
1. はじめに
こんにちは、DataRobotデータサイエンティストの長野です。普段はDataRobotでデータサイエンティストとして製造業・ヘルスケア業界のお客様を担当しています。技術的には生成AIを担当しています。 今回は、DataRobot CodeSpaceでLLMを使った名寄せ処理を試してみました。
名寄せ処理は、企業が保有する顧客データや商品データなどにおいて、同一のものを特定し、統合する処理のことです。 表記揺れやデータ形式の違いを吸収し、データの一貫性を保つために重要な役割を果たします。従来の名寄せ処理では、ルールベースのマッチングや名寄せツールなどが用いられてきましたが、LLMの登場により、自然言語処理能力を活用したより高度な名寄せ処理が可能になりました。
本記事では、DataRobot CodeSpace上でLLM(Azure OpenAI)を利用した名寄せ処理の具体的なコードと解説を通じて、LLMを活用した名寄せ処理の実現方法を紹介します。
2. 名寄せ処理とは
名寄せ処理は、企業が保有する様々なデータ(顧客データ、商品データ、取引データなど)の中から、同一のものを特定し、統合するプロセスです。これにより、データの一貫性が保たれ、重複データが排除されます。たとえば、顧客データを名寄せすることで、顧客の属性情報や購買履歴を正確に把握でき、よりパーソナルなマーケティング施策の展開が可能となります。
なお、LLMを活用した名寄せ処理は、従来のルールベースの手法に比べ柔軟な対応が可能ですが、APIトークンの利用に伴うコストが発生します。今回の実装例ではLLMを用いる手法を紹介していますが、必ずしもすべてのユースケースに最適な手法とは限らず、コスト面や出力の精度についても十分な検討が必要です。
3. DataRobot CodeSpaceとは
DataRobot CodeSpaceは、DataRobotプラットフォーム上でPythonなどの言語を用いてデータ分析や機械学習モデルの開発を行うための統合環境です。Jupyter Notebook形式(.ipynb)やPythonスクリプト(.py)での開発が可能で、統一された実行環境によりコードやノートブックの再現性が向上します。また、GPU環境を利用した高速な計算処理が実現できる点も大きな特徴です。
さらに、CodeSpaceでLLMを利用するメリットは以下の通りです。
- シームレスな連携: DataRobotの他の機能との統合が容易で、開発フロー全体の効率化が図れます。
- 迅速な試行: DataRobot AIアクセラレーターが提供する生成AI関連のコード資産をすぐに試せるため、プロトタイピングや実験がスムーズです。
- 高い再現性: 同一環境でのノートブックやコード実行により、結果の一貫性と再現性が保証されます。
4. 名寄せ処理のコード解説
以下では、DataRobot CodeSpace上でLLM(Azure OpenAI)を活用した名寄せ処理のコード例と、その解説を行います。今回使用した環境は、DataRobotプリインストールのPython 3.11イメージであり、データサイエンスに必要なライブラリは既に揃っているため、追加のインストール作業なくノートブックを実行できます。また、DataRobotプリインストール環境に加え、ユーザー独自のカスタム環境を構築することも可能です。
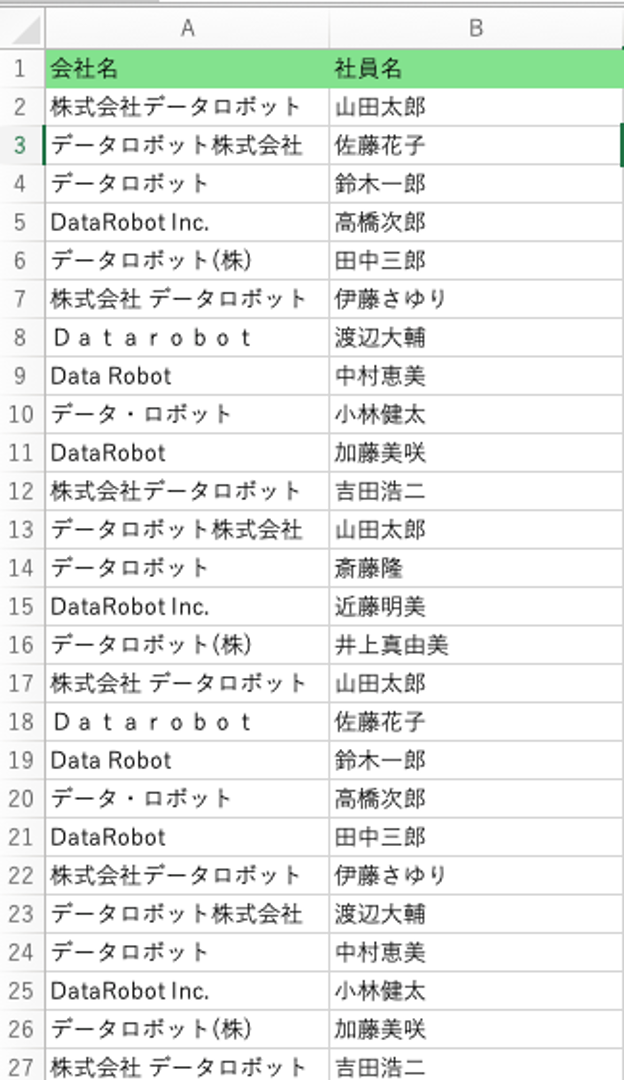
今回の例では、会社名と社員名を含むシンプルな架空のダミーデータセットを使用しています。具体的には、100レコードのデータセットのうち、会社名の列が「DataRobot」「OpenAI」「Claude」の3社に正しく名寄せできるかどうかを検証する内容となっています。
import os
import pandas as pd
import json
from openai import AzureOpenAI
# ============================================
# 設定項目
# ============================================
SYSTEM_PROMPT = f"次の名前リストに対して、同一と思われるものをひとつの代表値にまとめる名寄せ処理を行ってください。\
結果は、元の名前をキー、名寄せ後の名前を値とするJSON形式で必ず出力してください。\
有効な JSON 形式で出力してください。追加の説明やコメントは一切不要です。"
ADDITIONAL_COMMENT = "会社名は全てローマ字で統一して"#追加で出したい指令をここに記載
TARGET_COLUMN = "TARGET" #対象のカラム名を記載する、今回は「会社名」
df = pd.read_csv('YOUR_DATASET.csv')#対象のデータセットを指定
# ============================================
# OpenAI の設定(各自の環境に合わせて API キーなどを設定してください)
# ============================================
# Azure OpenAI 用の設定
client = AzureOpenAI(
api_key="YOUR_API_KEY", # 環境変数などからAPIキーを取得して設定してください
api_version="YOUR_API_VERSION", # ご利用のAPIバージョンを指定してください
azure_endpoint="YOUR_ENDPOINT", # Azureエンドポイントを指定してください
azure_deployment="YOUR_DEPLOYMENT" # ご利用のデプロイメント名を指定してください
)
# ============================================
# Azure OpenAI を使って名寄せプレビューを取得する関数
# ============================================
def preview_deduplication(df, target_column, additional_comment=""):
# 対象列のユニークな値リストを抽出
names = df[target_column].unique().tolist()
# デフォルトのプロンプトを作成
default_prompt = (
SYSTEM_PROMPT + f"\n名前リスト: {names}"
)
if additional_comment:
default_prompt += f"\n追加コメント: {additional_comment}"
print("【プロンプト内容】")
print(default_prompt)
try:
response = client.chat.completions.create(
model="gpt-4o", # 利用するモデル名(必要に応じて変更してください)
messages=[
{"role": "system", "content": "あなたはデータ名寄せの専門アシスタントです。"},
{"role": "user", "content": default_prompt}
],
max_tokens=500,
temperature=0.3
)
# 新しい SDK ではレスポンスは pydantic モデルなので、属性で値にアクセスします
response_text = response.choices[0].message.content.strip()
print("\n【名寄せプレビュー結果】")
print(response_text)
return response_text
except Exception as e:
print("OpenAI API の呼び出しに失敗しました:", e)
return None
# ============================================
# プレビュー結果を承認して新しい DataFrame を生成する機能
# ============================================
def accept_deduplication(df, target_column, dedup_result):
print(json)
try:
mapping = json.loads(dedup_result)
except json.JSONDecodeError as e:
print("名寄せ結果のJSONパースに失敗しました:", e)
return None
new_df = df.copy()
new_df[target_column] = new_df[target_column].apply(lambda x: mapping.get(x, x))
print("\n【新しい DataFrame】")
print(new_df)
return new_df
# ============================================
# メイン処理
# ============================================
if __name__ == "__main__":
# 1. デモデータセットの生成
print("【元のデモデータセット】")
print(df)
# 2. 名寄せプレビューの取得(必要に応じて追加コメントを付与)
preview = preview_deduplication(df, target_column=TARGET_COLUMN, additional_comment=ADDITIONAL_COMMENT)
# プレビュー結果を確認して、承認するかどうかユーザーに入力してもらう
user_input = input("\n上記プレビュー結果を承認しますか? (y/n): ")
if user_input.lower() == "y" and preview is not None:
new_df = accept_deduplication(df, target_column=TARGET_COLUMN, dedup_result=preview)
else:
print("名寄せ処理はキャンセルされました。")
上記のコードでは、以下の処理を行っています。
- OpenAI APIの設定:APIキーなどの情報を設定します。
- データセットの準備:名寄せ対象のデータセットを読み込みます。
- 名寄せプレビュー関数:LLMに名寄せの指示を出し、結果をJSON形式で取得します。
- プレビュー結果の承認とデータ更新関数:ユーザーがプレビュー結果を承認した場合、データセットを更新します。
- メイン処理:上記で定義した関数を呼び出し、名寄せ処理を実行します。
上記のコードを実行すると、名寄せのプレビュー結果が得られます。今回は、LLMに単にカラム名を指定するだけで、高精度な名寄せが実現されていることが確認できました。
ただし、理想としては「DataRobot」「OpenAI」「Claude」の3パターンに名寄せされることを期待していましたが、実際には「DataRobot Inc.」「OpenAI」「Claude Inc.」と、若干異なる結果となりました。これは、システムプロンプトの調整によって改善可能なポイントです。
出力結果一部抜粋
【名寄せプレビュー結果】
{
"株式会社データロボット": "DataRobot Inc.",
"データロボット株式会社": "DataRobot Inc.",
"データロボット": "DataRobot Inc.",
"DataRobot Inc.": "DataRobot Inc.",
"データロボット(株)": "DataRobot Inc.",
"株式会社 データロボット": "DataRobot Inc.",
"Datarobot": "DataRobot Inc.",
"Data Robot": "DataRobot Inc.",
"データ・ロボット": "DataRobot Inc.",
"DataRobot": "DataRobot Inc.",
"オープンAI": "OpenAI",
"株式会社オープンAI": "OpenAI",
"OpenAI": "OpenAI",
"オープン エーアイ": "OpenAI",
"OpenAI": "OpenAI",
"オープンAI": "OpenAI",
"オープンエーアイ": "OpenAI",
"Open AI": "OpenAI",
"オープンAI株式会社": "OpenAI",
"OpenA I": "OpenAI",
"Claude": "Claude Inc.",
"クロード": "Claude Inc.",
"株式会社クロード": "Claude Inc.",
"claude": "Claude Inc.",
"クロードInc.": "Claude Inc.",
"クロード株式会社": "Claude Inc.",
"C L A U D E": "Claude Inc.",
"クロード・システム": "Claude Inc.",
"クロードー": "Claude Inc."
