0.はじめに
CNN(Convolution Neural Network)をそのまま全結合層まで使って普段やられている方が多いと思いますが、ちょっと視点を変えてCNNをただの特徴量抽出器として扱ってみます。
具体的には【softmax】より上位の層を使って、ある次元の出力を基に別の機械学習手法(SVMなど)で分類してしまおうという考えです。
1.データの準備
今回はMNISTでは簡単すぎるので、CIFAR10を用いることにします
# 今回使うライブラリ
import matplotlib.pyplot as plt
import numpy as np
from keras.datasets import cifar10
from keras.models import *
from keras.layers import *
from keras.utils import *
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
import umap
from scipy.sparse.csgraph import connected_components
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
import seaborn as sns
# CIFAR10をロード
(X_train,y_train),(X_test, y_test) = cifar10.load_data()
2.データの確認
print('X_train:', X_train.shape, 'y_train:', y_train.shape)
print('X_test:', X_test.shape, 'y_test:', y_test.shape)
X_train: (50000, 32, 32, 3) y_train: (50000, 1)
X_test: (10000, 32, 32, 3) y_test: (10000, 1)
CIFAR10は、50000枚の学習データと10000枚の検証用データがあります。そして0〜9までの10このラベルデータから構成されてます。
どんな画像かを確認したいと思います。
# 学習用データをシャッフル
l = list(zip(X_train, y_train))
np.random.shuffle(l)
X_train, y_train = zip(*l)
# データを図示
plt.figure(figsize=(20,20))
for i in range(100):
plt.subplot(10,10,i+1)
plt.imshow(X_train[i])
plt.axis('off')
plt.title(str(y_train[i]),fontsize=14)
plt.savefig('./cifar10.png', bbox_inches='tight')
plt.show()

犬やら飛行機やら馬やら、様々な画像が入っています。
3.学習用に変換
今回はCNNに入出力できるように、入力は正規化、出力はone-hot表現に変換します。
## 正規化
X_train = np.array(X_train, dtype='float32')/255.
X_test = X_test/255.
## One-hot化
y_train = np_utils.to_categorical(y_train,10)
y_test = np_utils.to_categorical(y_test,10)
4.CNNモデル構築
今回は単純なSequentialなモデルを構築します。Softmaxの前の出力を得るために、それぞれの層に名前をつけていきます。
input1 = Input((32,32,3,))
conv1 = Conv2D(32, (2,2), padding='same', name='conv2D_1', kernel_initializer='he_normal')(input1)
conv1 = Conv2D(32, (2,2), padding='same', name='conv2D_2', kernel_initializer='he_normal')(conv1)
acti1 = Activation('relu', name='acti1')(conv1)
pool1 = MaxPool2D(pool_size=(2,2), name='pool1')(acti1)
drop1 = Dropout(0.2, name='drop1')(pool1)
conv2 = Conv2D(32, (2,2), padding='same', name='conv2D_3', kernel_initializer='he_normal')(drop1)
