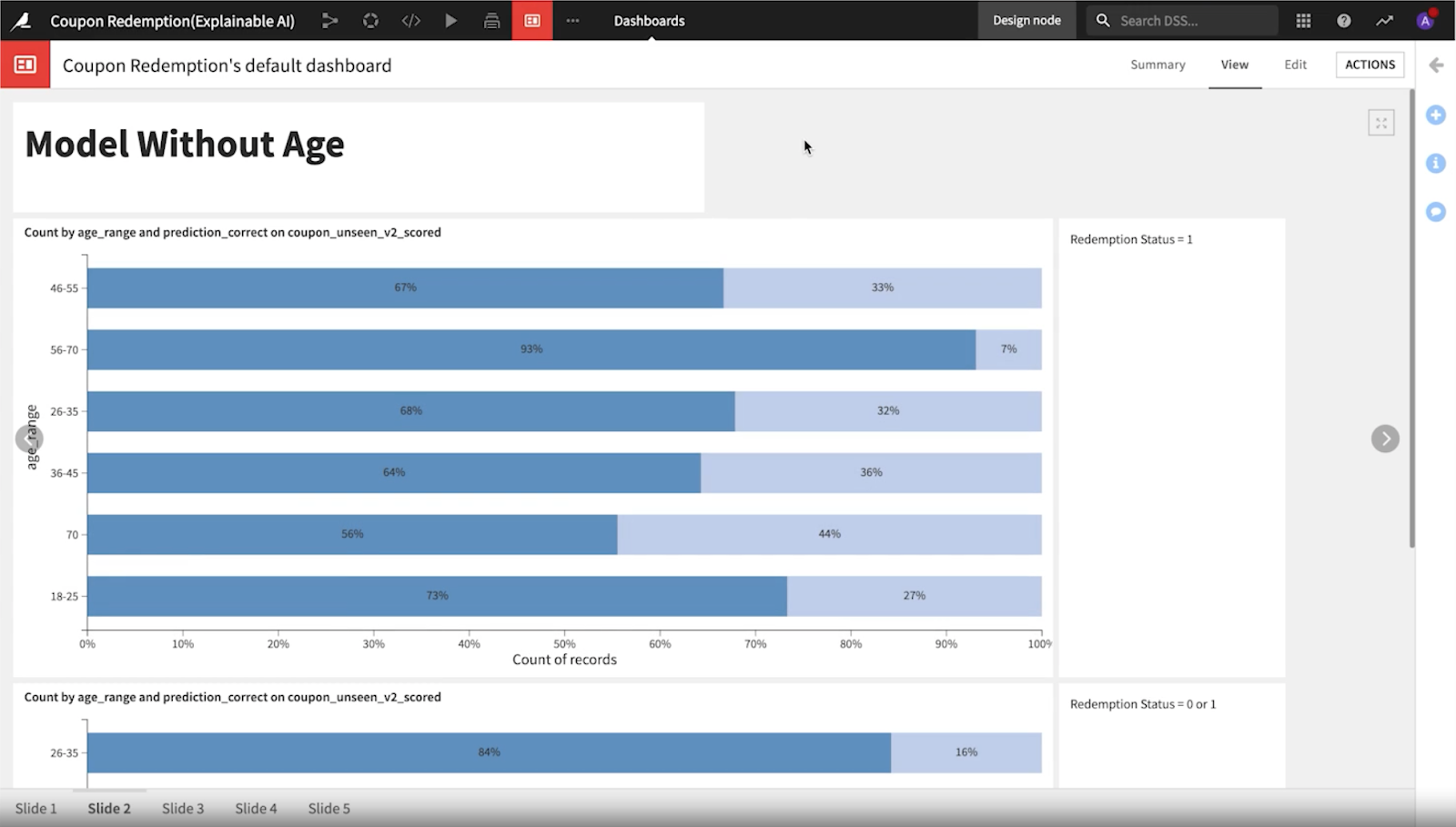
早速、チームはひとつめのモデルでは年齢層によるパフォーマンスの差が顕著であることに注目し、新しいモデルを検討しました。
2番目のモデルがどの年齢層でもより一貫性があり、少し公平であることがわかりました。また、偽陽性率もより近しくなっています。しかし、まだバイアスの懸念があったため、クレジットカードの種類、配偶者の有無、賃貸の有無、子供の数など、他の特徴についても調べることにししました。
2番目のモデルでは、特徴量のうち年齢と直接関係するものがいくつかあり、その結果、観察された格差が大きくなっている可能性があるとわかりました。これらの特徴量が実際に互いに関連しているのか、それとも独立しているのかを確認するために、Dataikuの統計タブにあるカイ二乗検定を実行しました。
