前回からの続き:[SIGNATE練習問題]自動車の評価をやってみた#2 〜Metric Learningしてみた〜
前回までのまとめ
SIGNATEの練習問題 自動車の評価にトライ。最近流行っている距離学習も使えそう。
ライブラリ
まずはライブラリのインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import PCA
import math
from sklearn.manifold import TSNE
import metric_learn
from mpl_toolkits.mplot3d import Axes3D
%matplotlib inline
from sklearn.ensemble import GradientBoostingClassifier, AdaBoostClassifier, ExtraTreesClassifier, RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
データ読み込み
df=pd.read_table('./data/train.tsv')
test_df = pd.read_table('./data/test.tsv')
df.head()
説明変数のラベル化
df['class']=df['class'].apply(lambda x:1 if x=='unacc' else(2 if x=='acc' else(3 if x=='good' else 4)))
df['buying']=df['buying'].apply(lambda x:1 if x=='low' else(2 if x=='med' else(3 if x=='high' else 4)))
df['maint']=df['maint'].apply(lambda x:1 if x=='low' else(2 if x=='med' else(3 if x=='high' else 4)))
df['doors'][df['doors']=='5more']=5
df['persons'][df['persons']=='more']=5
df['lug_boot']=df['lug_boot'].apply(lambda x:1 if x=='small' else(2 if x=='med' else 3))
df['safety']=df['safety'].apply(lambda x:1 if x=='low' else(2 if x=='med' else 3))
test_df['buying']=test_df['buying'].apply(lambda x:1 if x=='low' else(2 if x=='med' else(3 if x=='high' else 4)))
test_df['maint']=test_df['maint'].apply(lambda x:1 if x=='low' else(2 if x=='med' else(3 if x=='high' else 4)))
test_df['doors'][test_df['doors']=='5more']=5
test_df['persons'][test_df['persons']=='more']=5
test_df['lug_boot']=test_df['lug_boot'].apply(lambda x:1 if x=='small' else(2 if x=='med' else 3))
test_df['safety']=test_df['safety'].apply(lambda x:1 if x=='low' else(2 if x=='med' else 3))
目的変数抽出
df = df.drop('id', axis=1)
test_df = test_df.drop('id', axis=1)
df = df.astype('int')
test_df = test_df.astype('int')
sns.countplot(data=df, x='class',palette='Set3')
