ランキンングステージ(ステージ2)の徹底解説
はじめに
DataRobotの詹金(センキン)と申します。シニアデータサイエンティストとしてお客様の分析プロジェクトを支援しています。前職では、ECサイトでレコメンドシステムの開発に携わり、これまでレコメンドシステムの精度を競う世界的なデータ分析コンペティションで複数回の入賞経験があります。
本稿では、世界的なデータ分析コンペティションであるKaggleの「H&M Personalized Fashion Recommendations」[1]で筆者が優勝した時に用いた解法を基に、「Two-Stage Recommendation System」の後半部分、すなわちステージ1で選択された商品にランク付けを行う「ステージ2」の技法を詳しく解説します(このコンペティションでのタスクは、ファッションブランドH&Mの購買データを題材に、顧客の行動履歴から、翌週に購入する商品をレコメンドすることでした)。
特徴量エンジニアリング
レコメンドシステムの精度は、候補選択ステージである程度制限されますが、特徴量エンジニアリングの技術を駆使することで、そのポテンシャルを最大限に引き出すことができます。多様な手法で候補商品を作成しても、適切な特徴量を作成しなければ、レコメンドすべき商品が上位に表示されません。基本的な候補選択の手法に従って特徴量を作成すればある程度の精度は得られますが、さらに幅広い情報を用いて複雑な特徴量を作成しながら精度を限界まで向上させることがコンペでは行われます。
レコメンドシステムの特徴量は、主に以下の3種類に分けられます。
- 顧客側特徴量
- 商品側特徴量
- 顧客と商品の交互作用特徴量
特に、交互作用特徴量は精度改善のポテンシャルが高いため、注力すべきです。Kaggleの「H&M Personalized Fashion Recommendations」[1]で優勝したソリューションで使用されたインパクト上位の特徴量を抜粋すると、以下のようになります。

サンプリング
候補選択ステージで生成したデータは、データ量が大きく、正例よりも負例が圧倒的に多い不均衡データとなります。このようなデータに対しては、多数派のクラス(負例)だけをダウンサンプリングする Negative Down Sampling が非常に有効な手法です。モデルの学習時間を短縮できるだけでなく、精度も向上させることができます。
筆者の経験では、負例と正例の比率は3倍から10倍程度が適切です。また、負例のみのデータは学習に寄与しないため、すべて除外しても問題ありません。サンプリングのシード値を変えることで、複数のデータセットを作成し、それぞれで訓練したモデルを用いたアンサンブル学習も有効です。特徴量の生成には時間がかかるため、ダウンサンプリングを行ってから特徴量を生成することで、処理速度を向上させることができます。
モデルの選択
レコメンドシステムのモデル出力はK個の商品なので、二値分類とランキング学習(Learning-To-Rank)のどちらでも実装できます。
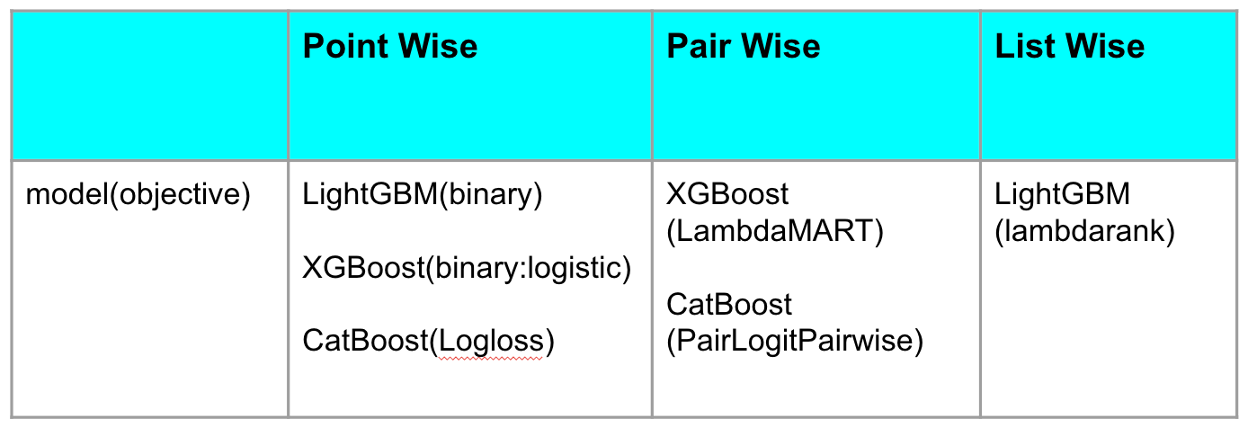
二値分類の場合、pointwise と呼ばれ、1つのサンプルから損失関数を計算します。
ランキング学習の場合、pairwise と listwise があります。pairwise は、顧客ごとに候補商品中の2つのサンプルペアを正しく順序付けできれば、結果として正しいランキングになるような損失関数を計算します。listwise は、顧客ごとにすべての候補商品が良い並び順になっているかどうかを考慮して損失関数を計算します。
レコメンドシステムの学習データは基本的にテーブルデータであり、勾配ブースティングモデルで非常に高い精度を達成できることが知られています。また、pointwise、pairwise、listwise のいずれのランキング学習にも対応しており、使い勝手が良いです。
筆者が経験した中で、良好な性能を示したモデルと損失関数を以下の表にまとめます。具体的なタスクによってそれぞれの性能は変化しますが、大きな差はありません。複数のモデルや損失関数を用いたアンサンブル学習も有効です。
評価指標の選択
レコメンドシステムの精度パフォーマンスを評価するには、適切な評価指標を設定することが重要です。システムの目的やステージによって様々な種類の評価指標があり、適切なものを選択し活用する必要があります。
候補選択ステージの指標には、Recall@K [6]がよく使われます。Recall は「実際に正例であったもののうち、どれだけ正しく選択できたか」を評価するための指標です。K は顧客ごとに選択する上位K個の候補商品を表します。K が大きいほど Recall@K は高くなりますが、計算負荷も増大し、一定の K を超えるとランキングステージの精度が低下する可能性もあります。そのため、トレードオフを考慮して最適な K を選択し、Recall を改善していく必要があります。