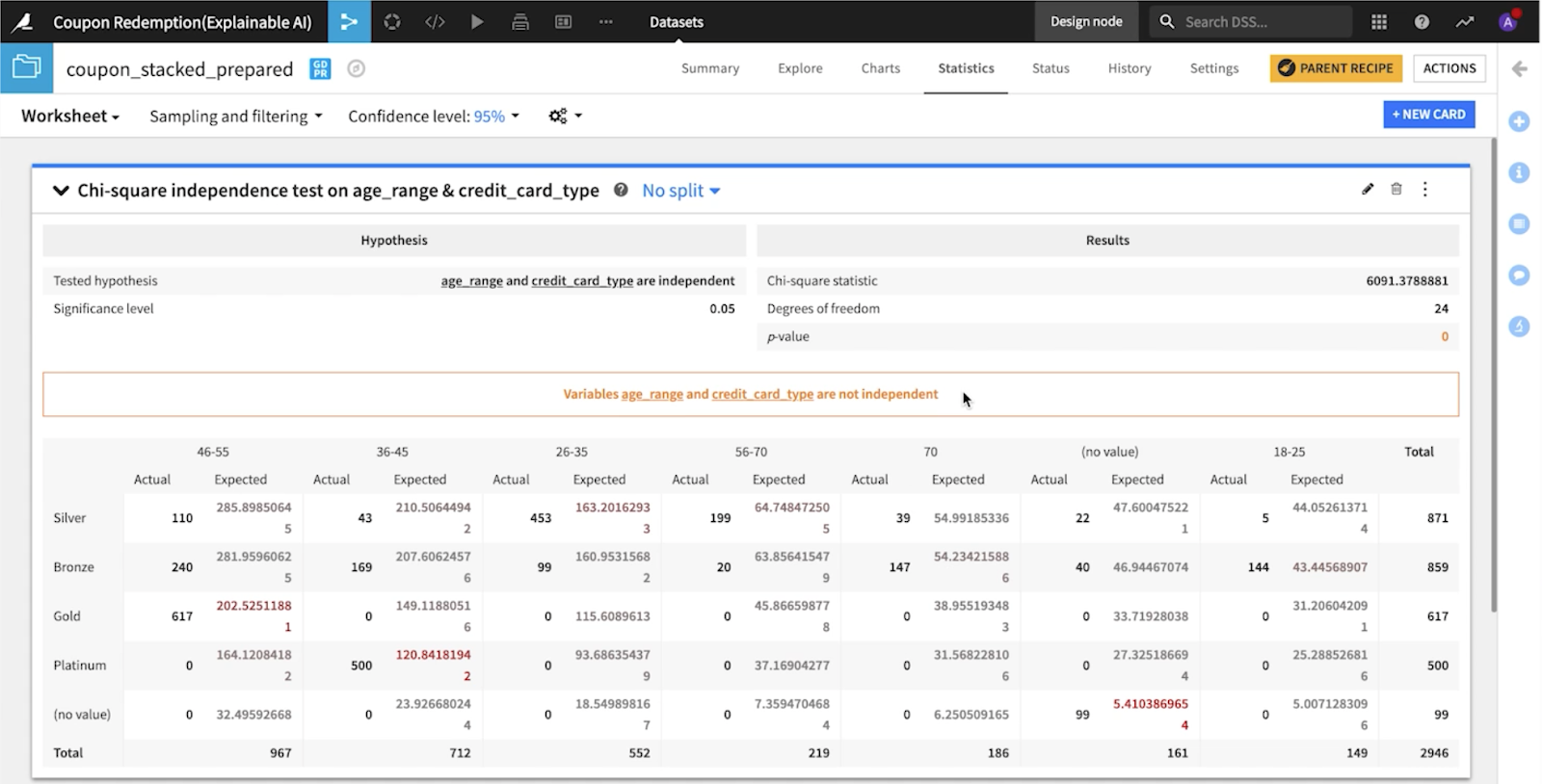
この検定では、年齢層とクレジットカードの種類を調べたところ、直感的に納得できる関係を検出することができたそうです。その結果、この特徴量も削除することが決定されました。そして、さらに検証を続けた結果、同じ理由で、3番目のモデルでは、家族のサイズと収入の大きさも削除されました。
三度目の正直: バイアスの少ない最終モデル
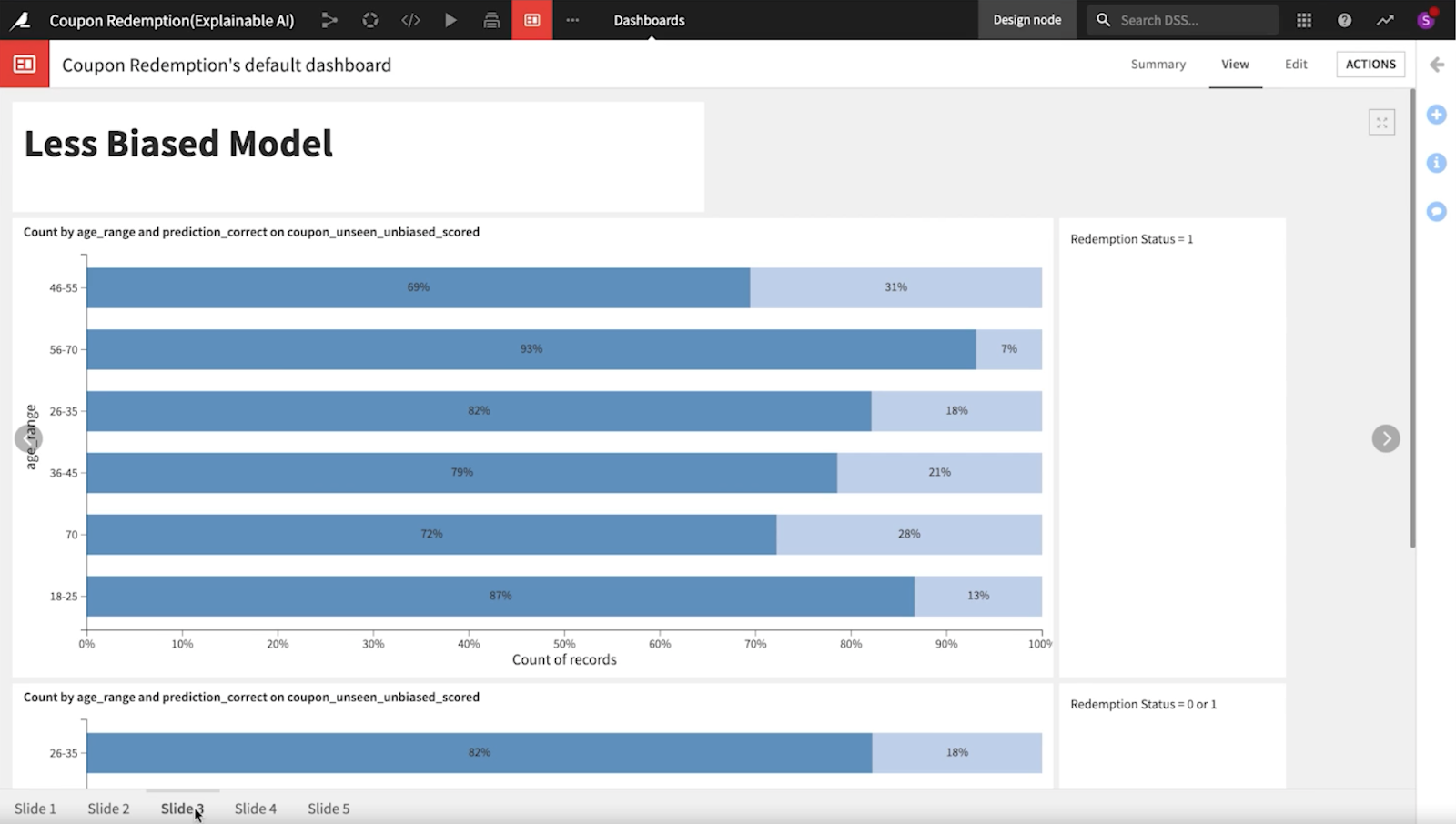
このプロジェクトではモデル開発の3回目で、データサイエンティストが各年齢層で偽陽性がますます小さくなっていることを確認することができました。このモデルは完璧ではありませんが、Dataikuのツールのおかげで、どの特徴量を捨てるべきかを特定できるようになり、バイアスが少なくなっています。