y = df['class']
train_df = df.drop('class',axis=1)
目的変数の分布はこんな感じ。'unacc'が多く、車ってあんまり評価されないのかと勘ぐる。
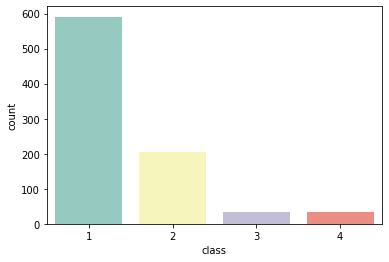
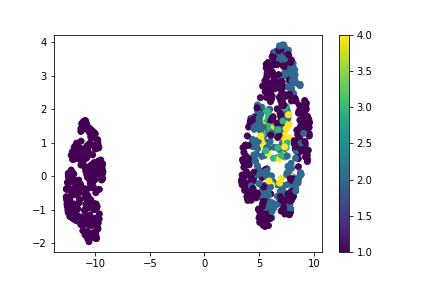
次元圧縮
データがどんな分布をしているかを確認するため、UMAPによって次元圧縮し分布化。
%time train_embedding = TSNE(n_components=2,perplexity=30,verbose=1,learning_rate =500,random_state=666).fit(train_df)
plt.scatter(train_embedding.embedding_[:,0],
train_embedding.embedding_[:,1],
c=y,
cmap='viridis')
plt.colorbar()
plt.show()
この分布上に説明変数はそれぞれどのように配置されているかを確認。
for i in list(train_df.columns):
plt.figure(figsize=(15,4))
plt.subplot(1,3,1)
plt.scatter(train_embedding.embedding_[:,0],
train_embedding.embedding_[:,1],
c=y,
cmap='viridis')
plt.colorbar()
plt.title('label')
plt.subplot(1,3,2)
plt.scatter(train_embedding.embedding_[:,0],
train_embedding.embedding_[:,1],
c=train_df[i],
cmap='viridis')
plt.title(str(i))
plt.colorbar()
plt.subplot(1,3,3)
sns.countplot(data=train_df, y=i, palette='Set3')
plt.show()
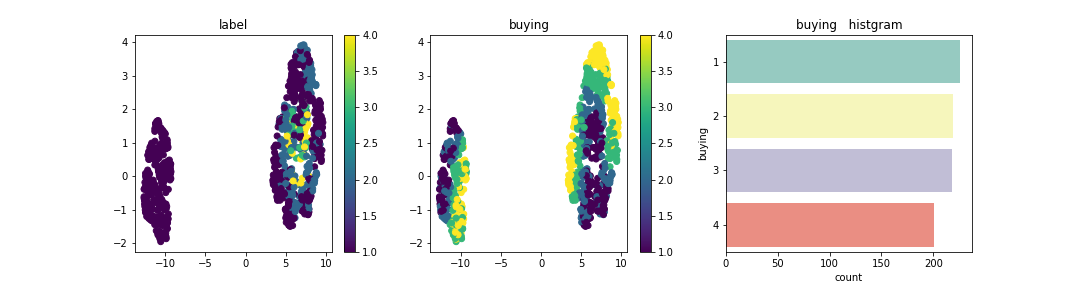
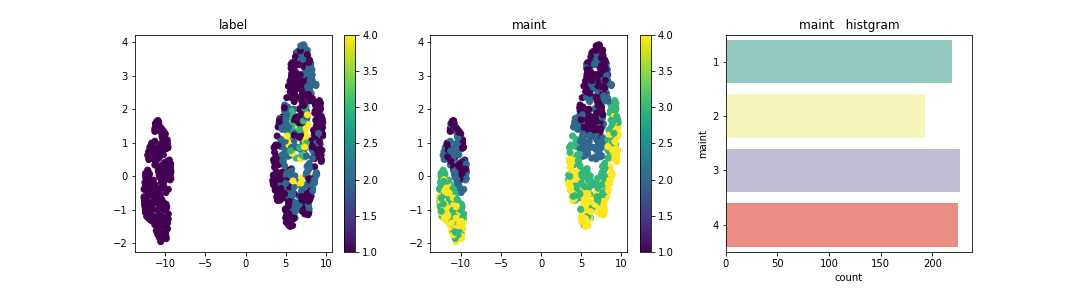
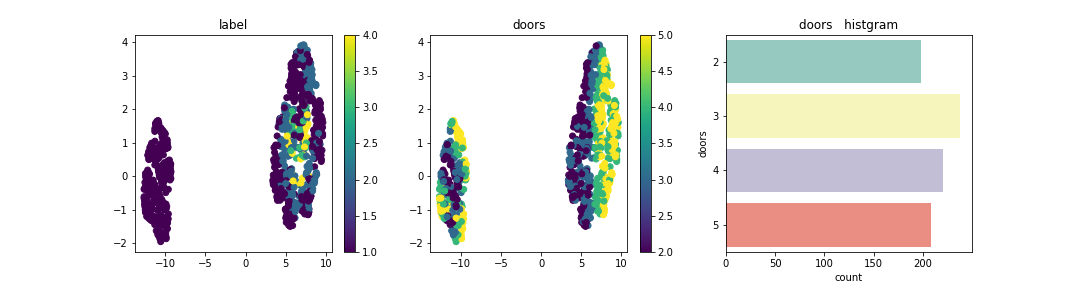
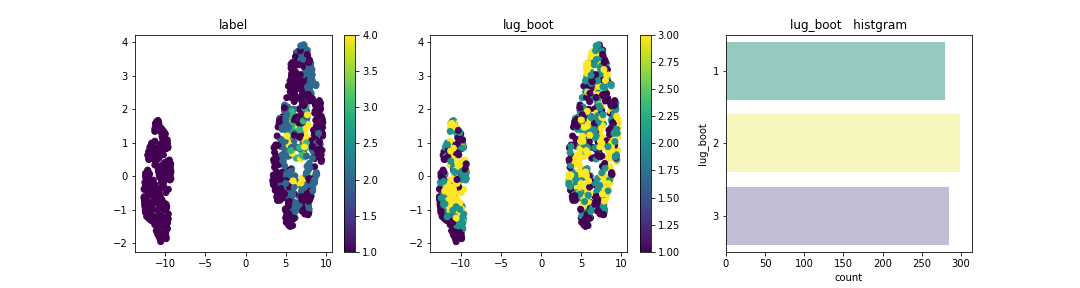
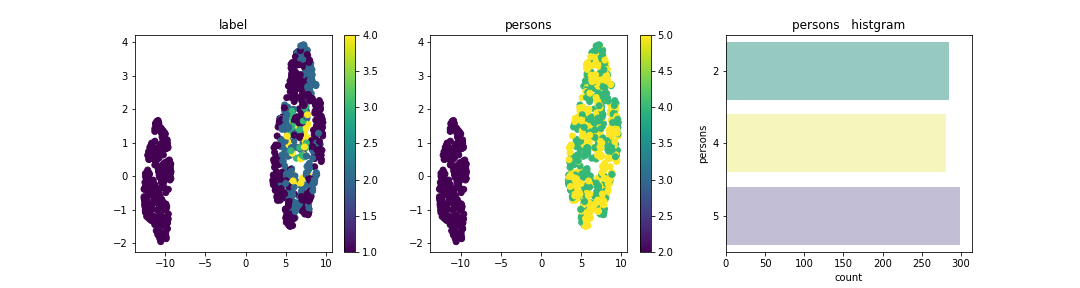
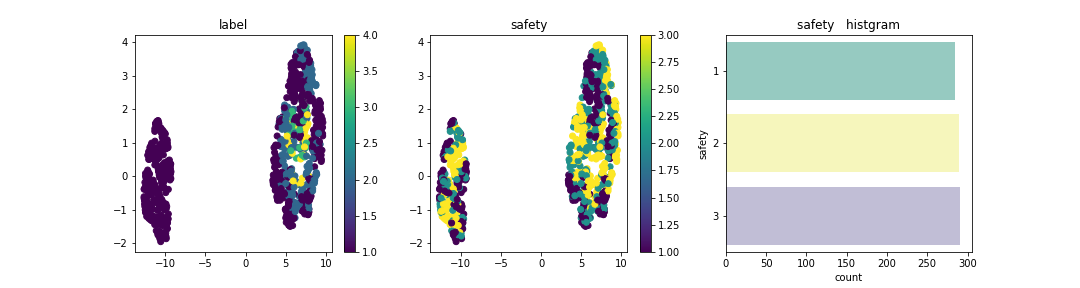
Personは、2が左に集合し、4 or moreが右に集合している。今回のデータセットを次元圧縮した場合の分布はPersonが大きく寄与しており、他の成分は分布上にデータが散在されあまり特徴は見られなかった。
Metric Learning
データをそのまま次元圧縮すると、乗員数(persons)の影響度が強く出るため
データの教師情報を基にデータ間の距離や類似度などの Metric を学習する手法を用いる
mlkr = metric_learn.MLKR(n_components=2)
mlkr.fit(train_df,y)
X_mlkr= mlkr .transform(train_df)
X_mlkr_test = mlkr .transform(test_df)
plt.scatter(X_mlkr[:,0],
X_mlkr[:,1],
c=y,
cmap='viridis')
plt.colorbar()
plt.show()
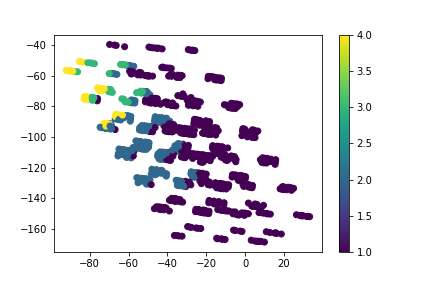
上図中の右下->左上に分布が推移するにつれ、正解ラベルも+方向にシフトしている。
先ほどと同様に、この分布上に各説明変数がどのように存在しているかを確認。
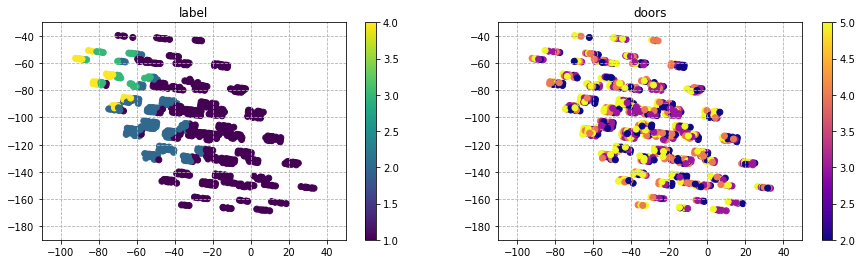
for i in list(train_df.columns):