ランキングステージの指標には、AUC がよく用いられます。AUC は正例と負例を識別する能力を測定し、ランク付けする能力も評価します。最終的に顧客ごとに予測値のランクの上位K個の候補商品を推薦します。他に、よく使われるランキング指標としては、MAP (Mean Average Precision)、MRR (Mean Reciprocal Rank)、nDCG (Normalized Discounted Cumulative Gain) [6]などがあります。
製品として実際に稼働している場合、ビジネス指標で評価することが重要となります。CTR(Click Through Rate:クリック率)や CVR(Conversion Rate:コンバージョン率)などの指標がよく見られます。本当に良いレコメンドシステムは、モデル指標とビジネス指標が一致するため、モデルの精度改善が直接ビジネス利益に反映されます。
LLMのレコメンドシステム活用
大規模言語モデル(LLM)は、登場以来、幅広いタスクに優れた汎用性を示すモデルとして注目されていますが、レコメンドシステムへの活用研究も活発化しています。従来のレコメンドシステムは、主にユーザーの行動履歴情報と協調フィルタリング技術を利用していましたが、文章から意味を理解することが苦手でした。LLMは従来の自然言語処理(NLP)モデルよりも幅広い知識や文脈を獲得できるため、レコメンドシステムのこの弱点を補うことができます。最新の研究論文[7]によると、LLMは予測型レコメンドシステムと生成型レコメンドシステムの2つの分野で貢献できることが示されています。
これまで解説したように、予測型レコメンドシステムの精度を改善するには、学習データと特徴量の質が重要です。LLMは、データオーグメンテーションと特徴量エンジニアリングに役立ちます。
Kaggleでよく使われるNLPタスクのデータオーグメンテーション手法として、英語からフランス語やドイツ語に翻訳し、さらに英語に逆翻訳することで、新しい英語データを作成し、学習データ数を増やす方法[8]があります。LLMは翻訳が得意で、高品質で類似した文章を生成できます。
従来のレコメンドシステムの特徴量抽出では、顧客の性別、年齢、地域、商品のサイズ、色、カテゴリなどがlabel encoderやone hot encoderで作成されていましたが、文脈や意味が欠けていました。商品のタイトルや説明文は、言語モデルでword embeddingやsentence embeddingが抽出されますが、LLMはより広い領域の知識、文脈、意味を理解した上で、すべての情報を組み合わせて、より深い理解に基づいたembedding特徴量を作成できます。
生成型レコメンドシステムは、予測型レコメンドシステムと異なり、コンテンツを生成することでレコメンドを改善することを目的としています。例えば、KDDCup2023のTask3[9]では、次の購入商品のタイトルを予測することが課題でした。このタスクの目的は、既存の商品をレコメンドするのではなく、新しい商品(コールドスタート商品)を予測することです。これは、生成型レコメンドシステムならではのユニークな課題と言えるでしょう。生成されたタイトルは、直接利用するのではなく、様々な下流タスクを改善する可能性を秘めています。LLMは、zero-shot/one-shot/few-shot学習に優れており、コールドスタート課題に適しています。
LLMは急速に進化しており、産業界におけるレコメンドシステムへの活用は始まったばかりです。今後の動向に注目すべきでしょう。
レコメンドコンペティション優勝解法徹底解説のまとめ
本ブログでは、実務で活かせる情報をご提供することを目的として、機械学習を用いたTwo-Stage Recommendation Systemを解説し、実際のコンペでこの簡潔かつ強力な技術を応用した結果、低コストでありながら高パフォーマンスな予測システムを構築できたことを示しました。ぜひ、皆様の業務でご活用いただければ幸いです。
References
[1] https://www.kaggle.com/competitions/h-and-m-personalized-fashion-recommendations
[6] https://towardsdatascience.com/evaluation-metrics-for-recommendation-systems-an-overview-71290690ecba
[7] https://arxiv.org/pdf/2305.19860
[8] https://www.kaggle.com/code/keitazoumana/data-augmentation-in-nlp-with-back-translation
[9] https://www.aicrowd.com/challenges/amazon-kdd-cup-23-multilingual-recommendation-challenge/problems/task-3-next-product-title-generation