この記事では、どのようにDataiku上で財務モデルを作成するかを紹介します。Excelのようなスプレッドシートベースのツールは、財務モデリングのための最も一般的なツールの一つであり、投資分析、損益モデリング、リスク管理など、あらゆる種類の業務に使用されています。なぜでしょうか?スプレッドシートには利便性があり、長い間使われてきており、今後も使われ続けるでしょう。しかし、いくつかの欠点も存在します。すなわち、インターフェイスが半構造的でもろく、特に大量のデータを扱う場合、スケジューリングの自動化ができないことなどが挙げられます。
基本的に、スプレッドシートベースのツールは、データを前面に出し、計算ロジックはバックグラウンドで参照できるようにしておきます。特定の計算に対するデペンデンシーグラフを表示することはできますが、複数のタブを持つスプレッドシートの中で、計算とデータの相互関連性など、全体のストーリーがどこで始まり、どこで終わるのかを把握するのは困難です。実世界のスプレッドシートは、時間の経過とともに複雑になる傾向があり、作業の理解や維持が難しくなります。また、カスタマイズを行いたければ、VBAマクロを書かなければなりませんが、これもまったく別のスキルを必要とします。

スプレッドシートは、企業のポートフォリオ・チームが投資銘柄の選択に関する完全な情報追跡が可能な状態で構築、管理、共同作業を行うような開発には不向きであることは確かです(つまり、一つの部門内では、ポートフォリオ構築のような、より包括的なワークストリームに自動化された形でアウトプットを流す必要があります)。スプレッドシートをベースとするツールは、そのほとんどがクラウドベースであるものの、様々なソースから引き出された大量のデータを操作する際に、他の計算オプションを活用するプッシュダウン機能はありません。また、APIサービスのような異なるタイプのデータソースに接続することも困難です。
Dataikuは、データに対して計算やその他の操作を実行するためのビジュアル・パイプラインを備えています。Dataikuは、ユーザーがフローの各ステップをクリックすることで、入力データ、処理、処理結果を見ることができるように、計算のビジュアル・フローを前面に出しています。これがインターフェイス上の根本的な違いです。 また、Dataikuにはデータプロファイリング機能があり、表計算ソフトの問題の主な原因であるヒューマンエラーを発見し、データ品質チェックを自動化できます。
このブログポストでは、NPV/IRR/投資回収期間、損益計算書作成、回帰例を用いた市場ベータ計算をDataikuでどのように再現できるかを概説します。
スプレッドシートベースのツールを使ったNPV/IRR/投資回収期間
典型的な財務モデリングの例では、5種類の項目があります。以下の項目は、財務モデリングに限らず、スプレッドシート・モデルによく見られるものです。