plt.figure(figsize=(15,4))
plt.subplot(1,2,1)
plt.scatter(X_mlkr[:,0],
X_mlkr[:,1],
c=y,
cmap='viridis')
plt.colorbar()
plt.title('label')
plt.grid(linestyle='dashed')
plt.subplot(1,2,2)
plt.scatter(X_mlkr[:,0],
X_mlkr[:,1],
c=train_df[i],
cmap='plasma')
plt.title(str(i))
plt.colorbar()
plt.grid(linestyle='dashed')
plt.show()
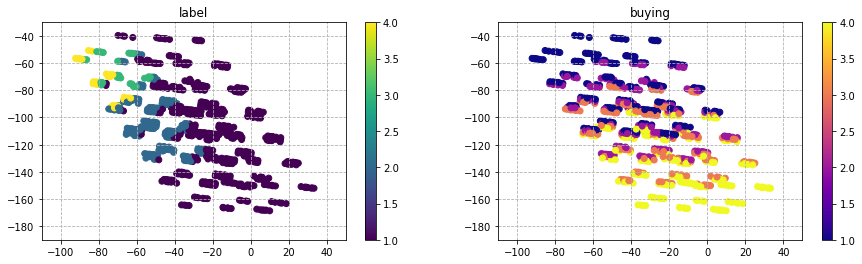
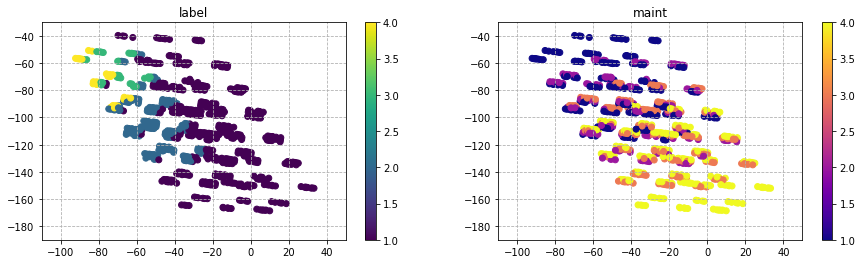
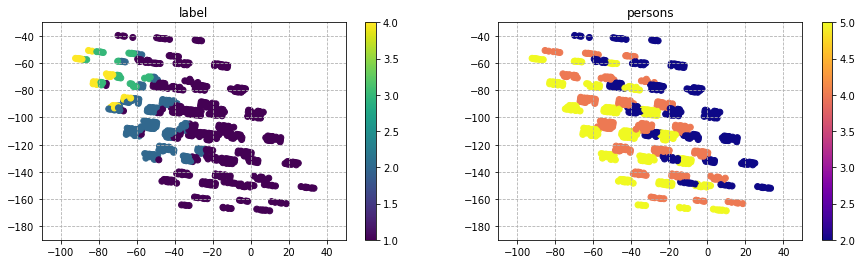
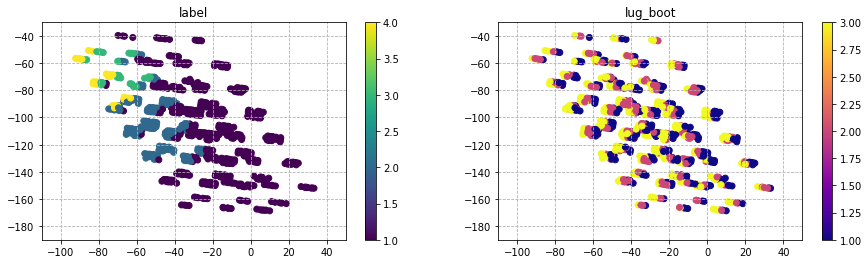
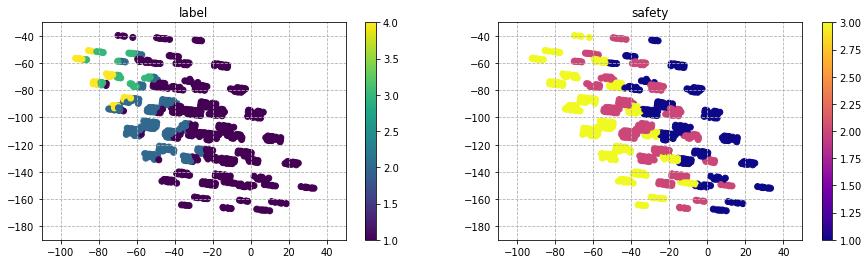
'buying'と'maint'は、図中で下に座標が推移するにつれ評価が悪くなる傾向が見られる。
'person'と'Safety'は、図中で左に座標が推移するにつれ評価が良くなっている傾向が見られる。
この2つの成分を使うことで、評価ラベルに対し影響する説明変数を明確にしていく。
学習
X_train, X_test, y_train, y_test = train_test_split(train_df, y, test_size=0.1, random_state=666)
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
kernel = 1.0 * RBF(1.0)
clf_RF = RandomForestClassifier(max_depth=10, random_state=666, criterion='entropy', class_weight='balanced')
clf_GB = GradientBoostingClassifier(max_depth=10, random_state=666)
clf_AB = AdaBoostClassifier(random_state=666)
clf_EX = ExtraTreesClassifier(max_depth=10, random_state=666)
clf_DT = DecisionTreeClassifier(max_depth=10, random_state=666)
gpc = GaussianProcessClassifier(kernel=kernel, random_state=666)
mlp = MLPClassifier(random_state=666)
clf_RF.fit(X_train, y_train)
clf_GB.fit(X_train, y_train)
clf_AB.fit(X_train, y_train)
clf_EX.fit(X_train, y_train)
clf_DT.fit(X_train, y_train)
mlp.fit(X_train, y_train)
gpc.fit(X_train, y_train)
y_pred_RF = clf_RF.predict(X_test)
y_pred_GB = clf_GB.predict(X_test)
y_pred_AB = clf_AB.predict(X_test)
y_pred_EX = clf_EX.predict(X_test)
y_pred_DT = clf_DT.predict(X_test)
y_pred_ML = mlp.predict(X_test)
y_pred_GP = gpc.predict(X_test)
accu = accuracy_score(y_test, y_pred_RF)
print('RF accuracy = {:>.4f}'.format(accu))