これだけでは終わらない
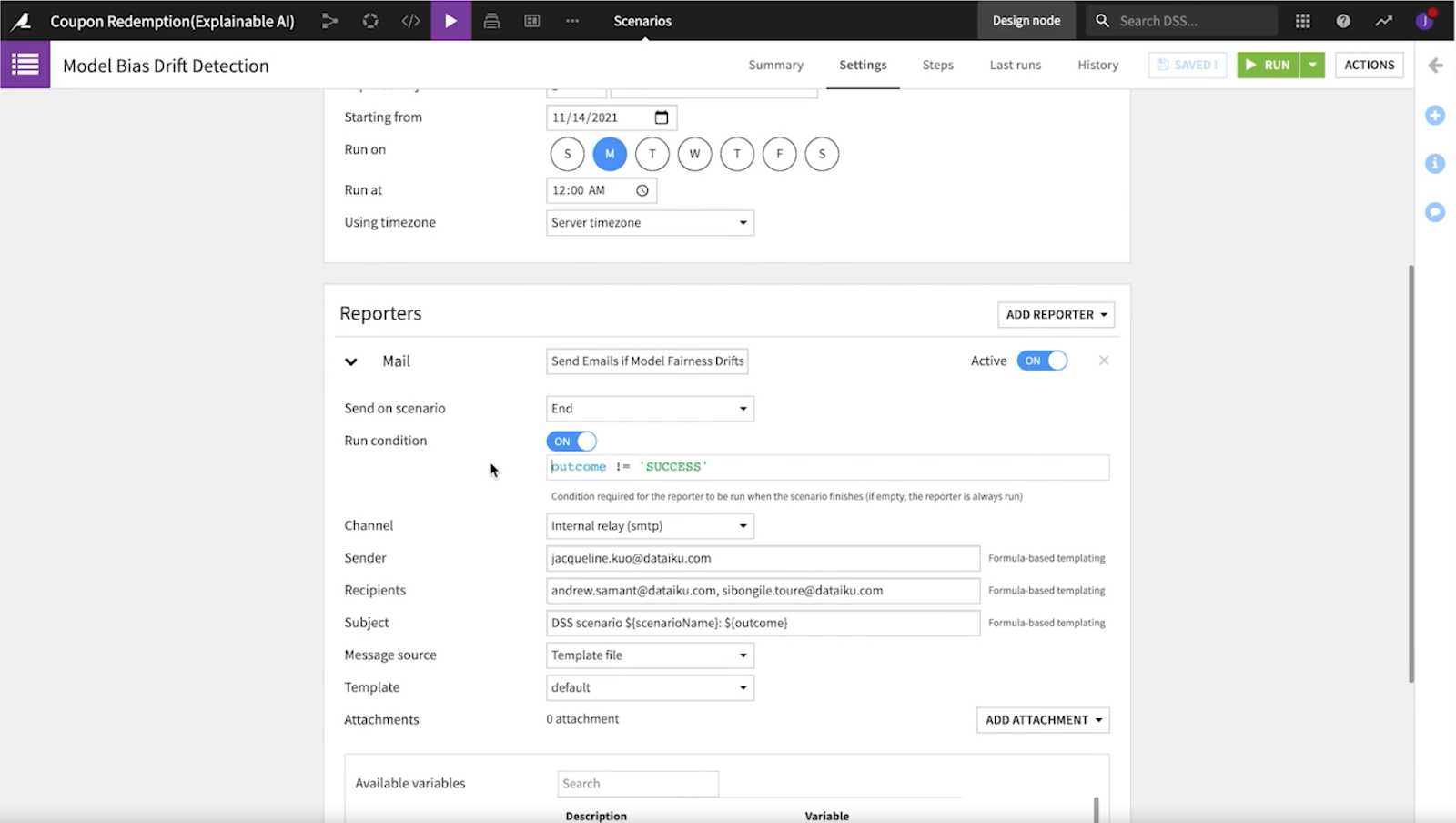
Dataikuでできることは、上述のようにモデルの開発を改善されたかたちで繰り返せるということだけではありません。メトリクス、チェック、シナリオを使用して、作成したモデルのパフォーマンスを長期にわたって追跡することもできます。
メトリックスとチェックは密接に関係しており、データセットを検査し、時間の経過とともにモデルの進化を追跡できます。シナリオ機能では、モデルのメトリクスとチェックに関連するジョブをスケジュールすることが可能です。フローにシームレスに統合された検出ツールにより、自動的にバイアスを発見するアラートを設定することができます。