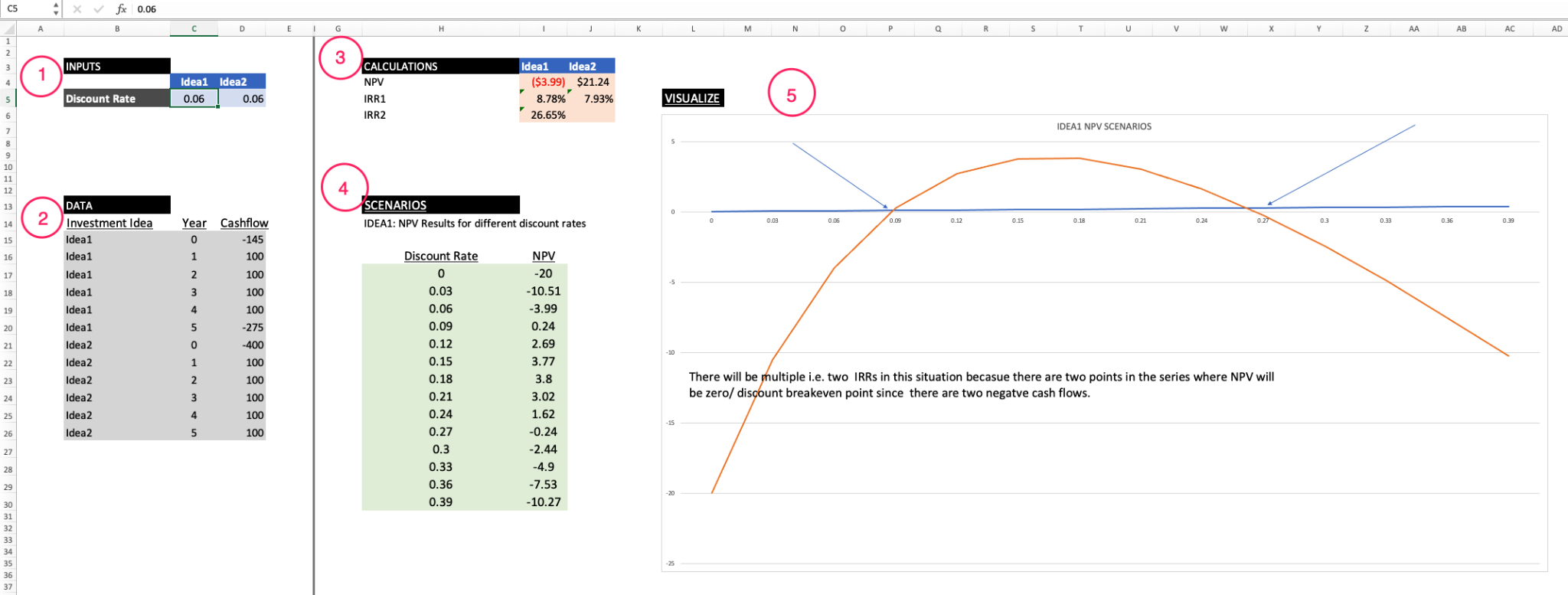
スプレッドシートの例
上記の図の通り、以下の項目があります:
- 変更可能なプレースホルダ (モデルの仮定)
- 静的な入力データ
- 中間計算と最終的に関心のある計算
- 様々なモデル仮定シナリオでの計算
- 計算とシナリオデータの視覚化
以下では、IRR/NPV/投資回収期間のDataikuフローをご覧いただけます:
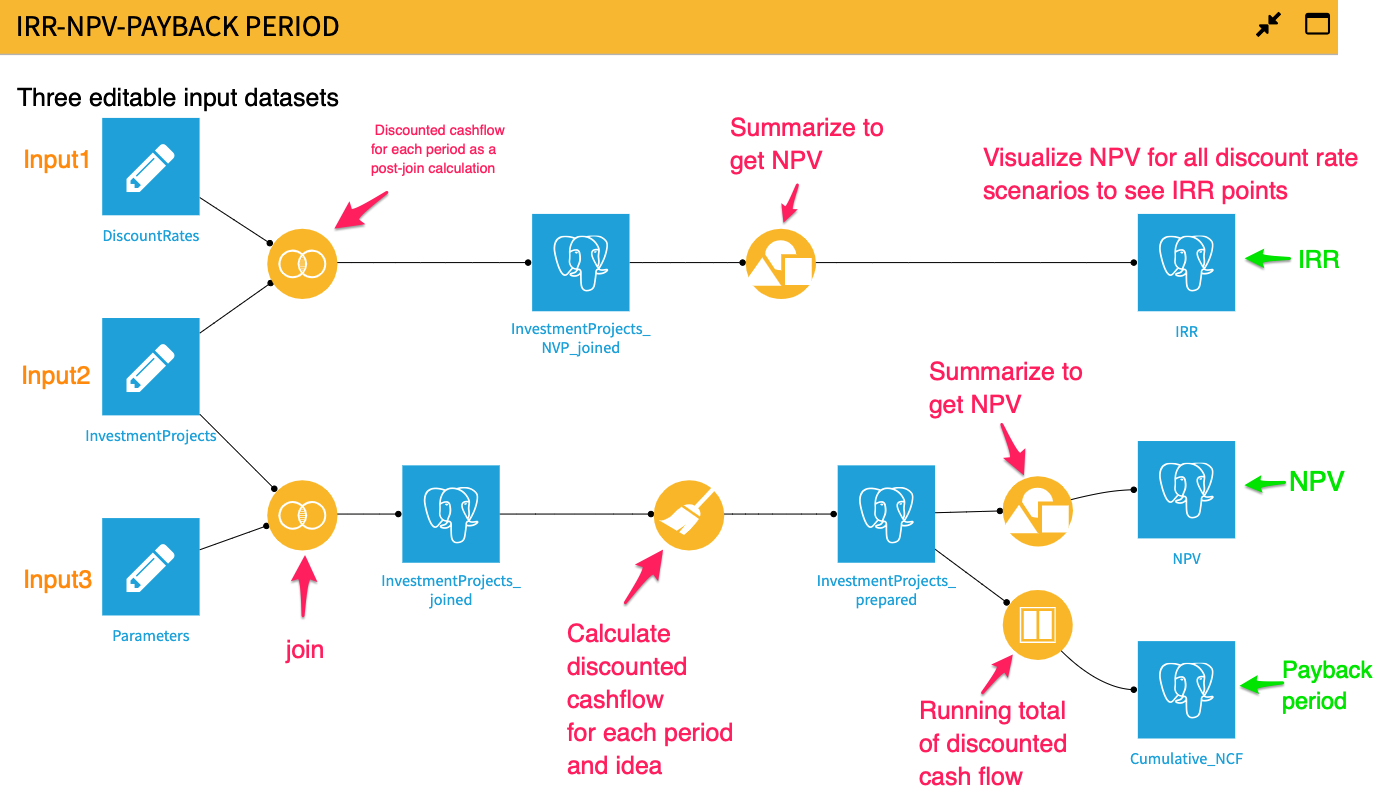
ステップ1:
割引率(モデルの仮定)、将来のキャッシュフロー(データ)、割引率1~40%(複数の割引率によるシナリオ)を3つの編集可能なデータセットに分けます。編集可能なデータセットを選んだ理由は、他のDataikuのデータセットタイプとは異なるからです。編集可能なデータセットは、Dataiku UIまたはDataikuアプリケーションを通じて変更することができます。
ステップ2:
データと割引率をつなげて1つのデータセットを作成します。セルの参照を行うスプレッドシートとは異なり、計算のために列/フィールドを参照できるように、異なるデータセットを結合させる必要があります。
ステップ3:
次に、各投資アイデアと期間について割引キャッシュフローを計算するために、ビジュアル準備レシピで数式処理工程を作成します。