accu = accuracy_score(y_test, y_pred_GB)
print('GB accuracy = {:>.4f}'.format(accu))
accu = accuracy_score(y_test, y_pred_AB)
print('AB accuracy = {:>.4f}'.format(accu))
accu = accuracy_score(y_test, y_pred_EX)
print('EX accuracy = {:>.4f}'.format(accu))
accu = accuracy_score(y_test, y_pred_DT)
print('DT accuracy = {:>.4f}'.format(accu))
accu = accuracy_score(y_test, y_pred_ML)
print('ML accuracy = {:>.4f}'.format(accu))
accu = accuracy_score(y_test, y_pred_GP)
print('GP accuracy = {:>.4f}'.format(accu))
plt.hist([y_test, y_pred_GP])
RF accuracy = 0.9310
GB accuracy = 0.9655
AB accuracy = 0.8046
EX accuracy = 0.9540
DT accuracy = 0.9540
ML accuracy = 0.8966
GP accuracy = 0.9195
勾配ブースティングが精度一番良い。
説明変数が変わった場合のシミュレーション
あるパラメータが変わった場合の、予測ラベルがどのように変化するかを見る
そうすることで、効果がありそうなパラメータの導出を試みる。
まずは、教師データを学習器で予測する。
y_pred_RF = clf_RF.predict(train_df)
y_pred_GB = clf_GB.predict(train_df)
y_pred_AB = clf_AB.predict(train_df)
y_pred_EX = clf_EX.predict(train_df)
y_pred_DT = clf_DT.predict(train_df)
y_pred_ML = mlp.predict(train_df)
y_pred_GP = gpc.predict(train_df)
accu = accuracy_score(y, y_pred_RF)
print('RF accuracy = {:>.4f}'.format(accu))
accu = accuracy_score(y, y_pred_GB)
print('GB accuracy = {:>.4f}'.format(accu))
accu = accuracy_score(y, y_pred_AB)
print('AB accuracy = {:>.4f}'.format(accu))
accu = accuracy_score(y, y_pred_EX)
print('EX accuracy = {:>.4f}'.format(accu))
accu = accuracy_score(y, y_pred_DT)
print('DT accuracy = {:>.4f}'.format(accu))
accu = accuracy_score(y, y_pred_ML)
print('ML accuracy = {:>.4f}'.format(accu))
accu = accuracy_score(y, y_pred_GP)
print('GP accuracy = {:>.4f}'.format(accu))
plt.hist([y, y_pred_GB])
RF accuracy = 0.9884
GB accuracy = 0.9965
AB accuracy = 0.7951
EX accuracy = 0.9954
DT accuracy = 0.9907
ML accuracy = 0.9236
GP accuracy = 0.9225
予測モデルには最も性能が良いGBを用いる。
評価が低い(=評価ラベルが1のもの)だけを抽出