conv2 = Conv2D(32, (2,2), padding='same', name='conv2D_4', kernel_initializer='he_normal')(conv2)
acti2 = Activation('relu', name='acti2')(conv2)
pool2 = MaxPool2D(pool_size=(2,2), name='pool2')(acti2)
drop2 = Dropout(0.2, name='drop2')(pool2)
flat1 = Flatten(name='flat1')(drop2)
#### 出力を得たい層 ####
dens1 = Dense(512, name='hidden')(flat1)
acti3 = Activation('relu', name='acti3')(dens1)
dens2 = Dense(10,activation='softmax', name='end')(acti3)
model = Model(inputs=input1, outputs=dens2)
model.compile(loss='categorical_crossentropy',
optimizer='Adam',
metrics=['accuracy'])
モデルの中間層'hidden'の出力を得るモデルを作ります。
layer_name = 'hidden'
hidden_model = Model(inputs=model.input, outputs=model.get_layer(layer_name).output)
これで、パラメータ更新がされた中間層の出力を得ることができます。
早速、学習させてみます。
history=model.fit(X_train,y_train,batch_size=128,epochs=20,verbose=1,validation_split=0.2)
テストデータで精度検証します。
predict_class = model.predict(X_test)
predict_class = np.argmax(predict_class, axis=1)
true_class = np.argmax(y_test, axis=1)
cmx = confusion_matrix(true_class, predict_class)
plt.figure(figsize=(12,12))
sns.heatmap(cmx, annot=True)
# plt.savefig('./cnn_predict.png', bbox_inches='tight')
plt.show()
print("Accuracy: {0}".format(accuracy_score(true_class, predict_class)))
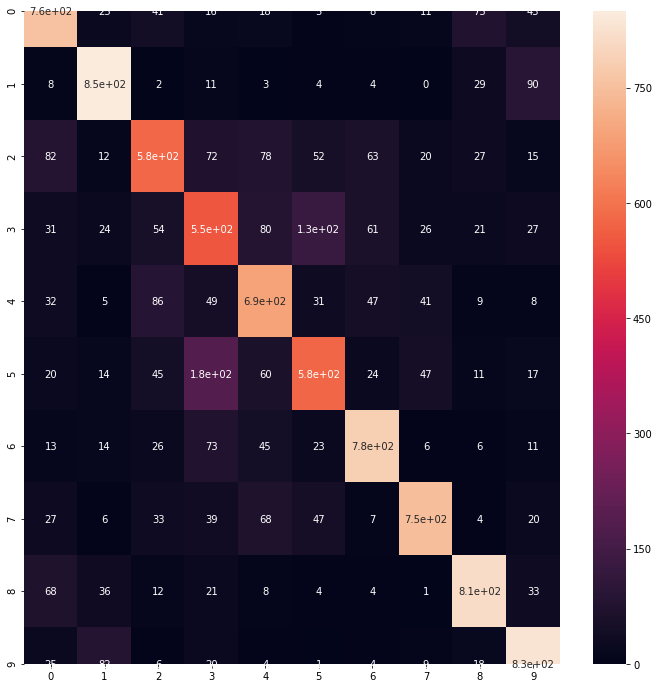
Accuracy: 0.7179
正答率は72%弱ってところです。これと今回のCNN+機械学習手法と比較します。
5.中間層出力の可視化
まずは中間層出力ではどのようにデータが分布されているかを次元圧縮によって可視化します。
hidden = hidden_model.predict(X_train)
hid_co = umap.UMAP().fit(hidden)
plt.scatter(hid_co.embedding_[:,0],
hid_co.embedding_[:,1],
c = np.argmax(y_train, axis=1),
cmap='plasma')
plt.colorbar()
plt.savefig('./train_umap.png', bbox_inches='tight')
plt.show()
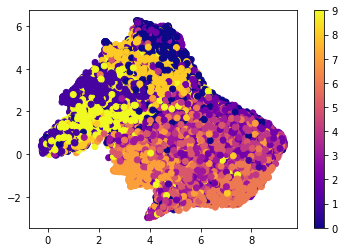
なかなかにごちゃごちゃしている。これが正答率が悪い原因なのかもしれない。
この次元圧縮する前の出力を用いて、SVMで分類していきます。
6.機械学習による分類
SVMでの分類学習におけるハイパーパラメータの調整は、グリッドサーチを使ってフィッティングしていきます。
svmclf = SVC()
svmclf.fit(hidden, np.argmax(y_train, axis=1))
# 予測
hidden_test = hidden_model.predict(X_test)
y_pred_SVM = svmclf.predict(hidden_test)
Accuracy: 0.7221
ちょっとだけ良くなりました。
7.おわりに
CNNの分類器はSoftmaxがメジャーになっていますが、これはそのまま学習することができることからだと思っています。
今回検証したように、CNNを特徴量抽出器として扱い分類問題はこれまでの機械学習手法の方が正確な場合もあります。
ハイパーパラメータのグリッドサーチや、他の機械学習(ランダムフォレストなど)でも試してみたいです。