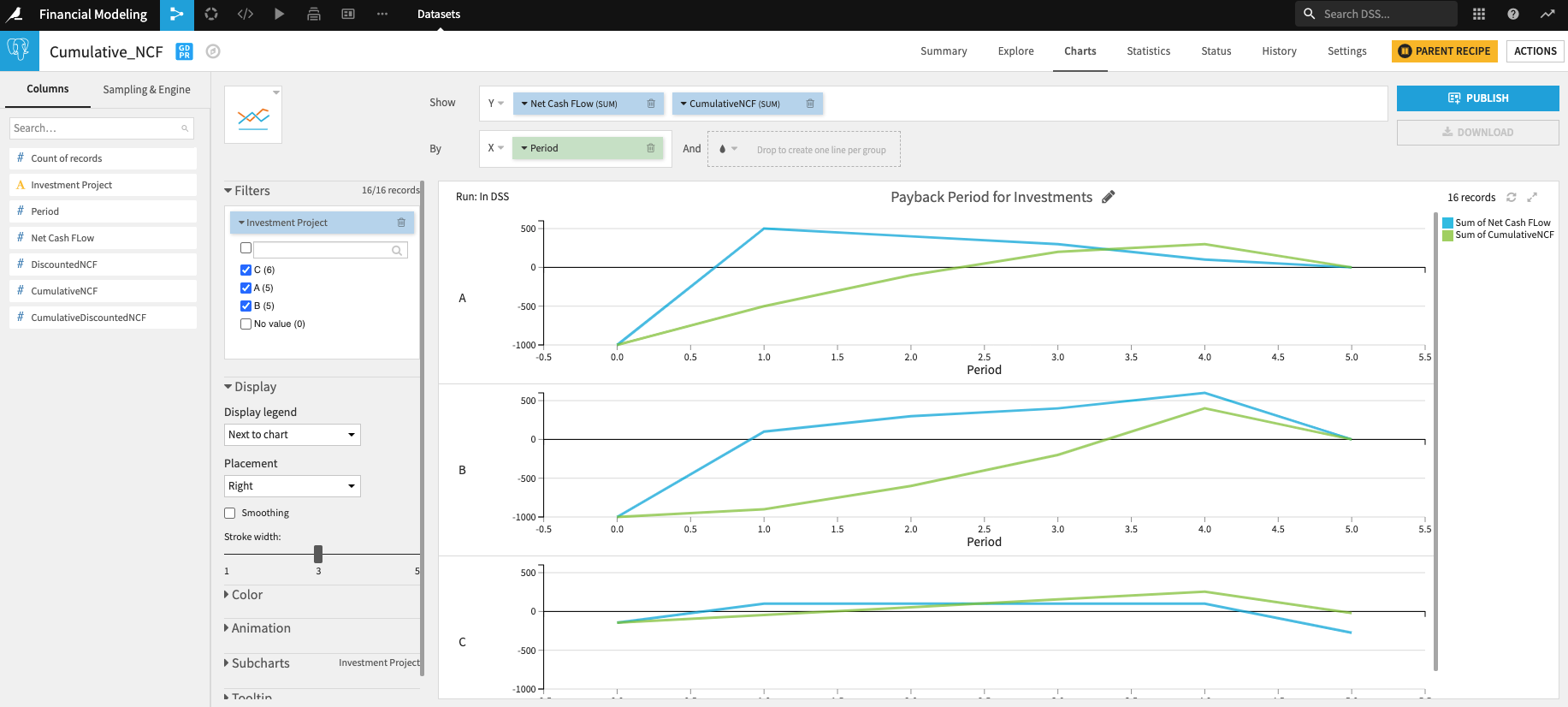
この方法の利点は2つあります: キャッシュ・フローを合計して正味現在価値を求めることができるようになっただけでなく、Windowsのレシピを使って割引キャッシュ・フローの状況を表示し、投資回収期間を確認できるようになったのです。
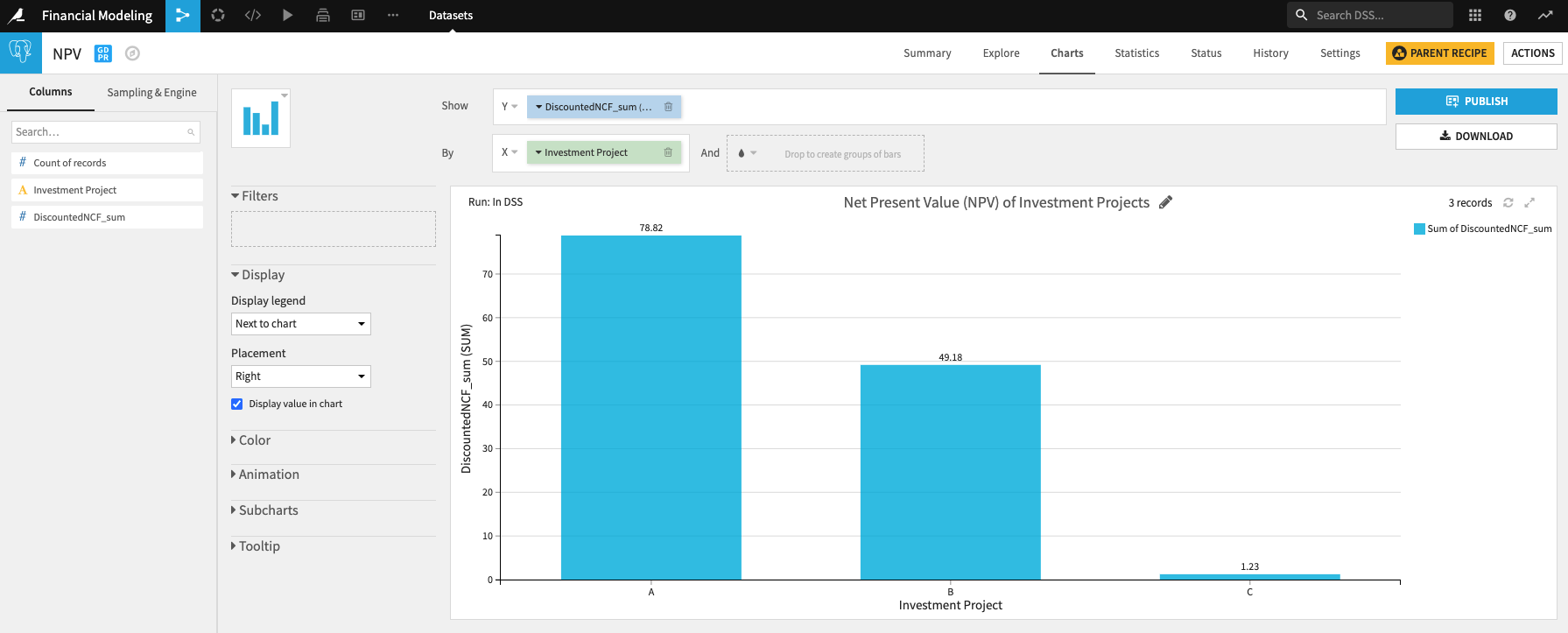
結果を可視化することで、以下のことがわかりました。
IRR:この投資アイデアには2つの負のキャッシュフローがあるため、IRRが2つあることがわかりました。

NPV:
Payback period:
表計算ベースのツールを使った損益計算書の作成
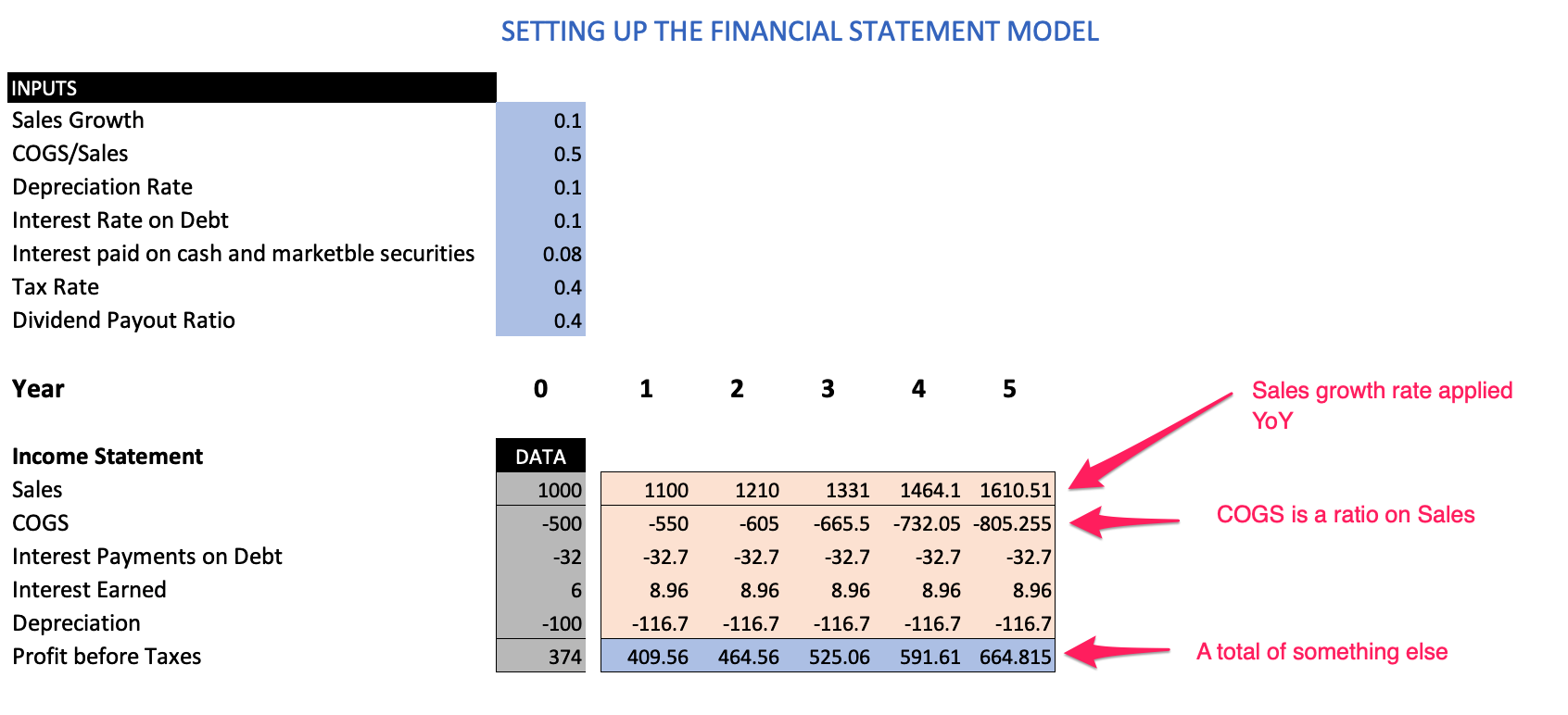
ここで、重要な点は以下の通りです:
1: 年複利成長率(CAGR)に基づき、左から右へ水平方向に適用される計算(例:売上高1年目から5年目まで)
2: 何かの比率関数である計算項目(例:売上原価)
3: 他の計算や小計に基づく計算項目である。
Dataikuでこの損益モデルを再現してみましょう:

Step 1:
過去のベースラインデータをアップロードする(インプット1)。どのデータソース(例:Snowflake)からも取り込むことができます。2番目のインプットは、各損益項目の計算がスムーズになるように、特定のフォーマットで構造化する必要がある計算ルールを取り込むためのものです。