評価変更シミュレーション
low_df = train_df.copy()
## 評価低いやつ
low_df['predict'] = y_pred_GB
low_df = low_df[low_df['predict'] == 1]
display(low_df)
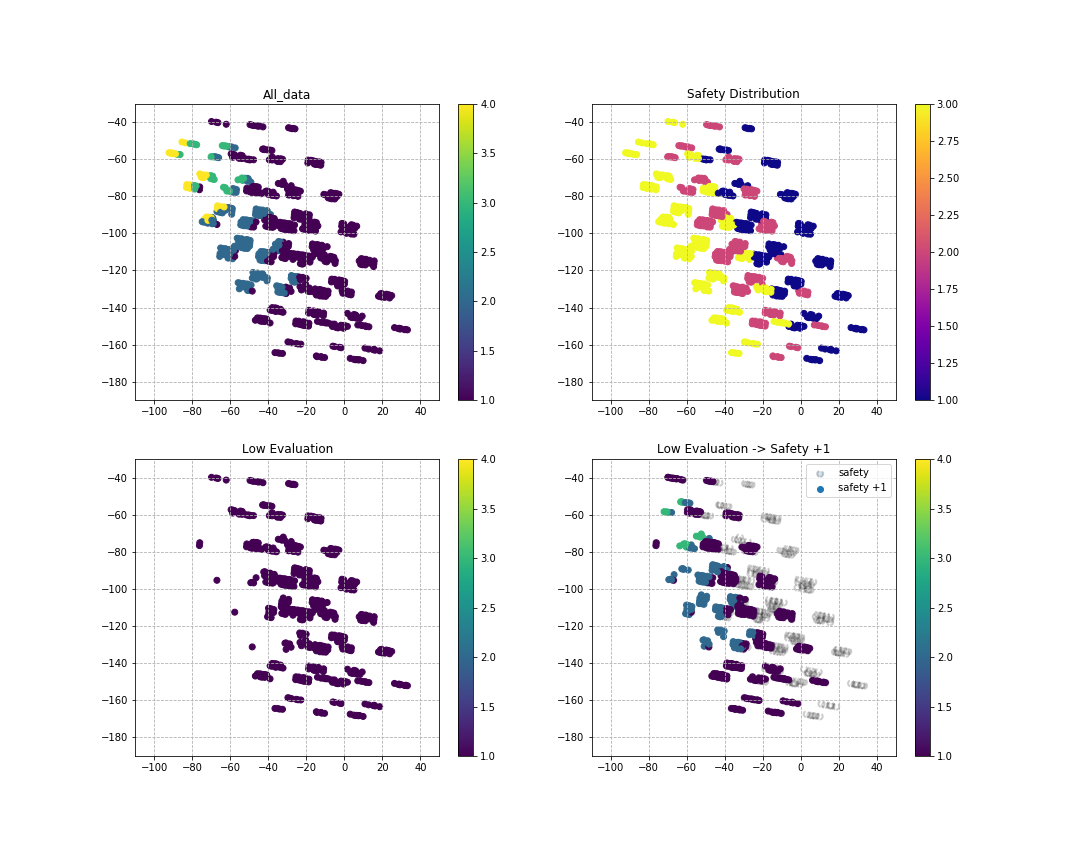
関係のありそうなsafetyを全体的に1押し上げてみる
このデータを使って、再学習によりラベルが変動するのかを調査。
low_df_safety = low_df.copy()
low_df_safety['safety']=low_df_safety['safety'].apply(lambda x:2 if x==1 else(3 if x==2 else(3)))
low_df_safety = low_df_safety.drop('predict', axis=1)
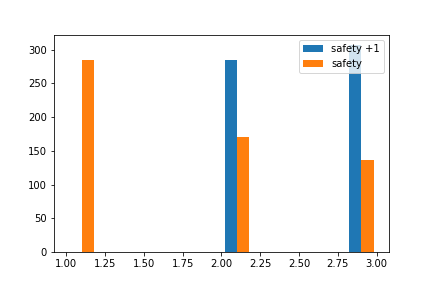
plt.hist([low_df_safety['safety'], low_df['safety']])
plt.show()
Safety評価を1上げたもので予測
low_predict = clf_GB.predict(low_df_safety)
plt.hist([low_predict, low_df['predict']])
low_df_test = low_df.copy()
low_df_test = low_df_test.drop('predict', axis=1)
low_lmnn_test = lmnn.transform(low_df_safety)
low_df_test = lmnn.transform(low_df_test)
plt.figure(figsize=(15,12))
plt.subplot(2,2,1)
plt.scatter(X_mlkr[:,0],
X_mlkr[:,1],
c=y,
cmap='viridis')
plt.colorbar()
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.title('All_data')
# plt.savefig('./fig/metric.png')
plt.subplot(2,2,2)
plt.scatter(X_mlkr[:,0],
X_mlkr[:,1],
c=train_df['buying'],
cmap='plasma')
plt.colorbar()
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.title('Buying Distribution')
plt.subplot(2,2,3)
plt.scatter(low_df_test[:,0],
low_df_test[:,1],
c=low_df['predict'],
vmin=1,
vmax=4,
cmap='viridis')
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.colorbar()
plt.title('Low Evaluation')
plt.subplot(2,2,4)
plt.scatter(low_df_test[:,0],
low_df_test[:,1],
c=low_df['predict'],
vmin=1,
vmax=4,
cmap='gray_r',
edgecolors='black',
linestyle='dashed',
linewidth=2,
alpha=0.2)
plt.scatter(low_mlkr_buying[:,0],
low_mlkr_buying[:,1],
c=low_buying,
cmap='viridis',
vmin=1,
vmax=4)
plt.colorbar()
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.title('Low Evaluation -> Buying -1')