クーポン引換プロジェクトでは、データサイエンティストはカスタム のpythonメトリックと、その指定値が特定の閾値を超えたときに表示される確認機能を作成しました。
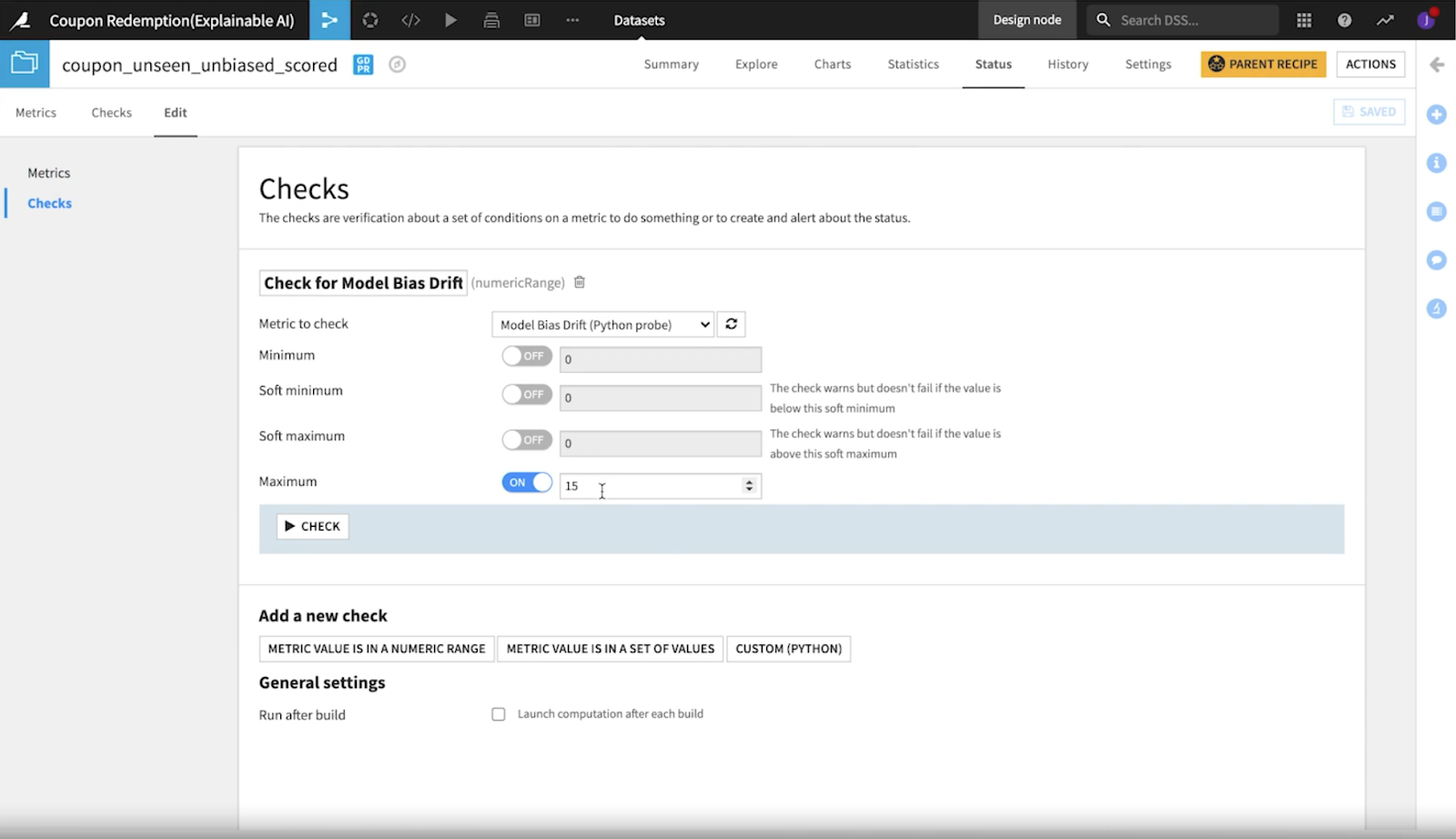
大規模にAIを管理することと、重要なポイント
なぜそれが重要なのかでしょうか?バイアスを抑えることは、より明白な理由(悪いAIという見出しから外れること)だけでなく、急速に進化する技術領域におけるAIアプリケーションの長期的な健全性といった、より微妙な理由からも非常に重要です。
AIシステムのより大きなリスクを理解することは、あらゆる業界のあらゆる組織のAIリーダーにとって最優先事項です。組織が取り組むべき相互に関連する3つのコンセプトは以下の通りです。
- AIガバナンス(リスクとコントロール)