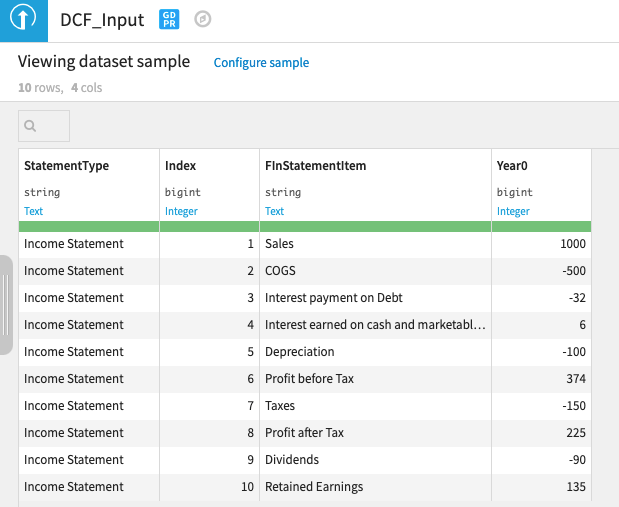
インプット1:過去のベースライン

インプット2: 計算ルール
計算ルール(データセット)は、ある期間の各損益項目の値が、それ自体に適用される比率の割合なのか、あるいは何か別のものなのかを指定する(例えば、COGS は売上高に適用される比率である)。また、単に金額とすることもでき、その場合は計算は不要である(例:負債の利払い)。INDEX 列もあり、これを使用して P&L 項目を特定の順序で並べ替えることができます。
5年目までの売上を計算するために、ビジュアル・プレパレーションのレシピでカスタマイズ・ステップ「成長率」を使用します。開始列」の値、CAGR、期間数を指定することが可能です。
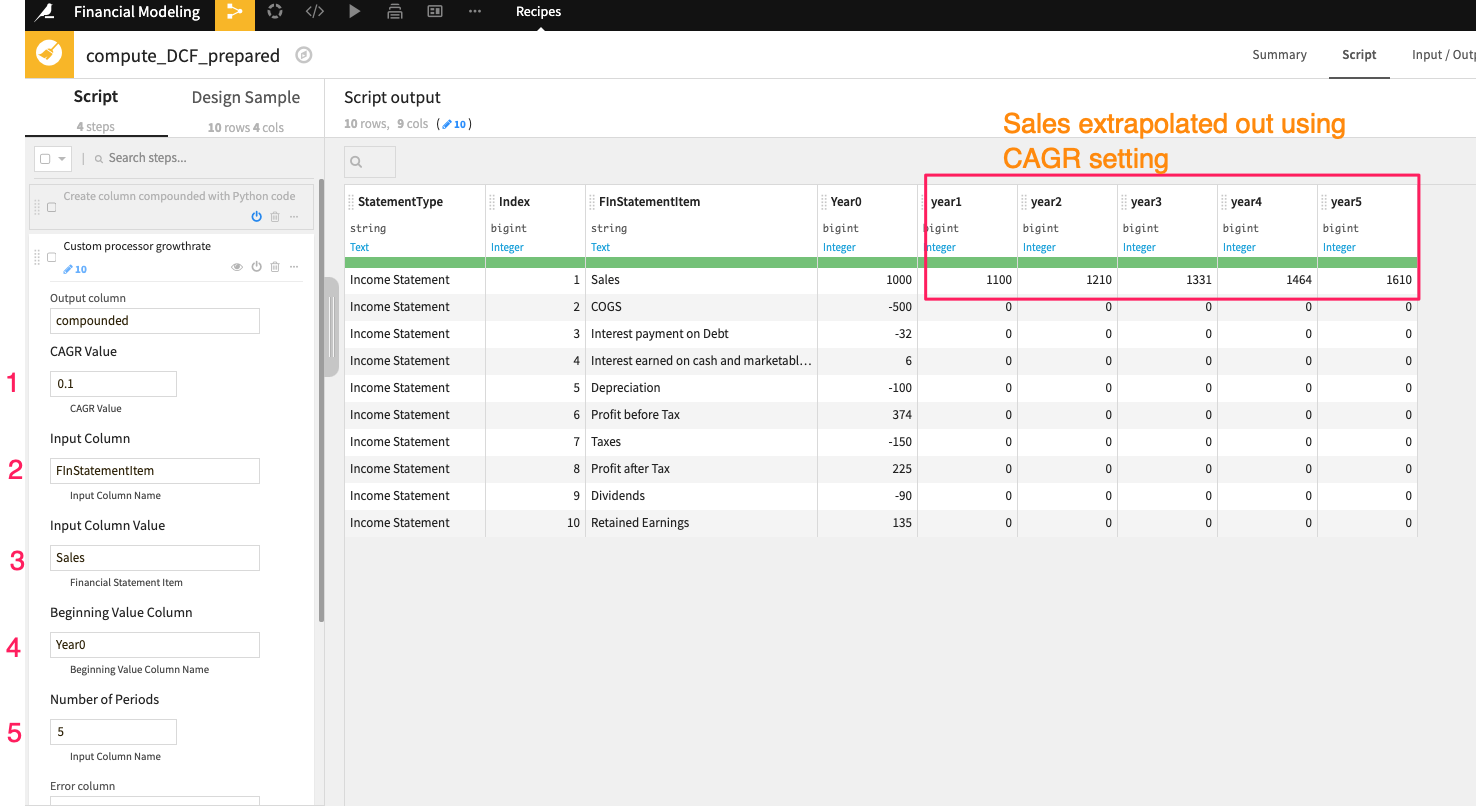
ここで、ビジュアルジョインのレシピを使ってデータセットを結合します。ここで重要なのは、ジョイントレシピの条件の1つが、計算ルールデータセットの "AppliedOn "カラムとヒストリカル・ベースラインデータセットの "FinStatementItem "カラムを結合することになっていることで す。これは、各損益項目を対応する計算ルールとその要素にマッピングするために行います。