plt.show()
Safetyを無理やりあげた場合に車両評価がどんな変化をするか分布上で確認。
下図中の左下が生データで予測した場合で、右下がSafety項目を"1"だけ評価上がった場合の分布図であり、
車の総合評価にはSafetyに注目すべきと言える。
売値も変えてみる
low_df_buying = low_df.copy()
low_df_buying['buying']=low_df_buying['buying'].apply(lambda x:1 if x==1 else(1 if x==2 else(2 if x==3 else(3))))
low_df_buying = low_df_buying.drop('predict', axis=1)
plt.hist([low_df_buying['buying'], low_df['buying']])
plt.show()
low_buying = clf_GB.predict(low_df_buying)
plt.hist([low_buying, low_df['predict']])
low_df_test = low_df.copy()
low_df_test = low_df_test.drop('predict', axis=1)
low_mlkr_buying = mlkr.transform(low_df_buying)
low_df_test = mlkr.transform(low_df_test)
plt.figure(figsize=(15,12))
plt.subplot(2,2,1)
plt.scatter(X_mlkr[:,0],
X_mlkr[:,1],
c=y,
cmap='viridis')
plt.colorbar()
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.title('All_data')
# plt.savefig('./fig/metric.png')
plt.subplot(2,2,2)
plt.scatter(X_mlkr[:,0],
X_mlkr[:,1],
c=train_df['buying'],
cmap='plasma')
plt.colorbar()
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.title('Buying Distribution')
plt.subplot(2,2,3)
plt.scatter(low_df_test[:,0]
,
low_df_test[:,1],
c=low_df['predict'],
vmin=1,
vmax=4,
cmap='viridis')
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.colorbar()
plt.title('Low Evaluation')
plt.subplot(2,2,4)
plt.scatter(low_df_test[:,0],
low_df_test[:,1],
c=low_df['predict'],
vmin=1,
vmax=4,
cmap='gray_r',
edgecolors='black',
linestyle='dashed',
linewidth=2,
alpha=0.2)
plt.scatter(low_mlkr_buying[:,0],
low_mlkr_buying[:,1],
c=low_buying,
cmap='viridis',
vmin=1,
vmax=4)
plt.colorbar()
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.title('Low Evaluation -> Buying -1')
plt.show())
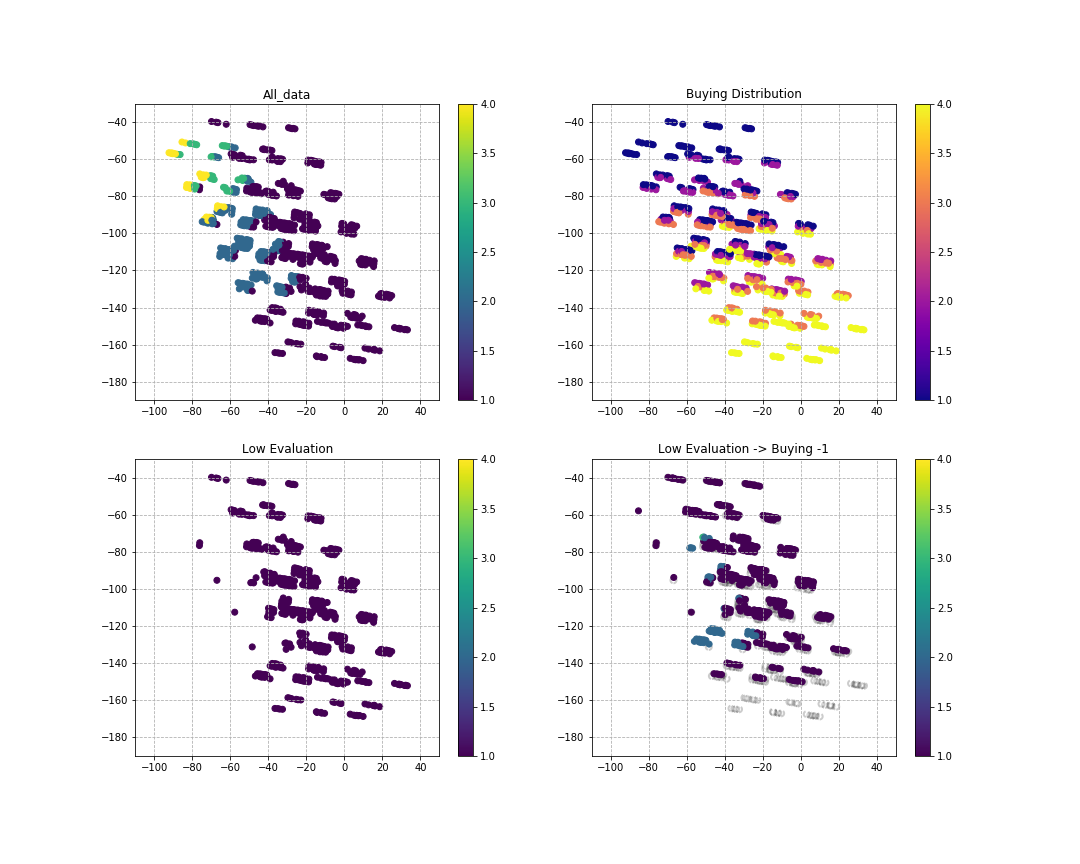
売値については、売値が下がることで評価が上がる可能性がある
両方変えてみた
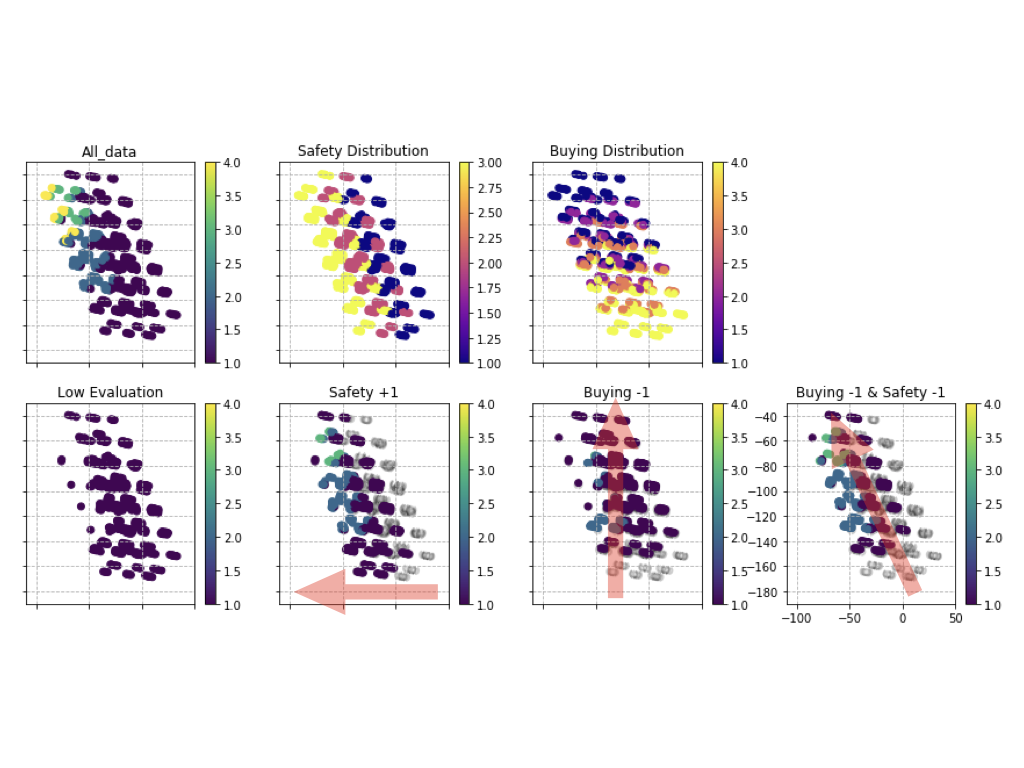
SafetyとBuyingの両方をいじって分布上に配置。