- MLOps(プロジェクト・ライフサイクル・マネジメント)
- 責任あるAI(透明性と公平性)
とはいえ、データリーダーだけで終わるわけにはいきません。データサイエンティストは、上記の例で示したように、モデル構築プロセスに透明性のあるレポートとモデルの公平性のベストプラクティスを組み込み、AIの拡大に伴うこれら3要素において、その役割を果たす必要があります。また、データサイエンスチームは、AIガバナンスチームと連携し、AIパイプライン全体を通してプロジェクトの目標に沿って調整する必要があります。
<図>
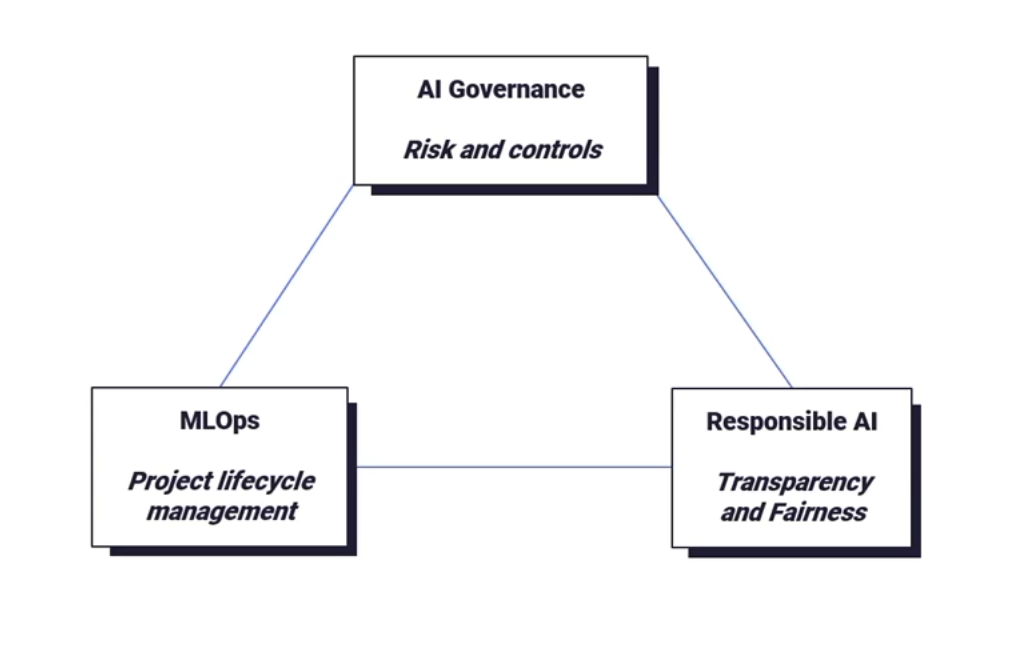
データサイエンティストは、AI活用を拡大しようとする組織全体の計画における単なるオプションプレーヤーではありません。より公平なモデルのためにバイアスを減らすことへの彼らの貢献は、責任あるAI、MLOps、AIガバナンスの中核的な一面です。しかし、バイアスを認識し、公平なモデルを構築する上で彼らの役割を果たすためには、データサイエンスチームが自由に使える適切なツールが必要です(少なくとも、それは大いに役立ちます)。だからこそ、Dataikuが提供するバイアスを識別し理解するのためのサポートは大きなゲームチェンジャーとなります。
Dataikuの責任あるAI
DataikuのデータサイエンティストによるDataikuのクーポン引換プロジェクトの詳細については、Dataiku Product Daysのセッションをご覧ください。
原文:Scaling AI Safely — What Role Does a Data Scientist Play?