いくつかのリシェーピング操作の後、以下のように構築された損益計算書が出来上がります。
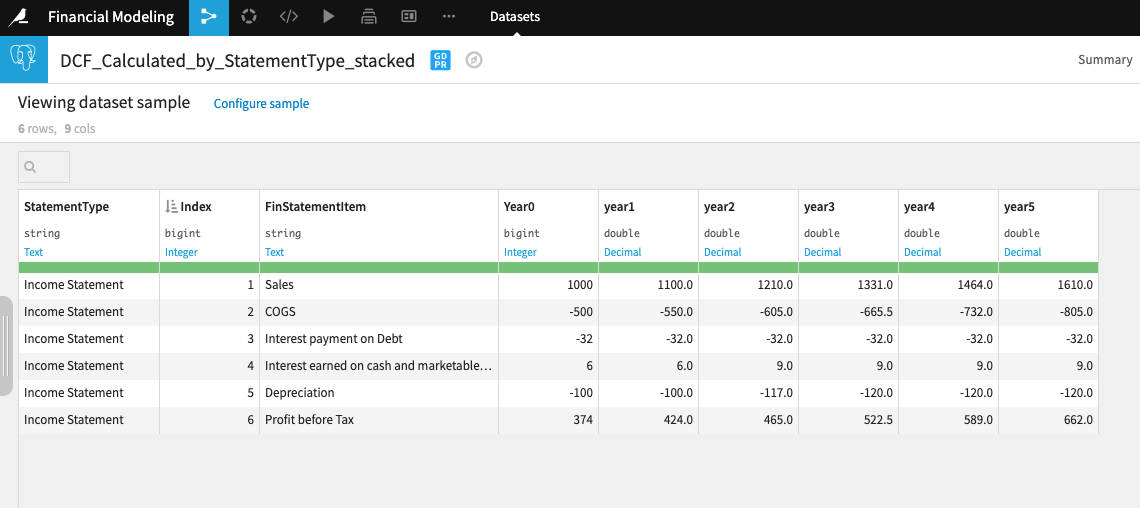
損益予測を可視化し、Dataikuダッシュボードに公開することが可能です。
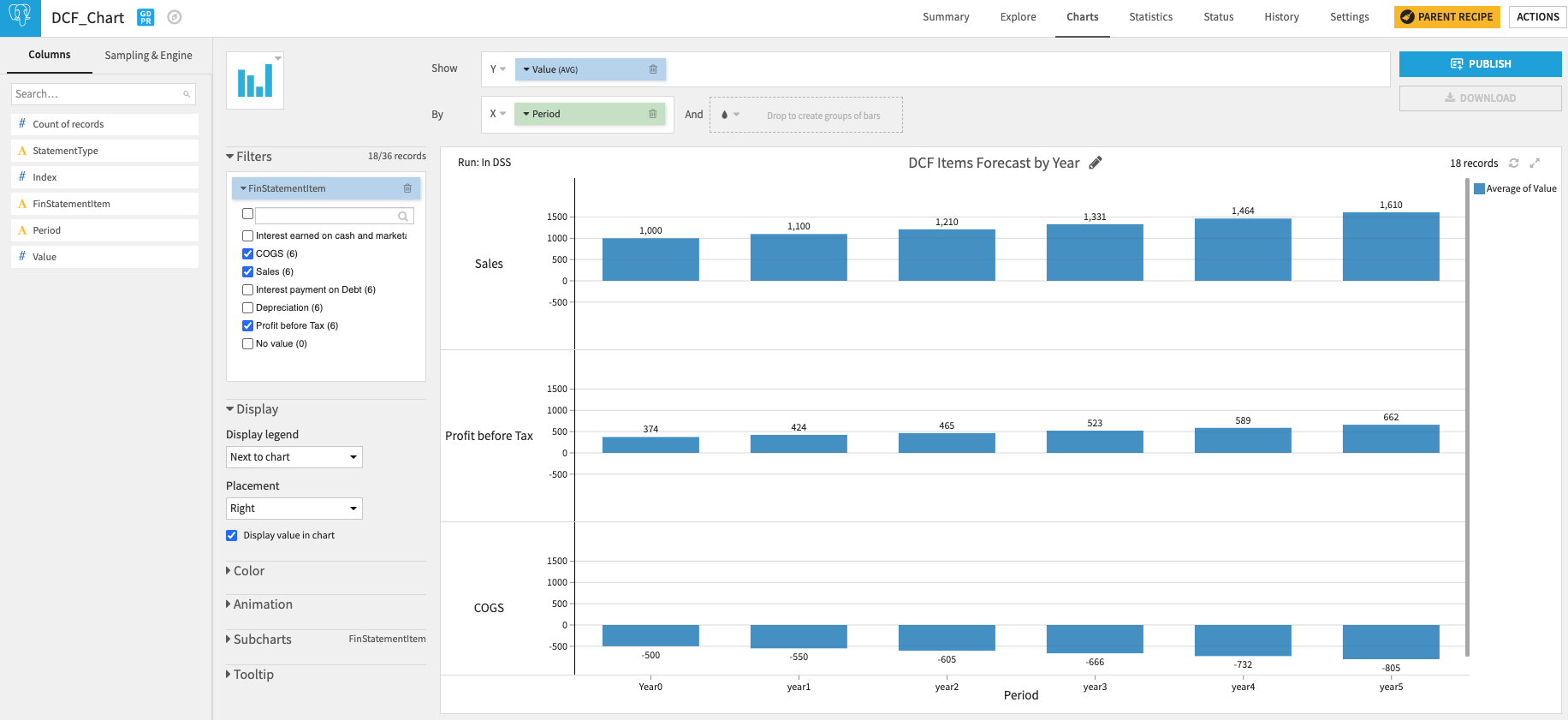
このDataikuフローをDataikuアプリにパッケージ化し、ビジネスユーザーと共有することも可能です。ビジネスユーザーは、自身の過去のベースラインや 計算ルールをアップロードして、入力に応じた出力を出すことができます。これは、Dataikuフローをアプリケーションの形で利用可能にする一般的な方法です。データを多くの人々(モデルの作成や開発に関与していない人々も)の手に渡すことで、組織はより多くのチームが洞察を利用できるようになり、最終的に日々の意思決定の改善につながります。
上述した事例は、財務モデリングの一部の例です。さらに、Dataikuは、機械学習による分析プロセスを実施または運用するために活用することもできます。
DataikuのビジュアルMLの例:
資本資産価格モデル(CAPM)は、基本的にキャッシュフローを割り引くための資本コストを計算するものであり、株式評価において重要なインプットである。CAPMは、市場リターンとの共分散から企業の資本コストを導出し、実際のベータ値(β値)を算出する。基本的には、市場リターンに対する株式またはポートフォリオのリターンの感応度を示します。