low_df_both = low_df.copy()
low_df_both['buying']=low_df_both['buying'].apply(lambda x:1 if x==1 else(1 if x==2 else(2 if x==3 else(3))))
low_df_both['safety']=low_df_both['safety'].apply(lambda x:2 if x==1 else(3 if x==2 else(3)))
low_df_both = low_df_both.drop('predict', axis=1)
low_both = clf_GB.predict(low_df_both)
plt.hist([low_both, low_df['predict']])
low_df_test = low_df.copy()
low_df_test = low_df_test.drop('predict', axis=1)
low_mlkr_both = mlkr.transform(low_df_both)
low_df_test = mlkr.transform(low_df_test)
low_both = clf_GB.predict(low_df_both)
plt.hist([low_both, low_df['predict']])
low_df_test = low_df.copy()
low_df_test = low_df_test.drop('predict', axis=1)
low_lmnn_both = lmnn.transform(low_df_both)
low_df_test = lmnn.transform(low_df_test)
plt.figure(figsize=(15,7))
plt.subplot(2,4,1)
plt.scatter(X_mlkr[:,0],
X_mlkr[:,1],
c=y,
cmap='viridis')
plt.colorbar()
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.tick_params(labelbottom=False,
labelleft=False,
labelright=False,
labeltop=False)
plt.title('All_data')
# plt.savefig('./fig/metric.png')
plt.subplot(2,4,2)
plt.scatter(X_mlkr[:,0],
X_mlkr[:,1],
c=train_df['safety'],
cmap='plasma')
plt.colorbar()
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.tick_params(labelbottom=False,
labelleft=False,
labelright=False,
labeltop=False)
plt.title('Safety Distribution')
plt.subplot(2,4,3)
plt.scatter(X_mlkr[:,0],
X_mlkr[:,1],
c=train_df['buying'],
cmap='plasma')
plt.colorbar()
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.tick_params(labelbottom=False,
labelleft=False,
labelright=False,
labeltop=False)
plt.title('Buying Distribution')
plt.subplot(2,4,5)
plt.scatter(low_df_test[:,0],
low_df_test[:,1],
c=low_df['predict'],
vmin=1,
vmax=4,
cmap='viridis')
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.colorbar()