}
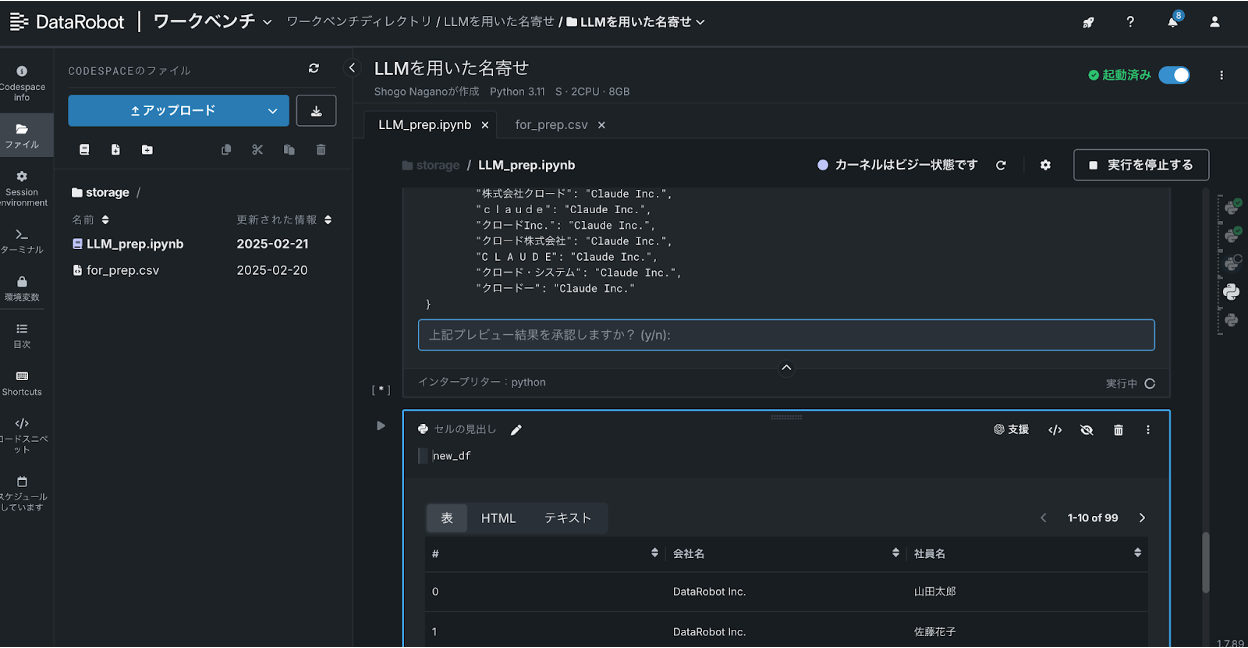
DataRobotの画面上で実行すると下記の通り、「上記プレビュー結果を承認しますか? (y/n)」と聞かれるので承認すると新しいDataFrame(new_df)として名寄せした結果が取得できます。
5. まとめ
本記事では、DataRobot CodeSpace上でAzure OpenAIを利用した名寄せ処理の一例をご紹介しました。LLMを活用することで、従来のルールベースでは対応しきれなかった表記揺れや多様なデータ形式に柔軟に対応できる可能性があることが確認できました。しかしながら、LLMのAPI利用にはトークンコストが発生するため、大規模データセットや頻繁な処理実行を行う場合、コスト面での注意が必要です。また、LLMの出力は必ずしも完璧ではなく、場合によっては誤った統合や予期せぬ結果が生じるリスクも考慮する必要があります。メリットとデメリットを理解しながら一つのアプローチとしてお使いいただければと思います。