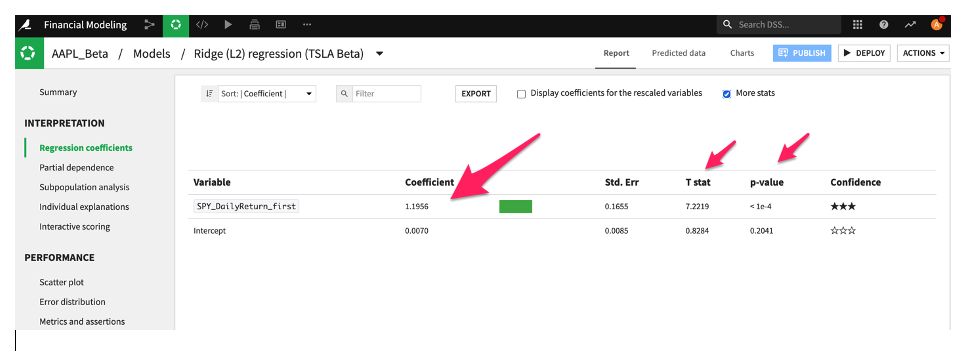
あるいは、S&P500 の対数リターン(独立変数)と株式のリターン(従属変数)を使って回帰を行い、回帰係数を求めることでベータを計算することもできます。Dataikuでは、Pythonのコードレシピを使用してプログラムでこれを行うか、私たちのビジュアルMLを介して行うことができます。以下の回帰アルゴリズムのカタログを参照してください。

回帰係数(すなわち、市場ベータとそれに対応するt統計量とp値*)の例です:
通常のマーケット・ベータとは別に、イールド・カーブ・ベータや、バリュー、規模、収益性、投資などの典型的な要因と銘柄のリターンとの関係を探ることができます。これにより、金利環境の変化に対するグロース対バリューのような特定の株式プロフィールの感応度をよりよく理解できるかもしれません。また、Dataiku ビジュアル ML を使ってイールドカーブの変化を他の要因に回帰し、R2 乗のような指標を使って最終変数間の多重共線性をチェックすることもできます。