plt.tick_params(labelbottom=False,
labelleft=False,
labelright=False,
labeltop=False)
plt.title('Low Evaluation')
plt.subplot(2,4,6)
plt.scatter(low_df_test[:,0],
low_df_test[:,1],
c=low_df['predict'],
vmin=1,
vmax=4,
cmap='gray_r',
edgecolors='black',
linestyle='dashed',
linewidth=2,
alpha=0.2)
plt.scatter(low_mlkr_test[:,0],
low_mlkr_test[:,1],
c=low_predict,
cmap='viridis',
vmin=1,
vmax=4)
plt.colorbar()
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.tick_params(labelbottom=False,
labelleft=False,
labelright=False,
labeltop=False)
plt.title('Safety +1')
plt.subplot(2,4,7)
plt.scatter(low_df_test[:,0],
low_df_test[:,1],
c=low_df['predict'],
vmin=1,
vmax=4,
cmap='gray_r',
edgecolors='black',
linestyle='dashed',
linewidth=2,
alpha=0.2)
plt.scatter(low_mlkr_buying[:,0],
low_mlkr_buying[:,1],
c=low_buying,
cmap='viridis',
vmin=1,
vmax=4)
plt.colorbar()
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.tick_params(labelbottom=False,
labelleft=False,
labelright=False,
labeltop=False)
plt.title('Buying -1')
plt.subplot(2,4,8)
plt.scatter(low_df_test[:,0],
low_df_test[:,1],
c=low_df['predict'],
vmin=1,
vmax=4,
cmap='gray_r',
edgecolors='black',
linestyle='dashed',
linewidth=2,
alpha=0.2)
plt.scatter(low_mlkr_both[:,0],
low_mlkr_both[:,1],
c=low_both,
cmap='viridis',
vmin=1,
vmax=4)
plt.colorbar()
plt.xlim(-110, 50)
plt.ylim(-190,-30)
plt.grid(linestyle='dashed')
plt.title('Buying -1 & Safety -1')
# plt.tick_params(labelbottom=False,
# labelleft=False,
# labelright=False,
# labeltop=False)
plt.axis(True)
plt.show()
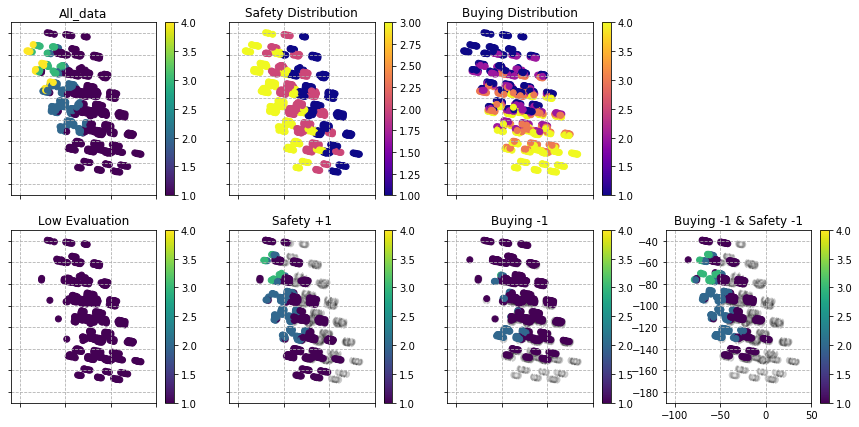
距離学習を行うことで、類似度が高いデータ同士は近くに置かれ、遠いものは遠くに置くことができる。その手法によって、ラベルごとにデータを並べていった場合にある方向にだけ反応する説明変数の抽出が可能となる。今回は安全性は緯度方向に反応し、売値は下から上に経度方向へと反応している。
つまり、この軸方向に力学的に作用するパラメータを変更することで、予測ラベルがどのように動くかが視覚的に理解することができる。
予測精度を上げるために、CNNに次回挑戦。
to be continued.