ボラティリティ・ジャンプのような非常に非線形な事象があることは明らかで、そのような事象では、価格がボラティリティにジャンプを経験する銘柄を特定するのに役立つニューラルネットのようなML技術が必要になります。バイナリであるターゲット変数(水平線X=y/nにおける低ボラティリティ)と、株式のボラティリティに影響を与える可能性のある入力変数(株式のヒストリカルベータ、ボラティリティ、ディストレスリスク、配当リスク、過度なバリュエーション)を含むデータセットを使用します。Dataikuは、ディープラーニングのためのビジュアルMLと、コードベースのインターフェースを介したモデル構築のためのコードレシピを提供しています。
スタンダード・チャータード銀行、メルセデス・ベンツ、ロイヤル・バンク・オブ・カナダなど、世界中の多国籍企業が、そのプロセスをスプレッドシートからDataikuに移しつつあります。そのため、チームの生産性が向上するだけでなく、より多くの人々が日常的にデータを利用するようになり、セルフサービスアナリティクスの文化が広まっています。
さらに先へ: 表計算ソフトからDataikuへ
日常的なAIは、データとAIの活用をシステム化することに尽きます。取り扱いにくいスプレッドシートからDataiku(財務モデリングを含むすべてのプロセス)への転換は、絶好のスタート地点です。Ebookはこちらからダウンロード。
原文はこちら:Moving From Spreadsheets to Dataiku for Financial Modeling